

网络编程套接字
1. 预备知识
1. 源 IP 地址 & 目的 IP 地址
- 是什么:
- 负责 跨网络 的全球寻址,由 路由器 使用。
- 源 IP:发件人所在的“城市 + 街道”的网络位置。
- 目的 IP:收件人所在的网络位置。
- 理解:
- 在互联网中,IP 就是定位“哪台主机”。
- 源 IP 说的是 “我是从哪里发的”,目的 IP 说的是 “我要送到哪去”。
2. 源 MAC 地址 & 目的 MAC 地址
- 是什么:
- MAC 是网卡的身份证,唯一标识一块网卡。负责 局域网内 的设备寻址,由 交换机 使用。
- 源 MAC:是当前发出这个数据帧的设备(比如你家的路由器或你的电脑)的网卡物理地址。
- 目的 MAC:是 当前这一跳 要送达的设备(比如你家的路由器,或者下一个网络的交换机)的网卡物理地址。
- 理解:
- MAC 负责在 同一个局域网 里找到对方机器。即使两个设备的 IP 地址在不同网段,中间的路由器也会逐跳修改 MAC 地址来转发数据。
- 示例:MAC 地址只在“本地”有效。就像快递从你家送到小区快递站,靠的是小区内部的三轮车(车牌号 A),这时“目的 MAC”是快递站;当快递从上海发往北京时,负责这段运输的是一辆大货车(车牌号 B),这时“目的 MAC”就是北京的中转仓库。IP 地址不变(收件人始终是北京的朋友),但每一段路的“运输车”(MAC 地址)都在变。
3. 源端口号 & 目的端口号
- 是什么:
- 负责 主机内部 的应用程序寻址,由 操作系统 使用。
- 目的端口号:是服务的“电话号码”。比如你想访问网页,就打 80 号(HTTP);想传文件,就打 21 号(FTP)。它告诉目标主机:“我要找你家哪个应用程序!”
- 源端口号:是你这边临时生成的一个“回拨号码”。比如你的电脑随机选了个 50000 号。它告诉对方:“我找你家的 21 号(FTP),你回复我的话,请打 50000 号。”
- 理解:
- 示例:一台电脑上可能同时有微信、浏览器、游戏等多个程序在上网。IP 地址只能把包裹送到“这台电脑”,而 端口号决定了这个包裹具体是给微信、还是给浏览器的。它实现了“一台主机,多程序同时通信”。
[!NOTE]
为什么引入“端口”而不是直接使用进程 PID?
我们发现端口和进程的 pid 十分相似,都能用于标识程序(进程)的唯一,那么为什么引入“端口”而不是直接使用进程 PID?
1. 端口 ≠ PID
- PID(进程 ID):操作系统内部标识某个正在运行的进程,只在本机有效,并且随 OS 调度,每次执行的 pid 都不同。
- 端口号:网络通信里的标识符,用来告诉 接收到的数据包应该交给哪一个程序。它必须有几个特点:
- 跨主机一致性:同一个端口号在不同机器上也能表示同类服务(比如 HTTP 默认端口 80)。
- 协议无关:端口号只和 TCP/UDP 协议挂钩,不依赖操作系统的 PID 管理。
- 隔离与安全:用户程序不能直接访问其他进程的 PID,而端口号可通过系统分配公开给网络层使用。
2. 为什么不直接用 PID?
- 解决跨主机问题:PID 是本地可变的,不同主机 PID 没意义,网络发包会搞不清楚收件程序是谁,而端口是网络通用的。
- 实现服务抽象:端口号提供抽象层,让网络层只关心“哪条程序逻辑要接收数据”,不关心 OS 如何调度进程。端口标识服务类型(如 Web、邮件),而不是具体的进程实例。
- 降低耦合性:传输层协议只依赖端口,不依赖操作系统的 PID,实现了协议栈的分层和解耦。
- 标准化服务:一些端口号有固定含义(如 HTTP 80,HTTPS 443),不同机器、不同系统都能互相理解,服务可以更换软件、重启,只要端口不变,对外服务就不中断,而 PID 没法做到这一点。
所以:
- PID = 家里某个家庭成员的身份证号 → 对邮局毫无意义。
- 端口号 = 房间号 → 邮递员知道把信送到哪个房间,不管家庭成员是谁。
端口号把“进程内部细节”和“网络通信”隔离开,保证协议跨主机可用,降低耦合。
所以他们的关系就像送快递:
- IP 地址 = 总快递单 → 从发货到收货,全程都指向同一个目的地(不变)。
- MAC 地址 = 中转贴纸 → 每经过一站,都会换成下一站的发件人/收件人(一直变化:Mac 地址出局域网之后,源和目都要被丢弃,让路由器重新封装)。
- 端口号 = 楼里具体的房间号(找准哪个程序收)。
4. TCP VS UDP(直观认识,后面详细讨论)
1. TCP:像“打电话”或“挂号快递”
- 有连接:就像打电话,你必须先拨号(建立连接),等对方说“喂,你好”(连接确认)之后,你们才能开始说话。通信结束时,还要说“再见”(断开连接)。
- 传输可靠:就像寄挂号快递。快递公司会确保包裹(数据)一定能送到,并且是完整无损的。如果路上丢了,他们会帮你找回或重寄。在 TCP 中,数据发送后,接收方必须回复“我收到了”(确认应答),如果没收到回复,发送方就会重发。
- 面向字节流:就像你们在电话里连续不断地说话,没有明确的“段落”划分。TCP 把数据看作一个连续的、没有固定边界的“字节流”。你发了“你好”和“世界”,接收方可能收到“你好世”和“界”,也可能收到“你好世界”,它需要自己判断消息的边界(这叫“粘包”问题,需要应用层自己解决)。
TCP:可靠、有序、有连接。适合对数据准确性要求高的场景,比如:网页浏览(HTTP/HTTPS)、文件下载、发送邮件。
2. UDP:像“发短信”或“普通平邮”
- 无连接:就像发短信,你不需要先打电话确认对方开机,直接输入内容发送就行。UDP 发送数据前,不需要和对方建立任何连接。
- 传输不可靠:就像发普通平邮。你把信(数据包)投进邮筒就完事了,至于信会不会丢、会不会被撕坏、会不会晚到,邮局(网络)不保证。UDP 发送数据后,不会管对方有没有收到。
- 面向数据报:就像每条短信都是一个独立的“数据包”。你发一条“你好”,就是一条完整的信息;再发一条“世界”,是另一条独立的信息。接收方收到的就是一个个完整、有明确边界的“数据报”,不会出现“粘包”或“拆包”的问题。
UDP:快速、简单、无连接、不保证可靠。适合对速度要求高、能容忍少量丢失的场景,比如:在线视频/语音通话(QQ、微信)、直播、网络游戏、DNS 查询。
[!IMPORTANT]
- TCP:追求“必须送到,且顺序正确”,所以慢但稳。
- UDP:追求“快,立刻发出去”,所以快但可能丢。
5. 网络字节序
1. 发展与由来
- 大小端的起源:大小端源于计算机内部多字节数据(如整数)在内存中的存储方式差异。这种 多字节数据在内存中存放顺序 差异源于早期 CPU 架构设计,并无绝对优劣,CPU 在内部处理数据时,按自己的方式最方便,高效,却也导致不同硬件平台存在分歧。
- 大端:数据的 高位字节 存储在 低内存地址,低位字节存储在高地址(类似人书写数字的顺序,如
0x1234存储为12 34)。 - 小端:数据的 低位字节 存储在 低内存地址,高位字节存储在高地址(如
0x1234存储为34 12)。
- 大端:数据的 高位字节 存储在 低内存地址,低位字节存储在高地址(类似人书写数字的顺序,如
- 网络字节序的诞生:当不同大小端的机器需要跨网络通信时,若直接发送原始字节流,接收方可能解析错误(例如小端机发送的
34 12被大端机解读为0x3412而非0x1234)。为解决此问题,TCP/IP 协议强制规定网络字节序统一为大端(也称“网络序”),确保所有设备在传输层达成一致。
2. 为何没有统一解决?
