

MyBatis简介
环境说明
- jdk 8 +
- MySQL 5.7.19
- maven-3.6.1
- IDEA
学习前需要掌握:
- JDBC
- MySQL
- Java 基础
- Maven
- Junit
什么是MyBatis
- MyBatis 是一款优秀的持久层框架
- MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集的过程
- MyBatis 可以使用简单的 XML 或注解来配置和映射原生信息,将接口和 Java 的 实体类 【Plain Old Java Objects,普通的 Java对象】映射成数据库中的记录。
- MyBatis 本是apache的一个开源项目ibatis, 2010年这个项目由apache 迁移到了google code,并且改名为MyBatis 。
- 2013年11月迁移到Github .
- Mybatis官方文档 : www.mybatis.org/mybatis-3/z…
- GitHub : github.com/mybatis/myb…
持久化
持久化是将程序数据在持久状态和瞬时状态间转换的机制。
- 即把数据(如内存中的对象)保存到可永久保存的存储设备中(如磁盘)。持久化的主要应用是将内存中的对象存储在数据库中,或者存储在磁盘文件中、XML数据文件中等等。
- JDBC就是一种持久化机制。文件IO也是一种持久化机制。
- 在生活中 : 将鲜肉冷藏,吃的时候再解冻的方法也是。将水果做成罐头的方法也是。
为什么需要持久化服务呢?那是由于内存本身的缺陷引起的
- 内存断电后数据会丢失,但有一些对象是无论如何都不能丢失的,比如银行账号等,遗憾的是,人们还无法保证内存永不掉电。
- 内存过于昂贵,与硬盘、光盘等外存相比,内存的价格要高2~3个数量级,而且维持成本也高,至少需要一直供电吧。所以即使对象不需要永久保存,也会因为内存的容量限制不能一直呆在内存中,需要持久化来缓存到外存。
持久层
什么是持久层?
- 完成持久化工作的代码块 . ----> dao层 【DAO (Data Access Object) 数据访问对象】
- 大多数情况下特别是企业级应用,数据持久化往往也就意味着将内存中的数据保存到磁盘上加以固化,而持久化的实现过程则大多通过各种关系数据库来完成。
- 不过这里有一个字需要特别强调,也就是所谓的“层”。对于应用系统而言,数据持久功能大多是必不可少的组成部分。也就是说,我们的系统中,已经天然的具备了“持久层”概念?也许是,但也许实际情况并非如此。之所以要独立出一个“持久层”的概念,而不是“持久模块”,“持久单元”,也就意味着,我们的系统架构中,应该有一个相对独立的逻辑层面,专注于数据持久化逻辑的实现.
- 与系统其他部分相对而言,这个层面应该具有一个较为清晰和严格的逻辑边界。【说白了就是用来操作数据库存在的!】
为什么需要Mybatis
-
Mybatis就是帮助程序猿将数据存入数据库中 , 和从数据库中取数据 .
-
传统的jdbc操作 , 有很多重复代码块 .比如 : 数据取出时的封装 , 数据库的建立连接等等... , 通过框架可以减少重复代码,提高开发效率 .
