RAG技术简介
什么是RAG
RAG(英文名称:Retrieval-Augmented Generation),中文译为:检索增强生成。
RAG 是当前 AI 领域解决知识时效性和准确性的核心技术之一。简单说就是 AI 在回答前先 “查资料”,再结合资料生成答案,而非只依赖训练时的固定知识。
大语言模型的出现让AI仿佛有了智能一样,不再是之前从固定的问题答案中检索,然后用设定好的内容返回给用户。而是结合自己训练的知识,生成贴合问题、有事实根据的答案。正如上面所言,大模型会通过所训练的知识生成答案,虽然大模型训练知识覆盖广泛,但是对于一些非公开、专业性的特定领域知识,它是无法准确回答的。此时RAG的出现解决这个问题。
弥补大模型的短板
知识过时问题
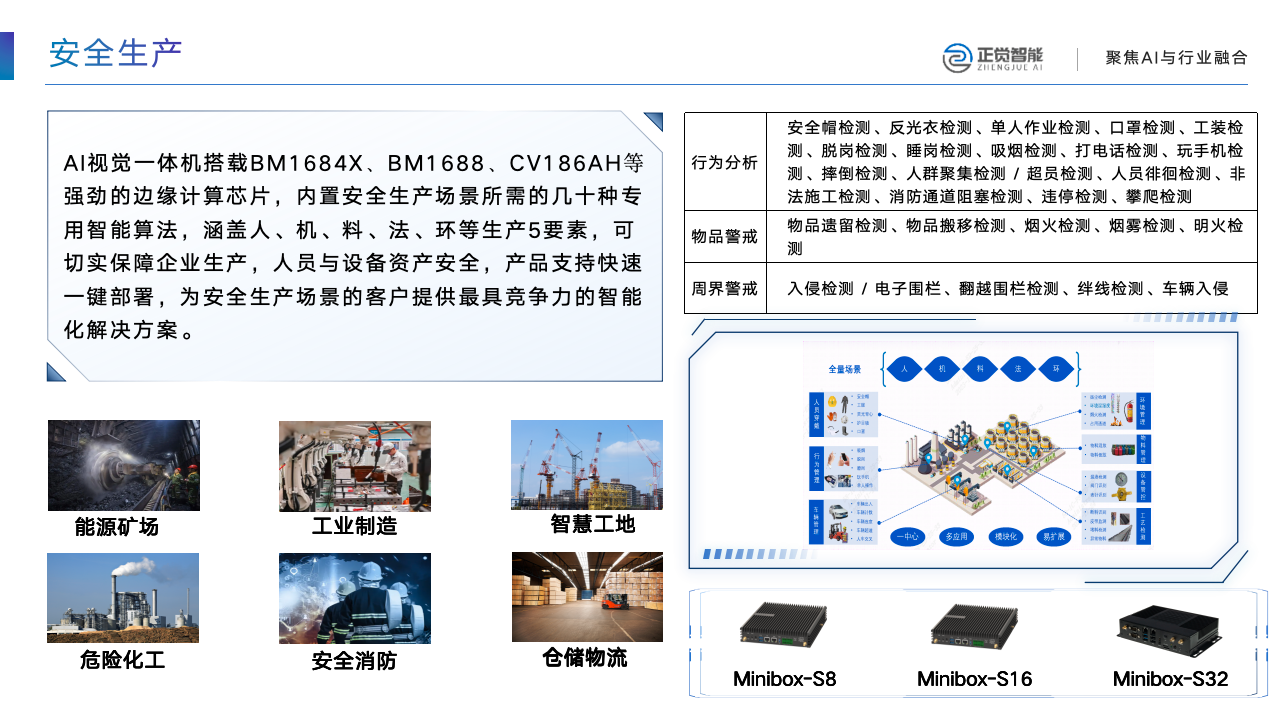
大模型训练数据是有截止时间的,以deepseek官网为例,笔者当前时间为2025年10月,但deepseek训练数据是2024年7月之前的。
知识不准确的问题
大模型有时的回答就是“一本正经的胡说八道”,这就是大模型的“幻觉”。出现“幻觉”的原因有:训练数据有误、过时、有偏见、问题分析有误等原因。RAG可以通过训练特定数据修正或者更新最新的资料,让大模型回答更准确。
专业领域适配问题
通用大模型对行业专属知识(如医疗病例、企业内部文档)掌握不足。RAG 可接入行业知识库,让 AI 成为垂直领域的 “专家”。
RAG的应用场景
企业知识库问答
最常见的就是企业内部资料的问答系统,比如产品使用手册、部署文档、公司规章制度等内部文档的内容问答。
智能客服
客服机器人检索产品故障库、售后政策,为用户提供标准化解决方案。
个人知识管理
学习笔记、工作心得、文档手册等都可以快速总结,提炼核心内容。
RAG 技术初探
使用简单流程
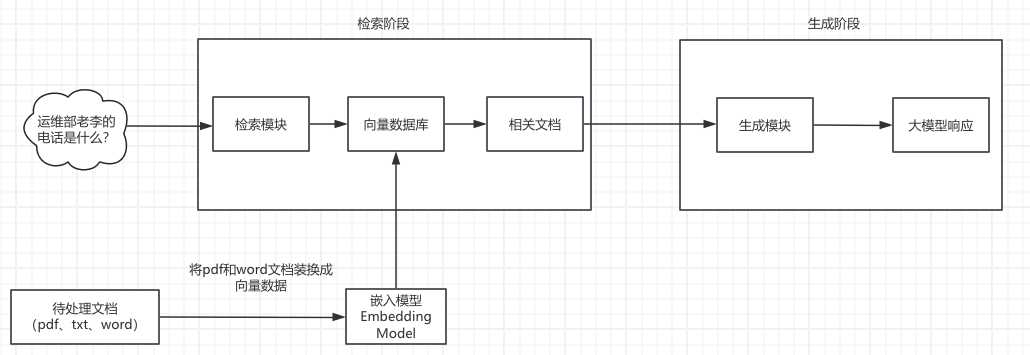
RAG使用简单流程: 1、索引:将文档通过嵌入模型转换为向量数据,并存储到向量数据库 2、检索:根据查询内容,从向量数据库找到最匹配的文档。 3、生成:将检索结果作为上下文输入LLM,生成自然语言响应。
索引构建 Embedding
向量嵌入,就是将我们真实世界中的非结构化的数据对象(文本、图像等)转换为数学上可操作的连续向量的技术。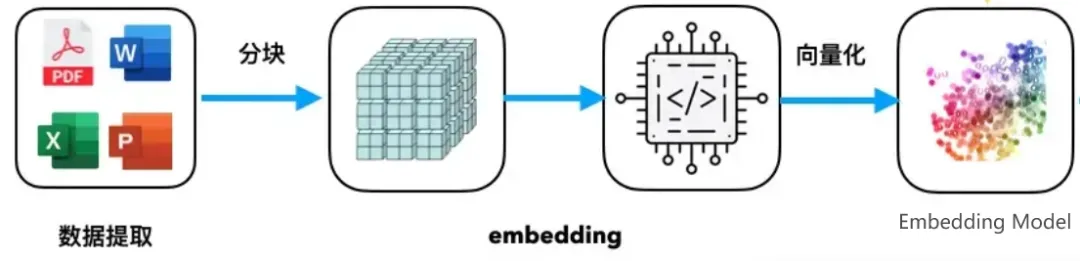
Embedding 常用于将文本数据映射为固定长度的实数向量,从而使计算机能够更好地处理和理解这些数据。每个单词或句子都可以用一个包含其语义信息的实数向量来表示。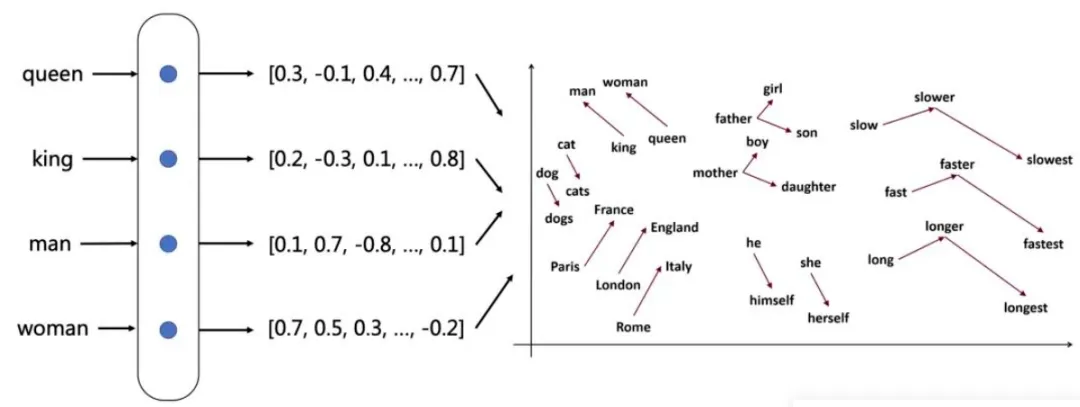
以“人骑自动车”为例,在计算机中,单词是以文字形式存在的,但计算机无法直接理解这些内容。 Embedding的作用就是将每个单词转化为向量,例如:
- “人”可以表示为 [0.2, 0.3, 0.4]
- “骑”可以表示为 [0.5, 0.6, 0.7]
- “自行车”可以表示为 [0.8, 0.9, 1.0]
通过这些向量,计算机可以执行各种计算,比如分析“人”和“自行车”之间的关系,或者判断“骑”这个动作与两者之间的关联性。此外,Embedding还可以帮助计算机更好地处理和理解自然语言中的复杂关系。例如:
- 相似的词(如“人”和“骑手”)在向量空间中会比较接近。
- 不相似的词(如“人”和“汽车”)则会比较远。
检索
混合检索
技术细节引用于:all-in-rag
混合检索(Hybrid Search)是一种结合了 稀疏向量(Sparse Vectors) 和 密集向量(Dense Vectors) 优势的先进搜索技术。旨在同时利用稀疏向量的关键词精确匹配能力和密集向量的语义理解能力,以克服单一向量检索的局限性,从而在各种搜索场景下提供更准确、更鲁棒的检索结果。
稀疏向量
稀疏向量,也常被称为“词法向量”,是基于词频统计的传统信息检索方法的数学表示。它通常是一个维度极高(与词汇表大小相当)但绝大多数元素为零的向量。它采用精准的“词袋”匹配模型,将文档视为一堆词的集合,不考虑其顺序和语法,其中向量的每一个维度都直接对应一个具体的词,非零值则代表该词在文档中的重要性(权重)。这类向量的经典权重计算方法是 TF-IDF。在信息检索领域,BM25 则是基于这种稀疏表示的成功且应用广泛的排序算法之一,其核心公式如下:

这种方法的优点是可解释性极强(每个维度都代表一个确切的词),无需训练,能够实现关键词的精确匹配,对于专业术语和特定名词的检索效果好。主要缺点是无法理解语义,例如它无法识别“汽车”和“轿车”是同义词,存在“词汇鸿沟”。
密集向量
密集向量,也常被称为“语义向量”,是通过深度学习模型学习到的数据(如文本、图像)的低维、稠密的浮点数表示。这些向量旨在将原始数据映射到一个连续的、充满意义的“语义空间”中来捕捉“语义”或“概念”。
在理想的语义空间中,向量之间的距离和方向代表了它们所表示概念之间的关系。
一个经典的例子是 vector('国王') - vector('男人') + vector('女人') 的计算结果在向量空间中非常接近 vector('女王'),这表明模型学会了“性别”和“皇室”这两个维度的抽象概念。 它的代表包括 Word2Vec、GloVe、以及所有基于 Transformer 的模型(如 BERT、GPT)生成的嵌入(Embeddings)。
其主要优点是能够理解同义词、近义词和上下文关系,泛化能力强,在语义搜索任务中表现卓越。但缺点也同样明显:可解释性差(向量中的每个维度通常没有具体的物理意义),需要大量数据和算力进行模型训练,且对于未登录词(OOV)的处理相对困难。
通过上文可以看出稀疏向量和密集向量各有千秋,那么将它们结合起来,实现优势互补,就成了一个不错的选择。