- 硬件设计的多样性:大小端的选择涉及 CPU 架构、性能优化和兼容性,历史上不同厂商有不同架构,没办法强制统一。
- 向后兼容性:改变现有系统的字节序会导致海量软件失效,成本过高。因此,只能通过协议层(如 TCP/IP)在传输时进行转换,而非根除底层差异。
3. 发送和接收
为了在不同 CPU 架构通信时,保证数字解释一致。网络协议规定统一字节序:TCP/IP 定义 大端字节序(最高有效字节在最前面),从而屏蔽了硬件差异。即:不管本机是大端还是小端,都要转换成大端再发送。
- 发送端:
- 大端机 → 直接发送。
- 小端机 → 先把数据转成大端再发。
- 接收端:
- 收到数据 → 如果本机是小端机,再把数据转成小端处理。
执行以下代码,进行内存测试即可验证自己机器的大小端。
#include <iostream> using namespace std; int main() { unsigned int x = 0x12345678; unsigned char* p = (unsigned char*)&x; if (p[0] == 0x12) { cout << "大端" << endl; } else { cout << "小端" << endl; } return 0; }
2. socket 编程接口
套接字就是操作系统给程序和网络接口之间的一层统一抽象。
1. 为什么要抽象套接字
套接字是操作系统提供的一个编程接口(API),用于实现不同场景下的通信。根据通信范围和需求,主要分为三类:
- 域间套接字:用于同一台主机内部的进程间通信(IPC)。不走网络协议栈,通过文件系统中的一个特殊文件作为通信端点,效率远高于网络套接字。
- 网络套接字: 用于不同主机之间的网络通信,比如个人电脑和百度服务器,使用 IP 地址 + 端口号 来定位目标(常见、广泛)。
- 原始套接字: 允许程序直接访问底层网络协议(如 IP、ICMP),通常用于开发网络工具(如
ping)或需要自定义协议头的场景。它绕过了传输层(TCP/UDP)。
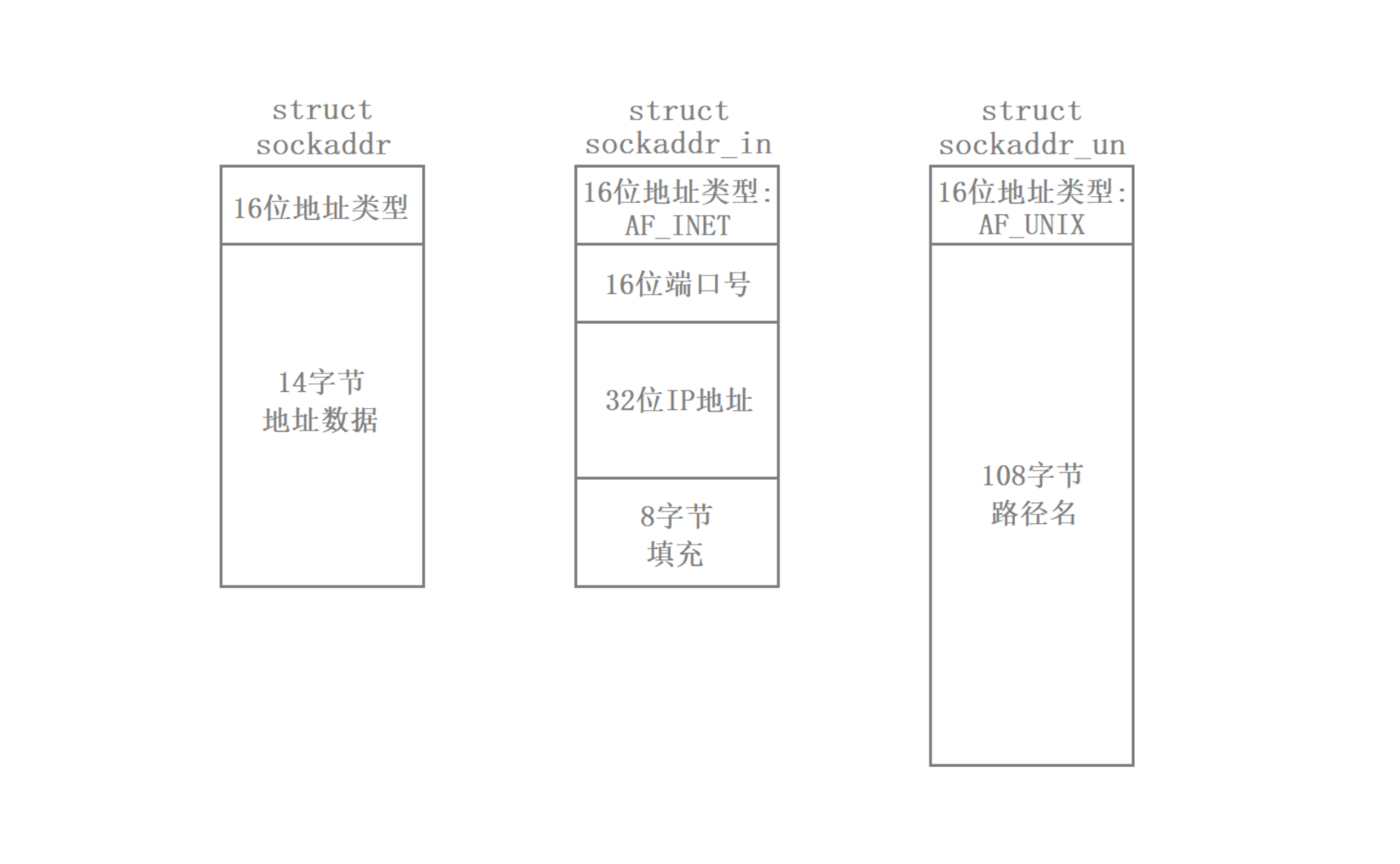
系统调用希望 函数原型统一,而不是每种地址类型写一个不同函数。因此套接字提供了 sockaddr_in 结构体和 sockaddr_un 结构体,其中 sockaddr_in 结构体是用于跨网络通信的,而 sockaddr_un 结构体是用于本地通信的。
为了让套接字的网络通信和本地通信能够使用同一套函数接口,于是就出现了 sockeaddr 结构体,它跟 sockaddr_in、sockaddr_un 的结构都不相同,但这三个结构体头部的 16 个比特位都是一样的,这个字段叫做协议家族。
2. socket —— 创建套接字
函数原型:
#include <sys/types.h>
#include <sys/socket.h>
int socket(int domain, int type, int protocol);
参数:
domain:地址族,常用AF_INET(IPv4)、AF_INET6(IPv6) 、AF_UNIX(本地)。type:套接字类型,常用SOCK_STREAM(TCP)、SOCK_DGRAM(UDP)。protocol:协议,通常设为 0(自动选择)。
返回值:成功返回套接字描述符(文件描述符,非负整数),失败 -1(需检查 errno)。
3. struct sockaddr_in —— IPv4 地址结构体
struct sockaddr_in 可以使用
man 7 ip命令进行查询。
结构体原型:
#include <sys/socket.h>
#include <netinet/in.h>
struct sockaddr_in
{
sa_family_t sin_family; // 地址族,必须是AF_INET
in_port_t sin_port; // 16位端口号(网络字节序),需用htons()转换
struct in_addr sin_addr; // 32位IP地址(网络字节序)
// unsigned char sin_zero[8]; // 通常不用,填充为0,使结构大小与sockaddr一致
};
struct in_addr
{
uint32_t s_addr; // 32位整数表示的IP地址(网络字节序)
};
简化理解:
struct sockaddr_in // IPv4 的地址结构体
├── sin_family // 地址族,AF_INET
├── sin_port // 端口号
├── sin_addr // IP 的结构体
├── s_addr // 实际 IP 地址
说明:
sin_family固定为 AF_INET。sin_port:范围为 0~65535,通常选择 1024 及以上,原因:0~1023是 知名端口(如 HTTP 的 80、FTP 的 21),属于系统内定的端口号,一般有固定的应用层协议使用,通常需要 root 权限才能绑定。1024~49151是 注册端口,用于特定服务(如 MySQL 的 3306)。49152~65535是 动态 / 临时端口,通常用于客户端随机分配。
struct in_addr内部包含一个 32 位无符号整数s_addr,表示 IPv4 地址(网络字节序)。INADDR_ANY(0.0.0.0网络字节序,无需额外转): 表示绑定任意本地地址,监听所有本地 IP。- 具体 IPv4 地址(如
192.168.1.100),需要通过inet_addr()或inet_pton()将字符串格式的 IP 转换为网络字节序:inet_addr("192.168.1.100"):直接返回网络字节序的 32 位地址。inet_pton(AF_INET, "192.168.1.100", &sin_addr):更推荐的现代方法(支持 IPv6)。
INADDR_LOOPBACK(不常用)表示本地回环地址,用于本地进程间通信。
注意:使用时需先初始化(用 bzero() 或 memset() 清零),避免随机值导致错误。初始化示例:
struct sockaddr_in addr;
bzero(&addr, sizeof(addr)); // 清零结构体
addr.sin_family = AF_INET; // IPv4
addr.sin_port = htons(8080); // 端口号(主机字节序转网络字节序)
addr.sin_addr.s_addr = INADDR_ANY; // 任意本地IP(0.0.0.0)
// 或指定IP: addr.sin_addr.s_addr = inet_addr("192.168.1.100");
4. bzero / memset —— 清零结构体内存
函数原型:
#include <strings.h>
void bzero(void *s, size_t n); // POSIX 接口,初始化 sockaddr_in
#include <cstring>
void *memset(void *s, int c, size_t n); // 推荐
使用示例(将内存块清零):
struct sockaddr_in addr;
