import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
df = pd.read_csv("酒店入住数据.csv")
df['入住日期'] = pd.to_datetime(df['入住日期'])
df['离店日期'] = pd.to_datetime(df['离店日期'])
df['入住天数'] = (df['离店日期'] - df['入住日期']).dt.days
df['总费用'] = df['日房价 (元)'] * df['入住天数'] + df['额外消费 (元)']
print(df)
df['月份'] = df['入住日期'].dt.month
df_month = df.groupby('月份').agg({
"入住订单号":"count",
"入住人数":"mean"
}).rename(columns={"入住订单号":"订单量", "入住人数":"平均入住人数"})
print(df_month)
quantiles = df['总费用'].quantile([0.25, 0.5, 0.75])
df_median = df['总费用'].median()
print("总费用的四分位数分别为:\n", quantiles)
print("总费用的中位数为:", df_median)
def group_people(num):
if num == 1:
return "1 人"
elif num == 2:
return "2 人"
else:
return "3 人及以上"
df['入住人数分组'] = df['入住人数'].apply(group_people)
print(df)
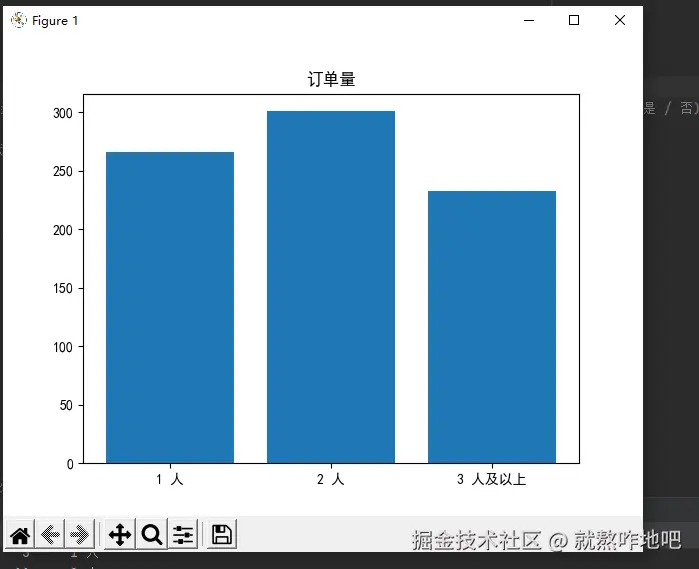
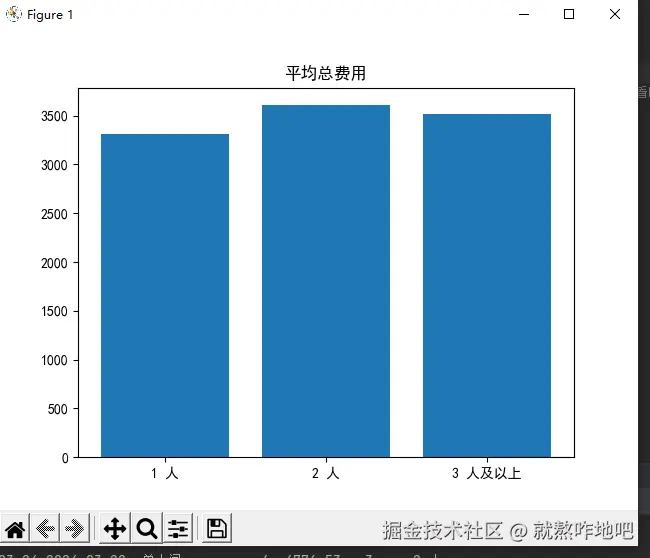
df_states = df.groupby("入住人数分组").agg({
"入住订单号":"count",
"总费用":"mean"
}).rename(columns={"入住订单号":"订单量", "总费用":"平均总费用"})
print(df_states)
plt.rcParams["font.sans-serif"] = ['SimHei']
plt.bar(df_states.index, df_states['订单量'])
plt.title('订单量')
plt.show()
plt.bar(df_states.index, df_states['平均总费用'])
plt.title('平均总费用')
plt.show()
new_df = df[df['房型'] == '套房']
new_df.to_csv("套房入住订单.csv")
df = pd.read_csv("物流配送数据.csv")
df['配送总费用'] = df['基础配送费 (元)'] + df['超重费 (元)']
df['发货时间'] = pd.to_datetime(df['发货时间'])
