

深入解析从NLQ到AI Agent的进化,揭示对话式分析的正确方向
随着企业数据量的爆炸式增长,如何高效、便捷地从数据中提取价值,已成为决定企业成败的关键。对话式商业智能(Conversational BI 或 ChatBI)应运而生,它承诺让非技术用户通过自然语言与数据对话,从而实现数据民主化。然而,在通往真正智能化的道路上,业界出现了一条看似捷径的技术路线:直接利用大语言模型(LLM)将自然语言翻译成SQL查询(Text-to-SQL)。
本文将深入探讨一个核心观点:为什么说单纯基于大语言模型SQL生成能力的ChatBI技术路线,最终都是“瞎折腾”。我们将从技术原理的根本性缺陷、主流产品的实现路径以及企业应用的实际挑战等多个维度,揭示从简单的自然语言查询(NLQ)到复杂的AI智能体(AI Agent)的进化,才是对话式AI的正确方向。
Text-to-SQL的根本性缺陷:看似捷径,实则悬崖
大语言模型(LLM)的出现,让Text-to-SQL的准确率得到了前所未有的提升,在公开的学术基准测试(如Spider)上,其执行准确率甚至能达到87%左右。这让许多人误以为,只要有一个强大的LLM,就能解决ChatBI的所有问题。然而,商业应用远比学术测试复杂,这种看似美好的技术路线,在现实中却隐藏着四大根本性缺陷。
缺陷一:确定性需求与概率性模型的根本矛盾
数据分析是一个对准确性要求极高的领域。一个错误的JOIN,一个错误的聚合函数,都可能导致天差地别的结论,从而误导商业决策。SQL查询本质上是一个需要100%确定性的逻辑问题。然而,LLM的核心是基于概率分布的生成模型,其输出天然存在不确定性。用一个概率模型去解决一个确定性问题,本身就是一种根本性的错配。这意味着,无论模型多强大,它总有“犯糊涂”的时候,而这种“小概率”的错误在企业级应用中是不可接受的。
缺陷二:无法跨越的“语义鸿沟”
用户的自然语言充满了模糊性、歧义和上下文依赖。例如,当用户问“上个月的热销产品”,LLM需要理解“热销”是按销售额还是销量排名?“上个月”是自然月还是滚动30天?这些定义在不同公司、不同业务场景下截然不同。LLM本身并不具备真实的业务知识,它只能根据训练数据进行“猜测”。这种从模糊的业务语义到精确的数据库物理结构的转换,存在着巨大的“语义鸿沟”。研究指出,语义模糊与歧义是导致Text-to-SQL出错的主要原因之一。
缺陷三:“黑箱”操作引发的信任危机
对于非技术用户而言,LLM生成的SQL代码是一个完全的“黑箱”。他们无法验证这个“黑箱”的内部逻辑是否正确,只能被动接受最终的图表或数字。当结果与预期不符时,用户无法判断是数据本身的问题,还是AI理解错了。这种不透明性严重削弱了用户对系统的信任。一份2025年的研究报告显示,尽管企业对GenAI的投资巨大,但高达95%的组织未能获得任何回报,其中一个关键原因就是业务流程的脆弱和缺乏上下文学习能力,这与“黑箱”操作带来的信任缺失密切相关。
缺陷四:将复杂分析简化为“单步翻译”的谬误
真实的商业分析是一个复杂的、迭代的探索过程,而非简单的“一问一答”。一个有经验的分析师在面对“上季度销售额为何下降”这类问题时,会进行一系列的假设、验证和下钻操作。而单纯的Text-to-SQL路线,将这个复杂的过程简化为了一个“翻译”任务,期望用户能一次性提出一个完美的问题,然后AI一次性给出完美的SQL。这完全违背了数据分析的本质,也对用户提出了不切实际的要求。