-
MyBatis 是一个半自动化的ORM框架 (Object Relationship Mapping) -->对象关系映射
-
所有的事情,不用Mybatis依旧可以做到,只是用了它,所有实现会更加简单!技术没有高低之分,只有使用这个技术的人有高低之别
-
MyBatis的优点
-
- 简单易学:本身就很小且简单。没有任何第三方依赖,最简单安装只要两个jar文件+配置几个sql映射文件就可以了,易于学习,易于使用,通过文档和源代码,可以比较完全的掌握它的设计思路和实现。
- 灵活:mybatis不会对应用程序或者数据库的现有设计强加任何影响。sql写在xml里,便于统一管理和优化。通过sql语句可以满足操作数据库的所有需求。
- 解除sql与程序代码的耦合:通过提供DAO层,将业务逻辑和数据访问逻辑分离,使系统的设计更清晰,更易维护,更易单元测试。sql和代码的分离,提高了可维护性。
- 提供xml标签,支持编写动态sql。
- 简单易学:本身就很小且简单。没有任何第三方依赖,最简单安装只要两个jar文件+配置几个sql映射文件就可以了,易于学习,易于使用,通过文档和源代码,可以比较完全的掌握它的设计思路和实现。
settings.xml文件

MyBatis第一个程序
1 创建一个Maven项目
-
先将父工程的src目录删除
-
导入我们需要的资源
-
<!--导入依赖--> <dependencies> <!--mysql驱动--> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.47</version> </dependency> <!--mybatis--> <dependency> <groupId>org.mybatis</groupId> <artifactId>mybatis</artifactId> <version>3.5.2</version> </dependency> <!--junit--> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> </dependency> </dependencies>说明:导入依赖在父工程中导入,这样的话我们每创建子工程就不用在导入依赖
-
-
可能出现问题说明:Maven静态资源过滤问题
-
解决方法如下,在pom.xml文件中添加
-
<!--解决资源过滤问题--> <build> <resources> <resource> <directory>src/main/java</directory> <includes> <include>**/*.properties</include> <include>**/*.xml</include> </includes> <filtering>false</filtering> </resource> <resource> <directory>src/main/resources</directory> <includes> <include>**/*.properties</include> <include>**/*.xml</include> </includes> <filtering>false</filtering> </resource> </resources> </build>
-
2 配置环境
在模块中的资源文件夹中创建mybatis-config.xml文件
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<!--configuration核心配置文件-->
<configuration>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<!--mysql驱动-->
<property name="driver" value="com.mysql.jdbc.Driver"/>
<!--xml中连字符要进行转译,&来表示连字符,UseSSL表示安全访问-->
<property name="url" value="jdbc:mysql://localhost:3306/db1?mybatis?UseSSL=true&userUnicode=true&charcterEncoding=UTF-8"/>
<property name="username" value="root"/>
<property name="password" value="root"/>
</dataSource>
</environment>
</environments>
<mappers>
<!--mapper地址-->
<mapper resource="org/mybatis/example/BlogMapper.xml"/>
</mappers>
</configuration>
说明:可以同时存在多套环境,上面的是默认的环境
修改mapper地址
<mappers>
<!--mapper地址-->
<mapper resource="com/xiaozhi/mapper/userMapper.xml"/>
</mappers>
说明:这个一定要是你自己的mapper配置文件所在的路径,不然会报以下错误

3 创建工具类
/**
* @author xiaozhi
* @description 获得SqlSession的工具类
* @create 2020-12-2020/12/30 11:07
*/
public class MybatisUtils {
private static SqlSessionFactory sqlSessionFactory;
static {
try {
String resource = "mybatis-config.xml";
// 创建一个流读取文件
InputStream inputStream = Resources.getResourceAsStream(resource);
// 获取到sqlSessionFactory工厂类
sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
} catch (IOException e) {
e.printStackTrace();
}
}
// 获取sqlSession连接
public static SqlSession getSession() {
return sqlSessionFactory.openSession();
}
}
4 编写JavaBean
public class User {
private Integer id;