df['签收时间'] = pd.to_datetime(df['签收时间'])
df['配送耗时'] = (df['签收时间'] - df['发货时间']).dt.total_seconds() / 3600
print(df)
df['发货月份'] = df['发货时间'].dt.month
df['发货日期'] = df['发货时间'].dt.day
df_states = df.groupby(['发货月份', '发货日期']).agg(
配送订单量=('运单号', 'count'),
平均配送距离=('配送距离 (km)', 'mean')
).reset_index()
print(df_states)
df_time = df['配送耗时'].agg(['max', 'min', 'mean', 'std'])
df_time['变异系数'] = df_time['std'] / df_time['mean']
print(df_time)
def group_distance(dist):
if 0 <= dist <10:
return "0-10km"
elif 10 <= dist < 20:
return "10-20km"
else:
return "20km+"
df['配送距离分组'] = df['配送距离 (km)'].apply(group_distance)
df['准时签收标记'] = df['是否准时签收'].map({'是':1, '否':0})
print(df)
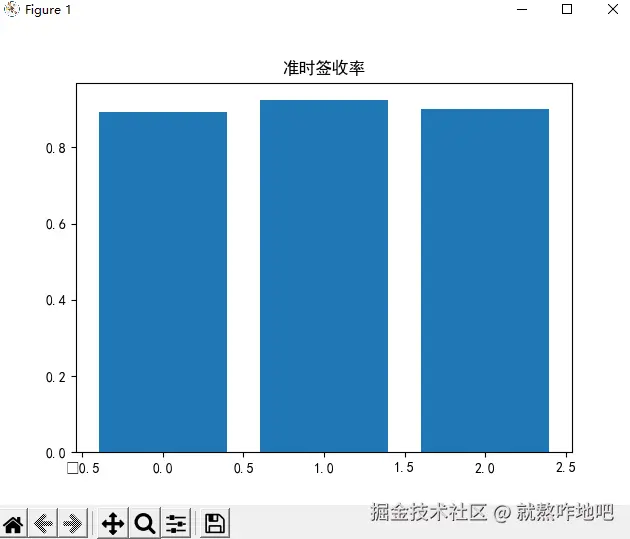
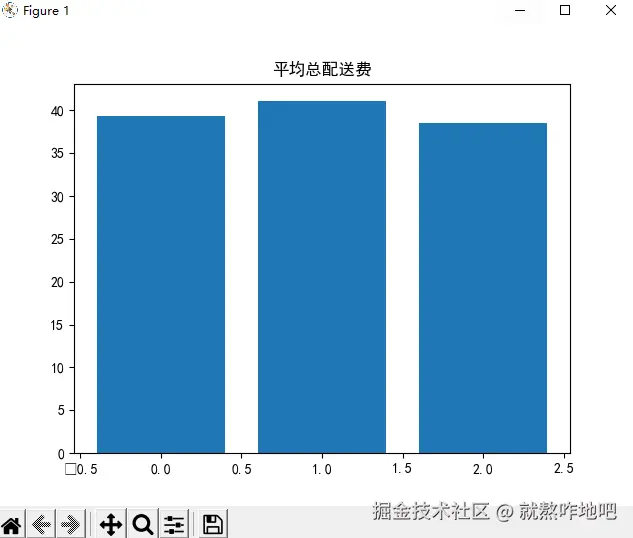
df_dis = df.groupby('配送距离分组').agg(
准时签收率=('准时签收标记', 'mean'),
平均总配送费=('配送总费用', 'mean')
).reset_index()
print(df_dis)
plt.rcParams["font.sans-serif"] = ['SimHei']
plt.bar(df_dis.index, df_dis['准时签收率'])
plt.title('准时签收率')
plt.show()
plt.bar(df_dis.index, df_dis['平均总配送费'])
plt.title('平均总配送费')
plt.show()
new_df = df[df['配送耗时'] > 24]
new_df.to_csv("超时配送订单.csv")
df = pd.read_csv("医院门诊数据.csv")
df['总费用'] = df['诊疗费用 (元)'] + df['药品费用 (元)']
df['是否高费用'] = np.where(df['总费用'] >= 500, '是', '否')
print(df)
def age_group(age):
if 0 <= age <= 18:
return "0-18"
elif 19 <= age <= 40:
return "19-40"