混合检索便是基于这个思路,通过结合多种搜索算法(最常见的是稀疏与密集检索)来提升搜索结果相关性和召回率。
- 主要目标:解决单一检索技术的局限性。例如,关键词检索无法理解语义,而向量检索则可能忽略掉必须精确匹配的关键词(如产品型号、函数名等)。
- 混合检索旨在同时利用稀疏向量的精确性和密集向量的泛化性,以应对复杂多变的搜索需求。
生成
当上一步检索匹配到文档片段后,为了满足真正的实际需求,需要通过大模型处理生成特定格式的数据,比如:json格式。
格式化生成的实现方法
LangChain 提供了一个强大的组件——OutputParsers(输出解析器),专门用于处理 LLM 的输出。
它的核心思想是:
- 提供格式指令:在发送给 LLM 的提示(Prompt)中,自动注入一段关于如何格式化输出的指令。
- 解析模型输出:接收 LLM 返回的纯文本字符串,并将其解析成预期的结构化数据(如 Python 对象)。
LangChain 提供了多种开箱即用的解析器,例如:
- StrOutputParser:最基础的输出解析器,它简单地将 LLM 的输出作为字符串返回。
- JsonOutputParser:可以解析包含嵌套结构和列表的复杂 JSON 字符串。•
- PydanticOutputParser:通过与 Pydantic 模型结合,可以实现对输出格式最严格的定义和验证。
重排序 Re-rank
重新排序的任务就像一个智能过滤器。当检索器从索引集合中检索多个上下文时,这些上下文与用户的查询的相关性可能不同,一些上下文可能非常相关,而另一些上下文可能只有轻微的相关甚至不相关。
重新排序的任务是评估这些上下文的相关性,并优先考虑最有可能提供准确和相关答案的上下文,让LLM在生成答案时优先考虑这些排名靠前的上下文,从而提高响应的准确性和质量。
RAG知识库-在线知识库工具
上文介绍了RAG相关技术原理,那么从本章起,和大家一起了解下如何使用RAG知识库。已经有很多互联网厂商提供了知识库服务,下面就介绍两种比较流行的知识库。
腾讯IMA
官网地址:ima.copilot-腾讯AI工作台
可以使用微信直接登录,如果下载了手机app和电脑端,登录成功就会有50G的初始空间。
创建知识库
现在网页端是无法创建知识库的,请下载PC版本后操作。
点击【个人知识库】,然后点击右上角的“+”,可以上传本地文件或者文件夹。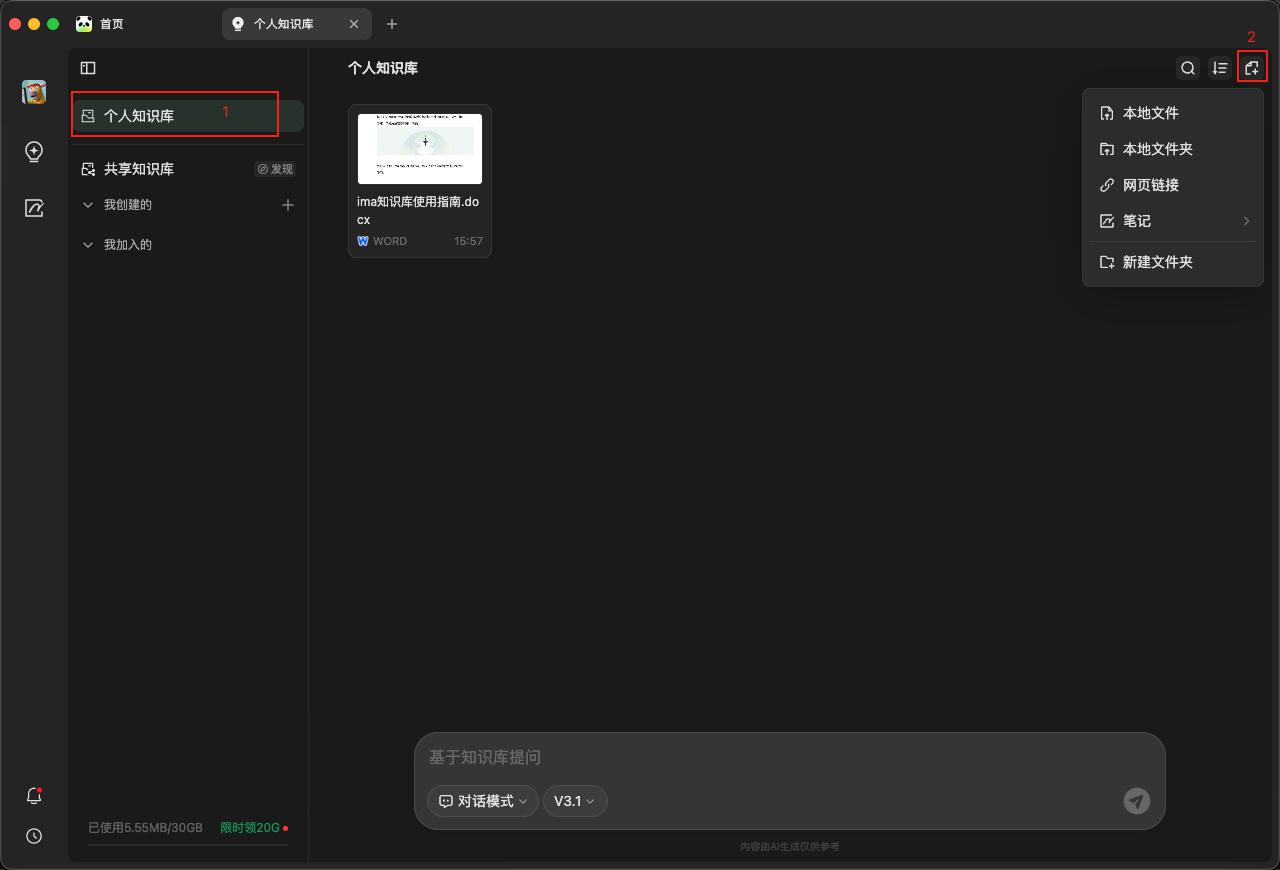
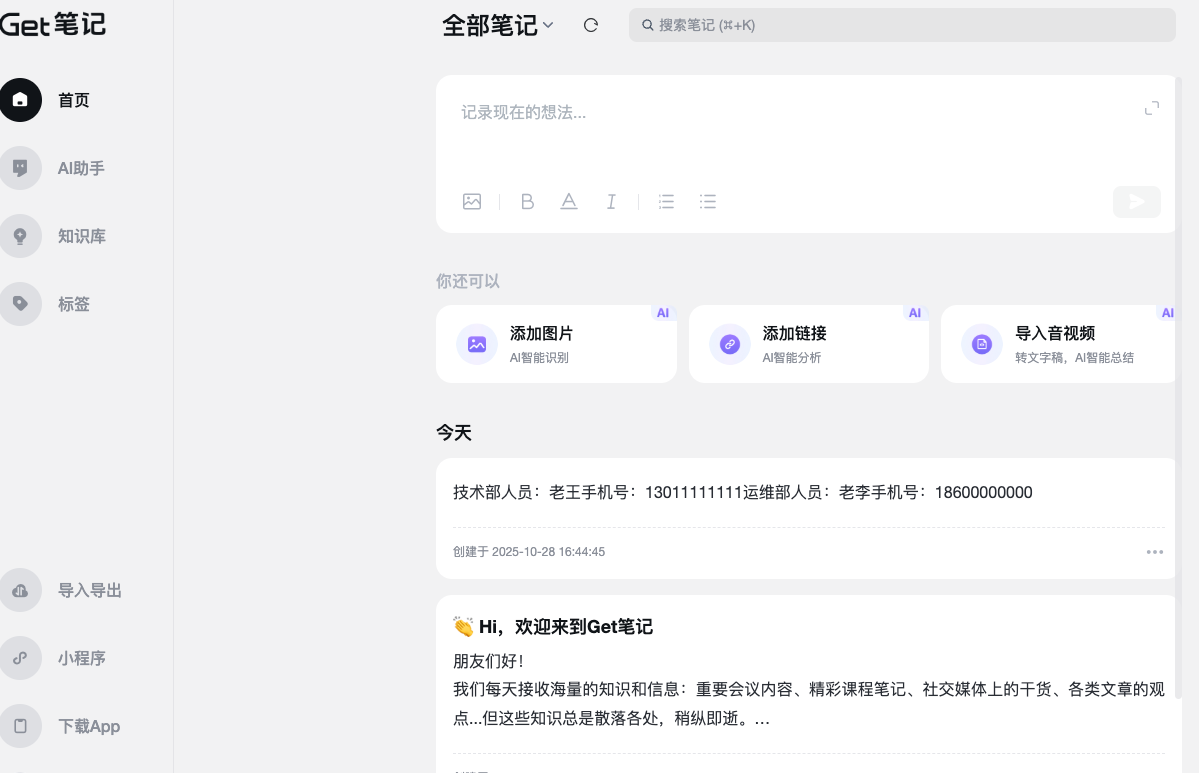
在电脑上创建一个“通讯录.docx”的word文档,内容为:
技术部人员:
老王手机号:13011111111
运维部人员:
老李手机号:18600000000
然后在上传这个文档到知识库。等待ima解析完成,就可以在下面对话框询问文档内容了,比如:运维部老李的联系方式是什么?
