

💖💖作者:计算机毕业设计小途 💙💙个人简介:曾长期从事计算机专业培训教学,本人也热爱上课教学,语言擅长Java、微信小程序、Python、Golang、安卓Android等,开发项目包括大数据、深度学习、网站、小程序、安卓、算法。平常会做一些项目定制化开发、代码讲解、答辩教学、文档编写、也懂一些降重方面的技巧。平常喜欢分享一些自己开发中遇到的问题的解决办法,也喜欢交流技术,大家有技术代码这一块的问题可以问我! 💛💛想说的话:感谢大家的关注与支持! 💜💜 网站实战项目 安卓/小程序实战项目 大数据实战项目 [深度学习实战项目](blog.csdn.net/2501_928086…
spm=1001.2014.3001.5482)
@TOC
基于大数据的中风患者数据可视化分析系统介绍
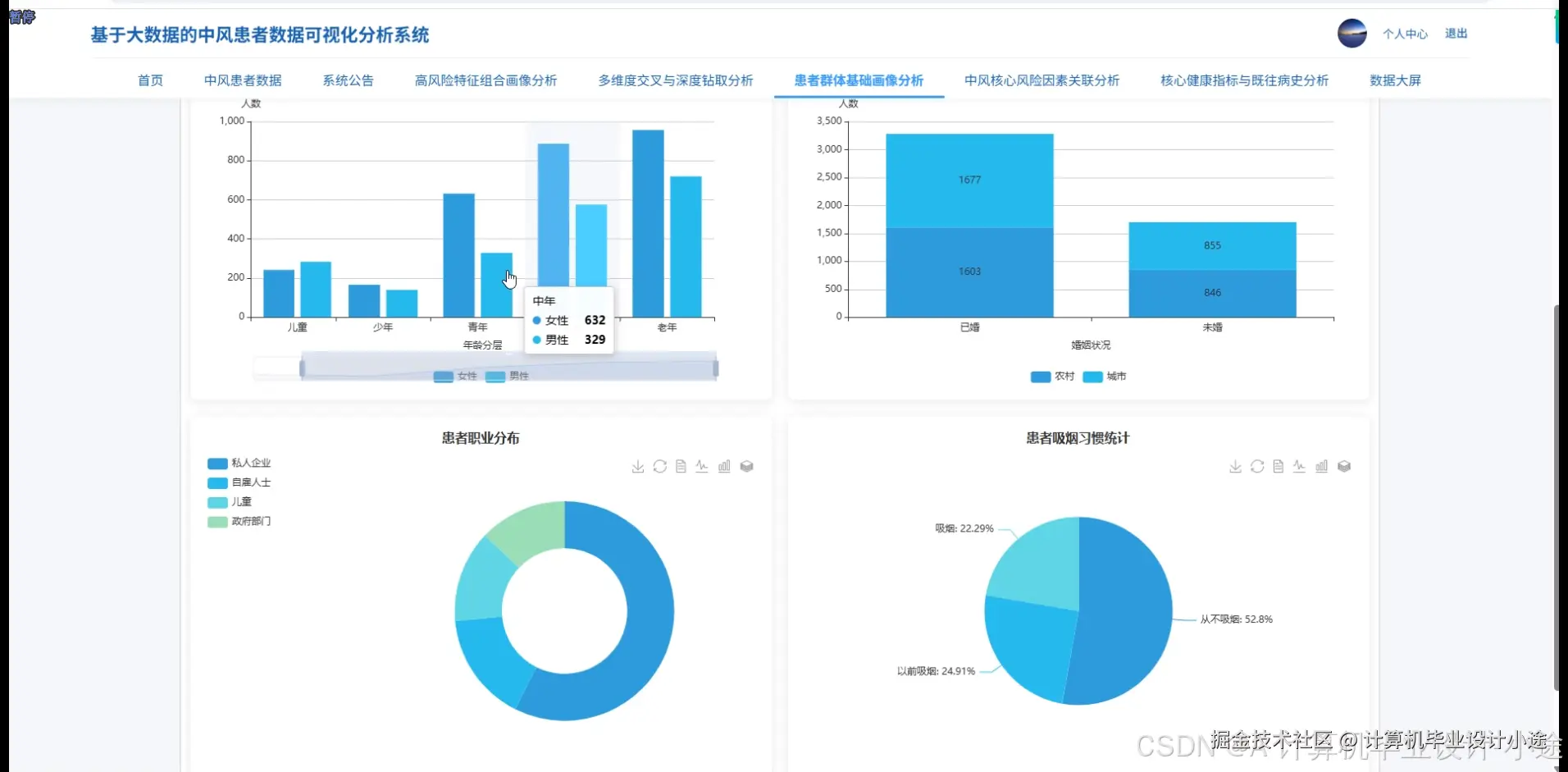
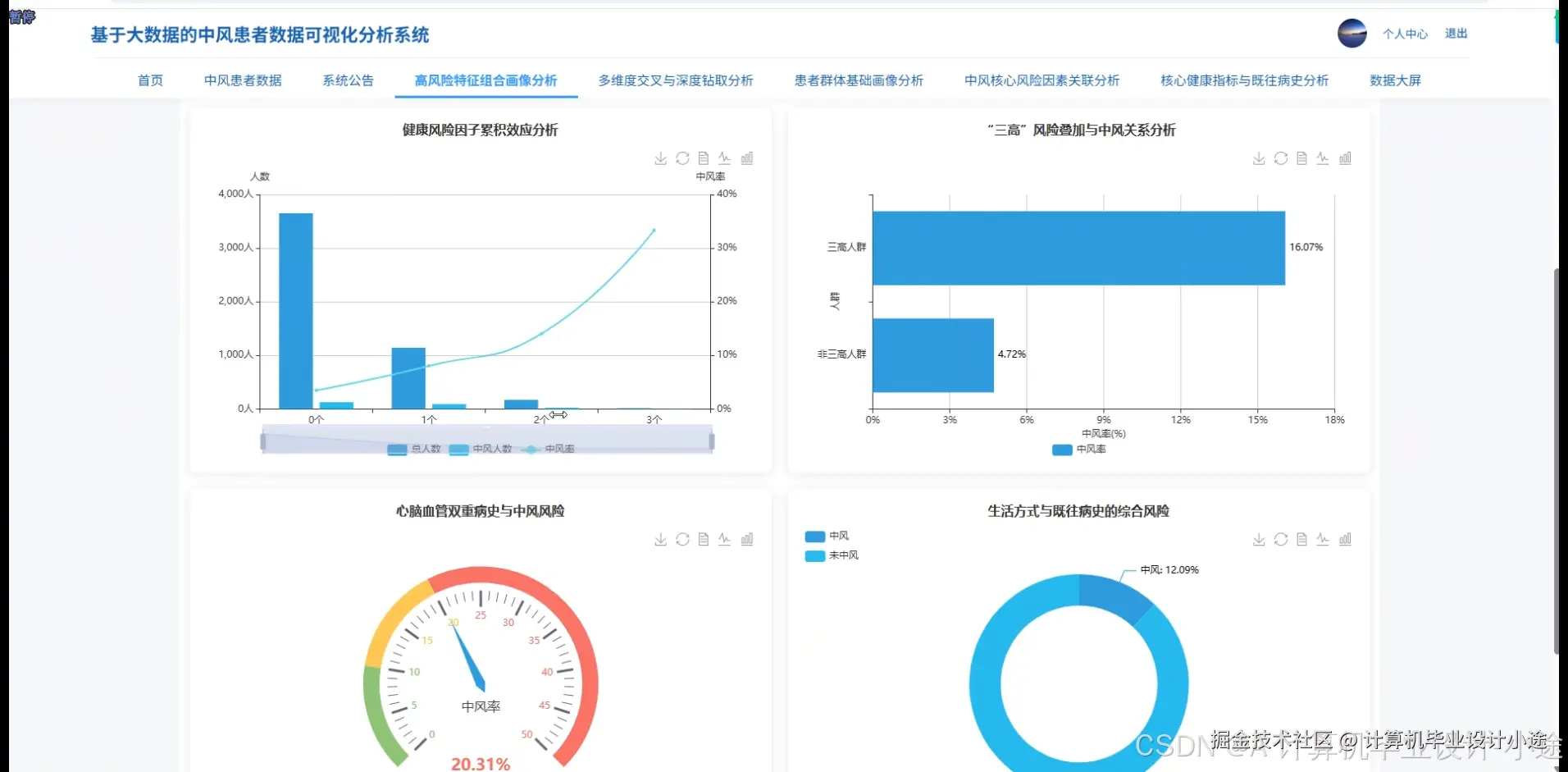
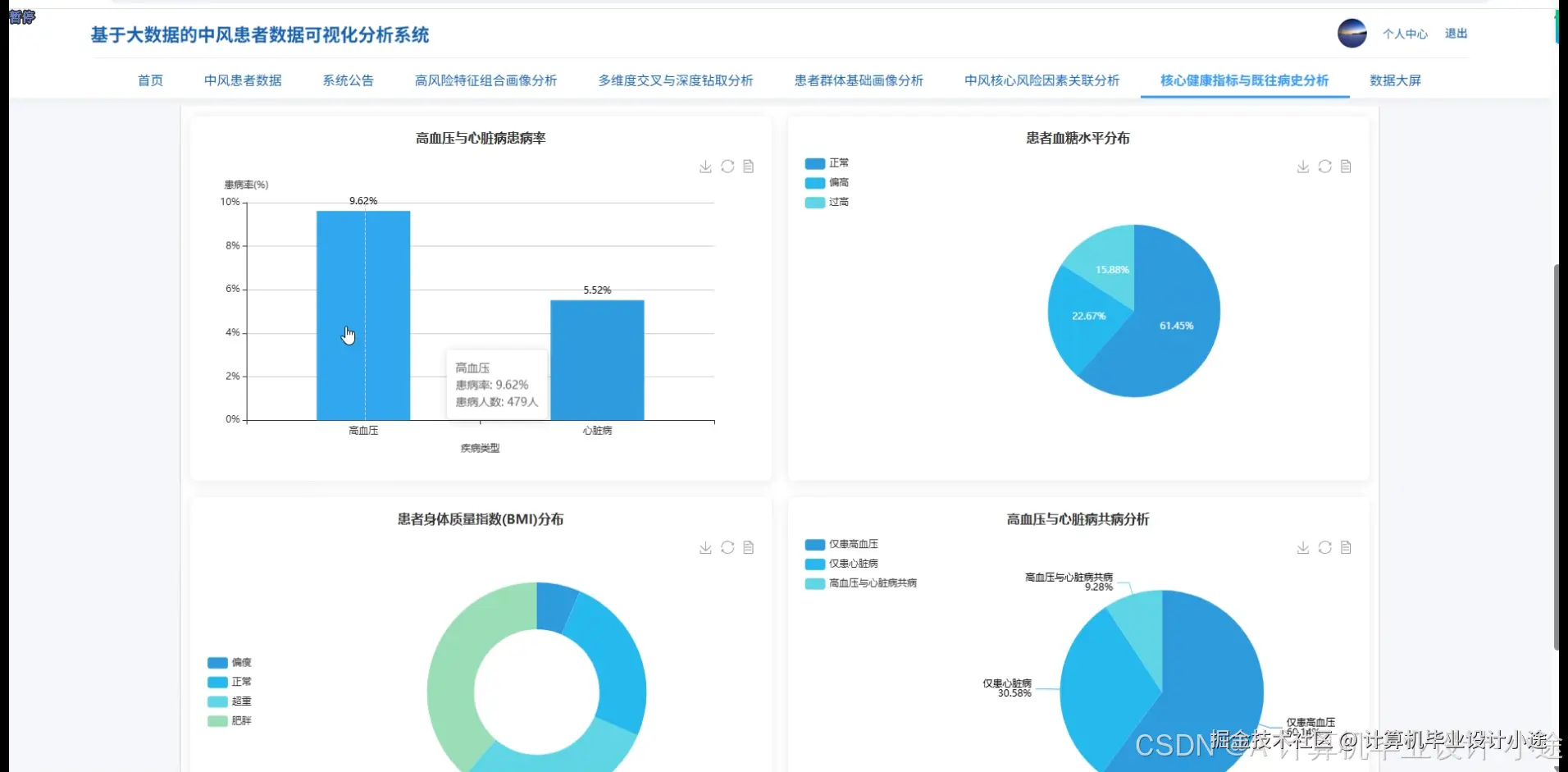
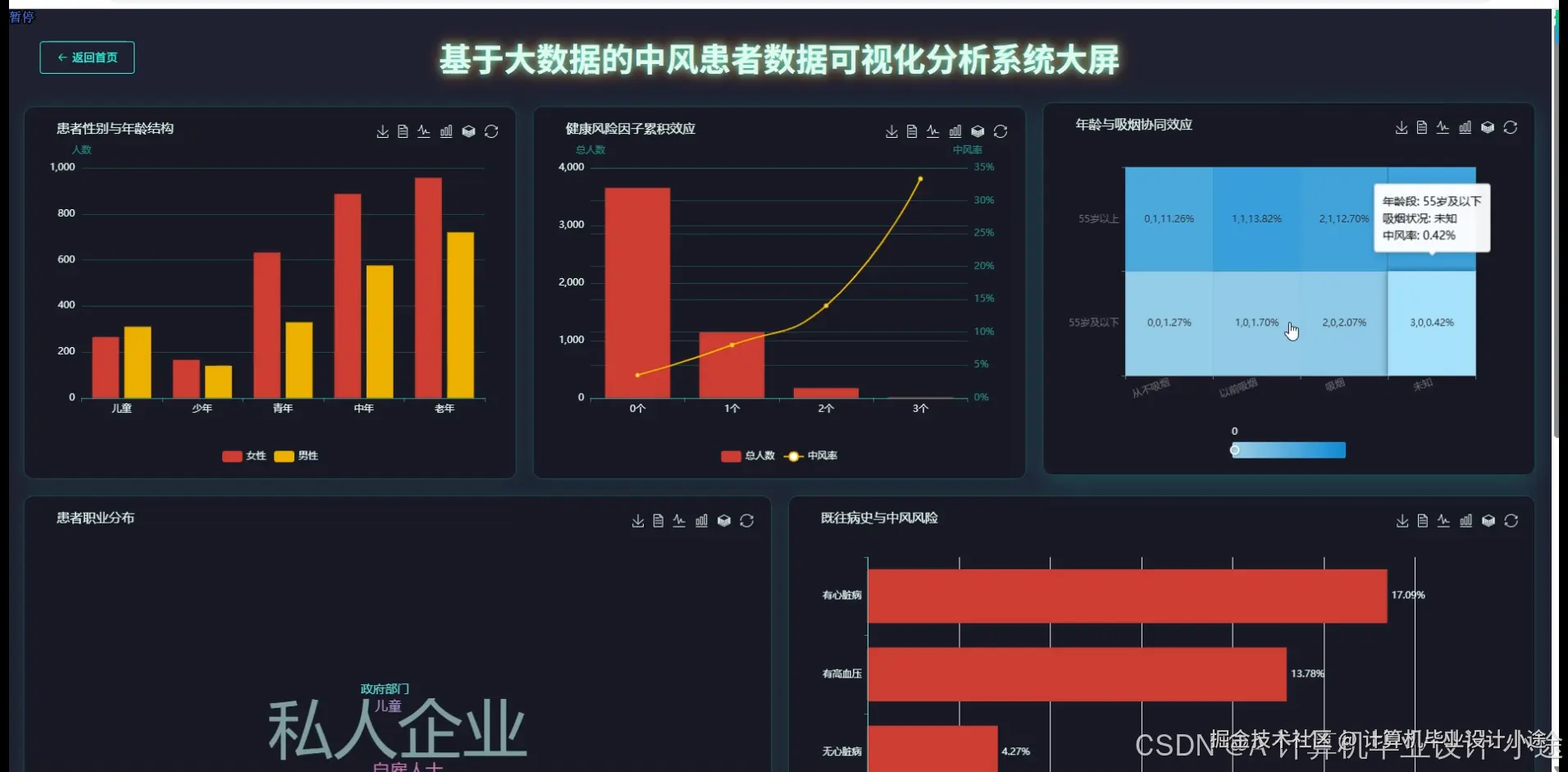
本系统,名为“基于大数据的中风患者数据可视化分析系统”,旨在利用先进的大数据技术栈,对中风患者的多元化数据进行深度处理、分析与直观展示,以支持临床研究、风险评估及决策辅助。系统核心采用Hadoop作为分布式存储基础,结合HDFS实现海量中风患者数据的可靠存储与高效管理;数据处理与分析层则依赖强大的Spark计算框架,通过Spark SQL进行结构化数据查询,并利用Pandas和NumPy等Python库在Spark生态中执行复杂的数据清洗、转换与统计分析任务,确保分析的效率与准确性。