elif 41 <= age <= 60:
return "41-60"
else:
return "60+"
df['年龄分组'] = df['患者年龄'].apply(age_group)
print(df)
df_states = df.groupby(['科室', '年龄分组']).agg(
总就诊数=('就诊编号', 'count'),
高费用就诊数=('是否高费用', lambda x:(x=='是').sum())
)
print(df_states)
ratio = df_states['高费用就诊数'] / df_states['总就诊数']
print(ratio)
corr = df['诊疗费用 (元)'].corr(df['药品费用 (元)'])
print(corr)
states = df.groupby("是否医保报销").agg(
诊疗费用均值=('诊疗费用 (元)', 'mean'),
诊疗费用方差=('诊疗费用 (元)', 'var'),
药品费用均值=('药品费用 (元)', 'mean'),
药品费用方差=('药品费用 (元)', 'var')
)
print(states)
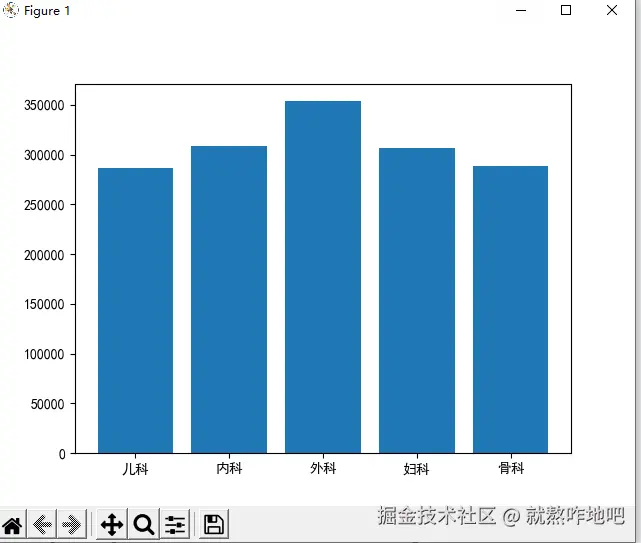
total_sales = df.groupby('科室')['总费用'].sum()
print(total_sales)
plt.rcParams["font.sans-serif"] = ['SimHei']
plt.bar(total_sales.index, total_sales)
plt.show()
df = pd.read_csv("短视频行为数据.csv")
df['观看日期'] = pd.to_datetime(df['观看日期'])
print(df)
df_states = df.groupby("视频类型").agg(
平均观看时长=('观看时长 (秒)', 'mean'),
平均点赞数=('点赞数', 'mean'),
活跃用户数=('用户ID', 'nunique')
).reset_index()
print(df_states)
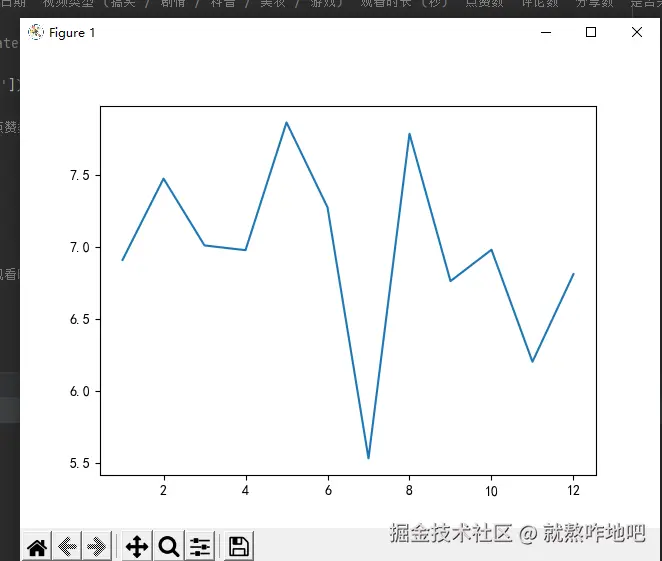
df['月份'] = df['观看日期'].dt.month
month_watch = df.groupby('月份').agg(
总观看时长秒=('观看时长 (秒)', 'sum')
).reset_index()
month_watch['总观看时长小时'] = month_watch['总观看时长秒'] / 3600
print(month_watch)
plt.plot(month_watch['月份'], month_watch['总观看时长小时'])
plt.show()
corr = df['观看时长 (秒)'].corr(df['点赞数'])
print(corr)
new_df = df[df['分享数'] >= 10]
new_df.to_csv('高分享视频记录.csv')