

HTTP 协议
1. HTTP 是什么
虽然我们说应用层协议是我们程序猿自己定的,但实际上,已经有大佬们定义了一些现成的,又非常好用的应用层协议,供我们直接参考使用。HTTP 就是其中之一,HTTP 全称 HyperText Transfer Protocol(超文本传输协议),它是一个 应用层协议,专门规定了浏览器和服务器之间怎么对话。简单来说,就是:
- 浏览器(客户端):“我要资源 A。”
- 服务器:“好的,给你资源 A。”
HTTP 负责 传输规则,至于你传的是 HTML、图片、视频、JSON,它根本不管。
2. 工作流程
HTTP 基本流程就是 请求-响应模型:
- 客户端发起请求(Request)。
- 服务器返回响应(Response)。
请求和响应里,都是一堆 报文(Headers + Body),有点像两个人通信时带着信封和正文。
3. 认识 URL
URL(统一资源定位符,Uniform Resource Locator)其实就是“网络上的地址”,就像现实生活中的“国家 → 城市 → 街道 → 门牌号”。 它一共有 7 个部分,每个部分都有职责。我们用一个例子来拆开看:

1. 协议方案名(scheme)
作用:指定使用哪种协议来访问资源。这是整个 URL 的“开头”,告诉浏览器该用什么方式去获取资源。常见值:
http:超文本传输协议(不加密)。https:安全的 HTTP(加密)。ftp:文件传输协议。mailto:发送邮件。file:本地文件。
2. 登录信息(认证信息)
作用:有些协议可以在 URL 中写用户名和密码,用来登录。格式:username:password@,比如:http://admin:123456@myserver.com。注意:现在几乎不用了,因为明文暴露账号密码,巨危险。现代认证一般靠 Token、Cookie、OAuth。
3. 服务器地址(host)
作用:指定目标服务器的域名或 IP 地址。说明:可以是域名(如 www.example.jp),也可以是 IP 地址(如 192.168.1.1),浏览器先通过 DNS 把域名解析成 IP,再去找目标机器。例如:www.baidu.com 就是百度的域名。
网络通信的关键是 IP 和端口号,所以只要知道某个网站的 IP 地址 和它运行服务的 端口号(通常是 80 或 443),就可以直接通过这个 IP 访问它。当然也存在不能访问的情况:服务器直接禁止使用 IP 地址访问、端口未开放、需要额外身份验证或配置等。域名 = IP 的“人类友好版本”,人记不住 39.156.70.37 这样的数字,所以发明了 域名系统 DNS,当输入 baidu.com 时,DNS 会自动查出它对应的 IP 地址 → 39.156.70.37,这就是所谓的:
- 序列化:把
baidu.com转成39.156.70.37(解析) - 反序列化:把
39.156.70.37映射回baidu.com(反向查询)
但注意:域名本身不包含端口信息。端口默认是 80(HTTP)或 443(HTTPS),除非特别指定。
4. 服务器端口号(port)
作用:指定服务器上监听的端口,一般情况下 URL 里省略不写。如果省略,则使用默认端口,HTTP 默认端口是 80,HTTPS 默认端口是 443。如果用了非默认端口,必须写出来,否则无法连接,格式: IP 地址:端口号
5. 文件路径(path)
作用:指定服务器上资源的具体路径(类似文件夹结构)。说明:大多数情况下路径从根目录开始(以 / 开头),表示要访问的网页、图片、API 接口等,但也可以配置非根目录下。
6. 查询字符串(Query String)
作用:向服务器传递额外参数,常用于搜索、筛选、用户标识等。通常在 GET 请求里用,格式是 key=value,多个参数用 & 连接,例如:?search=Python&page=2 表示搜索 Python 第 2 页。特点:
- 参数由
&分隔 - 键值对之间用
=连接 - 会被发送到服务器,但不会保存在页面中(除非显式存储)