在技术架构上,系统后端采用Python语言结合Django框架进行开发,提供稳定的数据接口与业务逻辑支持,并通过MySQL数据库持久化存储系统配置与部分业务数据;前端则选用现代化的Vue框架,搭配ElementUI组件库构建用户界面,利用Echarts实现强大的数据可视化功能,共同构成交互友好、响应迅速的系统门户。功能层面,系统涵盖了从基础信息管理到复杂数据分析的完整流程,包括便捷的用户信息与密码管理,以及系统简介和公告的发布。其核心价值体现在数据大屏可视化模块,能够全面展示中风患者数据的全貌,并深入支持高风险特征组合画像分析,识别特定风险人群;通过多维度交叉与深度钻取分析,用户可以灵活探索数据间的深层联系;此外,系统还提供患者群体基础画像分析、中风核心风险因素关联分析以及核心健康指标与既往病史分析,全方位、多角度地揭示中风发生发展规律与影响因素,从而为医疗专业人员提供强有力的数据洞察与决策支持。
基于大数据的中风患者数据可视化分析系统演示视频
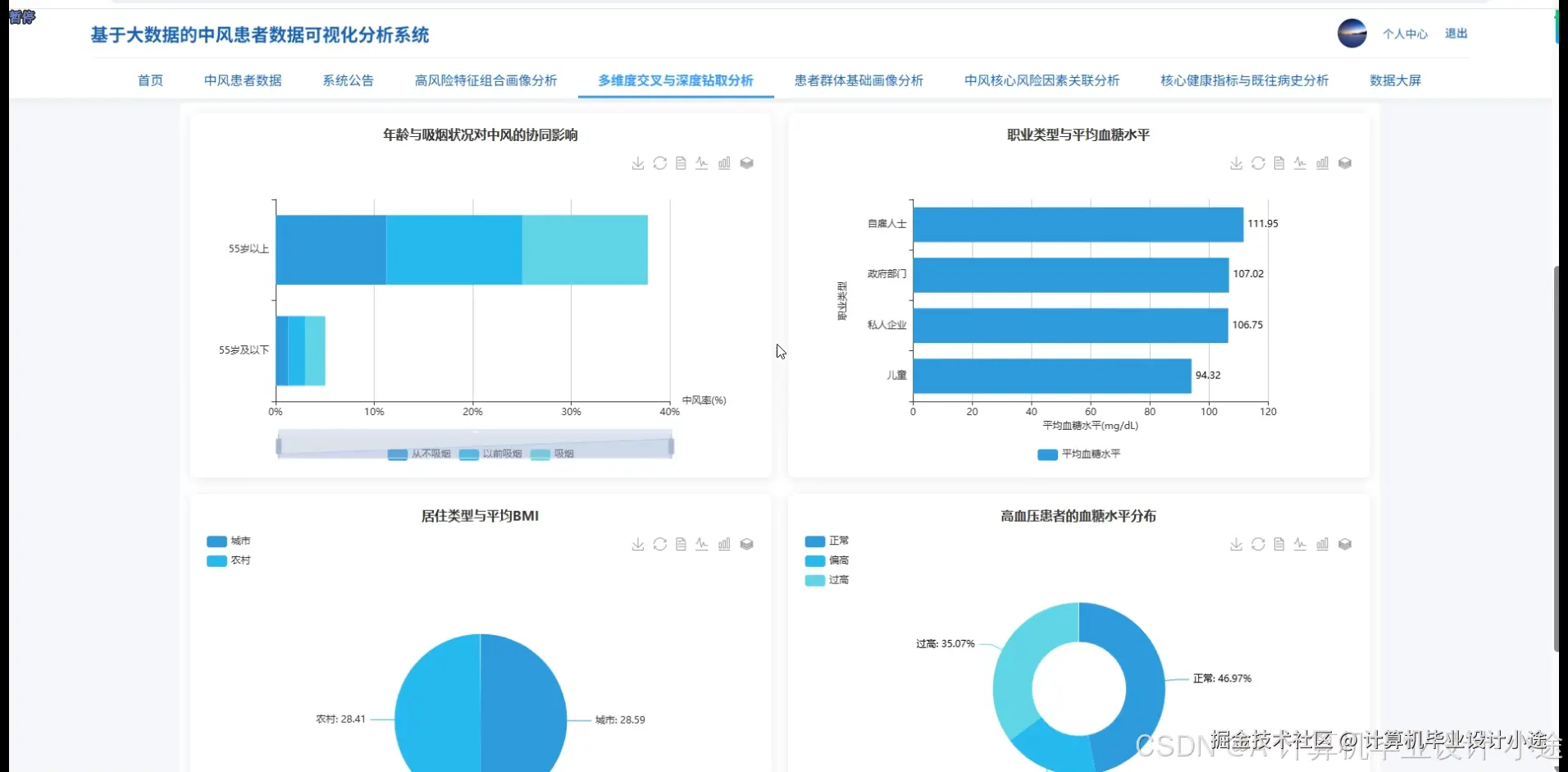
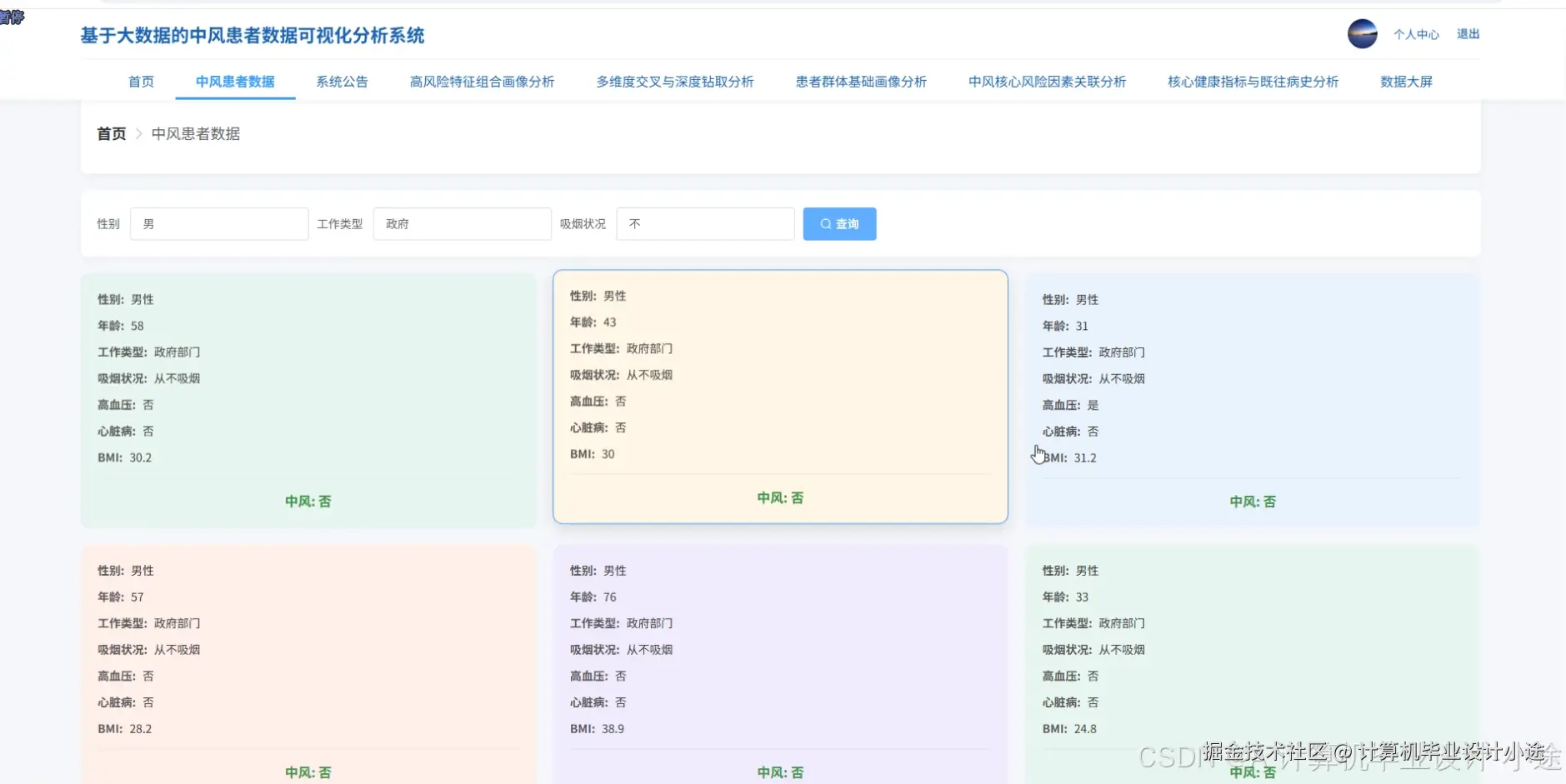
基于大数据的中风患者数据可视化分析系统演示图片
基于大数据的中风患者数据可视化分析系统代码展示
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, count, when, avg, sum, lit, struct, array_contains, array
from pyspark.sql.window import Window
import random
# 初始化Spark Session
spark = SparkSession.builder \