**核心观点:**单纯的Text-to-SQL路线,本质上是试图用一个“万能翻译器”去解决一个需要深度思考、多步推理和领域知识的复杂分析问题。这种技术上的“偷懒”导致其在准确性、可靠性和实用性上存在天然的上限,注定无法成为企业级ChatBI的最终解决方案。
正确的进化方向:从NLQ到AI Agent
既然单纯的Text-to-SQL是歧途,那么正确的道路在何方?答案是向更高级的智能形态进化:从基础的自然语言查询(NLQ),经由对话式分析,最终到达具备自主决策能力的AI Agent。
第一阶段:自然语言查询(NLQ)与语义层
NLQ是起点,它通过NLP技术将自然语言映射到数据库查询。但要使其可靠,关键在于引入一个“中间层”来弥合语义鸿沟。这个中间层可以是:
- 搜索引擎模式: 以DataFocus为代表,其核心是自研的Focus Search搜索引擎,而非SQL生成器。它将用户的自然语言解析为内部的查询指令,在预先构建的数据虚拟层上进行高效计算。这种方式通过配置同义词、业务术语等,构建了一个轻量级的语义模型,将不确定的自然语言问题,转化为在确定性模型上的搜索和计算,从而保证了结果的准确性。
- 语义层/DSL模式: 以ThoughtSpot、Looker为代表,它们强调构建一个强大的语义层(Semantic Layer)或领域特定语言(Domain-Specific Language, DSL)。这个语义层是业务规则的“宪法”,所有的数据查询都必须通过它。AI的任务不再是自由生成SQL,而是将用户意图准确地映射到这个已经定义好的、可信的语义模型上。这种NL2DSL2SQL的架构,通过增加中间表示,极大地增强了系统的鲁棒性和可治理性。
第二阶段:对话式分析能力构建
在NLQ的基础上,系统需要具备上下文理解和多轮对话的能力,才能称之为“对话式”。这需要一个强大的对话管理模块,能够跟踪对话历史,理解指代和省略,并在用户意图模糊时主动澄清。例如,当用户问完“上海的销售额”后接着问“北京呢?”,系统需要能理解这是在相同的指标下切换维度。
最终形态:AI Agent的智能决策
AI Agent是对话式分析的终极形态。它不再是被动地回答问题,而是像一个真正的“数据分析师”一样主动工作。一个成熟的AI Agent架构通常包括:
- 规划(Planning): 面对复杂问题,能自主地将其分解为一系列可执行的子任务。
- 工具调用(Tool Use): 能调用各种工具(如数据库查询、代码执行、API调用)来完成子任务。
- 记忆(Memory): 能记住历史操作和上下文,从失败中学习。
- 推理与反思(Reasoning & Reflection): 能对结果进行评估,如果未达到目标,会调整计划并进行新一轮的探索。
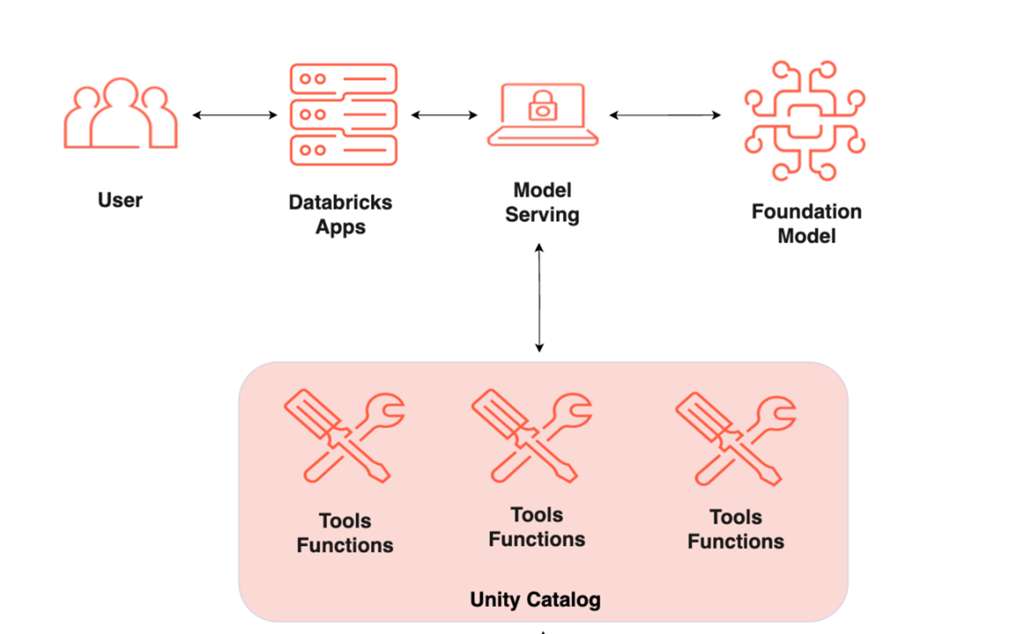
AI Agent架构示意图:用户请求被路由到模型服务,该服务可调用Unity Catalog中定义的各种工具函数来完成任务
AI Agent将“如何分析”的主动权交给了AI,它理解用户的最终目标,并自主规划执行。这才是解决现实世界中模糊、复杂分析需求的根本之道。
主流BI产品技术路线的现实写照
通过分析市场上主流BI产品的AI功能演进,我们可以清晰地看到不同技术路线的优劣和趋势。
| 产品 | 核心技术特点 | 技术路线评价 |
|---|---|---|
