

2024 年 11 月,Anthropic 公司推出了 MCP 协议。从今天回望,它无疑是一次极为成功的尝试。各种 MCP Server 相继涌现,其中不少极大地提升了 Agent 的能力。更重要的是,这些已经构建好的 MCP Server 可以被轻松地集成进自己的 Agent,实现能力的快速扩展。工程师们借助他人的成果,得以在更高层次上进行创新。这让智能体的开发进入了“组合式创新”的阶段。许多人将 2025 年称为“Agent 元年”——而 MCP,无疑在其中扮演了关键角色。
时隔将近一年,Anthropic 再度推出了 Skills。 如果说 MCP 让 LLM 能够与外部世界交互,模块化地扩展了 Agent 的能力边界,那么 Skills 的推出又意味着什么?从官方示例来看,Skills 能完成的功能,似乎完全可以用 MCP 来实现。
那么,Skills 真的是不可或缺的吗?
要回答这个问题,我们需要把视角转向另一个更底层的主题——从 Prompt Engineering 到 Context Engineering 的转变。
Prompt Engineering
当人们第一次接触大语言模型(LLM)时,往往会被它展现出的“智能”所震撼。只需输入一句自然语言,它就能流畅地回答问题、生成文本,甚至编写代码。然而,这种惊艳感很快被困惑所取代——同样的问题,不同的表达方式往往得到截然不同的答案。模型有时表现得像专家,有时又像一个胡言乱语的孩子。人们逐渐意识到:让 LLM 按照自己的意图行事,并非只要“问得清楚”这么简单。于是,“如何提问”本身,成了一门新的学问——Prompt Engineering。
人们开始尝试在一次 Prompt 中提供尽可能完整的信息:任务目标、操作规则以及过往经验,希望能一次性让 LLM 顺利完成任务。很快,大家发现这绝非易事——编写 Prompt 是一门真正的“技术活”。各种技巧相继出现:有人在提示中加入角色设定,让模型“扮演”专家、顾问或特定身份;有人精心拆解任务步骤,要求模型“逐步推理”;也有人设计模板化的提示,例如“少样本(few-shot)提示”、结尾加上“请用中文回答”、“请详细解释原因”等。甚至还有人把 Prompt 写成一整篇操作手册,规定输出格式、语气风格、思维路径,生怕模型偏离预期。从“提示链(Chain-of-Thought Prompting)”到“自我一致性(Self-Consistency)”,社区中层出不穷的技巧几乎让人相信——只要找到那句“完美的咒语”,模型就能被完全驯服。
然而,正因为如此,Prompt 也变得越来越复杂、越来越冗长。 现实世界始终在变化,过往经验只能作为参考,无法囊括所有情境。无论一个 Prompt 写得多么完整、多么精巧,它都无法像全知的神那样预先规划一切。Prompt Engineering 在真实任务中的表现因此往往有限且不稳定。更糟糕的是,冗长的 Prompt 在长任务的每一轮交互中都会占用大量 Token,带来可观的计算成本。人们开始意识到——Prompt Engineering 的边际价值,正在迅速递减。
Context Engineering
Context Engineering 是一种动态地为模型构建、维护、管理上下文的工程化方法,旨在让模型在复杂环境中持续保持对任务的理解。大约在今年六月开始,Context Engineering 这个概念迅速引发了广泛讨论。一个概念之所以容易被接受,往往是因为人们早已在无意识中实践它——只是后来,才为这些做法找到了一个恰当的名字。
从本质上看,Prompt Engineering 的早期探索,都是在尝试为模型提供尽可能多的上下文,以弥补其世界状态缺失。只是,这种“上下文补全”是通过手动输入实现的。问题在于,Prompt 是静态的,而真实的任务情境却始终在变化——信息流动、目标调整、环境反馈都无法被一段静态的文字完全涵盖。因此,人们也想出了一系列方法,尝试去解决这个问题。于是,模型的上下文构建从静态提示,开始向动态管理过渡——这正是 Context Engineering 的起点。
