

先说结论:层级搞错了,一切都怪不上工具
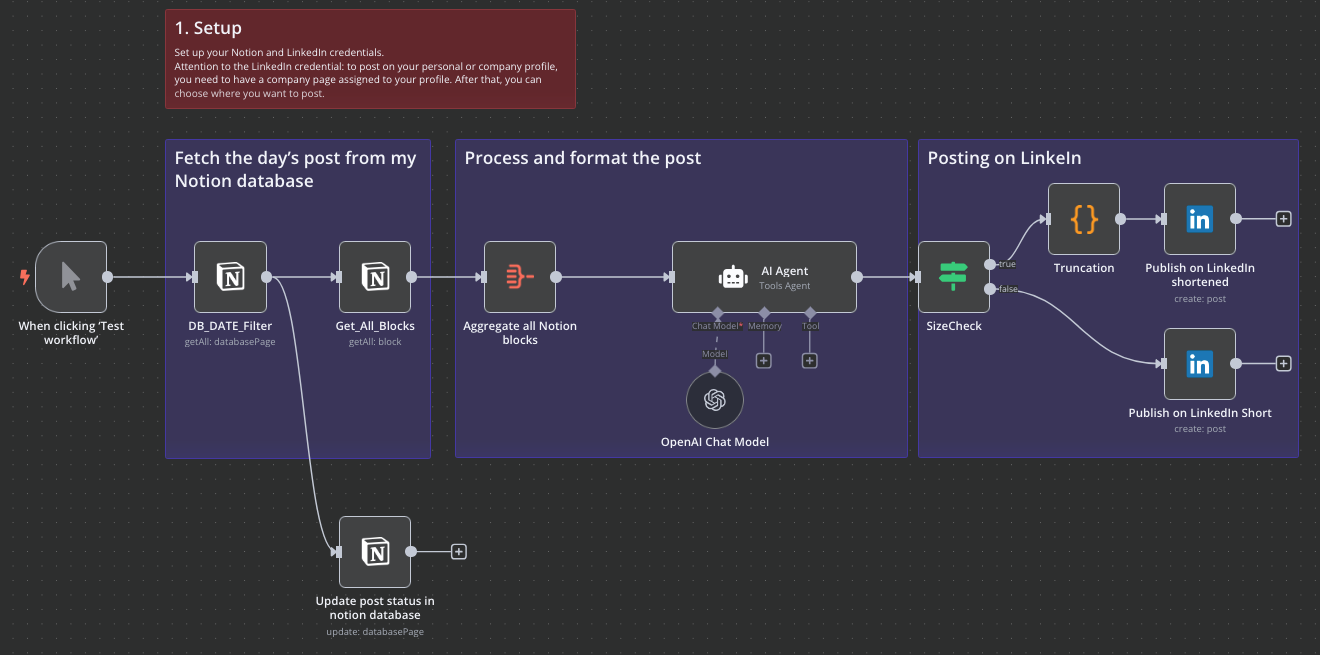
这两年做研发提效、GraphRAG、内部助手,身边最常见的一幕是: 有人拉起一个 n8n,三下五除二搭了个“AI 工作流”,Slack 连上了,Notion 连上了,表面上很热闹,真出了 Bug,没人知道问题出在 prompt、模型、还是某个小小的 if。
后来换个方向:把 Agent 当“服务端内核”,用 Python 写清楚角色、任务、状态、工具调用,围着日志和回放调一阵,再考虑要不要给别人拖拽。这个时候,crewAI 这种东西,就顺眼多了。
一句话:
- n8n 更像“外层编排 + 系统集成平台”;
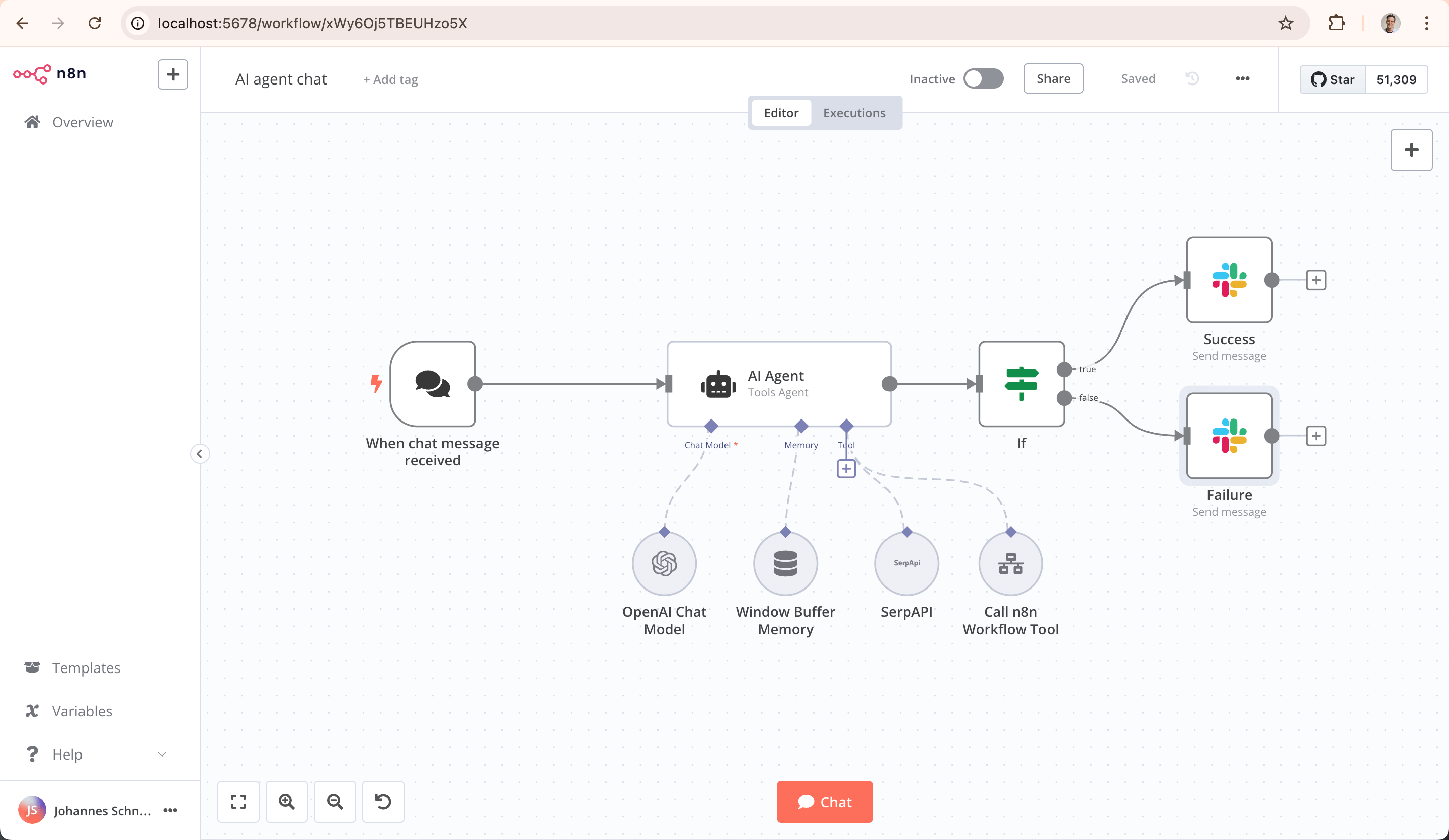
- crewAI 更像“Agent 引擎 + 任务流框架”。
你要造的是发动机,不是仪表盘。至少现在不是。
n8n:好用,但太容易让人“误以为自己已经工程化了”
先肯定一句:n8n 是个非常成熟的自动化平台,400+ 集成、可视化编辑器、自托管、权限、模板,这些对团队落地流程特别友好。
如果你要做的是:
- “有人在工单系统里提了 Bug,就自动去查日志 + 发个总结到飞书”
- “每天早上把埋点数据跑一遍,出个报表发到邮箱”
- “客服对话里叫一下 LLM 帮忙写个总结”
n8n 完全能搞,而且体验很好,拖节点比你写一堆 glue code 快乐多了。