可以看出,知识库正确读取到了老李的手机号。
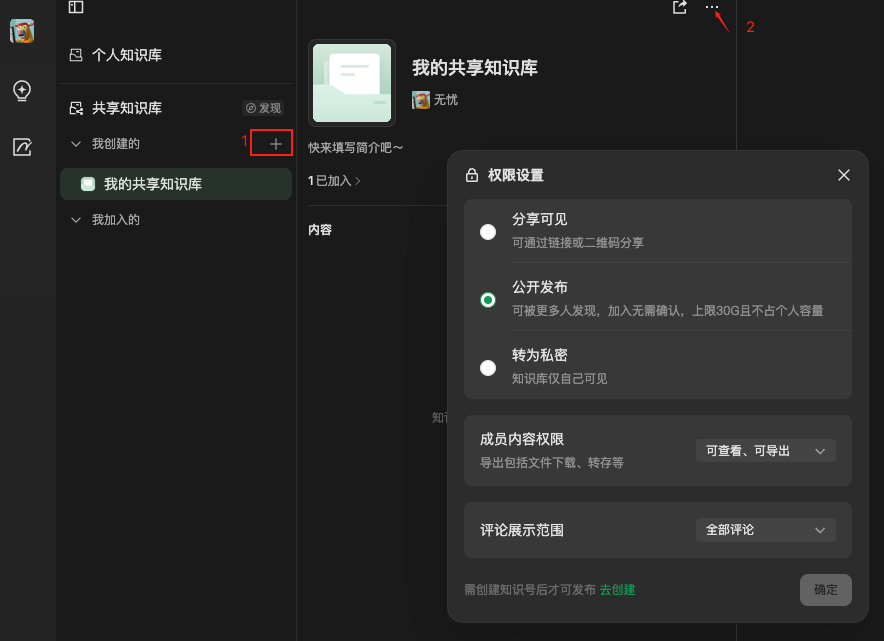
共享知识库
个人知识库上传的文档只有自己可以看到,如果想要别人也可查询知识库的内容,可以创建共享知识库。
共享知识库权限有以下几种:
- 分享可见:可以通过链接或者二维码的方式邀请人员进入知识库,成员进入需要通过你的审核。
- 公开发布:可以被所有人搜索到,成员进入无需审核,只要申请加入,就可以检索你知识库的内容,但是可以对用户权限显示,是否仅查看,或者可查看可导出文档到使用者本地。
公开发布的特点:
- 先说最大的优点:不占用个人知识库的50GB的空间。
- 可以被更多人使用,如果你有产品手册供很多人查看,可以使用这种方式。
GET笔记
官网地址:Get笔记 - 记录每一个闪光的想法 ,网址也特别好记:biji.com (笔记.com)。
GET笔记其实不是一个标准的知识库软件,它主要还是一个笔记软件。进入首页后,可以直接在上面输入框中,编写自己的文档内容,用上面通讯录的例子,创建一个笔记。
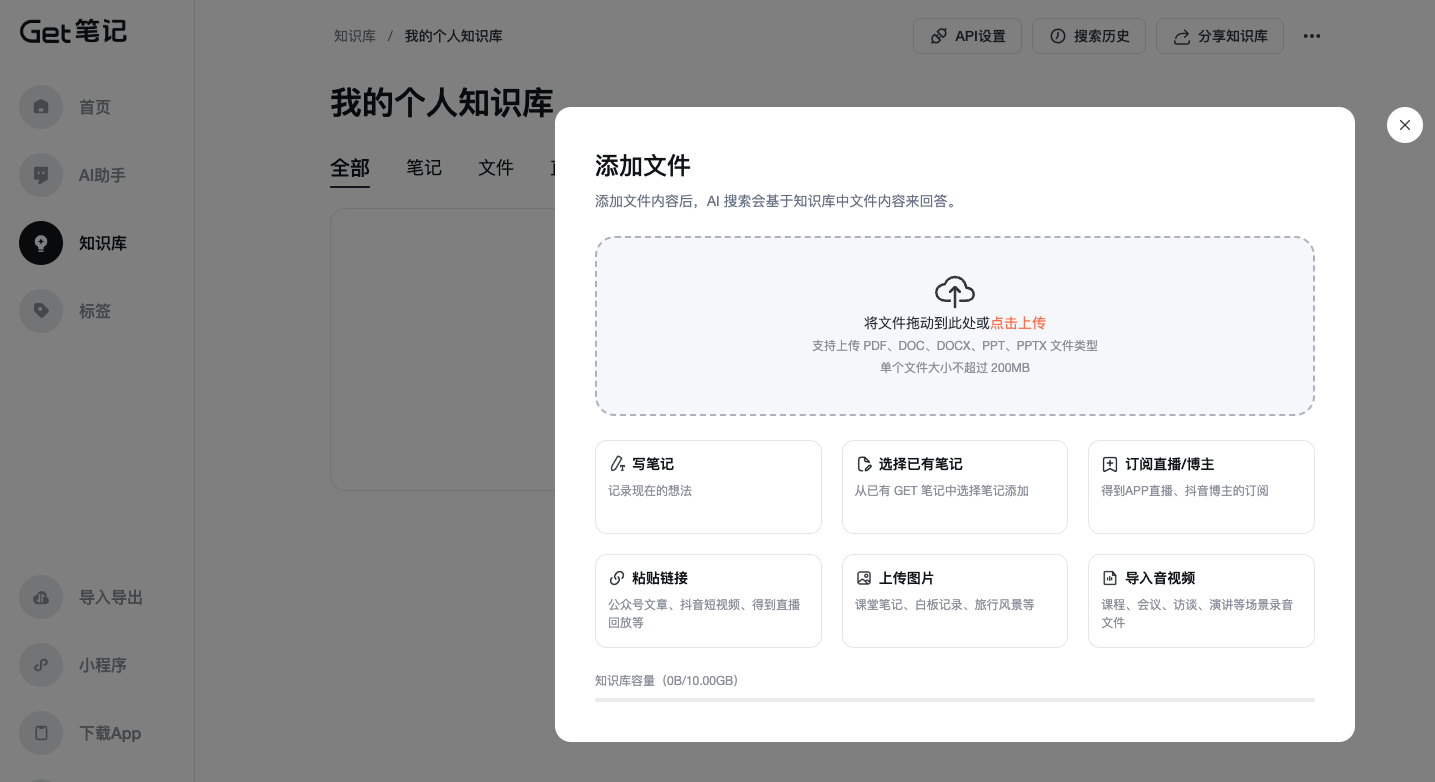
创建知识库
点击【知识库】,可以创建自己的知识库。创建知识库后,点击【添加】按钮,有以下几种添加知识库内容方式:
- 上传本地的pdf、word、ppt等文档,单个文件大小不超过200MB
- 直接写笔记的方式。
- 选择历史笔记内容。
- 得到直播/抖音博主短视频
- 公众号文章、抖音短视频地址
- 图片
- 音频转文字
可以看出GET笔记的知识库添加文档的方式比IMA更丰富一些。
我们使用选择已有笔记的方式加入知识库,测试下知识库功能。
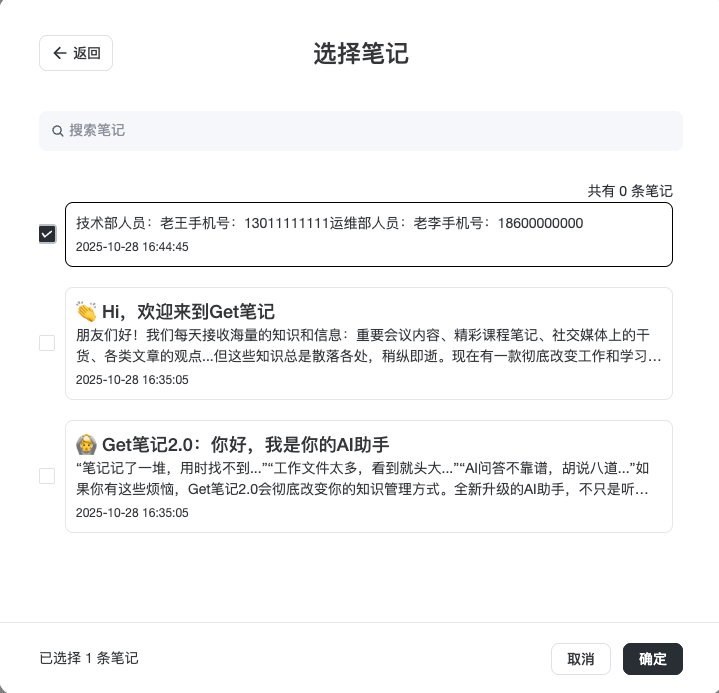
在页面右侧有个AI助手,可以直接和它对话询问知识库内容,注意,记得选择内容范围打开“知识库”。我们输入“运维部老李的联系方式是什么?”