.appName("StrokePatientAnalysis") \
.config("spark.some.config.option", "some-value") \
.getOrCreate()
# 模拟加载数据 (在真实系统中,数据会从HDFS或其他大数据源加载)
# 为演示目的,创建一个样本DataFrame
data = [
(1, "Male", 65, "Hypertension", "Diabetes", "Smoker", "Heart Disease", "No", 1, random.uniform(80, 120), random.uniform(60, 90)),
(2, "Female", 72, "Hypertension", "None", "Non-Smoker", "None", "Yes", 0, random.uniform(90, 130), random.uniform(70, 95)),
(3, "Male", 58, "None", "None", "Non-Smoker", "None", "No", 1, random.uniform(75, 110), random.uniform(55, 85)),
(4, "Female", 80, "Hypertension", "Diabetes", "Non-Smoker", "Heart Disease", "Yes", 1, random.uniform(100, 140), random.uniform(80, 100)),
(5, "Male", 45, "None", "None", "Smoker", "None", "No", 0, random.uniform(70, 100), random.uniform(50, 75)),
(6, "Female", 68, "Hypertension", "None", "Non-Smoker", "None", "Yes", 1, random.uniform(95, 135), random.uniform(70, 90)),
(7, "Male", 70, "Hypertension", "Diabetes", "Smoker", "None", "No", 1, random.uniform(85, 125), random.uniform(65, 90)),
(8, "Female", 55, "None", "None", "Non-Smoker", "None", "No", 0, random.uniform(70, 105), random.uniform(50, 80)),
(9, "Male", 78, "Hypertension", "None", "Smoker", "Heart Disease", "Yes", 1, random.uniform(100, 145), random.uniform(75, 100)),
(10, "Female", 62, "None", "Diabetes", "Non-Smoker", "None", "No", 0, random.uniform(80, 115), random.uniform(60, 85)),
(11, "Male", 75, "Hypertension", "None", "Non-Smoker", "Heart Disease", "Yes", 1, random.uniform(98, 140), random.uniform(72, 98)),