问题出在——你现在玩的,不是这个层级。
假设你要的是:
- GraphRAG:图结构 + 代码依赖 + 文档一锅炖,问一个问题顺着调用链走下去。
- 多 Agent:有人负责检索,有人负责规划,有人负责验证,有人负责改写工具调用。
- 本地模型:DeepSeek / Ollama / 自建推理服务,可控可审计,要能用日志回放每一步。
把这些塞进 n8n,你会发现:
- 状态长得离谱,一个 workflow 承担了“业务流程 + Agent 内部逻辑”,一改就牵一片。
- 历史对话、Agent 记忆、工具调用结果,全混在节点里,要么变成一坨 JSON,要么散在变量上,很难系统性调试。
- 真出问题,你最后还是得回到“自己写个服务”,然后用 n8n 当 HTTP 调用方。
这不怪 n8n,它的设计目标本来就是自动化平台,不是 Agent 引擎。
crewAI:你其实要的是“多进程调度器”,不是“流程图编辑器”
回到 crewAI。它卖点写得很直白:
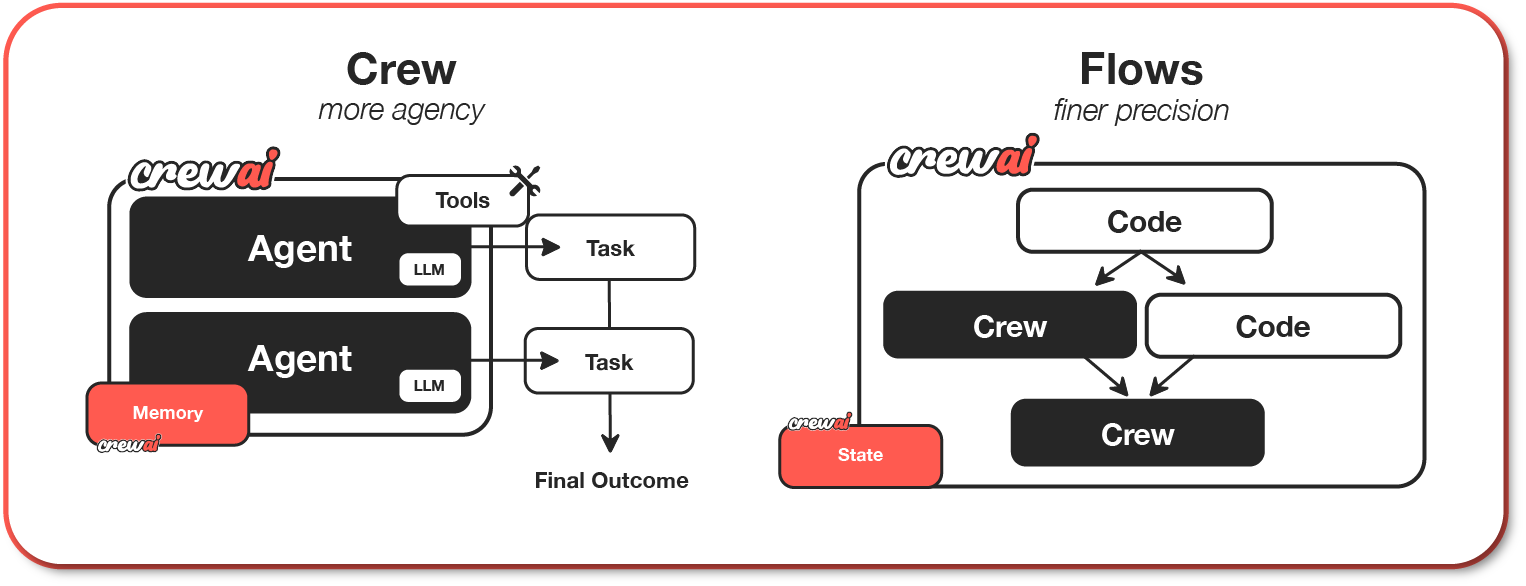
- 纯 Python、多 Agent 框架,独立于 LangChain;
- 有“Crew”(一组 Agent)和“Flow”(事件驱动流程)这两套抽象;
- 默认就考虑了角色、任务、流程、工具、模型接入这些东西。
翻译成人话:
- 你用 YAML / Python 把角色写出来:研究员、分析师、审稿人……
