import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
df = pd.read_csv("地铁客流数据.csv")
df['总客流'] = df['进站人数'] + df['出站人数']
print(df)
mean_in = df.groupby(['线路', '时段 (早高峰/平峰/晚高峰)'])['进站人数'].mean()
print(mean_in)
df['日期'] = pd.to_datetime(df['日期'])
df['月份'] = df['日期'].dt.month
sum_month = df.groupby('月份')['总客流'].sum()
print(sum_month)
plt.bar(sum_month.index, sum_month)
plt.show()
corr = df['进站人数'].corr(df['出站人数'])
print(corr)
plt.rcParams['font.sans-serif'] = ['SimHei']
df = df.sort_values('总客流', ascending=False)
print(df)
top5 = df[:5].reset_index()
print(top5)
plt.bar(top5['站点名称'], top5['总客流'])
plt.show()
df = pd.read_csv(
'网约车订单数据.csv',
index_col='订单ID'
)
df['总费用'] = df['起步价 (元)'] + df['行程距离 (km)'] * df['里程费 (元/km)'] + df['附加费 (元)']
print(df)
df['出发时间'] = pd.to_datetime(df['出发时间'])
df['小时'] = df['出发时间'].dt.hour
df['订单量'] = [1 for i in range(df.shape[0])]
state = df.groupby('小时').agg({
'订单量':'sum',
'行程距离 (km)':'mean'
})
print(state)
total = df['总费用'].agg(['max', 'min', 'mean', 'std'])
print(total)
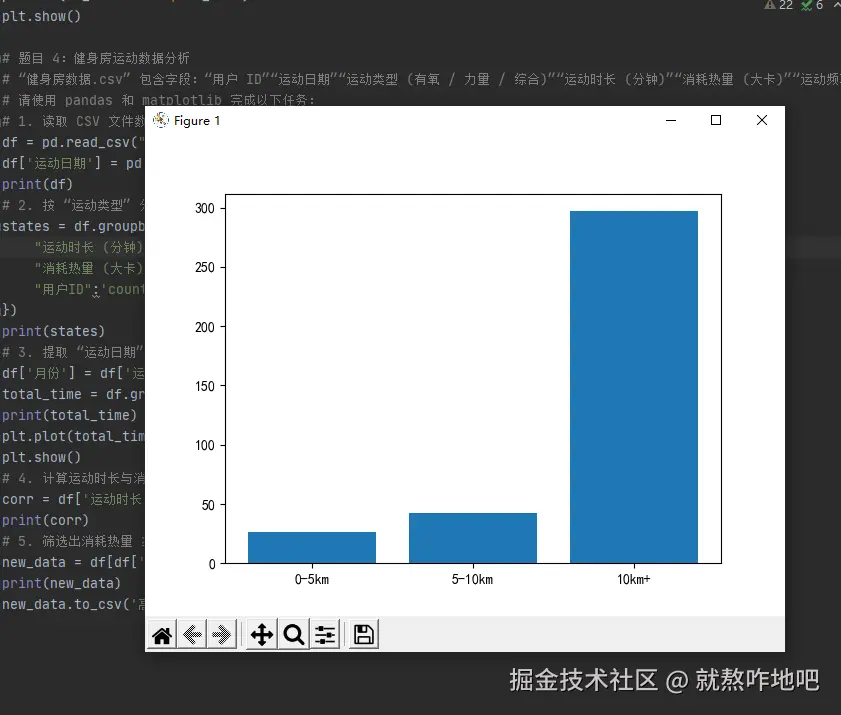
df['距离分组'] = pd.cut(
df['行程距离 (km)'],
bins=[0, 5, 10, np.inf],
labels=['0-5km', '5-10km', '10km+'],
right = False
)
print(df)
group_data = df.groupby('距离分组').agg({
'订单量':'count',
'总费用':'mean'
})
print(group_data)
plt.bar(group_data.index, group_data['订单量'])
plt.show()
plt.bar(group_data.index, group_data['总费用'])