7. 片段标识符(fragment)
片段标识符又叫 锚点,作用: 表示页面里的某个位置(控制页面滚动位置)。浏览器拿到页面后,会自动滚动到对应的位置(比如某一章节)。注意:片段不会传给服务器,它只在客户端(浏览器)起作用。
所以 URL 的 7 个部分完整结构:
协议://登录信息@服务器地址:端口号/路径?查询字符串#片段。
4. urlencode 和 urldecode
urlencode 是把不安全或特殊字符转成 “URL 能安全传输” 的格式;urldecode 是把它还原回来。
像 /?: 等这样的字符,已经被 URL 当做特殊意义理解了,因此这些字符不能随意出现,比如某个参数中需要带有这些特殊字符,就必须先对特殊字符进行转义。
转义的规则如下:将需要转码的字符转为 16 进制,然后从右到左,取 4 位(不足 4 位直接处理),每 2 位做一位,前面加上%,编码成 %XY 格式。
两个工具 站长之家 或 Json 格式化 可观察编码和解码的结果。
5. HTTP 请求和响应
1. 请求和响应报文的结构
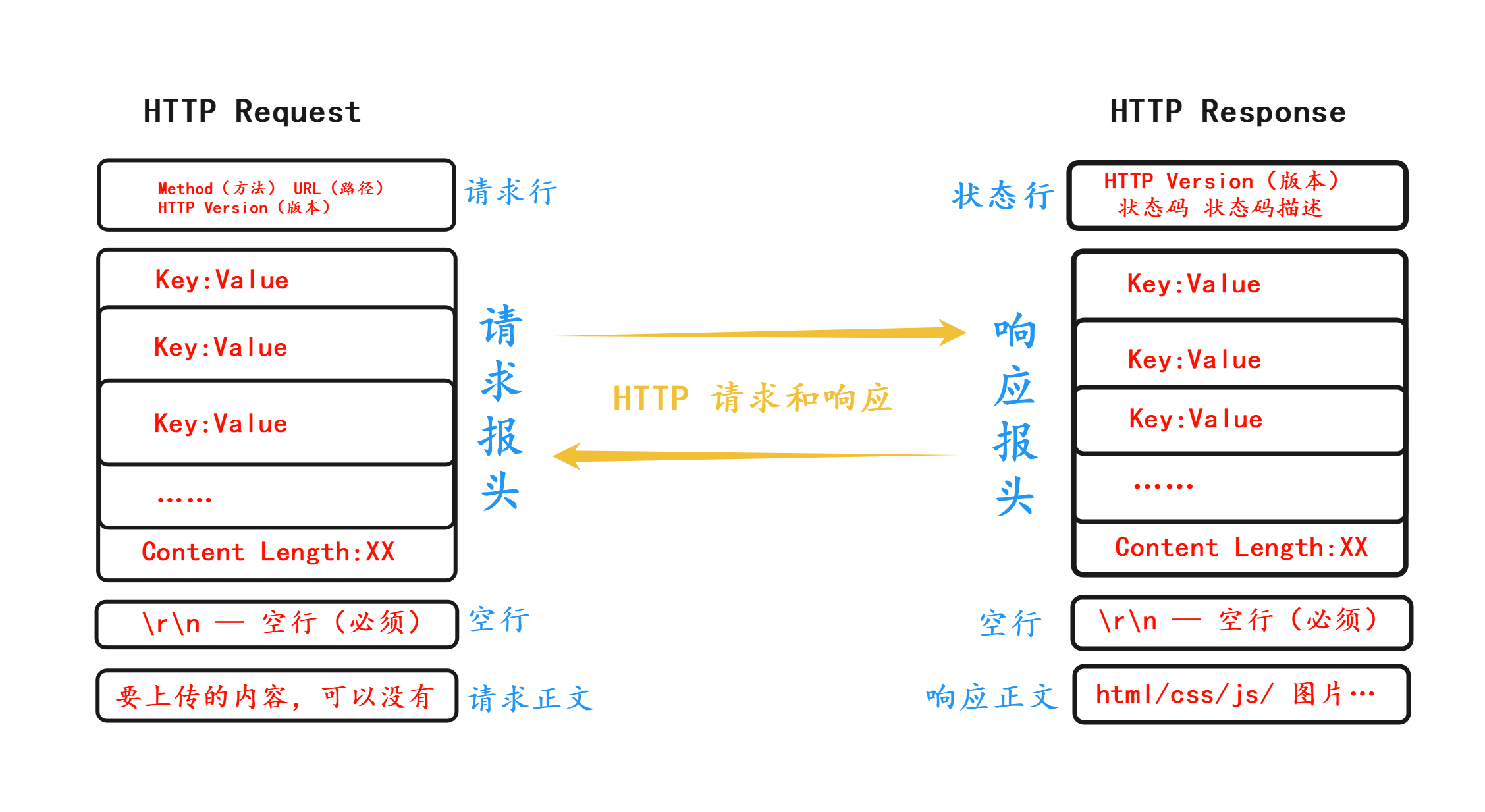
HTTP 请求报文结构
┌───────────────────────────────────────────┐
│ <method> <request-target> <http-version> │ ← 请求行 (Request Line)
├───────────────────────────────────────────┤
│ Header-Name: Header-Value │
│ Header-Name: Header-Value │ ← 请求头部 (Request Headers)
│ ... │
│ Content-Length: <length> │
├───────────────────────────────────────────┤
│ │ ← 空行 (CRLF: \r\n)
└───────────────────────────────────────────┘
┌───────────────────────────────────────────┐
│ <request-body> │ ← 请求体 (可选)
└───────────────────────────────────────────┘
HTTP 响应报文结构
┌───────────────────────────────────────────┐
│ <http-version> <status-code> <reason-phrase> │ ← 状态行 (Status Line)
├───────────────────────────────────────────┤
│ Header-Name: Header-Value │
│ Header-Name: Header-Value │ ← 响应头部 (Response Headers)
│ ... │
│ Content-Length: <length> │
├───────────────────────────────────────────┤
│ │ ← 空行 (CRLF: \r\n)
└───────────────────────────────────────────┘
┌───────────────────────────────────────────┐
│ <response-body> │ ← 响应体 (可选)
└───────────────────────────────────────────┘
1. HTTP 请求报文结构
整体格式:见上图,共有 请求行、请求头部、空行、请求正文/请求体(可选) 4 部分。
1. 请求行
格式: Method URL HTTP-Version。
-
Method(方法):请求方法,表示操作类型,说明要对资源做什么操作,常见方法:
GET(获取资源)、POST(提交数据)、PUT(更新资源)、DELETE(删除资源)、HEAD(获取头部信息)、OPTIONS(查询支持的方法)等。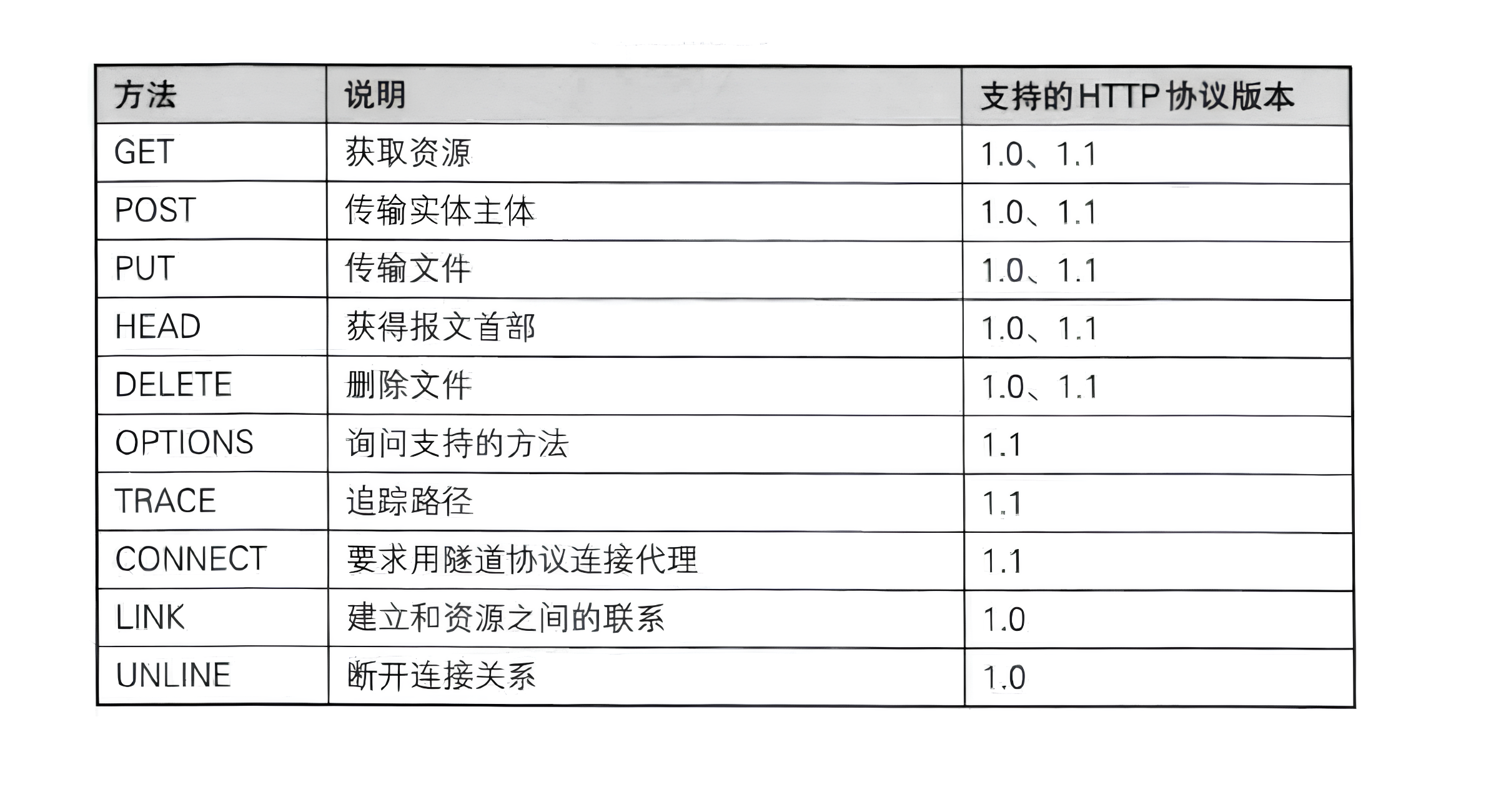
-
URL(路径):请求的目标资源的位置/路径,比如
/index.html、/api/user。 -
HTTP-Version(协议版本):常见
HTTP/1.0、HTTP/1.1、HTTP/2、HTTP/3。
HTTP/1.0:早期版本,性能较差。HTTP/1.1:目前最广泛使用的版本。HTTP/2:提升性能,支持多路复用。HTTP/3:基于 UDP,进一步优化延迟”。
2. 请求头部
由 若干个 Key: Value 形式的键值对 组成,每行一个,描述请求的 元信息,用于传递客户端的附加信息。
常见头部字段:
Host: 指定请求的目标主机名(必须存在)User-Agent: 标识客户端软件(如浏览器类型)Content-Type: 指明请求体的媒体类型(如application/json、application/x-www-form-urlencoded)Content-Length: 请求体的字节数(若使用Transfer-Encoding: chunked可省略)Authorization: 认证信息(如 Bearer Token)Cookie: 发送存储在客户端的 Cookie
头部字段不区分大小写,但通常首字母大写(如
Content-Type) 。
3. 空行
用 \r\n(回车 + 换行)表示,必须存在,用于分隔请求头和请求体。如果没有空行,服务器无法判断头部结束,会解析出错。
4. 请求正文/体
可选,用于存放实际传给服务器的数据。
2. HTTP 响应报文结构
整体格式:见上图,有 状态行、响应头、空行、响应正文/响应体 4 部分。
1. 状态行
HTTP-Version Status-Code Reason-Phrase
-
HTTP-Version:同上,常见
HTTP/1.0、HTTP/1.1、HTTP/2、HTTP/3。 -
Status-Code(状态码):三位数字,表示处理结果。
常见:
200成功、301永久重定向、404未找到资源(客户端错误)、500服务器内部错误。 -
Reason-Phrase:状态码的简短文字描述,比如
OK、Not Found。
2. 响应头部
同样是若干个 Key: Value 格式的键值对,描述服务端返回数据的元信息。
常见字段:
Content-Type: 响应体的媒体类型(如text/html、application/json)。Content-Length: 响应体的字节数。Server: 服务器软件信息(如 Apache、Nginx)。Set-Cookie: 设置客户端 Cookie。Location: 重定向地址(配合 3xx 状态码)。Cache-Control: 缓存策略。Date: 响应生成时间。
3. 空行
同样用 \r\n 表示,必须存在,用于分隔响应头和响应体。
4. 响应正文/体
服务器返回的实际内容。类型取决于 Content-Type:
text/html→ HTML 页面application/json→ JSON 数据image/png→ 图片二进制video/mp4→ 视频流
2. 网络调试工具
| 工具 | 定位 | 主要用途 |
|---|---|---|
| Fiddler | 专业抓包代理(被动监听/拦截) | 捕获流量、调试网络、分析问题 |
| Postman | API 客户端(主动请求) | 构造请求、测试接口、管理 API |
在 Linux 中,telnet 是一个基于 TCP 协议的远程登录与调试工具。简单说来,它就像一个 万能的 TCP 客户端,可以用它连接到任意 TCP 服务(HTTP、Redis……),然后手动输入命令。注意:Telnet 是明文传输,数据不加密,所以要小心使用,我们一般仅用来调试网络服务、测试端口连通性、模拟发送请求。 安装命令:
sudo yum install -y telnet # -y 表示自动安装,不需要确认
sudo yum install telnet
基本语法:
# telnet [主机名或IP地址] [端口号],比如:
telnet baidu.com 80
# 连通后的示例输出:
Trying 220.181.7.203...
Connected to baidu.com.
Escape character is '^]'.
注意:如果省略端口号,默认连接远程主机的 23 端口(Telnet 服务默认端口)。退出 Telnet 连接: Telnet 交互界面中,按 Ctrl + ] 进入命令模式,然后输入 quit 退出。
3. 一个简单的 HTTP 服务器 Demo
#pragma once
#include <iostream>
#include <string>
#include <unordered_map>
#include <fstream>
#include <sstream>
#include <sys/types.h>
#include <sys/socket.h>
#include <vector>
#include "Socket.hpp"
#include "Log.hpp"
static const uint16_t default_port = 8082; // 服务器默认监听端口
const int BUFFER_SIZE = 10240; // 缓冲区大小,用于接收 HTTP 请求
const std::string wwwroot = "./wwwroot"; // Web 根目录,所有静态资源都放在这个文件夹下
const std::string home_page = "index.html"; // 主页文件名
const std::string sep = "\r\n"; // HTTP 请求行和头之间的分隔符
class Thread_Data
{
public:
Thread_Data(int fd) // 构造函数:保存客户端 socket 文件描述符
: sockfd(fd)
{}
public:
int sockfd; // 客户端连接的 socket fd
};
// HTTP 请求类
class HTTP_Request
{
public:
std::vector<std::string> req_header;
std::string text;
// 解析结果
std::string method; // 请求方法
std::string url; // 请求 URL
std::string version; // HTTP 版本
std::string file_path; // 请求文件路径
public:
// HTTP_Request()
// {
// }
void Deserialize(std::string req)
{
while(true)
{
std::size_t pos = req.find(sep); // 查找每行的结束位置(\r\n)
if(pos == std::string::npos) // 找不到
{
break;
}
std::string temp = req.substr(0, pos); // 提取当前行
if(temp.empty())
{
break; // 空行表示请求头结束
}
req_header.push_back(temp);
req = req.substr(pos + 2); // 去掉当前行和分隔符
}
text = req; // 剩余部分是请求正文,可能为空
}
void Parse()
{
std::stringstream ss(req_header[0]); // 将请求行解析为字符串流
ss >> method >> url >> version; // 解析请求行
file_path = wwwroot; // 默认请求文件路径为 wwwroot