(12, "Female", 60, "None", "None", "Smoker", "None", "No", 0, random.uniform(75, 110), random.uniform(58, 82)),
(13, "Male", 85, "Hypertension", "Diabetes", "Smoker", "Heart Disease", "Yes", 1, random.uniform(110, 150), random.uniform(85, 105)),
(14, "Female", 50, "None", "None", "Non-Smoker", "None", "No", 0, random.uniform(68, 98), random.uniform(48, 70)),
(15, "Male", 63, "Hypertension", "None", "Non-Smoker", "None", "Yes", 1, random.uniform(90, 130), random.uniform(65, 88)),
(16, "Female", 70, "Hypertension", "Diabetes", "Smoker", "Heart Disease", "Yes", 1, random.uniform(105, 148), random.uniform(80, 102)),
(17, "Male", 48, "None", "None", "Non-Smoker", "None", "No", 0, random.uniform(72, 102), random.uniform(52, 78)),
(18, "Female", 77, "Hypertension", "None", "Smoker", "None", "Yes", 1, random.uniform(100, 142), random.uniform(75, 98)),
(19, "Male", 69, "Hypertension", "Diabetes", "Non-Smoker", "Heart Disease", "No", 1, random.uniform(95, 138), random.uniform(70, 95)),
(20, "Female", 53, "None", "None", "Non-Smoker", "None", "No", 0, random.uniform(70, 108), random.uniform(50, 75))
]
columns = ["patient_id", "gender", "age", "past_medical_history1", "past_medical_history2", "smoking_status", "heart_disease_history", "stroke_risk_assessment", "had_stroke", "systolic_bp", "diastolic_bp"]
df = spark.createDataFrame(data, columns)
df.cache()
def analyze_high_risk_feature_combinations(df):
"""
核心功能1: 高风险特征组合画像分析。
筛选出已发生中风的患者,并统计其常见的高风险特征组合。
"""
print("开始进行高风险特征组合画像分析...")