bzero(&addr, sizeof(addr));
// 或
memset(&addr, 0, sizeof(addr));
5. htons/htonl/ntohs/ntohl —— 字节序转换函数(保证大小端传输/解析)
函数原型:
#include <arpa/inet.h>
uint16_t htons(uint16_t hostshort); // 主机short(字节序) → 网络short(字节序,端口用,短整型)
uint32_t htonl(uint32_t hostlong); // 主机long(字节序) → 网络long(字节序,IP用,长整型)
uint16_t ntohs(uint16_t netshort); // 网络short(字节序) → 主机short(字节序,短整型)
uint32_t ntohl(uint32_t netlong); // 网络long(字节序) → 主机long(字节序,长整型)
要点:参数就是所谓的端口号,端口用 htons(port);IPv4 32 位值用 htonl(x) 或 inet_addr()。
6. inet_addr / inet_aton / inet_ntoa / inet_pton / inet_ntop —— IP 地址转换函数
不使用函数,手动实现(推荐:结构体):网络编程套接字(一) | CSDN(荐)
函数原型:
#include <arpa/inet.h>
// 注意:使用 struct sockaddr_in 结构体时,要注意对应的转型!!
// IPv4:字符串 → 32位网络字节序IP
in_addr_t inet_addr(const char* cp); // 参数:IP 字符串(192.168.1.1)
// IPv4:字符串 → in_addr 结构(推荐替代 inet_addr)
int inet_aton(const char* cp, struct in_addr* inp); // 第二个参数就是 IP 的结构体(struct in_addr*)
// IPv4:网络字节序 in_addr → 字符串
char* inet_ntoa(struct in_addr in); // 参数:IP 的结构体(struct in_addr)
// 通用(推荐):字符串 → 地址结构(IPv4/IPv6)
int inet_pton(int af, const char* src, void* dst); // 参数依次是:地址族,IP 字符串,一个外部的缓冲区地址
// 通用(推荐):地址结构 → 字符串(IPv4/IPv6)
const char* inet_ntop(int af, const void* src, char* dst, socklen_t size);
// 参数依次是:地址族,IP 的结构体,一个外部的缓冲区地址,缓冲区大小
----------------------------------------------------------------------------------------------------------------------
// 使用示例:
struct sockaddr_in addr;
struct in_addr ip;
char buffer[16];
bzero(&addr, sizeof(addr)); // 清空结构体
addr.sin_family = AF_INET; // IPv4协议
addr.sin_port = htons(8080); // 设置端口(转网络字节序)
// 1. inet_addr: 字符串IP → 网络字节序整数(32位)
addr.sin_addr.s_addr = inet_addr("192.168.1.100");
// 2. inet_aton: 字符串IP → in_addr结构(更安全)
inet_aton("192.168.1.100", &addr.sin_addr);
// 3. inet_ntoa: in_addr → 字符串IP(注意:返回静态缓冲区)
printf("IP: %s\n", inet_ntoa(addr.sin_addr));
// 4. inet_pton: 字符串 → 二进制IP(推荐,支持IPv6)
inet_pton(AF_INET, "192.168.1.100", &addr.sin_addr);
// 5. inet_ntop: 二进制IP → 字符串(推荐,线程安全)
inet_ntop(AF_INET, &addr.sin_addr, buffer, sizeof(buffer));
简短实用:
- 转 IP → 网络字节序(二进制)
- IPv4:
inet_aton()✅ - IPv4/IPv6:
inet_pton()✅(推荐) - 一般不建议:
inet_addr()(出错返回值和合法地址可能混淆)
- IPv4:
- 转 网络字节序(二进制) → 字符串
- IPv4:
inet_ntoa()(返回静态区指针,非线程安全) - IPv4/IPv6:
inet_ntop()✅(推荐,线程安全)
- IPv4:
af参数:AF_INET→ IPv4。AF_INET6→ IPv6。
- IPv4 简单写:
inet_aton / inet_ntoa。- 兼容 IPv4/IPv6、线程安全:优先用
inet_pton / inet_ntop。
7. bind —— 绑定套接字与地址(服务器必做)
#include <sys/socket.h>
int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
参数:
sockfd:socket()返回的套接字描述符。addr:指向地址结构体的指针(通常传入sockaddr_in并强制转换为sockaddr*)。addrlen:地址结构体的长度/大小(sizeof(struct sockaddr_in))。
返回值:成功返回 0,失败返回 -1。
注意:服务器必须 绑定固定端口,客户端通常不需要(系统自动分配临时端口)。
1-7 的接口属于 TCP 和 UDP 共用,8-10 算是 TCP 的专用函数了。
8.
listen—— 服务器监听函数原型:
#include <sys/socket.h> int listen(int sockfd, int backlog);参数:
sockfd:已绑定的 TCP 套接字。backlog:等待连接队列的最大长度,通常设为 5-10(超过则新连接被拒绝)。返回值:成功返回
0,失败返回-1。9.
accept—— 服务器接受连接函数原型:
#include <sys/socket.h> int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen);参数:
sockfd:listen()监听的套接字。addr:输出参数,存储客户端地址(需预先分配空间)。addrlen:输入输出参数,传入addr大小,返回实际地址长度。返回值:成功返回 新的套接字描述符(专门用于与该客户端通信),失败返回
-1。注意:阻塞函数,若无连接则一直等待。
10.