RAG
RAG 的出现,是对大语言模型知识边界的一次突破,换句话说,是对模型上下文知识的一种动态补充。
众所周知,大语言模型的知识来自于训练数据,这意味着它的知识是静态的、有截止日期的。当用户询问“我们公司上季度的销售数据”或是“昨天发布的新产品特性”时,模型无法回答——这些信息根本不在它的训练数据中。这正是 Prompt Engineering 的天花板:无论提示多巧妙,模型不知道的东西,永远问不出来。
RAG 提供了一个优雅的解决方案:在推理时动态检索相关信息,并将其注入到模型的上下文中。
图 1:朴素RAG系统
上图所示的是一个最朴素的 RAG 系统,在实际应用中,一个表现良好的 RAG 系统要复杂得多。
Tools
如果说 RAG 让模型能够“看到”更多信息,那么 Tools 则让模型能够“做到”更多事情。 在过去,大语言模型只能基于已有的文本生成回答,它是一个纯粹的“语言回答者”。然而,现实世界的任务往往需要与外部系统交互——查询数据库、调用 API、操作文件系统、执行代码。这些能力的缺失,使得 LLM 在真实场景中显得力不从心。
工具调用机制的引入,改变了这一局限。模型在推理过程中可以根据任务需要主动调用外部工具,实现从“被动回答”到“主动行动”的转变。目前,几乎所有主流的 AI 应用框架都支持这一能力,常见的使用场景包括数据库查询、API 调用、文件处理、代码执行、邮件发送、数据分析等。工具的引入不仅扩展了模型的边界,也让“语言”成为操控现实系统的一种通用接口。
通过工具调用,模型的能力边界被重新定义,而下一个关键问题是——如何让这些能力在时间维度上得以延续。
Memory
Memory 解决的是上下文在时间维度上的持久化问题。
大语言模型本质上是无状态的——每次对话都是独立的推理过程。这在技术上简洁优雅,但在用户体验上却存在明显的断层。用户期望 AI 能够记住之前交流过的信息,就像与一个真实的人对话一样。如果每次对话都要重新解释背景,这样的交互体验显然难以接受。
Memory 系统正是为了弥合这个 gap 而设计的。它可以分为两个层次来理解:
短期记忆处理单次对话中的上下文维护。这相对直接:系统保留当前会话的所有历史消息,每次生成响应时,都会将之前的对话历史包含在 context 中。这使得模型能够理解指代关系、保持话题连贯性。当用户说“把它改成红色”时,模型知道“它”指的是之前提到的那个对象。
长期记忆则要复杂得多。它需要在会话结束后保存关键信息,并在未来的对话中适时检索和使用这些内容。这涉及几个技术挑战:哪些信息值得保存?如何高效组织?何时检索?
对此,业界已有不少探索。其中 Mem0 是一个较为优秀的实现。它意识到,Memory 中过多的内容一方面会占用大量 Token,增加成本;另一方面,冗余信息在 context 中会产生噪音,影响 Agent 完成任务的质量。为此,它将大量工作用于信息的更新、整合与删除。
换句话说,Mem0 让记忆真正具备了遗忘与重构的能力——这正是人类心智模式的重要特征。这也给 Context Engineering 带来启示:保持信息的有效性和推理的效率至关重要,不能无节制地扩充 Context。
图 2:Mem0 系统架构概览
RAG、Tools、Memory 这三种技术,从不同角度解决了同一个核心问题:如何为大语言模型提供恰当的、充分的上下文。RAG 从外部知识库检索信息,Tools 从系统执行中获取信息,Memory 从历史交互中提取信息。它们共同构成了 Context Engineering 的技术基础。
MCP
