1、线性回归
定义:线性回归是一种用于建立变量之间线性关系的统计模型。它试图找到一个线性函数,使得该函数能够最好地描述自变量(解释变量)与因变量(响应变量)之间的关系,从而可以根据自变量的值来预测或解释因变量的值。
2、线性回归主要数学公式
线性回归主要是将训练数据拟合成一个多元线性函数,若需要拟合的数据有n个特征属性值,有m个数据,一个标签,那么线性回归就将其拟合成一个n元线性函数hθ(x0i,x1i,x2i,...,xji)=hθ(xi)=(θ)T⋅xi(其中xi=(x0i,x1i,x2i,x3i,...,xji)T,θ=(θ0,θ1,θ2,θ3,...,θj)T,i表示第i个数据,总共有m个,i=1,2,3,...,m,j表示第j个特征值,总共有n个,j=0,1,2,3,...,n,其中第0个特征认为是线性函数的常数项,故x0i恒等于1),比如:现有三个属性:房子面积x1,房子楼层x2,房子地段x3。一个标签:房子价格y。那么线性回归拟合的线性函数为:y=θ1x1+θ2x2+θ3x3+θ0,其中θ0,θ1,θ2,θ3为拟合的目标,通过梯度下降找到最佳的θj。
使用梯度下降进行优化损失函数,使得损失函数最小:
目标损失函数:J(θ)=2m1∑i=1m(yi−hθ(xi))2
梯度下降公式:∂θj∂J(θ)=−m1∑i=1m(yi−hθ(xi))xji
批量梯度下降:随机找到一个初始θj(j是每个特征对应的j,如x1对应的j是1)然后逐步更新θj,根据以下公式θj′=θj−∂θj∂J(θ)直到找到最小的θj(每一个θj同时更新)
随机梯度下降:随机找到一个初始θj(j是每个属性对应的j,如x1对应的j是1)然后逐步更新θj,根据以下公式θj′=θj+(yi−hθ(xi))xji直到找到最小的θj(每一个θj同时更新)
小批量梯度下降(一般用这个):随机找到一个初始θj(j是每个属性对应的j,如x1对应的j是1)然后逐步更新θj,根据以下公式θj′=θj−α∂θj∂J(θ)(α为学习率)直到找到最小的θj(每一个θj同时更新)
3、真实数据展示
数据说明:五组数据,每组数据有4个特征值:
| 特征值1 | 特征值2 | 特征值3 | 特征值4 | 标签 |
|---|
| 1.2 | 2.5 | 3.7 | 4.1 | 12.3 |
| 2.1 | 3.2 | 4.5 | 5.3 | 16.8 |
| 3.3 | 4.7 | 5.9 | 6.2 | 20.5 |
| 4.2 | 5.1 | 6.7 | 7.3 | 24.8 |
| 5.4 | 6.3 | 7.2 | 8.1 | 29.6 |
以小批量梯度下降为准,特征值1,特征值2,特征值3,特征值4为x1,x2,x3,x4,标签为y,目标:找到一个函数:y=θ1x1+θ2x2+θ3x3+θ4x4+θ0,于是假设初始θ1=1,θ2=1,θ3=1,θ4=1,θ0=1,α=0.1,于是,以更新θ1为例,∂θ1∂J(θ)=−m1∑i=1m(yi−hθ(xi))x1i=−51((12.3−(1×1.2+1×2.5+1×3.7+1×4.1+1))×1.2+(16.8−(1×2.1+1×3.2+1×4.5+1×5.3))×2.1+(20.5−(1×3.3+1×4.7+1×5.9+1×6.2))×3.3+(24.8−(1×4.2+1×5.1+1×6.7+1×7.3))×4.2+(29.6−(1×5.4+1×6.3+1×7.2+1×8.1))×5.4)=−1.998,按照小批量梯度下降公式可得θ1′=θ1−α∂θ1∂J(θ)=1−0.1×(−1.998)=1.1998,同时,按照此θ1更新,更新θ0,θ2,θ3,θ4(在更新θ0时,将所有xji=1),于是,就得到了第一次更新的θ0,θ1,θ2,θ3,θ4,接下来,更新n次,使得J(θ)最小。
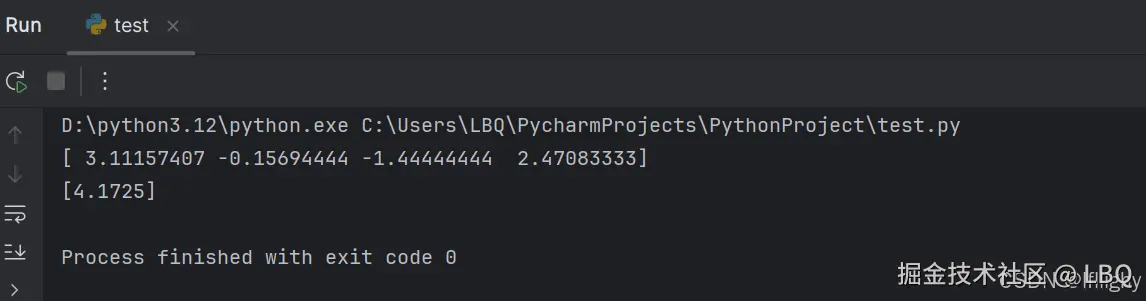
代码实现:
import numpy as np
from sklearn.linear_model import LinearRegression
X = np.array([[1.2,2.5,3.7,4.1],
[2.1,3.2,4.5,5.3],
[3.3,4.7,5.9,6.2],
[4.2,5.1,6.7,7.3],
[5.4,6.3,7.2,8.1]])
y = np.array([[12.3],[16.8],[20.5],[24.8],[29.6]])
reg = LinearRegression()
reg.fit(X,y)
w_ =np.array(reg.coef_)
w = w_.flatten()
b = np.array(reg.intercept_)