connect—— 客户端连接服务器函数原型:
#include <sys/socket.h> int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen); // 参数:要连接的服务器地址,端口号,超时时间(用来设置连接尝试的最长时间)参数:与
bind()类似,但addr是服务器的地址。返回值:成功返回
0,失败返回-1。
11. 数据传输函数 send/recv —— TCP 收发
函数原型:
#include <sys/socket.h>
ssize_t send(int sockfd, const void *buf, size_t len, int flags);
ssize_t recv(int sockfd, void *buf, size_t len, int flags);
send→ 我要把这段数据,发 给已经连接的对方。recv→ 我要从已经连接的对方那里 接收 一段数据。
参数对比:
| 参数 | send 参数 | recv 参数 | 相同点 | 不同点 |
|---|---|---|---|---|
| 1. socket 文件描述符 | int sockfd | int sockfd | 都是已连接的套接字(由 accept() 或 connect() 得到) | 无 |
| 2. 数据缓冲区 | const void *buf | void *buf | 都是存放数据的内存区域 | send 的数据是 只读 的(要发出去),recv 的数据是 可写 的(接收进来) |
| 3. 缓冲区长度/大小(字节数) | size_t len | size_t len | 都表示操作的数据字节数 | 无 |
| 4. 标志位(一般为 0) | int flags | int flags | 都可设置特殊行为(如非阻塞、等待模式) | 一般用 0,也可指定 MSG_NOSIGNAL(send 阻止 SIGPIPE)或 MSG_WAITALL(recv 等到缓冲区填满才返回) |
返回值:
send():- 成功:返回实际发送的字节数(可能 小于请求长度,应用层需要循环
send)。 - 失败:返回
-1并设置errno(如EPIPE表示对方已关闭连接)。
- 成功:返回实际发送的字节数(可能 小于请求长度,应用层需要循环
recv():- 成功:返回实际接收的字节数。
- 返回
0:表示对方已正常关闭连接(EOF)。 - 失败:返回
-1并设置errno(如ECONNRESET表示连接被对方重置)。
TCP 是 字节流:一次
send不保证对方一次recv就读满,注意循环收发。
12. 数据传输函数 sendto/recvfrom —— UDP 收发
函数原型:
#include <sys/socket.h>
ssize_t sendto(int sockfd, const void *buf, size_t len, int flags, const struct sockaddr *dest_addr, socklen_t addrlen);
ssize_t recvfrom(int sockfd, void *buf, size_t len, int flags, struct sockaddr *src_addr, socklen_t *addrlen);
sendto→ 我要把这段数据,发 给某个地址。recvfrom→ 我要接 收 一段数据,同时想知道它是从哪来的。
参数:
| 参数 | sendto 参数 | recvfrom 参数 | 相同点 | 不同点 |
|---|---|---|---|---|
| 1. socket 文件描述符 | int sockfd | int sockfd | 都是由 socket() 创建的套接字,指明操作的对象 | 无 |
| 2. 数据缓冲区 | const void *buf | void *buf | 都是存放数据的内存区域 | sendto 的数据是 只读 的(要发出去),recvfrom 的数据是 可写 的(接收进来) |
| 3. 缓冲区长度/大小(字节数) | size_t len | size_t len | 都表示操作的数据字节数 | 无 |
| 4. 标志位(一般为 0) | int flags | int flags | 都可设置特殊行为(如非阻塞、等待模式) | 通常 sendto 默认用 0,recvfrom 可能会用 MSG_WAITALL 等 |
| 5. 地址结构(需要转型) | const struct sockaddr *dest_addr | struct sockaddr *src_addr | 都是 struct sockaddr* 类型,用来描述网络地址 | sendto 需要指定 目标地址(发给谁),recvfrom 获取 对方地址(谁发来的) |
| 6. 地址结构大小 | socklen_t addrlen | socklen_t *addrlen | 都与地址结构体长度相关 | sendto 传值(只读,告诉内核目标地址长度),recvfrom 传指针(可写,内核回填实际地址长度) |
相同的返回值:
- 成功: 返回实际发送/接收的字节数(
ssize_t类型,正整数); - 失败: 返回
-1并设置errno(常见如:EINVAL参数无效,EAGAIN非阻塞模式下暂时无数据,ECONNREFUSED目标不可达等)。
UDP 是 报文:一发一收,天然有包界;长度超 MTU 可能被分片/丢弃。
13. close() —— 关闭套接字
函数原型:
#include <unistd.h>
int close(int fd);
作用:关闭套接字描述符,释放资源。
返回值:成功返回 0,失败返回 -1。
3. 理解协议与对应的服务器和客户端通信流程
1. UDP
1. UDP 服务器 (Server)
.
├── socket() // 1. 创建一个UDP套接字
├── 配置服务器地址(sockaddr_in) // 2. 准备自己的地址信息
│ ├── bzero / memset // - 清零结构体
│ ├── serv_addr.sin_family // - 指定IPv4
│ ├── serv_addr.sin_port // - 指定端口号
│ └── serv_addr.sin_addr.s_addr // - 指定IP地址
├── bind() // 3. 将套接字与地址绑定 (正式“调频道”)
├── recvfrom() // 4. 等待并接收客户端消息
│ ├── 参数中会返回客户端地址(cli_addr) // - 知道是谁发来的
│ └── 参数中会返回消息内容(buffer) // - 得到消息内容
├── sendto() // 5. 给客户端发送回复
│ ├── 指定目标地址(cli_addr) // - 回复给刚才发消息的客户端
│ └── 发送回复内容
└── close() // 6. 关闭套接字
2. UDP 客户端 (Client)
.
├── socket() // 1. 创建一个UDP套接字
├── 配置服务器地址(sockaddr_in) // 2. 准备要发往的服务器地址
│ ├── bzero / memset() // - 清零结构体
│ ├── serv_addr.sin_family // - 指定IPv4
│ ├── serv_addr.sin_port // - 服务器端口
│ └── serv_addr.sin_addr.s_addr // - 服务器IP
├──(可选) 配置客户端地址 // 3. 如果需要,可以显式绑定客户端端口
│ ├── bzero / memset()
│ ├── cli_addr.sin_family
│ ├── cli_addr.sin_port // 指定一个固定端口,或让系统自动分配
│ └── cli_addr.sin_addr.s_addr // 通常用任意IP
├──(可选) bind() // 4. 显式绑定客户端端口 (如果第3步配置了),可以不需要,系统会自动分配一个临时端口
├── sendto() // 5. 给服务器发送请求
├── recvfrom() // 6. 等待并接收服务器的回复
│ ├── 参数中会返回服务器地址(serv_addr) // - 确认是预期的服务器回复
│ └── 参数中会返回回复内容(buffer)
└── close() // 7. 关闭套接字
3. UDP 就像“发微信语音消息”
你和朋友在不同的地方,你录了一段语音:“我在东门等你!”,然后发给了他的微信号。
- socket():你们都装了微信(通信工具准备好了)。
- bind():你注册了微信号(相当于绑定 IP 和端口),别人能通过这个号找到你。
- sendto():你发送语音,指定了发给“朋友的微信号”(目标 IP+端口)。
- recvfrom():朋友的微信收到了消息,他知道是你发的,也听到了内容。
特点:
- 你发完就不管了,不确认他有没有收到(不可靠)。
- 如果网络卡了,语音可能 丢了、乱了、重复了,你也不知道。
- 但 速度快,适合直播、语音通话等实时场景。
UDP:无连接、不保证送达、速度快,像“广播喊话”或“发语音”。
2. TCP
1. TCP 服务器 (Server)
.