if(url == "/" || url == "index.html") // 请求根目录或主页
{
file_path += ("/" + home_page); // 文件路径为 wwwroot/index.html
}
else
{
file_path += url; // 请求文件路径为 wwwroot/url
}
}
void DebugPrint()
{
for(auto &it : req_header)
{
std::cout << it << "\n\n";
}
std::cout << "method: " << method << std::endl;
std::cout << "url: " << url << std::endl;
std::cout << "version: " << version << std::endl;
std::cout << "text: " << text << std::endl;
}
};
// HTTP 服务器类
class HTTP_Server
{
private:
Sock listensock_; // 监听 socket 封装对象
uint16_t port_; // 服务器监听端口号
std::unordered_map<std::string, std::string> content_type; // MIME 映射表
public:
HTTP_Server(uint16_t port = default_port) // 构造函数:初始化监听端口
: port_(port)
{
}
~HTTP_Server()
{
}
// 启动服务器,进入主循环:监听 -> 接收连接 -> 为连接分配线程处理
void Start()
{
listensock_.Socket(); // 创建监听 socket
listensock_.Bind(port_); // 绑定端口
listensock_.Listen(); // 开始监听
for (;;)
{
std::string clientip;
uint16_t clientport;
// 接受一个新连接(阻塞等待)
int sockfd = listensock_.Accept(&clientip, &clientport);
if (sockfd < 0)
{
continue; // 失败则跳过,继续等待下一个连接
}
log_(Info, "get a new connect, sockfd: %d", sockfd);
// 为每个连接分配一个线程进行处理
pthread_t tid;
Thread_Data* td = new Thread_Data(sockfd);
pthread_create(&tid, nullptr, Thread_Run, td);
}
}
// 处理 HTTP 请求:读取请求报文,构造并发送 HTTP 响应
static void HandlerHttp1(int sockfd)
{
char buf[BUFFER_SIZE];
ssize_t n = recv(sockfd, buf, BUFFER_SIZE - 1, 0); // 读取请求数据
if(n > 0)
{
buf[n] = '\0'; // 添加字符串结束符
std::cout << buf;
std::string text ="Hello Linux!"; // 响应正文内容
std::string response_line = "HTTP/1.1 200 OK\r\n"; // 状态行
std::string response_header = "Content-Length: "; // 响应头
response_header += std::to_string(text.size());
response_header += "\r\n";
std::string blank_line = "\r\n"; // 空行