private String name;
private String password;
private String email;
说明:这里我之前就在数据库中创建好的一个表
5 编写Mapper接口类
public interface UserMapper {
// 获取所有的用户信息
public List<User> selectUser();
}
6 编写Mapper.xml配置文件
要创建一个Mapper.xml文件
- namespace属性:绑定一个对应的Dao/Mapper接口,报名名字必须要和接口名一致
- id是接口中的方法名,resultType是结果集的类型
- select标签内写sql语句
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--namespace属性:绑定一个对应的Dao/Mapper接口-->
<mapper namespace="com.xiaozhi.mapper.UserMapper">
<!--id是接口中的方法名,resultType是结果集的类型-->
<select id="selectUser" resultType="com.xiaozhi.pojo.User">
/*标签内写sql语句*/
select * from user
</select>
</mapper>
补充:这里我们是查询操作,所以是select标签
7 编写测试类进行测试
public class UserMapperTest {
//第一种方式
@Test
public void Test1(){
// 1获取到sqlSession对象
SqlSession session = MybatisUtils.getSession();
// 2得到mapper接口
UserMapper mapper = session.getMapper(UserMapper.class);
// 3调用方法
List<User> users = mapper.selectUser();
for (User user:users) {
System.out.println(user);
}
// 关闭资源
session.close();
}
// 第二种方式
@Test
public void Test2(){
// 1获取到sqlSession对象
SqlSession session = MybatisUtils.getSession();
List<User> users = session.selectList("com.xiaozhi.mapper.UserMapper.selectUser");
for (User user:users) {
System.out.println(user);
}
}
}
推荐使用第一种方式,结构清晰
可能会出现的问题
IDEA连接数据库出现的问题
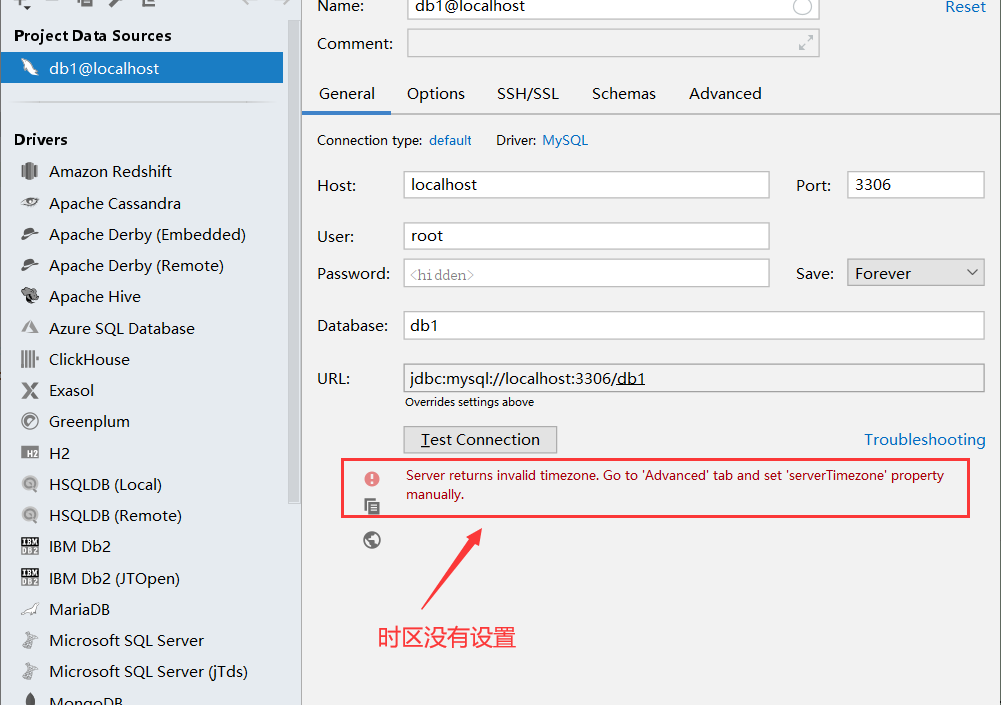
解决
通过show variables like'%time_zone'; 查看当前的时区设置
在mysq命令行模式下输入 set global time_zone='+8:00'; 修改时区,然后重启就可以了
CRUD操作
- resultType:sql语句执行的返回值
- paramterType:参数类型
- #{参数名}:通过这个占位符取值,名字一定要一致,相当于是JDBC中的'?'占位符;
基本步骤
- 编写接口,写入方法
- 编写xml文件
- 测试
- 得到SqlSession对象
- 通过SqlSession对象得到接口的实现类
- 调用接口里面的方法
- 增删改一定要提交事物
- 关闭资源
select查询
根据id查询用户
-
// 根据id查询用户 User selectUserById(Integer id); -
<select id="selectUserById" resultType="com.xiaozhi.pojo.User"> select * from user where id=#{id} </select> -
@Test public void Test3(){ // c测试使用id来查询用户 SqlSession session = MybatisUtils.getSession(); UserMapper mapper = session.getMapper(UserMapper.class); // 得到接口 User user = mapper.selectUserById(1); System.out.println(user); session.close(); }
insert插入
-
// 插入用户信息 int insertUser(User user); -
<!--插入用户--> <insert id="insertUser" parameterType="com.xiaozhi.pojo.User"> insert into user values (#{id},#{username},#{password},#{email}); </insert>
update修改
-
// 修改用户信息 int updateUser(User user); -
<!--修改用户--> <update id="updateUser" parameterType="com.xiaozhi.pojo.User"> update user set username=#{username},password=#{password},email=#{email} where id = #{id} </update>
dalete删除
-
// 删除用户信息 int deleteUser(int id); -
<!--删除用户--> <delete id="deleteUser" parameterType="com.xiaozhi.pojo.User"> delete from user where id = #{id} </delete>
注意:增删改操作一定要提交事物
批量删除
在接口中编写方法,根据id批量删除
int batchDeleteByName(@Param("ids") String ids);
<delete id="batchDeleteByName" >
delete from `t_user` where name in (${names})
</delete>
==注意:批量删除要使用${},而不是#{},因为#{}它会自动带上单引号,不会报错,但是会导致删除失败==
/**
* 测试批量删除
*/
@Test