- 每个角色一个 Agent,对应一个或多个 Task;
- 把一堆 Agent + Task 丢进一个 Crew,指定是顺序跑、还是层级跑;
- 再用 Flow 把不同 Crew 串起来,像写后端服务一样写逻辑、写 if-else、写状态机。
关键有两点,特别对你这种搞 GraphRAG / 研发助手的开发者友好:
-
状态和日志在你自己的代码世界里
- 你可以直接把 GraphRAG 的查询、代码解析、检索逻辑写进 Python 函数,挂成工具。
- Agent 的输入输出就是你眼熟的 dict / pydantic 模型,loguru 打日志,pytest 写回归,完全是正常工程套路。
-
“Crew + Flow”这两个抽象,刚好卡在“够用又不太重”的点上
- Crew 解决“多 Agent 怎么协同”:谁先干、谁再干、要不要有个负责人复核。
- Flow 解决“在真实系统里跑起来”的事:定时触发、事件触发、状态路由。你不会被迫一上线就写成一整套庞大的 LangGraph 图,却又比“手写一堆 while True + queue”要健康太多。
对一个想认真折腾 Agent 的开发者来说,这个抽象层级刚刚好。你可以先用它写出“内部 Agent 服务”,等稳定了,再考虑要不要暴露给 n8n 这种外层平台用。
真正的区别:谁当“内核”,谁当“外壳”
如果只是在“选哪个框架”这个层面纠结,其实挺浪费时间。 更实在的问法是:在你的系统里,谁是内核,谁是外壳?