std::string response = response_line;
response += response_header;
response += blank_line;
response += text;
send(sockfd, response.c_str(), response.size(), 0); // 发送响应
}
close(sockfd);
}
static std::string Read_Htmlfile(const std::string &path)
{
std::ifstream in(path);
if(!in.is_open())
{
return "404 Not Found";
}
std::string content;
std::string line;
while(std::getline(in, line))
{
content += line;
}
in.close();
return content;
}
static void HandlerHttp2(int sockfd)
{
char buf[BUFFER_SIZE];
ssize_t n = recv(sockfd, buf, BUFFER_SIZE - 1, 0); // 读取请求数据
if(n > 0)
{
buf[n] = '\0'; // 添加字符串结束符
std::cout << buf;
std::string text = Read_Htmlfile("wwwroot/index.html"); // 读取并构造响应正文内容
std::string response_line = "HTTP/1.1 200 OK\r\n"; // 状态行
std::string response_header = "Content-Length: "; // 响应头
response_header += std::to_string(text.size());
response_header += "\r\n";
std::string blank_line = "\r\n"; // 空行
std::string response = response_line;
response += response_header;
response += blank_line;
response += text;
send(sockfd, response.c_str(), response.size(), 0); // 发送响应
}
close(sockfd);
}
static void HandlerHttp3(int sockfd)
{
char buf[BUFFER_SIZE];
ssize_t n = recv(sockfd, buf, BUFFER_SIZE - 1, 0); // 读取请求数据
if(n > 0)
{
buf[n] = '\0'; // 添加字符串结束符
std::cout << buf;
HTTP_Request req;
req.Deserialize(buf);
req.Parse();
req.DebugPrint();
std::string text = Read_Htmlfile(req.file_path); // 读取并构造响应正文内容
std::string response_line = "HTTP/1.1 200 OK\r\n"; // 状态行
std::string response_header = "Content-Length: "; // 响应头
response_header += std::to_string(text.size());
response_header += "\r\n";
std::string blank_line = "\r\n"; // 空行
std::string response = response_line;
response += response_header;
response += blank_line;