2024 年 11 月,MCP 问世。从 MCP 的全称 Model Context Protocol,我们能了解到两个事实。第一,“context for model” 这个概念在那时就已进入讨论。第二,MCP 是一个协议,它定义了模型与外界交互的方式,但不限制交互的内容。MCP 定义了三种资源:resources、tools、prompt。利用这三种资源,RAG、Tools 和 Memory 的功能都可以实现。
有一种声音说要用 MCP 来替代 RAG。这句话是错误的。MCP 可以用来实现 RAG,从 Agent 的角度来看,可以用 MCP 的方式来替代最初的 retrieve。但不管如何实现,从更一般的角度看,它依旧是 RAG。类似地,说要用 MCP 来替代 Tools,也是错误的。
很多人觉得 2025 年是 Agent 元年,如果这是真的,那么 MCP 功不可没。在 MCP 之前,构建 Agent 是个体力活。想让 Agent 查数据库,得自己写集成代码;想搜索网页,再写一套。更麻烦的是,这些代码往往与特定框架绑定,换个框架就得重写。每个开发者都在造轮子,GitHub 上同一个功能有几十种实现,彼此无法复用。
MCP 改变了游戏规则。它定义了一套标准协议,规范了 Agent 与外部工具的交互方式。这个标准化带来的不只是技术上的统一,更是生态上的可能性。
当有人写了一个 GitHub 集成的 MCP Server,所有人都能用。有人做了 Slack 接入,你的 Agent 立刻就能处理 Slack 消息。不需要改代码,启用即可。这种能力的可复用性,是 MCP 最大的价值。
从根本上说,MCP 让 Context 的构建变得更工程化——而 Context,正是智能体得以存在的核心。
Skills
既然 MCP 如此强大,那为什么 Anthropic 还要继续推出 Skills 呢?原因仍然可以追溯到 Context Engineering。
MCP 本身的实现方式会带来一个问题:它会大量占用 context 中的 Token 数量。对于短任务尚可接受,但对于长任务而言,每次都会参与大语言模型的推理。与上文提到的 Memory 类似,context 中过多的无关信息,一方面会增加成本,另一方面也会影响任务性能。因此需要做减法。
如果说 Context Engineering 是构建 Agent 的重要方向,那么 Context Management 决定了能走多远。而 Skills 就是 Anthropic 的一个重要实践和方案,它是一种“任务知识模块化”的尝试——让经验以结构化的方式可加载、可共享。
Skills 本质上是存放在目录中的知识文件。每个 Skill 是一个独立目录,核心是其中的 SKILL.md 文档。这个文档沉淀了:
- 执行该类任务时的成功经验和容易踩的坑;
- 相关工具的调用建议和参数设置技巧;
- 质量把关要点和性能优化方向;
- 可直接参考的代码片段和模板。
---
name: my-skill-name
description: A clear description of what this skill does and when to use it
---
# My Skill Name
## Core Principles
- Principle 1: The fundamental approach to this task
- Principle 2: Key philosophy that guides implementation
## Common Pitfalls
- ❌ Mistake 1: What beginners often do wrong
- ✅ Solution: The correct approach to avoid these
## Code Template
```
// Basic structure for this type of task
function exampleImplementation() {
// Step 1: Setup
// Step 2: Core logic
}
```