| DataFocus | 搜索引擎模式:以自研的Focus Search引擎为核心,将NLQ解析为内部查询指令,而非直接生成SQL。通过配置同义词、关键词等构建轻量级语义模型。 | 避开陷阱,务实进化:从一开始就避开了纯Text-to-SQL的陷阱,保证了查询的确定性。通过FocusGPT的引入,正在向更智能的对话和Agent形态演进。 |
| ThoughtSpot | Agentic AI + 语义层:明确提出“智能体分析平台”,拥有强大的Agentic Semantic Layer。其AI智能体Spotter能主动发现、解释并推荐行动。 | 行业引领者:技术路线最为清晰和前瞻,直接对标AI Agent的终极形态,强调从洞察到行动的闭环。是Agentic BI的典型代表。 |
| Tableau | 从NLQ到Agent的转型:早期功能“Ask Data”因局限性被淘汰,全面转向由“Tableau Agent”驱动的Tableau Pulse。强调主动、个性化的洞察推送。 | 果断转型,拥抱未来:放弃较为初级的NLQ功能,证明了单纯的Text-to-SQL路线在实践中遇到了瓶颈。其转型方向验证了Agent模式的正确性。 |
| Power BI | 生态集成的分析助手:Q&A功能严重依赖人工构建的数据模型。Copilot的加入增强了其作为“助手”的能力,能辅助生成报告、编写DAX等。 | 强大的生态,谨慎的AI:AI功能更多是作为其庞大生态的增强插件,核心仍是辅助用户操作,而非自主决策。其实现路径相对保守,但胜在与微软生态的深度绑定。 |
| Amazon QuickSight | 云原生GenAI助手:由统一的AI助手Amazon Q驱动,将生成式AI能力嵌入BI全流程。通过意图分类将请求路由到不同处理路径。 | LLM赋能的典范:充分利用了LLM的能力,但并非简单地做Text-to-SQL。它通过意图分类和Q Topics等机制,为LLM的自由发挥套上了“缰绳”,体现了在开放与可控之间的平衡。 |
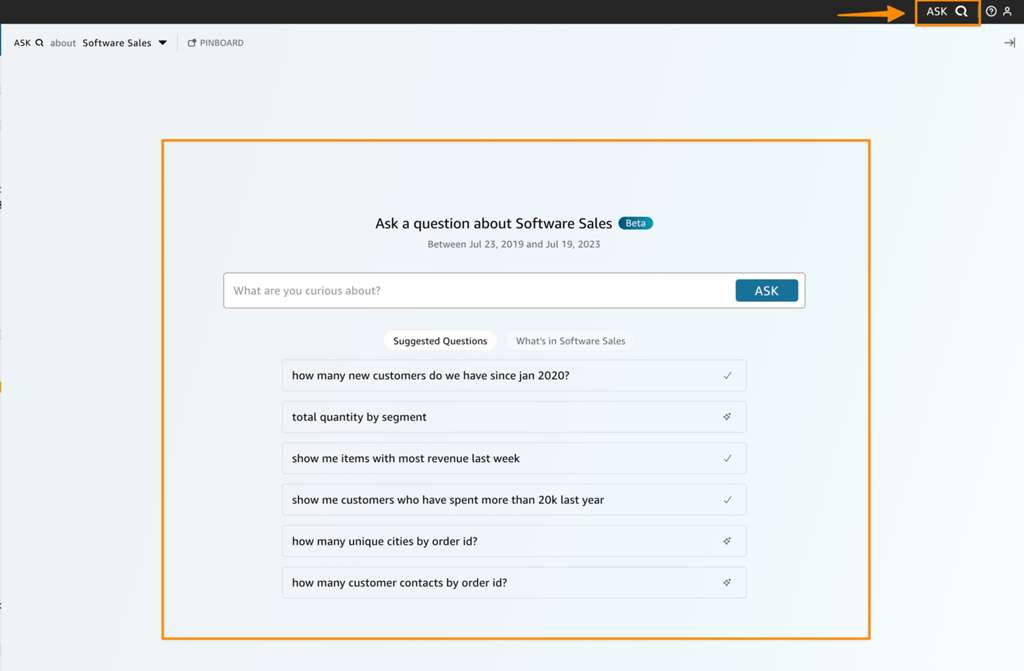
Amazon Q in QuickSight的Q&A体验,通过建议问题和数据概览等方式,为LLM的交互提供了结构化引导
结论:告别“翻译器”思维,拥抱“分析师”智能体
综上所述,单纯依赖大语言模型进行Text-to-SQL翻译的ChatBI技术路线,之所以是“瞎折腾”,其根本原因在于:
- 技术原理的错配: 试图用概率性的语言模型解决需要100%确定性的逻辑查询问题,导致结果不可靠。
- 对分析本质的误解: 将复杂的、迭代的分析过程,错误地简化为单一、线性的“翻译”任务。
- 对数据治理的回避: 妄图用一个“万能”的AI模型绕过语义层、数据准备等基础但至关重要的工作,这在企业级应用中注定失败。
真正的未来属于那些能够将LLM的强大语言能力,与确定性的计算引擎、结构化的语义模型以及自主的规划决策能力相结合的AI Agent系统。无论是DataFocus的“搜索引擎”模式,还是ThoughtSpot的“智能体+语义层”模式,其共同点都是为AI的发挥建立了一个可靠、可控的框架,确保其在正确的轨道上运行。
对于正在进行数字化转型的企业而言,选择ChatBI产品时不应被“一句话生成SQL”的炫技所迷惑。更应该关注其技术架构是否稳健,是否具备处理复杂业务逻辑的语义能力,以及是否能从一个简单的“问答工具”进化为一个真正的“智能分析伙伴”。告别“翻译器”的思维定式,拥抱具备自主思考和行动能力的“分析师”智能体,这才是通往数据驱动决策的正确道路。