public void TestBatchDelete(){
SqlSession session = MybatisUtils.getSession();
UserMapper mapper = session.getMapper(UserMapper.class);
int i = mapper.batchDeleteByName("1,2,3");
System.out.println(i);
}
注:如果程序执行成功,但是数据库中的数据还存在,那可能是没有commit,可以设置自动commit,在openSession方法中传入一个true就表示开启自动提交事务
万能的map
情况:我们需要修改密码,这个时候只需要传id和password参数就可以了,我们以往的做法是将整个对象放入,然后调用它的属性来进行修改,在传少个参数的情况下是可以通过map来进行赋值的
注意
- 我们用实体类的方式参数的名字是一定要对应的,而我们的map方式是可以自定义的,但是取值的key一定要是对应的
- map方式可以在不需要多余的参数的时候使用
示例
写好方法,参数是map
// 修改用户密码
int setPwd(Map<String,Object> map);
参数类型是map的,然后通过key来取值
<!--万能的map-->
<update id="setPwd" parameterType="map">
update user set password = #{pwd} where id = #{id};
</update>
练习
根据用户名和密码查询
第一种方式
通过注释的方式
-
// 根据用户名和密码来查询用户 - 第一种方式 User selectUserByNamePaw(@Param("username") String username,@Param("password") String password); -
<select id="selectUserByNamePaw" resultType="com.xiaozhi.pojo.User"> select * from user where username=#{username} and password=#{password} </select> -
@Test public void Test4(){ SqlSession session = MybatisUtils.getSession(); UserMapper mapper = session.getMapper(UserMapper.class); User xiaozhi = mapper.selectUserByNamePaw("xiaozhi", "123456"); System.out.println(xiaozhi); session.close(); }
第二种方式
万能的map:传一个map集合的参数,里面放的是我们的用户名和密码,在xml文件中我们在通过map的key值来输出到sql语句中
-
// 第二种方式 User selectUserByNamePaw2(Map<String,Object> map); -
<select id="selectUserByNamePaw2" parameterType="map" resultType="com.xiaozhi.pojo.User"> select * from user where username=#{username} and password=#{password} </select> -
// 第二种方式 @Test public void Test5(){ Map<String, Object> map = new HashMap<String, Object>(); map.put("username","xiaozhi"); map.put("password","123456"); SqlSession session = MybatisUtils.getSession(); UserMapper mapper = session.getMapper(UserMapper.class); User user = mapper.selectUserByNamePaw2(map); System.out.println(user); session.close(); }
模糊查询
sql注入问题
在jdbc中我们用?代替我们的参数值,假设我们要做一个根据id来查询用户信息的操作,这个?也就是id值,假设我们客户传的是这样的值"3 and id = 1",那么我们的sql语句就会变成是这样的:
select * from user where id = 3 and id = 1;很明显进行了一个字符串拼接,这样就造成了我们的sql语句出现问题,为了避免这种情况,我们要将这个值给写死,用类型或者是其他的方式
示例 - 查询有a字母的用户
<!--模糊查询-->
List<User> selectUserByA(String value);
<select id="selectUserByA" resultType="com.xiaozhi.pojo.User">
select * from user where username like #{value}
</select>
说明:上面的方式会导致SQL注入的问题
<select id="selectUserByA" resultType="com.xiaozhi.pojo.User">
select * from user where username like "%"#{value}"%"
</select>
所以,我们可以将sql语句写死
配置解析
mybatis-config.xml 系统核心配置文件
MyBatis 的配置文件包含了会深深影响 MyBatis 行为的设置和属性信息。
下面是可以进行配置的:
-
configuration(配置) - properties(属性 - settings(设置) - typeAliases(类型别名) - typeHandlers(类型处理器) - objectFactory(对象工厂) - plugins(插件 - environments(环境配置) - environment(环境变量) - transactionManager(事务管理器) - dataSource(数据源) - databaseIdProvider(数据库厂商标识) - mappers(映射器)
说明:注意标签的位置,顺序不对是会报错的,一定要按人家的规范来
我们可以阅读 mybatis-config.xml 上面的dtd的头文件!