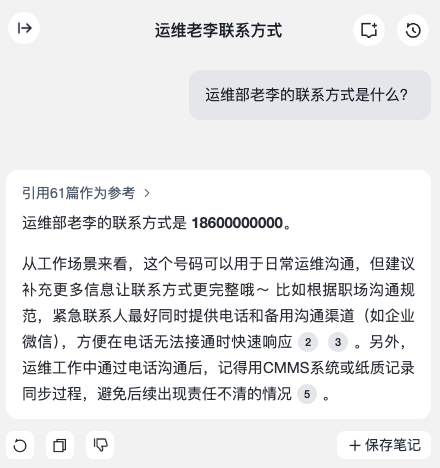 可以看到,GET笔记知识库也正确返回了老李的联系方式。
可以看到,GET笔记知识库也正确返回了老李的联系方式。
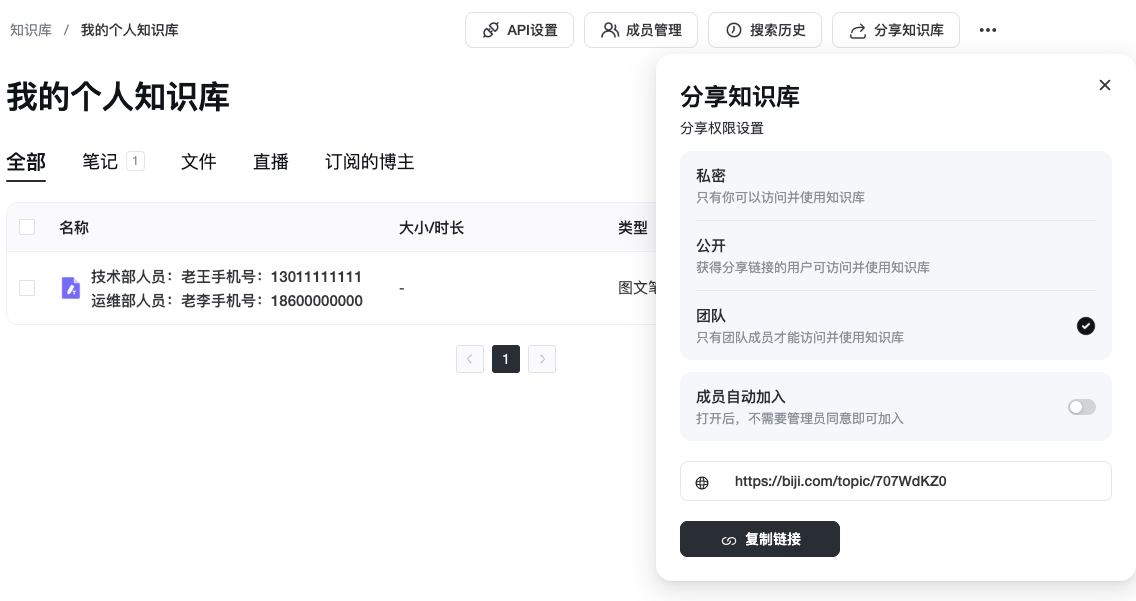
分享知识库
自己创建的知识库,也可以通过“分享知识库”让更多人使用。权限设置如下:
- 公开。所有获取的链接的用户都可以访问使用知识库。
- 团队。只有成为团队成员的人才可以使用知识库。
本地知识库工具
在线的知识库虽然方便快捷,但是有也明显的缺点。
- 知识库文档只能由一人维护,没有办法覆盖到多人维护,共同使用的场景。
- 需要上传文档到知识库提供方,对于一些企业内部保密的文档,有泄露机密的风险。
那么下面我们一起看一下,企业内部私有化部署知识库的方案。
部署开源大模型
笔者使用环境:cuda 12.6、GPU nvidia 4060 8g 软件:docker、docker-compose、ollama
启动ollama
使用docker-compose方式启动,假设运行目录为/data/bigmodel
# 创建文件夹
mkdir /data/bigmodel/ollama -p
mkdir /data/bigmodel/bge-rerank-v2-m3 -p
mkdir /data/bigmodel/maxkb -p
# 进入ollma目录,并新建docker-compose.yaml文件
cd /data/bigmodel/ollama
vi docker-compose.yaml
docker-compose.yaml
version: '3.9'
services:
ollama:
image: ollama/ollama
container_name: ollama
restart: always