-
内核:
- 负责结构化知识(GraphRAG、知识图谱)、
- 负责复杂任务拆解、多 Agent 协作、
- 负责日志、回放、评测和灰度。 这个东西,应该是 Python 服务、git 管控、可以单元测试,可以做 CI/CD,可以被你骂两句然后认真 refactor 的那种。对你来说,crewAI 比较适合站在这里。
-
外壳:
- 负责把“有点难度的内核能力”包装成“几个 HTTP 接口 / Webhook / 事件通道”,
- 再接 Slack、飞书、Jira、工单系统、数据库,解决“怎么接到现有系统里”的问题。 这块,n8n 是非常爽的,拖几条线就能帮你把新东西接进老系统。
当你把这个层级想明白了,其实“我为什么推荐你先用 crewAI,而不是 n8n”就很好解释:
- 你现在在搭的是内核,而不是给别人看的自动化大屏。
- 你手上最值钱的东西,不是那几个 workflow,而是你对“Agent 怎么拆、GraphRAG 怎么建、日志怎么打、异常怎么兜底”的工程判断。
先把这块打磨出来,哪天真要开给运营 / 产品用,再上 n8n,当一个优雅的外壳,而不是把所有复杂度都塞到节点图里。
如果你现在就要开干,可以这么落一手
最后给几个很落地的小建议,不算“教程”,更像“踩坑总结”:
- crewAI 更像你自己写的“Agent service + orchestration layer”;
- n8n 更像你公司买的一个“自动化平台 + 插件市场”。
这也是为什么,现在不少团队会走一个“内外分层”的套路:
里层用 crewAI 或类似框架,把多 Agent 能力做成一个稳定的 HTTP / gRPC 服务,自己掌握代码、监控和评测体系;外层再用 n8n 这类平台,把这个服务当成一个节点,和 CRM、财务、工单系统一起编排,让非开发同学也能拉流程。
你要是站在“只做一个 side project,快点跑起来”这个角度,n8n 确实很香:两个小时搞一个 AI 工作流的案例,不是夸张的故事,而是官方和社区经常挂在嘴边的节奏。 但如果你心里已经在想:“这套 Agent 以后要不要上生产、要不要做 A/B、要不要做 SLA 和报警?”——那就老老实实先把内核写在 crewAI 里,把自己当成是给团队造基础设施,而不是造一个玩具。
最后啰嗦一句,留给开发者
选型这种事,很容易被“哪个更火”“哪个视频多”带节奏。n8n 星多、集成多,这是事实;crewAI 这两年在多 Agent 圈子里冒头也很快,这也是事实。 但对一个写代码的开发者来说,更关键的问题只有一个:一年之后,谁在维护这套系统?
如果答案是“主要还是我和我的同事”,那你至少要有一个 code-first 的、多 Agent 友好的内核,这一票大概率会投给 crewAI。等内核稳了,再上 n8n 这种平台,把它当壳子包出去,顺手也不迟。
反过来,如果你现在就是在给一群非技术同学服务,他们要的就是“今天能改个流程、明天能多拉一个节点”,那就别纠结 crewAI 了,先把 n8n 玩熟,给自己省点命。