response += text;
send(sockfd, response.c_str(), response.size(), 0); // 发送响应
}
close(sockfd);
}
static void HandlerHttp4(int sockfd)
{
char buf[BUFFER_SIZE];
ssize_t n = recv(sockfd, buf, BUFFER_SIZE - 1, 0); // 读取请求数据
if(n > 0)
{
buf[n] = '\0'; // 添加字符串结束符
std::cout << buf;
HTTP_Request req;
req.Deserialize(buf);
req.Parse();
req.DebugPrint();
bool flag = true;
std::string text = Read_Htmlfile(req.file_path); // 读取并构造响应正文内容
if(text.empty())
{
flag = false;
std::string err_thml = wwwroot + "/err.html";
text = Read_Htmlfile(err_thml);
}
std::string response_line; // 状态行
if(flag)
{
response_line = "HTTP/1.1 200 OK\r\n";
}
else
{
response_line = "HTTP/1.1 404 Not Found\r\n";
}
std::string response_header = "Content-Length: "; // 响应头
response_header += std::to_string(text.size());
// 示例:重定向(可取消注释使用)
//response_header += "Location: https://minbit.top\r\n";
response_header += "\r\n";
std::string blank_line = "\r\n"; // 空行
std::string response = response_line;
response += response_header;
response += blank_line;
response += text;
send(sockfd, response.c_str(), response.size(), 0); // 发送响应
}
close(sockfd);
}
// 线程运行函数:分离线程 -> 调用处理函数 -> 清理资源
static void* Thread_Run(void* args)
{
pthread_detach(pthread_self()); // 分离线程,自动回收资源
Thread_Data* td = static_cast<Thread_Data*>(args);
// 调用服务器请求处理函数,这里可以选择HandlerHttp1、HandlerHttp2、HandlerHttp3、HandlerHttp4进行不同处理
// 然而,这些方法并不能使网页上的图片进行显示,原因是图片的Content-Type类型并没有被设置,因此需要在 HTTP 响应头中添加 Content-Type 字段
// 于是我创建了HTTP_Server_image.hpp对图片(二进制)的处理,并在HTTP_Server_image.cc中调用HTTP_Server_image.hpp的处理函数
HandlerHttp4(td->sockfd);
delete td; // 释放申请的 Thread_Data
return nullptr;
}
};
由于文件较多,不便展示,这里仅展示关键代码,完整代码详见 GitHub。食用方法:浏览器输入对应的 IP 和端口(示例:主机 IP:端口号),可选访问的路径,但是路径不存在就无法访问。👉 简单的 HTTP 服务器 Demo 演示 | B 站演示。下面简单了解一下 HTTP 请求的请求头:
User-Agent(用户代理)是服务器判断客户端身份的关键依据:一方面,爬虫可以通过伪装成真实浏览器的 User-Agent(如 Chrome、Edge 等)来绕过反爬虫机制,避免被封禁;另一方面,网站会根据 User-Agent 中包含的操作系统(如 Windows、Android)和设备类型,在浏览器中会自动推送对应版本的下载链接或适配页面,实现“你用什么设备访问,就给你什么内容”。
6. Cookie 和 Session
【HTTP】Cookie 和 Session 详解 | CSDN
Cookie、Session、Token 究竟区别在哪?如何进行身份认证,保持用户登录状态? | B 站
浏览器是如何既保护又泄漏你的隐私? | 从 Cookie、第三方 Cookie 到浏览器指纹 | B 站
【白】竟然有这么多人不知道 cookie 是什么?雷普了! | B 站
[!TIP]
上面的视频讲解非常详细,强烈建议观看,下面直接给结论,就不解释原因了。
1. Cookie 基础
- 本质:存放在浏览器端的小型文本数据(
key = value格式),随请求头自动带到服务端。 - 用途:
- 记录用户身份(保持登录状态)。
- 存储用户偏好(语言、主题)。
- 实现统计/追踪(广告、分析)。
- 分类:
- 会话 Cookie(内存级):存放在内存中,关闭浏览器就没了。
- 持久 Cookie(文件级):写到磁盘里,有过期时间,可以长期保存。
- 重要属性:
Expires/Max-Age:过期时间。HttpOnly:JS 不能访问,防止 XSS。Secure:只能在 HTTPS 传输。SameSite:防止 CSRF 攻击。
2. Session 基础
- 本质:存在 服务器端 的一份用户状态数据,通常用来保存登录信息、购物车等。
- 关联方式:服务端会生成一个
session_id,通过 Cookie(或 URL 参数)传给浏览器。下次请求时,浏览器带上session_id,服务端根据它找到该用户对应的 Session 数据。 - 特点:
- 更安全(数据不在客户端存,只保存一个 ID)。
- 存储空间大(由服务器控制,不受 Cookie 4KB 限制)。
- 需要服务器内存/数据库支持。
3. Cookie vs Session
| 特点 | Cookie (客户端存) | Session (服务端存) |
|---|---|---|
| 存储位置 | 浏览器 | 服务器 |
| 存储容量 | 单个 4KB,数量有限 | 理论无限,取决于服务器资源 |
| 安全性 | 容易被窃取/篡改,需要加密 | 更安全,客户端只保存一个 ID |
| 生命周期 | 由过期时间控制 | 一般随会话/服务器配置而定 |
| 常见用途 | 记住登录状态、个性化配置 | 登录态验证、购物车、权限控制 |
4. 扩展
- 为什么需要 Session,不能只靠 Cookie?
- Cookie 存储在客户端,容易篡改、不安全,且存储空间有限;Session 更适合保存关键业务数据。
- Session 的实现原理?
- 服务端维护一个
session_id -> 数据的映射表。客户端每次请求时带上session_id(通常在 Cookie 里),服务端根据这个 ID 找回对应数据。
- 服务端维护一个
- Cookie 被禁用了怎么办?
- 可以把
session_id放到 URL 参数里,但安全性差,一般结合其他手段。
- 可以把
- 分布式部署时 Session 怎么保持一致?
- 需要做 Session 共享/持久化,常用方法是把 Session 存在 Redis、数据库里,所有服务器共享。
- Token(JWT)和 Session 的区别?
- Session:状态保存在服务器。
- Token(JWT):状态保存在客户端(自包含),服务端只做校验,不保存状态,更适合分布式/无状态架构。