属性(Properties)
这些属性可以在外部进行配置,并可以进行动态替换。你既可以在典型的 Java 属性文件中配置这些属性,也可以在 properties 元素的子元素中设置。
第一步 :在资源目录下新建一个db.properties
driver=com.mysql.jdbc.Driver
url=jdbc:mysql://localhost:3306/db1?useSSL=true&useUnicode=true&characterEncoding=utf8
username=root
password=root
第二步 : 将文件导入properties 配置文件
<configuration>
<properties resource="jdbc.properties"/>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
</environment>
</environments>
<mappers>
<!--mapper地址-->
<mapper resource="com/xiaozhi/dao/UserMapper.xml"/>
</mappers>
</configuration>
properties元素中的resource是数据源,导入的方式有两种:
①直接引入
②在properties元素的子元素property中设置值,有name和value属性,value属性指向的是文件中的名字,name属性是用来取值的
<properties resource="db.properties">
<property name="driver" value="driver"/>
<property name="url" value="url"/>
<property name="username" value="root"/>
<property name="password" value="password"/>
</properties>
- 配置文件优先级问题
- 优先执行的是properties元素中的数据源
- 新特性:使用占位符
environments元素
可以配置多套运行环境
<environments default="development">
<environment id="development">
<transactionManager type="JDBC">
<property name="..." value="..."/>
</transactionManager>
<dataSource type="POOLED">
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
</environment>
</environments>
- 配置MyBatis的多套运行环境,将SQL映射到多个不同的数据库上,必须指定其中一个为默认运行环境(通过default指定)
子元素节点environment
- dataSource元素使用标准的JDBC数据源接口来配置JDBC连接对象的资源
- 数据源是必须配置的
- 有三种内置的数据源类型
- type="[UNPOOLED|POOLED|JNDI]"
- unpooled:这个数据源的实现只是每次被请求时打开和关闭连接。
- pooled:这种数据源的实现利用“池”的概念将 JDBC 连接对象组织起来 , 这是一种使得并发 Web 应用快速响应请求的流行处理方式。
- jndi:这个数据源的实现是为了能在如 Spring 或应用服务器这类容器中使用,容器可以集中或在外部配置数据源,然后放置一个 JNDI 上下文的引用。
- 数据源也有很多第三方的实现,比如dbcp,c3p0,druid等等....
子元素节点:transactionManager - [ 事务管理器 ]
-
<!-- 语法 --> <transactionManager type="[ JDBC | MANAGED ]"/> -
这两种事务管理器类型都不需要设置任何属性。
-
具体的一套环境,通过设置id进行区别,id保证唯一!
