

DeepSeek-OCR:用光学压缩颠覆长文本处理,10倍压缩比下的97%精度革命
大家好,我是AI算法工程师七月,曾在华为、阿里任职,技术栈广泛,爱好广泛,喜欢摄影、羽毛球。目前个人在烟台有一家企业星瀚科技。
我会在这里分享关于 编程技术、独立开发、行业资讯,思考感悟 等内容。爱好交友,想加群滴滴我,wx:swk15688532358,交流分享
如果本文能给你提供启发或帮助,欢迎动动小手指,一键三连 (点赞、评论、转发),给我一些支持和鼓励,谢谢。
作者:七月 链接:www.xinghehuimeng.com.cn/article/6
来源:七月 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
2025 年 10 月,DeepSeek 团队开源的 DeepSeek-OCR 模型以 "上下文光学压缩" 技术惊艳业界,仅 30 亿参数量便实现了 10 倍无损压缩的突破,重新定义了 OCR 技术的效率边界。这款模型在单张 A100-40G 显卡上达成每日 20 万页文档处理能力。
先说一个问题,什么是光学压缩-OCR
简单来说,这是一种让AI“看图识字”的极致版。
传统思路中,要让AI读懂长文档,通常需要将整个文档转换成数字文本,这个过程会消耗大量的“token”(可以理解为AI处理信息的单位),导致计算效率低下。

而DeepSeek-OCR走了一条与众不同的路:它先把文本变成图像,再用视觉token来压缩表示这些信息。想象一下,你有一篇万字长文,不需要让AI一个字一个字去读,而是让它“看一眼”图片,就能理解并还原出原文内容。
核心突破在于:包含文档文本的单张图像,能够用远少于等效文本的token量来表征丰富信息。这意味着通过视觉token进行光学压缩可以实现更高的压缩比,用更少的资源做更多的事。
一、颠覆性突破:光学压缩重塑文本处理范式
1.1 核心发现:10倍压缩下的无损解码
实验数据揭示震撼结果:
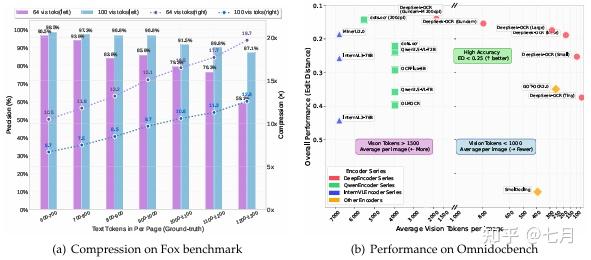
- 压缩比<10倍时:OCR精度达97%(Fox基准测试)
- 压缩比20倍时:精度仍保持60%
- 实际应用:仅用100个视觉token(640×640分辨率)超越GOT-OCR2.0(256token);800token内击败MinerU2.0(6000+token)
技术启示:这意味着一页千字文档仅需100个视觉token即可精准还原,为LLM历史对话压缩、超长文档处理提供革命性方案。
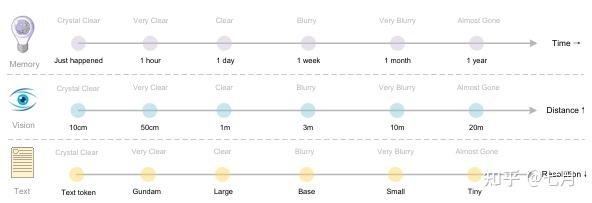
1.2 仿生学设计:模拟人类记忆机制
团队创造性地将视觉分辨率递减与人类记忆遗忘曲线关联:
- 近期文本:高分辨率渲染(如1280×1280)
- 历史文本:逐步降采样(1024→640→512)
- 效果:自然实现“清晰→模糊→遗忘”的信息衰减,完美契合LLM上下文管理需求
二、技术架构:DeepEncoder的压缩艺术
2.1 三段式压缩引擎 关键创新点:
- 双阶段注意力:SAM处理局部细节(80M参数),CLIP捕获全局语义(300M参数)
- 16倍卷积压缩:将4096 token压缩至256 token,激活内存降低94%
- 动态分辨率支持:单模型兼容6种模式(64-1853 token)
DeepSeek-OCR的架构可以理解为两部分:一个专业的“眼睛” (DeepEncoder编码器)和一个聪明的“大脑” (DeepSeek3B-MoE解码器)。
那双“专业眼睛”:DeepEncoder
这双眼睛的厉害之处在于它能在高分辨率输入下保持低计算消耗,同时实现高效的视觉压缩。

当它看到一张1024×1024的文档图片时,传统视觉模型可能会生成4096个token,而DeepEncoder能将其压缩到仅256个token。这种压缩能力让它能够高效处理各种复杂文档,同时保持较低的计算负担。
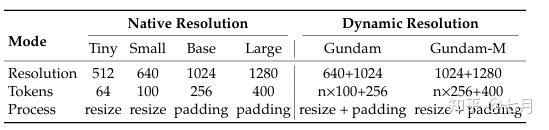
更重要的是,这双眼睛支持多种“视力模式” ,从轻量的Tiny模式(64个token)到高保真的Gundam模式(795个token),模型可以根据任务复杂度自动选择压缩等级。
- 日常文档(如论文、幻灯片):仅需100个视觉token即可精准识别
- 复杂文档(如报纸、科学论文):通过Gundam模式实现高精度还原
那个“聪明大脑”:DeepSeek3B-MoE
这个大脑采用混合专家架构,在推理时仅激活部分专家模块,总激活参数量约5.7亿。这种“按需激活”的机制让模型既具备强大的表达能力,又能保持低延迟和高能效,特别适合文档OCR、图文生成等场景。