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
volumes:
- ./data:/root/.ollama
ports:
- "11434:11434"
启动
docker-compose up -d
部署嵌入模型 bge-m3
待ollama启动成功后,执行下面命令
docker exec -it ollama
ollama pull bge-m3:latest
等待pull 完成,模型就算部署好了。
部署通用大模型 qwen3
执行下面命令
docker exec -it ollama
ollama pull qwen3:1.7b
部署重排序模型 bge-rerank-v2-m3
# 进入bge-rerank-v2-m3目录,并新建docker-compose.yaml文件
cd /data/bigmodel/bge-rerank-v2-m3
vi docker-compose.yaml
docker-compose.yaml
version: "3"
services:
reranker:
image: registry.cn-hangzhou.aliyuncs.com/fastgpt/bge-rerank-v2-m3:v0.1
container_name: reranker
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
ports:
- 6006:6006
environment:
- CUDA_VISIBLE_DEVICES=0
- ACCESS_TOKEN=123456
restart: always
启动
docker-compose up -d
部署maxkb
# 进入maxkb目录,并新建docker-compose.yaml文件
cd /data/bigmodel/maxkb
vi docker-compose.yaml
docker-compose.yaml
version: '3'
services:
maxkb:
image: registry.fit2cloud.com/maxkb/maxkb
container_name: maxkb
restart: always
ports:
- "8080:8080"
volumes:
- ./maxkb:/opt/maxkb
使用maxkb知识库
浏览器访问 http://目标服务器IP地址:8080
默认登录信息 用户名:admin 默认密码:MaxKB@123.. 登录成功后,会提示修改密码,修改为你自己的密码就可以了。
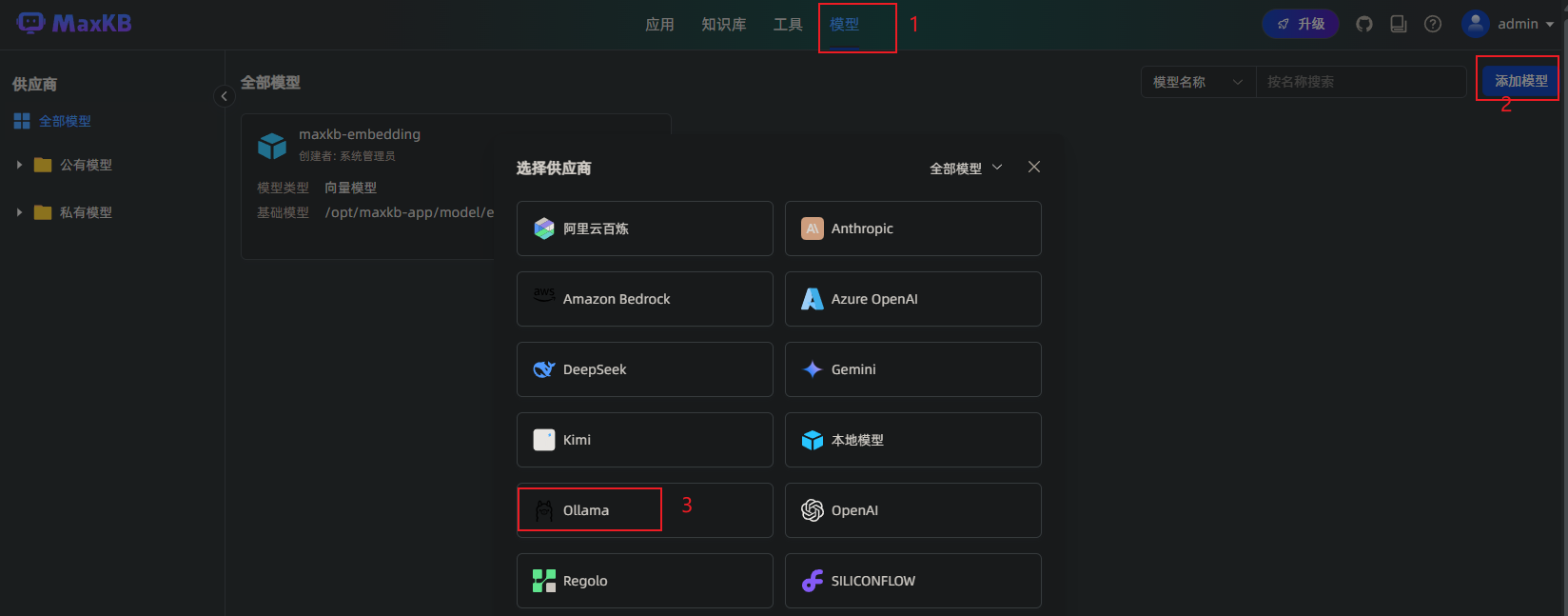
新增模型
登录以后,点击上侧【模型】菜单,点击【增加模型】,再点击ollama增加ollama运行的模型。
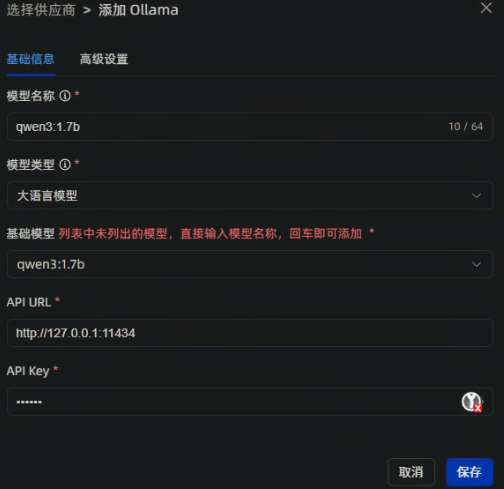
设置大语言模型
如下图所示,添加大语言模型:qwen3:1.7b,API Key 随便填写即可,比如:123,点击保存即可,
设置嵌入模型
与大语言模型相同的操作,设置嵌入模型
设置重排序模型
重排序模型的供应商选择为SILICONFLOW
填入重排序模型名称: bge-reranker-v2-m3,设置API Key 为:123456 。
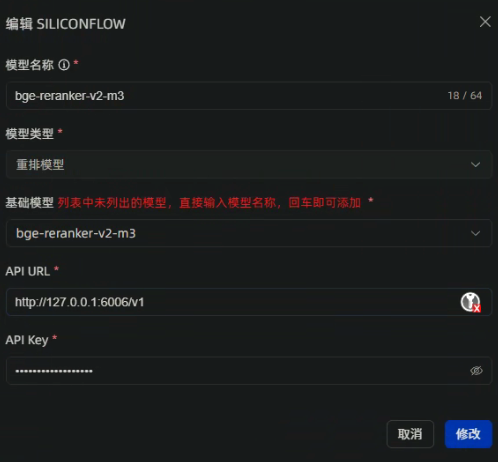
至此,大语言模型、嵌入模型、重排序模型都设置好了
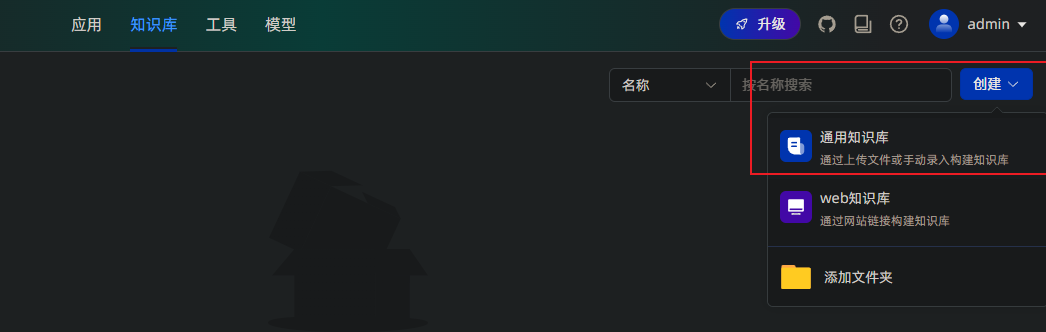
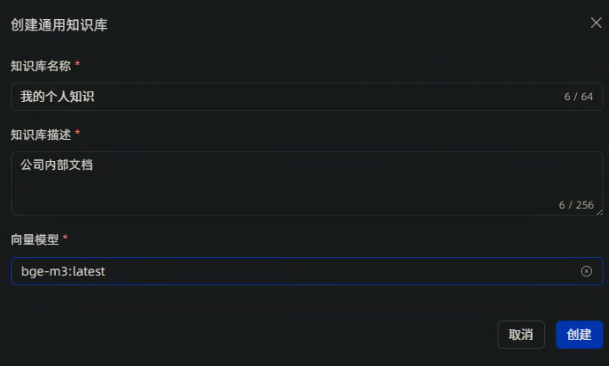
新增知识库
点击maxkb上侧的【知识库】菜单,点击【创建】按钮,选择【通用知识库】
上传文档