├── socket() // 1. 创建一个TCP套接字 (SOCK_STREAM)
├── 配置服务器地址 (sockaddr_in) // 2. 准备自己的地址信息
│ ├── bzero / memset() // - 清零结构体
│ ├── serv_addr.sin_family = AF_INET // - IPv4
│ ├── serv_addr.sin_port = htons(PORT) // - 绑定端口
│ └── serv_addr.sin_addr.s_addr = INADDR_ANY // - 监听所有网卡
├── bind() // 3. 将套接字绑定到地址上
├── listen() // 4. 开始监听连接请求(进入“待接电话”状态)
│ └── 设置 backlog 队列(等待 accept 的连接数)
│
├── accept() // 5. 阻塞等待客户端连接到来
│ ├── 成功后返回一个新的连接套接字 (connfd) // - 用于与该客户端通信
│ └── 客户端地址信息 (cli_addr) 被填充 // - 知道是谁连进来了
│
├── recv() // 6. 使用 connfd 接收数据
│ └── 从客户端读取消息内容 (buffer)
│
├── send() // 7. 使用 connfd 发送回复
│ └── 向客户端发送响应数据
│
├── close(connfd) // 8. 关闭连接套接字(通信结束)
│
└── close(sockfd) // 9. 最后关闭监听套接字(程序退出时)
2. TCP 客户端 (Client)
.
├── socket() // 1. 创建一个TCP套接字 (SOCK_STREAM)
├── 配置目标服务器地址 (sockaddr_in) // 2. 指定要连接的服务器
│ ├── bzero / memset() // - 清零结构体
│ ├── serv_addr.sin_family = AF_INET // - IPv4
│ ├── serv_addr.sin_port = htons(PORT) // - 服务器端口
│ └── serv_addr.sin_addr.s_addr = inet_addr("IP") // - 服务器IP地址
│
├── connect() // 3. 发起连接请求(触发三次握手)
│ └── 成功则表示连接建立完成
│
├── send() // 4. 发送请求数据到服务器
│ └── 通过已连接的套接字发送消息
│
├── recv() // 5. 接收服务器的回复
│ └── 读取返回的数据
│
├── close() // 6. 关闭连接(触发四次挥手)
3. TCP 就像“打电话”
你拿出手机,拨通朋友的号码。
- socket():你们都有手机(通信工具)。
- bind():你的手机有号码(IP+端口),别人可以打给你。
- connect():你拨号,他接听——建立连接(三次握手)。
- send()/recv():你们开始通话。你说一句,他“嗯”一声表示听到了;如果信号不好没听清,他会说“再说一遍”,你就会 重说。
- close():聊完后,互相说“拜拜”才挂电话(四次挥手)。
关键特点:
- 通话前必须 先建立连接。
- 数据 不会丢、不会乱序,发出去就得确认收到。
- 如果网络差,通话会卡,但内容 绝对准确。
TCP:有连接、可靠传输、保证顺序,像“打电话”一样稳。
4. UDP 服务器和客户端 Demo
1. UDP_Server.hpp
#pragma once
#include <iostream>
#include <string>
#include <unistd.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <errno.h>
#include <cstring>
#include <functional>
#include <cstdlib>
#include "Log.hpp"
using namespace std;
// 错误码定义
enum
{
SOCKET_ERR = 1, // 创建 socket 失败
BIND_ERR // bind 失败
};
// 默认端口和 IP 地址
static const uint16_t defaultport = 8080;
static const string defaultip = "0.0.0.0";
static const int BUFFER_SIZE = 1024; // 接收缓冲区大小
// 定义回调函数类型:接收一个字符串请求,返回一个字符串响应
typedef function<string(const string&)> func_t;
class UDP_Server
{
public:
UDP_Server(const uint16_t &port = defaultport, const string &ip = defaultip,
int enable_log = 1,
int classification = 1,
const string &log_path = "./log.txt",
int console_out = 1)
: sockfd_(0), port_(port), ip_(ip), isrunning_(false),
log_(enable_log, classification, log_path, console_out) {}
~UDP_Server()
{
if(sockfd_ > 0)
{
close(sockfd_); // 关闭 socket 文件描述符
log_(Info, "UDP 服务器套接字已关闭");
}
}
void Init()
{
// 1. 创建 UDP socket
sockfd_ = socket(AF_INET, SOCK_DGRAM, 0);
if(sockfd_ < 0)
{
log_(Fatal, "套接字创建错误,sockfd: %d", sockfd_);
exit(SOCKET_ERR);
}
log_(Info, "套接字创建成功,sockfd: %d", sockfd_);
// 2. 设置 IPv4 地址结构
struct sockaddr_in local;
bzero(&local, sizeof(local)); // 内存清零
local.sin_family = AF_INET; // IPv4
local.sin_port = htons(port_); // 端口号转换为网络字节序
local.sin_addr.s_addr = inet_addr(ip_.c_str()); // 将字符串 IP 转换为网络字节序整数
// 3. 绑定 socket 到本地地址
if(bind(sockfd_, (const struct sockaddr *)&local, sizeof(local)) < 0)
{
log_(Fatal, "绑定套接字错误,errno: %d,错误字符串: %s", errno, strerror(errno));
exit(BIND_ERR);
}
log_(Info, "绑定套接字成功,本地地址: %s:%d", ip_.c_str(), port_);
}
void Run(func_t func)
{
isrunning_ = true;
char buffer[BUFFER_SIZE]; // 接收缓冲区
while (isrunning_)
{
struct sockaddr_in client; // 客户端地址信息
socklen_t len = sizeof(client); // 必须初始化长度
// 接收客户端数据
ssize_t n = recvfrom(sockfd_, buffer, sizeof(buffer) - 1, 0, (struct sockaddr*)&client, &len);
if (n < 0)
{
log_(Warning, "recvfrom error, errno: %d, err string: %s", errno, strerror(errno));
continue;
}
buffer[n] = '\0'; // 添加字符串结束符
string request(buffer); // 构造请求字符串
string response = func(request); // 调用用户自定义处理函数生成响应
// 发送响应回客户端
sendto(sockfd_, response.c_str(), response.size(), 0, (const struct sockaddr*)&client, len);
}
}
private:
int sockfd_; // socket 文件描述符
string ip_; // 服务器绑定的 IP 地址
uint16_t port_; // 服务器监听的端口号
bool isrunning_; // 服务运行状态标志
Log log_; // 日志对象成员
};
2. Log.hpp
#pragma once
#include <iostream>
#include <string>
#include <stdlib.h> // exit, perror
#include <unistd.h> // read, write, close
#include <sys/types.h> // open, close, read, write, lseek
#include <sys/stat.h> // mkdir
#include <fcntl.h> // open, O_RDONLY, O_WRONLY, O_CREAT, O_APPEND
#include <errno.h> // errno
#include <sys/time.h> // gettimeofday, struct timeval
#include <ctime> // localtime_r, struct tm
#include <cstdarg> // va_list, va_start, va_end
using namespace std;
// 管道错误码
enum FIFO_ERROR_CODE
{
FIFO_CREATE_ERR = 1, // 这是创建管道文件失败的错误码
FIFO_DELETE_ERR = 2, // 这是删除管道文件失败的错误码
FIFO_OPEN_ERR // 这是打开管道文件失败的错误码(枚举会自动赋值为3)
};
// 日志等级
enum Log_Level
{
Fatal, // 最严重级别
Error, // 严重错误
Warning, // 警告
Debug, // 调试信息
Info // 普通信息
};
class Log
{
int enable = 1; // 是否启用日志
int classification = 1; // 是否分类
string log_path = "./log.txt"; // 日志存放路径
int console_out = 1; // 是否输出到终端
// 日志等级转换成字符串
string level_to_string(int level)
{
switch (level)
{
case Fatal:
return "Fatal";
case Error:
return "Error";
case Warning:
return "Warning";
case Debug:
return "Debug";
case Info:
return "Info";
default:
return "None";
}
}
// 获取当前计算机的时间,返回格式:YYYY-MM-DD HH:MM:SS.UUUUUU (含微秒)
string get_current_time()
{
struct timeval tv; // timeval:包含秒和微秒
gettimeofday(&tv, nullptr); // 系统调用:获取当前时间(精确到微秒)
struct tm t; // tm:分解时间,转格式(年、月、日、时、分、秒)
localtime_r(&tv.tv_sec, &t); // 把秒转换成年月日时分秒(本地时区)
char buffer[64]; // 定义字符数组作为格式化输出的缓冲区
snprintf(buffer, sizeof(buffer),
"%04d-%02d-%02d %02d:%02d:%02d.%06ld",
t.tm_year + 1900, // 年:tm_year 从 1900 开始计数
t.tm_mon + 1, // 月:tm_mon 从 0 开始,0 表示 1 月
t.tm_mday, // 日
t.tm_hour, // 时
t.tm_min, // 分
t.tm_sec, // 秒
tv.tv_usec); // 微秒部分,取自 gettimeofday
return string(buffer); // 转换成 string 返回
}
public:
Log() = default; // 使用默认构造
Log(int enable, int classification, string log_path, int console_out)
: enable(enable),
classification(classification),
log_path(log_path),
console_out(console_out)
{
}
// 重载函数调用运算符
void operator()(int level, const string& format, ...)