print(w)
print(b)
结果:
4、多项式回归
定义:多项式线性回归是线性回归的一种扩展,通过引入特征的高次项(如x2,x3,...)来拟合非线性关系。虽然输入特征被非线性变换,但模型对参数θ仍然是线性的,即将原本的n个属性通过两两组合的方式变成∑i=1i=kCn+i−1i个属性,其中k扩展的最高次项的次数,比如:有三个属性:x1,x2,x3,将其扩展到最高次项的次数为2,那么,它就变成Cn1+Cn+12=C31+C3+12=9项,分别为:x1,x2,x3,x12,x22,x32,x1x2,x1x3,x2x3,最后把这9项当成9个属性作线性回归,就得到了多项式线性回归的函数。
5、正则化
1)lasso回归:
Lasso 回归,即最小绝对收缩和选择算子回归(Least Absolute Shrinkage and Selection Operator),是一种用于线性回归模型的正则化方法,为的是防止过拟合,即回归曲线完美拟合训练数据,但是对测试数据效果预测效果不理想的情况。lasso回归增加了惩罚项:λ∑j=1n∣θj∣(n表示特征数量)。于是,目标损失函数就变成:J′(θ)=2m1∑i=1m(yi−hθ(xi))2+λ∑j=1n∣θj∣,对于该损失函数的优化,使用坐标轴下降法(coordinate descent)优化θ0不需要正则优化,步骤如下:
1.把目标损失函数展开: J′(θ)=2m1∑i=1m(yi−hθ(xi))2+λ∑j=1n∣θj∣=2m1∑i=1m(∑j=1nθjxji+θ0−yi)2+λ∑j=1n∣θj∣
2.固定其他θj,先优化其中的θl,l∈[1,n],求其对于θl的偏导数: ∂θl∂J(θ)=m1∑i=1m(∑j=1nθjxji+θ0−yi)xli+λ∂θl∂∣θl∣=m1∑i=1m(∑j=1,j=lnθjxji+θ0−yi+θlxli)xli+λ∂θl∂∣θl∣=m1∑i=1m(∑j=1,j=lnθjxji+θ0−yi)+m1∑i=1mθl(xli)2+λ∂θl∂∣θl∣(正则项 λ∂θl∂∣θl∣ 需要分情况讨论),由于先固定除θl之外的其他θj故把第一项m1∑i=1m(∑j=1,j=lnθjxji+θ0−yi)当作常数,作记号为Cl,第二项m1∑i=1mθl(xli)2是优化项,将m1∑i=1m(xli)2 作记号为 Al,显然 Al>0,一般情况下不太可能等于0,于是认为它是大于0的,于是原式就变∂θl∂J(θ)=Cl+Alθl+λ∂θl∂∣θl∣
3.分情况讨论∂θl∂J(θ):
a.当θl>0时,∂θl∂J(θ)=Cl+Alθl+λ (∣θl∣=θl)
b.当θl<0时,∂θl∂J(θ)=Cl+Alθl−λ (∣θl∣=−θl)
c.当θl=0时,∂θl∂J(θ)∈[Cl+Alθl−λ,Cl+Alθl+λ] (∂θl∂∣θl∣θl→0−=Cl+Alθl−λ,∂θl∂∣θl∣θl→0+=Cl+Alθl+λ)
4.另偏导数∂θl∂J(θ)=0 解得:
a.当θl>0时,θl=Al−Cl−λ>0因为 Al>0 故 −Cl−λ>0,即 Cl<−λ
b.当θl<0时,θl=Alλ−Cl<0因为 Al>0 故 λ−Cl<0,即 Cl>λ
c.当θl=0时,Cl∈[−λ,λ]
5.最终θl更新的结论:
a.当Cl<−λ时,θl=Al−Cl−λ
b.当Cl>λ时,θl=Alλ−Cl
c.当Cl∈[−λ,λ]时,θl=0
6.最终所有的θj更新: 将l取1,2,3,4,...,n,每次取l为其中一个值,固定其他值,直至所有的除θ0外的θj都更新,最后就得到最优解
7.对于θ0的更新:因为正则项里面θj中j是从1到n,所以更新θ0的方法与没有正则项的目标损失函数一样的优化。
2)岭回归:
岭回归(Ridge Regression)是一种用于处理线性回归模型中多重共线性问题的有偏估计方法,与lasso回归一样,都是为了防止过拟合,于是增加了惩罚项:2λ∑j=1nθj2(n表示特征数量)。于是,目标损失函数就变成:J′(θ)=2m1∑i=1m(yi−hθ(xi))2+2λ∑j=1nθj2,想要优化损失函数,使用梯度下降法找到最优的θ=(θ0,θ1,θ2,...,θn),其中θ0不需要正则优化。于是,使用小批量梯度下降,θj′=θj−α∂θj∂J′(θ)=θj−α(−m1∑i=1m(yi−hθ(xi))xji+λθj)=θj−α(m1∑i=1m(hθ(xi)−yi))xji+λθj)=(1−αλ)θj−α(m1∑i=1m(hθ(xi)−yi))xji)=(1−αλ)θj−α∂θj∂J(θ),其中1−αλ 是正则项。对于θ0的更新,因为正则项里面θj中j是从1到n,所以更新θ0的方法与没有正则项的目标损失函数一样的优化。