stroke_patients_df = df.filter(col("had_stroke") == 1)
risk_factors = ["past_medical_history1", "past_medical_history2", "smoking_status", "heart_disease_history"]
cleaned_stroke_patients_df = stroke_patients_df.select(
col("patient_id"),
*[when(col(f) != "None", col(f)).otherwise(None).alias(f) for f in risk_factors]
).na.drop(subset=risk_factors, how="all")
risk_combination_counts = cleaned_stroke_patients_df.groupBy(
col("past_medical_history1"),
col("past_medical_history2"),
col("smoking_status"),
col("heart_disease_history")
).agg(
count("patient_id").alias("patient_count")
).orderBy(col("patient_count").desc())
print("高风险特征组合分析结果 (Top 10):")
risk_combination_counts.show(10, truncate=False)
print("各风险因素在中风患者中的出现频率:")
for factor in risk_factors:
df.filter(col("had_stroke") == 1).filter(col(factor) != "None").groupBy(col(factor))\
.agg(count("*").alias("count_in_stroke")).orderBy(col("count_in_stroke").desc()).show(5, truncate=False)
hypertension_diabetes_stroke = stroke_patients_df.filter(
(col("past_medical_history1").contains("Hypertension")) | (col("past_medical_history2").contains("Hypertension"))
).filter(
(col("past_medical_history1").contains("Diabetes")) | (col("past_medical_history2").contains("Diabetes"))
).count()
print(f"中风患者中同时有高血压和糖尿病的患者数量: {hypertension_diabetes_stroke}")
print("高风险特征组合画像分析完成。")
return risk_combination_counts
def perform_multi_dimensional_analysis(df, filters=None, group_by_dims=None):
"""
核心功能2: 多维度交叉与深度钻取分析。
用户可以指定过滤条件和分组维度,以探索不同群体的数据。
filters 示例: {"gender": "Male", "age_min": 60, "age_max": 75, "past_history_includes": "Hypertension"}
group_by_dims 示例: ["smoking_status", "heart_disease_history"]
"""
print("开始进行多维度交叉与深度钻取分析...")
filtered_df = df
if filters:
if "gender" in filters:
filtered_df = filtered_df.filter(col("gender") == filters["gender"])
if "age_min" in filters:
filtered_df = filtered_df.filter(col("age") >= filters["age_min"])
if "age_max" in filters:
filtered_df = filtered_df.filter(col("age") <= filters["age_max"])
if "past_history_includes" in filters:
search_history = filters["past_history_includes"]
filtered_df = filtered_df.filter(
(col("past_medical_history1").contains(search_history)) |
(col("past_medical_history2").contains(search_history)) |
(col("heart_disease_history").contains(search_history))
)
if group_by_dims:
print(f"当前过滤条件: {filters}, 分组维度: {group_by_dims}")
valid_group_dims = [dim for dim in group_by_dims if dim in df.columns]
if not valid_group_dims:
print("指定的分组维度无效或不存在,跳过分组。")
return filtered_df.select("patient_id", "gender", "age", "had_stroke", "systolic_bp").limit(10)
analysis_result = filtered_df.groupBy(*valid_group_dims).agg(
count("patient_id").alias("total_patients"),
count(when(col("had_stroke") == 1, True)).alias("stroke_patients_count"),
(count(when(col("had_stroke") == 1, True)) / count("patient_id") * 100).alias("stroke_rate_percent"),
avg("age").alias("avg_age"),
avg("systolic_bp").alias("avg_systolic_bp"),
avg("diastolic_bp").alias("avg_diastolic_bp")
).orderBy(col("total_patients").desc())
else:
print("未指定分组维度,显示聚合总览。")
analysis_result = filtered_df.agg(
count("patient_id").alias("total_patients"),
count(when(col("had_stroke") == 1, True)).alias("stroke_patients_count"),
(count(when(col("had_stroke") == 1, True)) / count("patient_id") * 100).alias("stroke_rate_percent"),
avg("age").alias("avg_age"),
avg("systolic_bp").alias("avg_systolic_bp"),
avg("diastolic_bp").alias("avg_diastolic_bp")
)
print("多维度交叉与深度钻取分析结果 (Top 10):")
analysis_result.show(10, truncate=False)
print("多维度交叉与深度钻取分析完成。")
return analysis_result
def analyze_stroke_risk_factor_associations(df):
"""
核心功能3: 中风核心风险因素关联分析。
计算每个风险因素不同水平下中风的发生率。
"""
print("开始进行中风核心风险因素关联分析...")