{
if (enable == 0)
{
return; // 日志未启用
}
va_list args;
va_start(args, format);
// 计算需要的缓冲区大小
int size = vsnprintf(nullptr, 0, format.c_str(), args) + 1;
va_end(args);
if (size <= 0)
{
return; // 格式化失败
}
// 分配缓冲区并格式化字符串
char* buffer = new char[size];
va_start(args, format);
vsnprintf(buffer, size, format.c_str(), args);
va_end(args);
string content(buffer);
delete[] buffer;
// 调用原有的处理逻辑
string level_str = "[" + level_to_string(level) + "] ";
string log_message;
if (classification == 1)
{
log_message = level_str + "[" + get_current_time() + "] " + content + "\n";
}
else if (classification == 0)
{
log_message = "[" + get_current_time() + "] " + content + "\n";
}
else
{
printf("传入的分类参数错误!\n");
return;
}
if (console_out == 1)
{
cout << log_message;
}
log_to_file(level, log_message);
}
private:
// 文件路径的后缀处理函数:当按照日志等级分类存储并且文件路径是 "./log.txt" 这种有文件扩展名时的处理方法
string Suffix_processing(int level, string log_path)
{
string Path;
if (log_path.back() == '/') // 如果是一个目录的路径,比如 "./log/",则最终文件名为 "log_等级名.txt"
{
Path = log_path + "log_" + level_to_string(level) + ".txt";
}
else // 如果是一个文件路径,比如 "./log.txt",则最终文件名为 "log_等级名.txt"
{
size_t pos = log_path.find_last_of('.'); // 从后往前找到第一个 '.' 的位置,即最后一次出现的 '.' 的位置
if (pos != string::npos)
{
string left = log_path.substr(0, pos); // 去掉后缀,即我所需要的有效的前部分路径
string right = log_path.substr(pos); // 保留后缀,即有效的文件扩展名
Path = left + "_" + level_to_string(level) + right; // 组合成新的文件名
}
else // 如果没有文件扩展名(比如 "./log"),则直接在文件名后面加上 "_等级名.txt"
{
Path = log_path + "_" + level_to_string(level) + ".txt";
}
}
return Path;
}
// 核心写文件函数
void log_to_file(int level, const string& log_content)
{
string Path;
if (classification == 1)
{
Path = Suffix_processing(level, log_path); // 按照日志等级分类存储
}
else if (classification == 0)
{
Path = log_path; // 不分类直接使用传入的 log_path
}
// 追加写入,文件不存在则创建,权限 0644
int fd = open(Path.c_str(), O_WRONLY | O_CREAT | O_APPEND, 0644);
if (fd < 0)
{
perror("");
exit(FIFO_OPEN_ERR);
}
write(fd, log_content.c_str(), log_content.size());
close(fd);
}
};
3. UDP_Client.cc
#include <iostream>
#include <string>
#include <cstring>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <unistd.h>
using namespace std;
const int BUFSIZE = 1024; // 接收服务器响应的缓冲区大小
void Usage(string proc)
{
cout << "\n\r用法: " << proc << " 服务器IP 服务器端口号\n" << "例如: " << proc << " 127.0.0.1 8080\n" << endl;
}
int main(int argc, char* argv[])
{
// 检查命令行参数数量,argc != 3 的原因:
// argv[0]: 程序名称(如 "./udpclient"),argv[1]: 服务器IP地址(如 "127.0.0.1"),argv[2]: 服务器端口号(如 "8080")
if(argc != 3)
{
Usage(argv[0]);
exit(0);
}
// 1. 解析命令行参数获取服务器IP和端口
string serverip = argv[1]; // 获取服务器IP地址
uint16_t serverport = stoi(argv[2]); // 将端口号字符串转换为整数
// 2. 构造服务器地址结构
struct sockaddr_in server;
bzero(&server, sizeof(server)); // 内存清零
server.sin_family = AF_INET; // 设置地址族为IPv4
server.sin_port = htons(serverport); // 端口号转换为网络字节序
server.sin_addr.s_addr = inet_addr(serverip.c_str()); // IP地址转换为网络字节序
// 3. 创建套接字
int sockfd = socket(AF_INET, SOCK_DGRAM, 0); // 创建UDP套接字
if(sockfd < 0)
{
cout << "创建套接字失败!" << endl;
exit(1);
}
//cout << "创建套接字成功!" << endl;
// 客户端通常不需要显式调用bind函数!
// 原因:
// 1. 一个端口号只能被一个进程bind,对server是如此,对于client也是如此
// 2. 客户端的端口号其实不重要,只要能保证主机上的唯一性就可以
// 3. 系统会在首次发送数据时自动为客户端分配一个随机端口号(隐式bind)
// 4. 这样可以避免端口冲突,简化客户端编程
socklen_t server_len = sizeof(server); // 获取地址结构大小,用于后续的sendto和recvfrom函数
string message; // 存储用户输入的消息
char buffer[BUFSIZE]; // 接收服务器响应的缓冲区
// 4. 循环发送消息并接收服务器响应
while(true)
{
cout << "请输入您要发送的消息@ ";
getline(cin, message); // 读取用户输入的消息
if(message == "q" || message == "exit" || message == "quit")
{
cout << "客户端退出!" << endl;
break;
}
// 5. 发送消息
// sendto参数说明:sockfd: socket文件描述符,message.c_str(): 要发送的数据,message.size(): 数据长度,
// 0: 标志位(一般为0),(struct sockaddr *)&server: 目标地址结构,server_len: 地址结构大小
ssize_t send_bytes = sendto(sockfd, message.c_str(), message.size(), 0, (struct sockaddr*)& server, server_len);
if(send_bytes < 0)
{
cout << "发送消息失败!" << endl;
continue;
}
//cout << "发送消息成功!" << endl;
// 6. 接收服务器响应
struct sockaddr_in server_response; // 服务器响应的地址结构
socklen_t server_response_len = sizeof(server_response); // 服务器响应的地址结构大小