创建成功后,上传本地电脑中的【通讯录.docx】文档。上传文档可以看出maxkb支持多种文档类型:txt、Markdown、PDF、docx等,你也可以上传其他格式文档试试。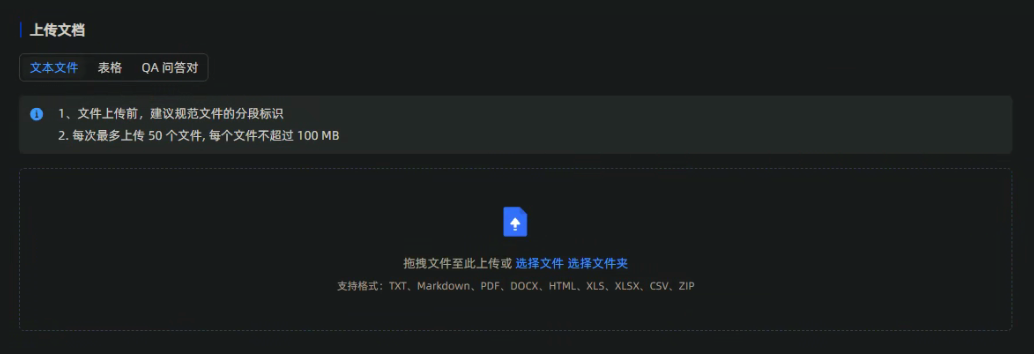
上传成功后,点击【下一步】,进入文档处理页面,可以选择文档分段规则,屏幕右侧为文档的预览信息。确认无误,点击【开始导入】。
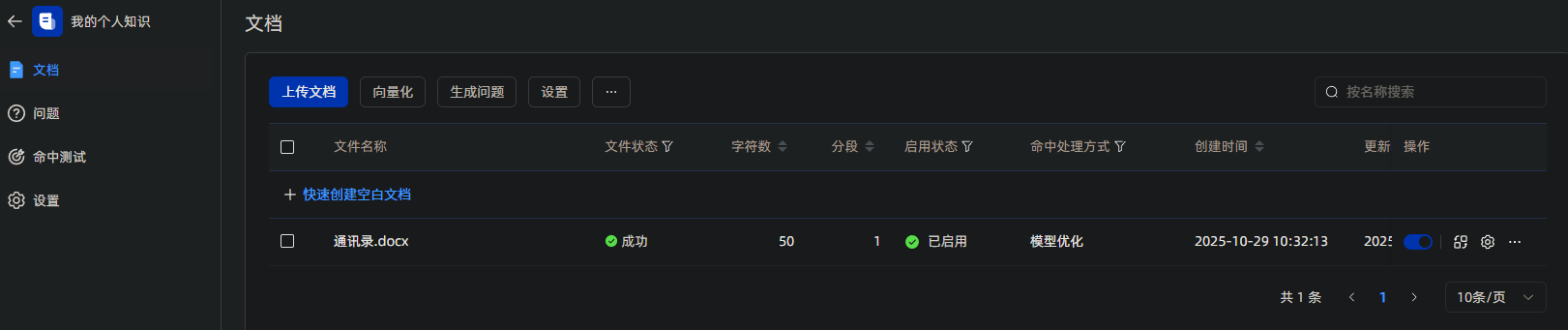
创建应用
点击顶部【应用】菜单,点击【创建】,创建简易应用,设置完成名称后点击【创建】按钮。
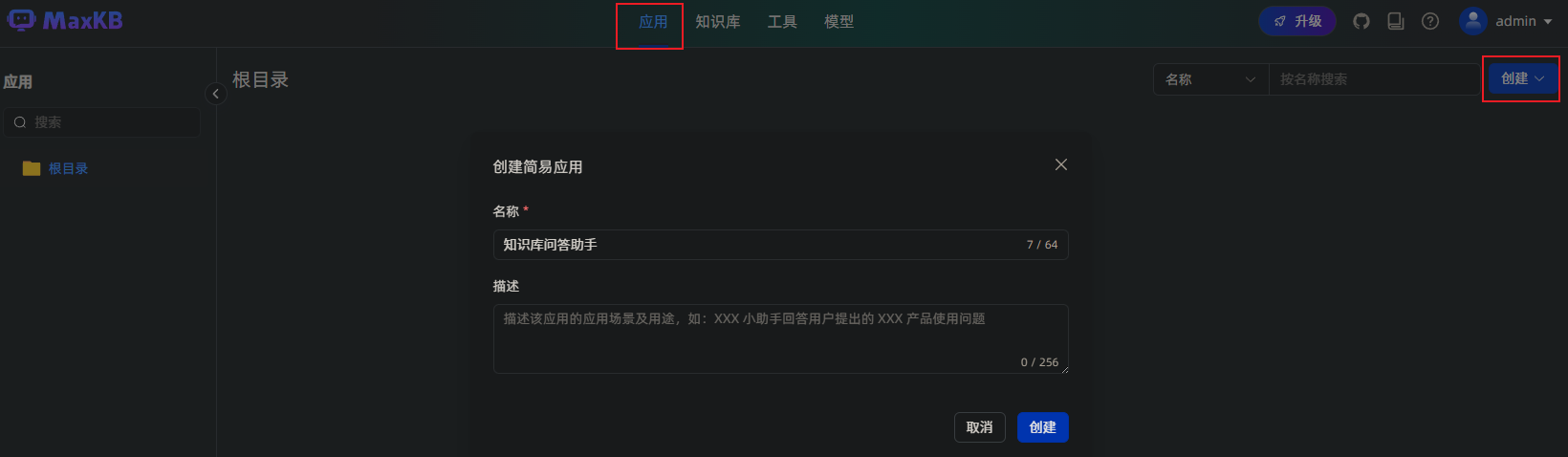
然后进入应用设置界面,选择AI模型为:qwen3:1.7b,关联知识库选择刚才创建的知识库。然后其他信息按需填写,最后点击右上角的【发布】按钮就可以了。
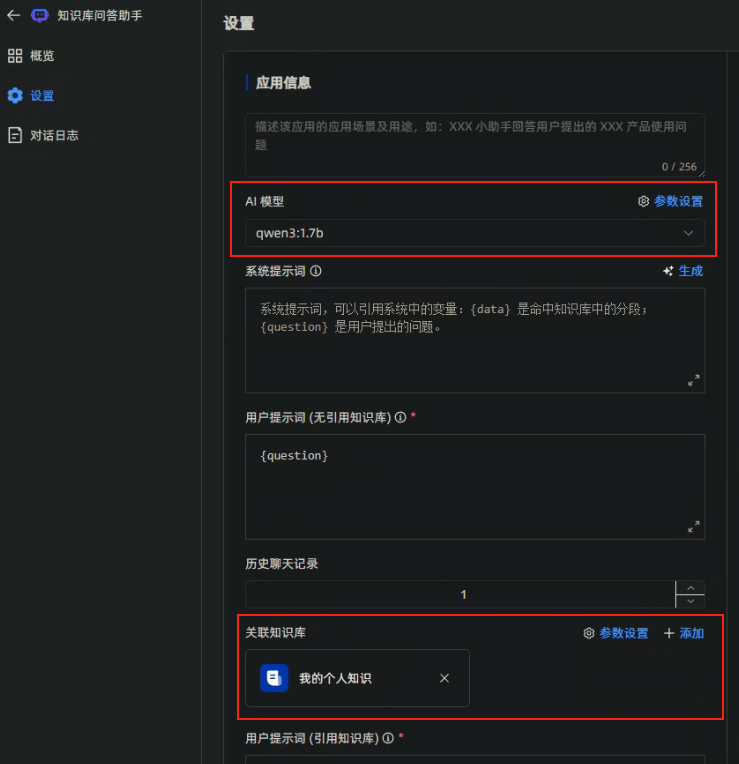
简单测试下
发布成功后,点击刚才创建的应用。
点击【去对话】按钮,跳转到对话界面,也可以复制上面的【公开访问链接】在浏览器中打开。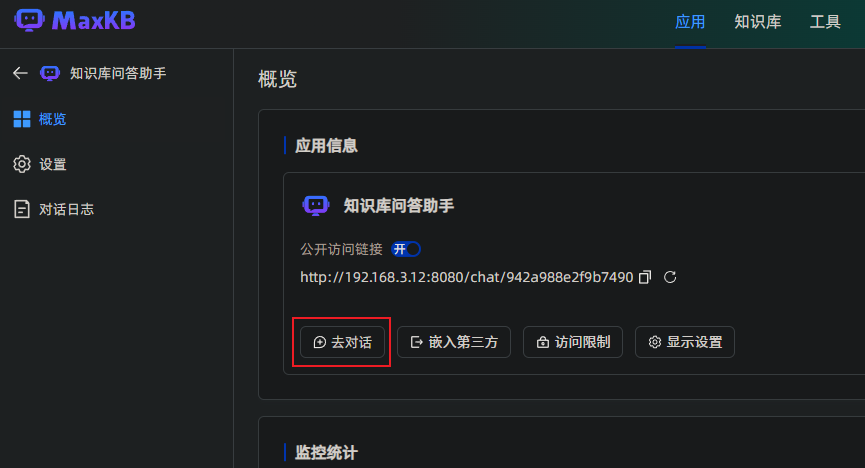
点击【显示设置】,勾选【显示知识来源】、【显示执行详情】两个按钮。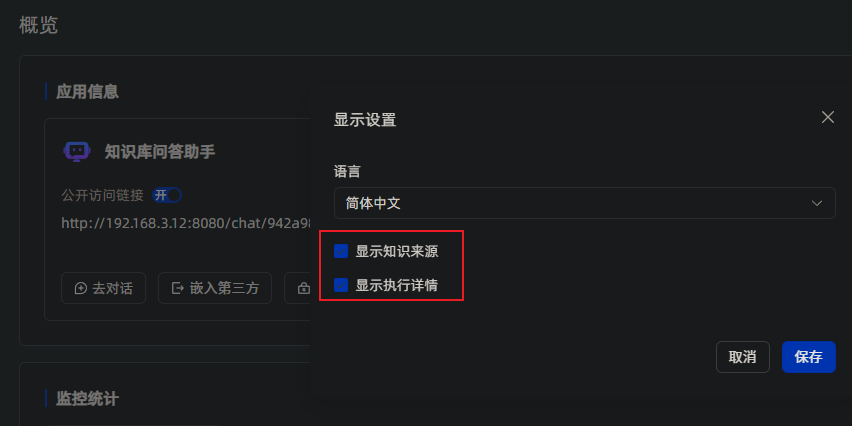
进入对话界面,继续询问:老李的手机号是什么? 如图所示可以正确得到老李的手机号,点击【执行详情】可以看到具体的执行信息。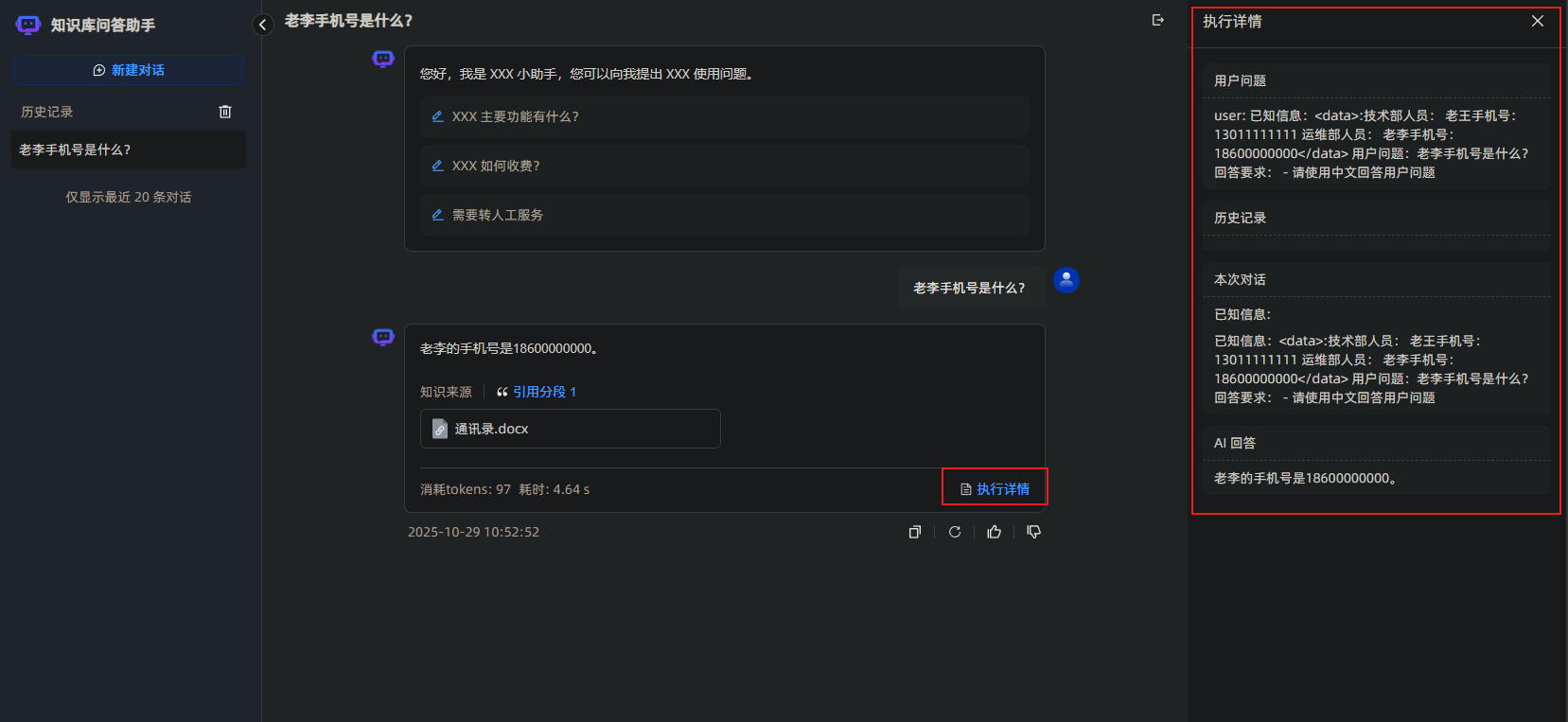
结语
通过上面对RAG相关技术及应用的介绍,你是否已经知晓和了解了RAG相关知识了呢。如果你有其他问题,请留言评论。有帮助的话,请帮忙点赞、评论、转发,一键三连,谢谢支持。
如果你有安全生产、园区管理、食品安全监管相关的需求,我们可提供成熟的方案,聚焦AI + 行业融合,帮你省心省力创价值。