mappers(映射器)
- 映射器 : 定义映射SQL语句文件
- 既然 MyBatis 的行为其他元素已经配置完了,我们现在就要定义 SQL 映射语句了。但是首先我们需要告诉 MyBatis 到哪里去找到这些语句。Java 在自动查找这方面没有提供一个很好的方法,所以最佳的方式是告诉 MyBatis 到哪里去找映射文件。你可以使用相对于类路径的资源引用, 或完全限定资源定位符(包括
file:///的 URL),或类名和包名等。映射器是MyBatis中最核心的组件之一,在MyBatis 3之前,只支持xml映射器,即:所有的SQL语句都必须在xml文件中配置。而从MyBatis 3开始,还支持接口映射器,这种映射器方式允许以Java代码的方式注解定义SQL语句,非常简洁。
引入资源方式
<!-- 使用相对于类路径的资源引用 -->
<mappers>
<mapper resource="org/mybatis/builder/PostMapper.xml"/>
</mappers>
<!-- 使用完全限定资源定位符(URL) -->
<mappers>
<mapper url="file:///var/mappers/AuthorMapper.xml"/>
</mappers>
<!--
使用映射器接口实现类的完全限定类名
需要配置文件名称和接口名称一致,并且位于同一目录下
-->
<mappers>
<mapper class="org.mybatis.builder.AuthorMapper"/>
</mappers>
<!--
将包内的映射器接口实现全部注册为映射器
但是需要配置文件名称和接口名称一致,并且位于同一目录下
-->
<mappers>
<package name="org.mybatis.builder"/>
</mappers>
Mapper文件
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.kuang.mapper.UserMapper">
</mapper>
-
namespace中文意思:命名空间,作用如下:
-
namespace的命名必须跟某个接口同名
-
接口中的方法与映射文件中sql语句id应该一一对应
-
-
- namespace和子元素的id联合保证唯一 , 区别不同的mapper
- 绑定DAO接口
- namespace命名规则 : 包名+类名
typeAliases(类型别名)
说明:有类别名之后我们就不用在写类名了,写我们设定好的名字就可以找到指定的类
注意:注册的地方不能使用这种方式
第一种方式
类型别名可为 Java 类型设置一个缩写名字。 它仅用于 XML 配置,意在降低冗余的全限定类名书写。例如:
<typeAliases>
<typeAlias alias="Author" type="domain.blog.Author"/>
<typeAlias alias="Blog" type="domain.blog.Blog"/>
<typeAlias alias="Comment" type="domain.blog.Comment"/>
<typeAlias alias="Post" type="domain.blog.Post"/>
<typeAlias alias="Section" type="domain.blog.Section"/>
<typeAlias alias="Tag" type="domain.blog.Tag"/>
</typeAliases>
当这样配置时,Blog 可以用在任何使用 domain.blog.Blog 的地方。
代码实现
mybatis-config.xml中添加
<typeAliases>
<typeAlias alias="User" type="com.xiaozhi.pojo.User"/>
</typeAliases>
修改UserMapper.xml
<select id="selectUser" resultType="User">
select * from user
</select>
第二种方式
也可以指定一个包名,MyBatis 会在包名下面搜索需要的 Java Bean,比如:
<typeAliases>
<package name="domain.blog"/>
</typeAliases>
没有注解的情况:会使用 Bean 的首字母小写的非限定类名来作为它的别名。 比如 domain.blog.Author 的别名为 author;
<typeAliases>
<package name="com.xiaozhi"/>
</typeAliases>
<select id="selectUser" resultType="user">
select * from user
</select>
有注解的情况:则别名为其注解值。见下面的例子:
@Alias("author")
public class Author {
...
