

今天智谱开源这个东西,对于像我们这样搞内容创作、做AI产品的人来说,绝对是个炸裂的福利。
一直以来,高质量的语音合成(TTS)要么贵(大厂API),要么难(开源模型效果机械、部署复杂)。今天,智谱直接把GLM-TTS正式上线并开源,且商用友好(Apache 2.0协议)。
不废话,直接来看看是个什么东西,以及为什么我说它可能是目前开源界最懂戏的声音模型。
1. 3秒就能复刻
以前克隆一个声音,我们可能需要录几十句话,甚至半小时。GLM-TTS只需要3秒。这不是简单的拼凑,它是真的瞬间学会了你的音色。
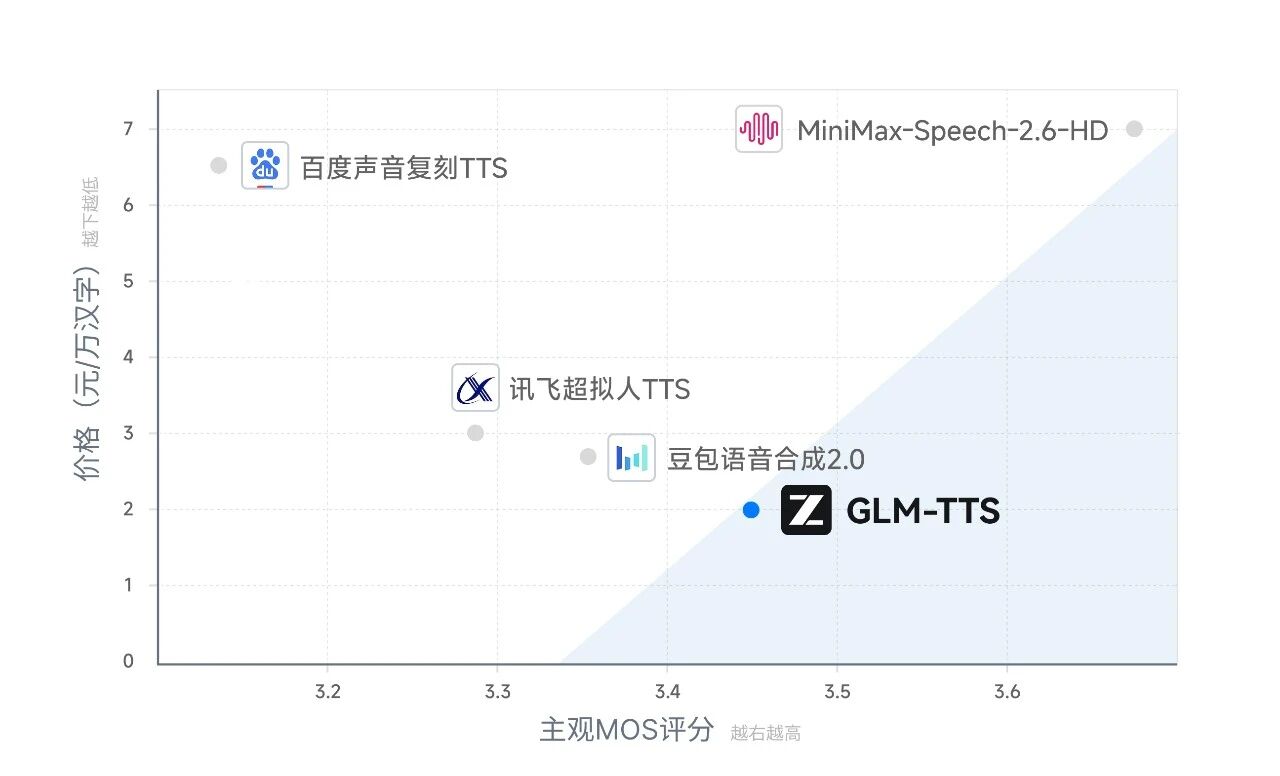 最重要的是,它不仅是读字,它是在表演。
最重要的是,它不仅是读字,它是在表演。
很多开源模型读起文章来像没有感情的杀手,但GLM-TTS能根据上下文,自动匹配开心、悲伤、愤怒的情绪。它甚至能模拟真人的呼吸感、停顿和笑声,让声音听起来有血有肉。
2. 为什么它听起来这么像人?
结合智谱同步发布的技术报告,我挖到了它背后的三个黑科技,正是这些让它跟普通模型拉开了差距:
- 魔鬼训练(GRPO强化学习)
这就好比送AI去上了中央戏剧学院。智谱引入了一种叫GRPO的强化学习机制。传统的模型只要字音读对就给分,GLM-TTS是演得像才给分。
所以在情感表达和副语言(比如笑声、叹气)上,它在开源界拿到了SOTA(目前最佳)的成绩。它不再是读稿机器,而是有情绪的表达者。
- 低成本定制(LoRA微调)
这对开发者极度友好。以前想训练一个专属的高质量IP音色,算力成本很高。
技术报告显示,GLM-TTS只需要调整模型里15%的参数,喂给它1小时的数据,就能训练出一个工业级的专属音色。这意味着,我们想给自己的数字人、客服机器人定制独一无二的声音,成本极低,速度极快。
-
专治没文化乱读(Phoneme-in技术)
做过视频的朋友都知道,AI最怕多音字(银行读成银行为)。
GLM-TTS支持混合输入,不管是多音字、生僻字,还是复杂的数学公式,你都可以强制指定发音。做教育课件、读古诗、讲专业术语,它都能拿捏得死死的,大大减少了后期修音的工作量。
3. 这对我们意味着什么?
作为内容创作者或开发者,GLM-TTS的开源意味着我们可以:
**1. 零成本搭建内容矩阵:**做短视频口播,不再依赖千篇一律的剪映女声,3秒生成各种风格的旁白,辨识度拉满。
**2. 打造更逼真的数字人:**结合之前开源的GLM-4-Voice,现在的数字人不仅能看,还能带着情绪跟你吵架、聊天,沉浸感直接上一个台阶。
**3. 工业级落地:**只有10W小时的训练数据,单机4天就能预训练完,这对中小厂的算力非常友好,二开难度大大降低。
写在最后
智谱这次开源,属于是把听感和控制力做到了平衡。它不仅解决能不能说的问题,更解决了说得像不像人的问题。
对于想做出海视频、数字人IP、或者智能客服的朋友,赶紧去Hugging Face下载权重试试吧。
你的时间,只该用于思考。剩下的,交给AI。
开源地址 (Apache 2.0协议):
-
GitHub👉github.com/zai-org/GLM…
-
Hugging Face👉huggingface.co/zai-org/GLM…
API接入与开发文档:
在线体验:
-
网页版👉audio.z.ai
-
APP端👉智谱清言
如果你也对AI感兴趣,想拥抱AI,不妨可以来看看我们的AI超级个体知识库👇 免费的!
AI超级个体知识库