## Examples
- Example usage 1: Simple case
- Example usage 2: Complex scenario
## Guidelines
- When to use this approach vs alternatives
- How to handle edge cases
- Performance considerations
## Quality Checklist
- [ ] Validation point 1
- [ ] Validation point 2
- [ ] Output meets requirement X
示例:SKILL.md 文件的基本结构
关键差异在于“时机” :Skills 采用延迟加载策略,初始状态下只有 name 和 description 会包含在上下文中。只有当 LLM 识别到需要处理特定任务时,才会调用 file_read 读取相应的 SKILL.md。假设一个 Skill 中需要调用 10 个 Tool,这些 Tool 的签名信息只有在被使用时才会加载到 context 中。而如果不使用 Skill,仅依赖 MCP,Agent 启动时这 10 个 Tool 的完整签名信息就必须全部加载到 Context 中。
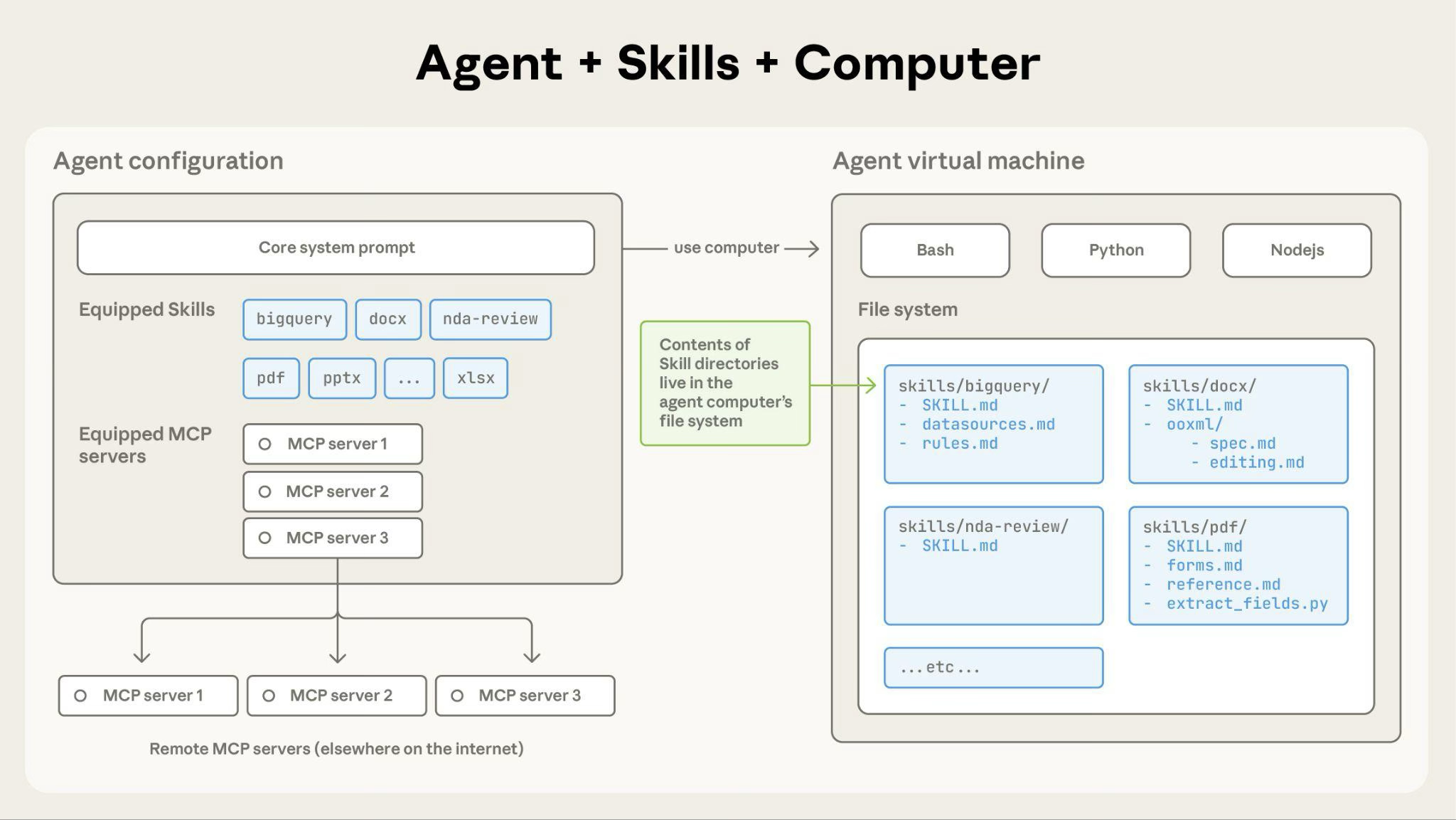
图 3:Agent Skills 架构
那么,如果将 MCP 的 Tool 做成高度封装的场景化服务,是否也可行?
从功能上看也是可行的。但即便如此,MCP 消耗的 Token 依旧大于 Skills。因为 MCP 的设计天生会导致更多信息被加入到 context 中。它们的完整签名信息必须始终存在于上下文中,包括工具名称和功能描述、参数 schema(类型、必填项、取值范围等),以及返回值格式说明。另一个问题是,如果 MCP 是高度场景化的,那它也就失去了灵活组装的优势,也与其“每个 Tool 只做好一件事”的设计哲学相左。
让我们回到开头的问题:Skills 真的是不可或缺的吗?我认为,未必如此。 如果你所构建的 Agent 尚未触及性能瓶颈,或者还处于验证阶段、尚未进入大规模使用,那么 MCP 已经足够。此时,技术验证与业务赋能才是更重要的目标,项目初期的一些“粗放式”管理完全可以接受。
对于像 Anthropic 这样的成熟的大型公司而言,情况就不同了。他们提供的大多是包月制的服务模型,在这种模式下,节省 Token 成本至关重要。减少 Token 占用不仅能显著降低成本,也能在长任务中提升模型推理的质量与稳定性。而质量的提升,又会进一步减少任务重复次数,从而在循环中持续降低整体成本。如果你们做的也是 Agent 平台之类的工作,实现类似 Skills 的功能是非常有意义的。
虽然 Skills 是当前阶段的一个优秀实践,但 Context Engineering 的探索还在继续。无论是 Subagent、Tools、MCP 还是 Skills,它们之间都存在一定的共性——本质上,都是在不断扩展 LLM 的能力边界,是 Context Engineering 的不同实践形态。而 Skills,可以看作是对 Context Engineering 的一次深度优化与精炼尝试。
随着模型的发展与实践的深入,人们必然会遇到新的问题。为了解决这些问题,我们会创造新的技术;而新的技术,又会带来新的挑战——这是一个持续演化、循环往复的过程。但有一点短期内不会改变: Agent 的研究,将会在模拟人类认知深层结构的方向上不断深入。
参考资料
- LlamaIndex: Understanding RAG
- arXiv: Paper 2504.19413
- Anthropic: Agent Skills Documentation
- Eric Ma: Exploring Skills vs MCP Servers