}
代码实现
@Alias("xiaozhi")
public class User {
<select id="selectUser" resultType="xiaozhi">
select * from user
</select>
常见类型别名
下面是一些为常见的 Java 类型内建的类型别名。它们都是不区分大小写的,注意,为了应对原始类型的命名重复,采取了特殊的命名风格。
| 别名 | 映射的类型 |
|---|---|
| _byte | byte |
| _long | long |
| _short | short |
| _int | int |
| _integer | int |
| _double | double |
| _float | float |
| _boolean | boolean |
| string | String |
| byte | Byte |
| long | Long |
| short | Short |
| int | Integer |
| integer | Integer |
| double | Double |
| float | Float |
| boolean | Boolean |
| date | Date |
| decimal | BigDecimal |
| bigdecimal | BigDecimal |
| object | Object |
| map | Map |
| hashmap | HashMap |
| list | List |
| arraylist | ArrayList |
| collection | Collection |
| iterator | Iterator |
其他配置浏览
设置(settings)
这是 MyBatis 中极为重要的调整设置,它们会改变 MyBatis 的运行时行为。
目前需要知道的三个:
- 懒加载 lazyLoadingEnabled
- 日志实现 logImpl
- 缓存开启关闭 cacheEnabled
一个配置完整的设置如下
<settings>
<setting name="cacheEnabled" value="true"/>
<setting name="lazyLoadingEnabled" value="true"/>
<setting name="multipleResultSetsEnabled" value="true"/>
<setting name="useColumnLabel" value="true"/>
<setting name="useGeneratedKeys" value="false"/>
<setting name="autoMappingBehavior" value="PARTIAL"/>
<setting name="autoMappingUnknownColumnBehavior" value="WARNING"/>
<setting name="defaultExecutorType" value="SIMPLE"/>
<setting name="defaultStatementTimeout" value="25"/>
<setting name="defaultFetchSize" value="100"/>
<setting name="safeRowBoundsEnabled" value="false"/>
<setting name="mapUnderscoreToCamelCase" value="false"/>
<setting name="localCacheScope" value="SESSION"/>
<setting name="jdbcTypeForNull" value="OTHER"/>
<setting name="lazyLoadTriggerMethods" value="equals,clone,hashCode,toString"/>
</settings>
类型处理器
- 无论是 MyBatis 在预处理语句(PreparedStatement)中设置一个参数时,还是从结果集中取出一个值时, 都会用类型处理器将获取的值以合适的方式转换成 Java 类型。
- 你可以重写类型处理器或创建你自己的类型处理器来处理不支持的或非标准的类型。【了解即可】
对象工厂
- MyBatis 每次创建结果对象的新实例时,它都会使用一个对象工厂(ObjectFactory)实例来完成。