// recvfrom参数说明:socket文件描述符,buffer: 接收缓冲区,缓冲区大小(留一个字节给'\0'),标志位(一般为0),发送方地址结构,地址结构大小(传入时是sizeof,返回时是实际大小)
ssize_t recv_bytes = recvfrom(sockfd, buffer, sizeof(buffer) - 1, 0, (struct sockaddr*)& server_response, &server_response_len);
if (recv_bytes > 0)
{
buffer[recv_bytes] = '\0'; // 添加字符串结束符
//cout << "收到服务器响应 (" << recv_bytes << " 字节): " << buffer << endl;
}
else if (recv_bytes == 0)
{
cout << "服务器关闭连接" << endl;
}
else
{
cout << "接收数据失败" << endl;
}
}
// 7. 关闭套接字
close(sockfd);
cout << "客户端socket已关闭" << endl;
return 0;
}
4. Main.cc
#include "UDP_Server.hpp"
#include <memory>
#include <vector>
void Usage(string proc)
{
cout << "\n\r用法: " << proc << " 端口号[1024+]\n" << "说明: 端口号建议使用1024以上的端口,避免与系统保留端口冲突\n" << "示例: " << proc << " 8080\n" << endl;
}
// 对命令进行安全检查
bool SafeCheck(const string& cmd)
{
// 可能不安全的命令,可自行添加
vector<string> unsafe = {
"rm",
"mv",
"cp",
"kill",
"sudo",
"unlink",
"uninstall",
"yum",
"top",
"while"
};
for(const auto& danger_cmd : unsafe)
{
// 检查命令中是否包含危险命令
if(cmd.find(danger_cmd) != string::npos)
{
return false; // 找到危险命令,返回false
}
}
return true;
}
// 处理收到的消息
string Handler(const string& s)
{
string ret = "服务器收到一条消息: ";
ret += s;
cout << ret << endl;
return ret;
}
// 可以直接执行命令的函数
string ExcuteCommand(const string& cmd)
{
cout << "获取一个请求命令: " << cmd << endl;
if(!SafeCheck(cmd))
{
cout << "这是一个不安全的命令,已经发现,并且拒绝执行!" << endl;
return "Unsafe commands!";
}
// popen 用于创建管道并读取命令,参数:要执行的命令,打开管道的模式("r":读)
FILE *fp = popen(cmd.c_str(), "r");
if(nullptr == fp)
{
perror("popen");
return "error";
}
string ret;
char buffer[4096];
while(true)
{
char *ok = fgets(buffer, sizeof(buffer), fp);
if(ok == nullptr)
{
break;
}
ret += buffer;
}
pclose(fp); // 关闭管道
return ret;
}
int main(int argc, char* argv[])
{
// 检查命令行参数数量,argc != 2 的原因:
// argv[0]: 程序名称(如 "./udpserver"),argv[1]: 监听端口号(如 "8080")
if (argc != 2)
{
Usage(argv[0]);
exit(0);
}
// 解析端口号参数
uint16_t port = std::stoi(argv[1]); // 将字符串端口号转换为整数
unique_ptr<UDP_Server> svr(new UDP_Server(port)); // 使用智能指针创建UDP服务器对象,自动内存管理,避免内存泄漏
svr->Init(); // 初始化服务器
svr->Run(Handler); // 启动服务器,可选择的函数:Handler、ExcuteCommand
return 0;
}
5. TCP 服务器和客户端 Demo
这部分的代码和文件较多,不便展示,可前往 GitHub 查看 TCP 服务器和客户端 Demo。
6. 守护进程
1. 什么是会话(Session)?
会话是 Linux 中进程管理的一个逻辑单位,对应一次 “登录会话”,一次登录(通过 SSH 登录到服务器)就创建了一个“会话”。这个“会话”在 Linux 中对应的是一个 shell 进程(如 bash),这是我们与 OS 交互的入口。一个会话包含:
- 一个 控制终端(在 Xshell 中看到的命令行界面);
- 多个进程,然而一些进程之间又有关联,进而形成多个 进程组,但同一时间 只有一个进程组能成为前台进程组,其余均为后台进程组。
进程组 是一组相关进程的集合(比如一个程序启动的主进程和它的子进程),共享同一个 进程组 ID(PGID),由进程组首进程(创建该组的进程)的 PID 决定。
会话的生命周期与你的登录状态绑定: 当退出登录(关闭 Xshell 窗口或执行 exit),会话会终止,默认会向会话内的所有进程发送终止信号 SIGHUP(挂断信号,信号 1),除非它们被“脱离”了会话(如使用 nohup 或 disown)。
2. 前台进程 vs 后台进程
- 前台进程: 占据终端,可以接收键盘输入(如 Ctrl+C、Ctrl+Z),一次只能有一个前台进程,在终端输入命令后直接执行的程序默认是前台进程。
- 后台进程: 不占用终端,不能直接接收键盘输入,可以同时运行多个进程(任务),输出仍可能打印到终端(除非重定向)。
前、后台进程也称作前、后台任务,一个会话只能有一个前台进程,键盘信号只能发给前台进程!
3. 作业号 vs 进程 ID(PID)
jobs 显示的是 作业号(如 %1),是 shell 内部编号。ps 命令显示的是 进程 ID(PID),是系统级唯一标识。可以用 %1 来引用作业,如:
kill %1 # 终止作业1
fg %1 # 前台恢复作业1
bg %1 # 后台恢复作业1
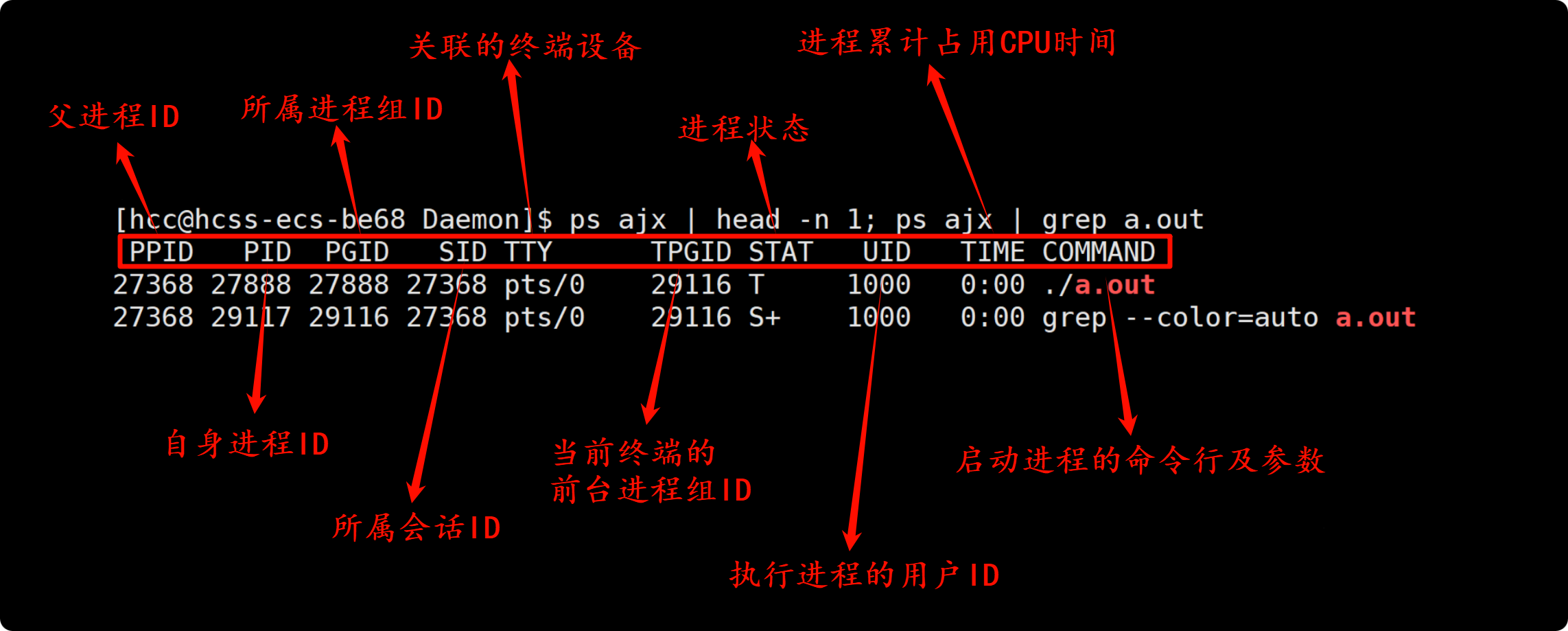
ps ajx | head -n 1; ps ajx | grep a.out 查看示例进程的相关信息:
4. 作业控制命令
Linux shell(如 bash)支持“作业控制”,允许管理前台/后台任务。用一个简单的代码示例并编译成 a.out 可执行程序,来体会作业控制:
-
&:在命令末尾添加&,表示 “启动该命令后立即将其放入后台运行”,终端不等待命令执行完成,直接返回提示符,允许你继续输入其他命令。示例:./a.out >> log.txt & # 将a.out放入后台,输出重定向到log.txt sleep 100 & # 后台休眠100秒- 区分
&用法的核心原则在于位置判断:- 若
&在 命令末尾,且不是条件表达式的一部分 → 后台运行命令。 - 若
&在 两个命令之间 → 并行启动两个后台命令。 - 若
&在 **[[ ]]或$(( ))内部 ** → 按位与运算。
- 若
- 区分
-
jobs:查看当前会话中所有 后台进程(任务)的状态。[1]是作业号(Job ID),+表示默认作业。示例:[1]+ Running ./a.out >> log.txt & -
fg:将一个后台(或暂停)的作业调到 前台(SIGCONT)继续运行。示例:$ fg %1 ./a.out # 现在在前台运行,可接收 Ctrl+C -
Ctrl+Z:给 前台 进程组发 SIGTSTP(19 号信号),把它“暂停”成可后台继续的作业(T状态)。a.out被暂停,不再运行,但未退出,示例:$ ./a.out # 前台运行 ^Z # 按 Ctrl+Z [1]+ Stopped ./a.out -
bg:让一个被暂停的作业在后台 继续运行。示例:$ bg %1 # 或直接 bg(作用于默认作业) [1]+ ./a.out >> log.txt & -
kill -SIGTERM %1/kill -9 %1:给作业发信号(%1是作业号,和 PID 不同)。 -
disown -h %1:把作业从当前 shell 的作业表 剥离,不再受 SIGHUP 影响。示例:./a.out >> log.txt & disown %1 -
nohup:让进程 忽略 SIGHUP,常配合重定向使用,退出登录,进程仍运行:nohup ./a.out >> log.txt &。
5. 守护进程
1. 什么是守护进程?