plt.show()
new_data = df[df['行程距离 (km)'] >= 10]
new_data.to_csv("长途订单.csv")
df = pd.read_csv("体检数据.csv")
df['是否高血压'] = np.where((df['收缩压 (mmHg)'] >= 140)|(df['舒张压 (mmHg)']>=90), '是', '否')
print(df)
df['年龄分组'] = pd.cut(
df['年龄'],
bins=[17, 30, 50, np.inf],
labels=['18-30', '31-50', '50+'],
right=False
)
rate = df.groupby(['性别', '年龄分组'])['是否高血压'].apply(lambda x:(x=='是').mean()).reset_index()
print(rate)
corr = df['空腹血糖 (mmol/L)'].corr(df['胆固醇 (mmol/L)'])
print(corr)
df_mean = df.groupby('性别').agg({
"收缩压 (mmHg)":'mean',
'舒张压 (mmHg)':'mean',
'空腹血糖 (mmol/L)':'mean'
})
df_var = df.groupby('性别').agg({
"收缩压 (mmHg)":'var',
'舒张压 (mmHg)':'var',
'空腹血糖 (mmol/L)':'var'
})
print(df_var)
print(df_mean)
df_male = df.groupby('性别')['收缩压 (mmHg)'].mean()
print(df_male)
plt.bar(df_male.index, df_male)
plt.show()
df = pd.read_csv("健身房数据.csv")
df['运动日期'] = pd.to_datetime(df['运动日期'])
print(df)
states = df.groupby('运动类型 (有氧/力量/综合)').agg({
"运动时长 (分钟)":'mean',
"消耗热量 (大卡)":'mean',
"用户ID":'count'
})
print(states)
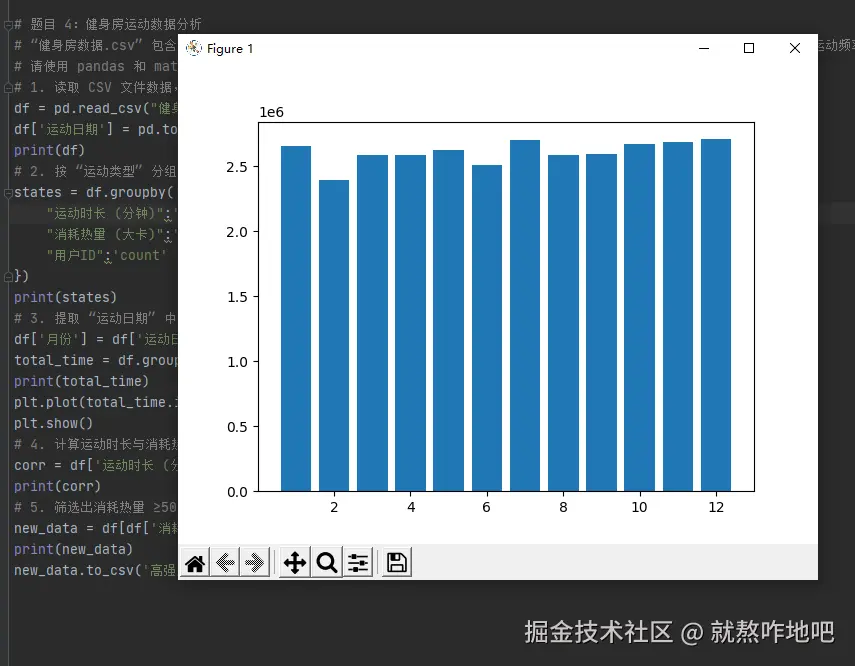
df['月份'] = df['运动日期'].dt.month
total_time = df.groupby('月份')['运动时长 (分钟)'].sum()
print(total_time)
plt.plot(total_time.index, total_time)
plt.show()
corr = df['运动时长 (分钟)'].corr(df['消耗热量 (大卡)'])
print(corr)
new_data = df[df['消耗热量 (大卡)'] >= 500]
print(new_data)
new_data.to_csv('高强度运动记录.csv')