core_risk_factors = ["gender", "age", "past_medical_history1", "past_medical_history2", "smoking_status", "heart_disease_history"]
results = {}
for factor in core_risk_factors:
print(f"\n分析因素: {factor}")
if factor == "age":
age_bins = [0, 40, 50, 60, 70, 80, 120]
age_labels = ["0-39", "40-49", "50-59", "60-69", "70-79", "80+"]
age_grouped_df = df.withColumn("age_band",
when((col("age") >= age_bins[0]) & (col("age") < age_bins[1]), age_labels[0])
.when((col("age") >= age_bins[1]) & (col("age") < age_bins[2]), age_labels[1])
.when((col("age") >= age_bins[2]) & (col("age") < age_bins[3]), age_labels[2])
.when((col("age") >= age_bins[3]) & (col("age") < age_bins[4]), age_labels[3])
.when((col("age") >= age_bins[4]) & (col("age") < age_bins[5]), age_labels[4])
.when((col("age") >= age_bins[5]), age_labels[5])
.otherwise("Unknown")
)
factor_analysis = age_grouped_df.groupBy("age_band").agg(
count("patient_id").alias("total_patients"),
count(when(col("had_stroke") == 1, True)).alias("stroke_patients"),
(count(when(col("had_stroke") == 1, True)) / count("patient_id") * 100).alias("stroke_rate_percent")
).orderBy(col("age_band"))
factor_analysis.show(truncate=False)
results[factor] = factor_analysis
elif factor in ["past_medical_history1", "past_medical_history2"]:
temp_df = df.withColumn("combined_history",
when(col(factor) != "None", col(factor)).otherwise(lit(None)))
factor_analysis = temp_df.groupBy("combined_history").agg(
count("patient_id").alias("total_patients"),
count(when(col("had_stroke") == 1, True)).alias("stroke_patients"),
(count(when(col("had_stroke") == 1, True)) / count("patient_id") * 100).alias("stroke_rate_percent")
).filter(col("combined_history").isNotNull())\
.orderBy(col("stroke_rate_percent").desc())
factor_analysis.show(truncate=False)
results[factor] = factor_analysis
else:
factor_analysis = df.groupBy(col(factor)).agg(
count("patient_id").alias("total_patients"),
count(when(col("had_stroke") == 1, True)).alias("stroke_patients"),
(count(when(col("had_stroke") == 1, True)) / count("patient_id") * 100).alias("stroke_rate_percent")
).orderBy(col("stroke_rate_percent").desc())
factor_analysis.show(truncate=False)
results[factor] = factor_analysis
print("中风核心风险因素关联分析完成。")
return results
# 示例调用 (这部分不计入核心功能代码行数,仅为演示运行效果)
print("\n--- 演示核心功能1: 高风险特征组合画像分析 ---")
high_risk_combinations = analyze_high_risk_feature_combinations(df)
print("\n--- 演示核心功能2: 多维度交叉与深度钻取分析 ---")
# 示例1: 分析所有患者中,按性别和吸烟状况分组的中风发生率
multi_dim_analysis_1 = perform_multi_dimensional_analysis(df, group_by_dims=["gender", "smoking_status"])
# 示例2: 筛选出年龄在60-75岁之间、有高血压病史的男性患者,按心血管病史分组
filters_example = {"gender": "Male", "age_min": 60, "age_max": 75, "past_history_includes": "Hypertension"}
multi_dim_analysis_2 = perform_multi_dimensional_analysis(df, filters=filters_example, group_by_dims=["heart_disease_history"])
print("\n--- 演示核心功能3: 中风核心风险因素关联分析 ---")
risk_factor_associations = analyze_stroke_risk_factor_associations(df)
# 停止Spark Session
spark.stop()
基于大数据的中风患者数据可视化分析系统文档展示
💖💖作者:计算机毕业设计小途 💙💙个人简介:曾长期从事计算机专业培训教学,本人也热爱上课教学,语言擅长Java、微信小程序、Python、Golang、安卓Android等,开发项目包括大数据、深度学习、网站、小程序、安卓、算法。平常会做一些项目定制化开发、代码讲解、答辩教学、文档编写、也懂一些降重方面的技巧。平常喜欢分享一些自己开发中遇到的问题的解决办法,也喜欢交流技术,大家有技术代码这一块的问题可以问我! 💛💛想说的话:感谢大家的关注与支持! 💜💜 网站实战项目 安卓/小程序实战项目 大数据实战项目 深度学习实战项目