守护进程(Daemon) 是一种长期运行的后台进程,不依赖于任何终端或用户会话。它们通常在系统启动时启动,直到系统关闭才停止。常见例子:sshd(SSH 服务)、httpd(Web 服务)、crond(定时任务)。
2. 守护进程的特点
- 脱离终端与会话:通常是会话领导者,避免被 SIGHUP 杀死。
- 双 fork 技术:创建守护进程时通常 fork 两次,确保不成为进程组领导者。
- 重定向标准流:将 stdin、stdout、stderr 重定向到
/dev/null或日志文件。 - 工作目录:通常切换到
/或固定目录,避免阻塞文件系统卸载。
6. /dev/null 是什么?
本质:/dev/null 是一个特殊的字符设备文件,被称为 黑洞设备,也叫“空设备”,我们只要把它当作垃圾桶就好。
行为:
- 往它里面写任何东西,直接丢弃,就像写到空气里。
- 从它里面读,总是 立刻返回 EOF(表示空文件,没数据)。
所以很多守护进程会把 标准输入/输出/错误 重定向到 /dev/null,避免占用终端。那么它到底有什么用?
在守护进程中,标准输入(stdin)、标准输出(stdout)、标准错误(stderr)必须被重定向,否则:
- 如果进程尝试读 stdin → 会出错(因为没有终端)。
- 如果写 stdout/stderr → 输出无处可去,可能引发异常或写入旧终端。
所以,把这三个标准流重定向到 /dev/null 是一种安全兜底措施,确保:不会因为读写标准流而崩溃、不会干扰原终端或产生混乱输出。
7. setsid() 函数原型
-
作用: 创建一个新的 会话,并成为该会话的会话首进程,同时成为新的 进程组组长,脱离当前控制终端,不再受键盘信号影响。
-
函数原型
#include <unistd.h>
pid_t setsid(void);
-
使用条件(fork 一次 + setsid 的经典组合):
-
调用
setsid()的进程 不能 是进程组组长,否则会失败返回-1。 -
所以通常先
fork()一次,让子进程保证不是组长,再在子进程里setsid()。
-
-
代码示例:
#pragma once
#include <iostream>
#include <cstdlib>
#include <unistd.h>
#include <signal.h>
#include <string>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
using namespace std;
const string nullfile = "/dev/null";
void Daemon(const string &cwd = "")
{
// 1. 忽略其他异常信号
signal(SIGCLD, SIG_IGN);
signal(SIGPIPE, SIG_IGN);
// signal(SIGSTOP, SIG_IGN);
// 2. 将自己变成独立的会话
if (fork() > 0)
{
exit(0);
}
setsid();
// 3. 更改当前调用进程的工作目录
if (!cwd.empty())
{
chdir(cwd.c_str());
}
// 4. 标准输入,标准输出,标准错误重定向至/dev/null
int fd = open(nullfile.c_str(), O_RDWR);
if(fd > 0)
{
dup2(fd, STDIN_FILENO); // stdin 重定向,防止后台读键盘阻塞
dup2(fd, STDOUT_FILENO); // stdout 重定向,不在终端打印
dup2(fd, STDERR_FILENO); // stderr 重定向,错误也不污染终端
close(fd);
}
}
守护进程的本质也是孤儿进程!
8. daemon() 方法(glibc 提供的简便函数)
Linux glibc 提供了一个库函数 daemon(),可以 自动 完成守护进程化,这会简化守护进程,方便我们的编码。
- 函数原型
#include <unistd.h>
int daemon(int nochdir, int noclose);
-
参数:
-
nochdir = 0→ 把工作目录切换到根目录/; -
noclose = 0→ 把stdin/stdout/stderr重定向到/dev/null。
-
-
返回值:成功返回
0,失败返回-1。 -
代码示例:
#include <unistd.h>
#include <cstdlib>
#include <iostream>
int main()
{
// 创建守护进程
if (daemon(0, 0) == -1)
{
perror("daemon");
exit(1);
}
// 守护进程的主循环
while (true)
{
// 写日志或者处理任务
sleep(1);
}
}
daemon()内部其实就做了手写的那些步骤:fork、setsid、chdir、dup2到/dev/null,所以用起来更方便。需要注意的是:daemon()没有做 双重 fork、也不处理umask,所以 严格场景 下(比如写系统级服务),还是建议手写模板或用 systemd 管理。
7. 配置安全组规则
安全组就像是一个虚拟防火墙,用于控制云服务器的入站和出站流量。默认情况下,安全组拒绝所有来自外部的入站请求。以我的华为云 Flexus 应用服务器 L 实例为例,在安全组中开放 3000-20000 端口(个人自定义范围)后,就相当于在防火墙上开了一个 “口子”,这样就允许外部设备通过这些端口与云服务器上的服务进行通信了,将自己的客户端发给朋友运行,本机的服务器就可以开始通信了。
不同厂商的配置大同小异,因为这部分配置比较简单,就不演示了,实在不会,B 站的教程相当多,这里仅提供示例配置:
- 优先级:1
- 策略:允许
- 类型:IPv4
- 协议端口:TCP : 3000-20000
- 源地址:0.0.0.0
隐私安全考虑:
- 及时关闭不必要规则:在演示完成后,如果这些开放的安全组规则不再需要,应及时将其关闭。否则,服务器可能会面临潜在的安全风险,比如恶意攻击者可能会利用开放的端口尝试进行入侵、扫描或其他非法操作。
- 最小权限原则:在配置安全组规则时就应遵循最小权限原则,即只开放那些确实需要用于演示通信的端口和协议,有需要可以限制来源 IP 范围。
- 数据隐私方面:除了端口规则外,还要注意通信过程中涉及的数据是否包含敏感信息。如果有,需要确保数据在传输(如采用加密协议)和存储过程中的安全性,避免隐私数据泄露。