- 默认的对象工厂需要做的仅仅是实例化目标类,要么通过默认构造方法,要么在参数映射存在的时候通过有参构造方法来实例化。
- 如果想覆盖对象工厂的默认行为,则可以通过创建自己的对象工厂来实现。【了解即可】
生命周期和作用域
分析一下Mybatis的执行过程!
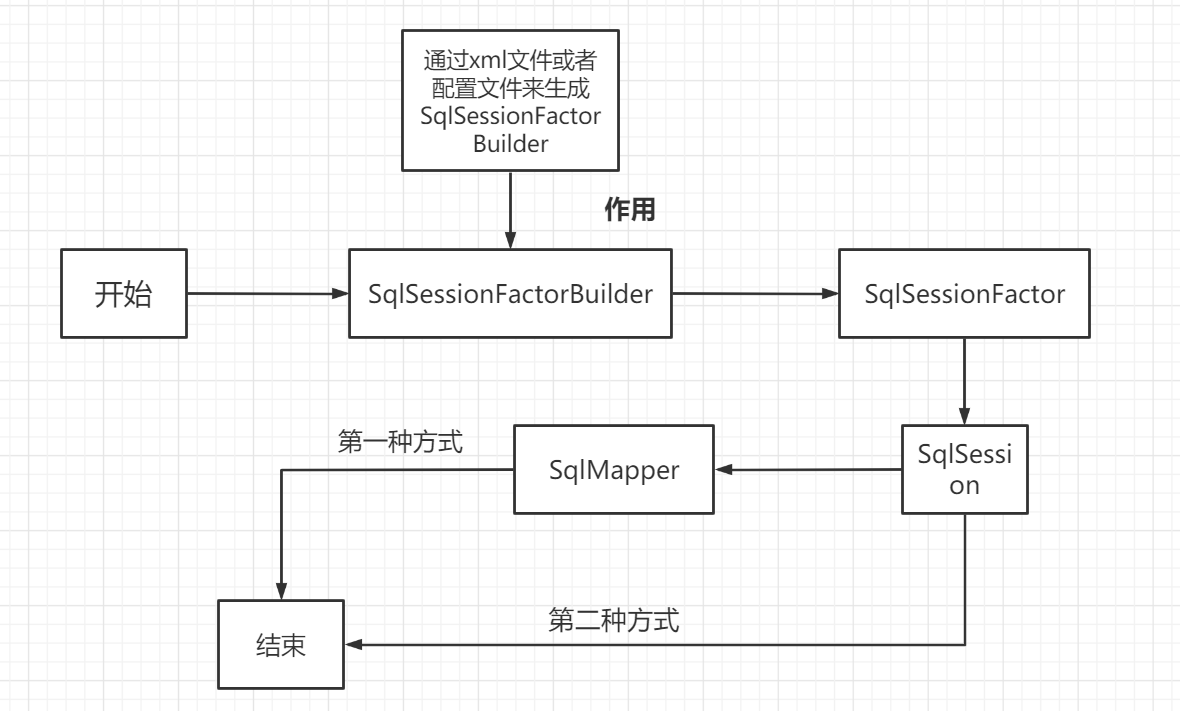
作用域理解:
- SqlSessionFactoryBuilder 的作用在于创建 SqlSessionFactory,创建成功后,SqlSessionFactoryBuilder 就失去了作用,所以它只能存在于创建 SqlSessionFactory 的方法中,而不要让其长期存在。因此 SqlSessionFactoryBuilder 实例的最佳作用域是方法作用域(也就是局部方法变量)。
- SqlSessionFactory 可以被认为是一个数据库连接池,它的作用是创建 SqlSession 接口对象。因为 MyBatis 的本质就是 Java 对数据库的操作,所以 SqlSessionFactory 的生命周期存在于整个 MyBatis 的应用之中,所以一旦创建了 SqlSessionFactory,就要长期保存它,直至不再使用 MyBatis 应用,所以可以认为 SqlSessionFactory 的生命周期就等同于 MyBatis 的应用周期。
- 由于 SqlSessionFactory 是一个对数据库的连接池,所以它占据着数据库的连接资源。如果创建多个 SqlSessionFactory,那么就存在多个数据库连接池,这样不利于对数据库资源的控制,也会导致数据库连接资源被消耗光,出现系统宕机等情况,所以尽量避免发生这样的情况。
- 因此在一般的应用中我们往往希望 SqlSessionFactory 作为一个单例,让它在应用中被共享。所以说 SqlSessionFactory 的最佳作用域是应用作用域。
- 如果说 SqlSessionFactory 相当于数据库连接池,那么 SqlSession 就相当于一个数据库连接(Connection 对象),你可以在一个事务里面执行多条 SQL,然后通过它的 commit、rollback 等方法,提交或者回滚事务。所以它应该存活在一个业务请求中,处理完整个请求后,应该关闭这条连接,让它归还给 SqlSessionFactory,否则数据库资源就很快被耗费精光,系统就会瘫痪,所以用 try...catch...finally... 语句来保证其正确关闭。
- 所以 SqlSession 的最佳的作用域是请求或方法作用域。
ResultMap元素
解决:字段名和属性名不一致
说明:在数据库中,两个英文的时候通常是用_隔开,而在我们的java程序中是第二个字母大写这样来区分的,那么这个就会导致两者的名字不一致,所以我们可以使用ResultMap来解决

方式一:在SQL语句中添加别名就可以了
<select id="selectUser" resultType="user">
select id,username name,password from user
</select>
说明:这种方式比较笨重,不建议使用,一般使用第二种方式
方式二:通过ResultMap元素来进行映射
在ResultMap元素中有两个属性,id表示名字,type表示要修改的类
子元素result中的两个属性
- column:表示字段
- property:表示属性
通过这两个属性来进行映射,property相当于是map中的key,column相当于是value,通过key来取值
具体实现
表结构
实体类
public class User {
private Integer id;
private String name;
private String password;
代码
<!--id表示用哪个resultMap来进行映射,type表示对哪个实体类进行映射-->
<resultMap id="map" type="User">
<result column="username" property="name"/>
<result column="id" property="id"/>
</resultMap>
<!--id是接口中的方法名,resultType是结果集的类型-->
<select id="selectUser" resultMap="map">
select id,username,password from user
</select>
说明:result可以有多个
日志
介绍
通过百度去学习
- Log4j是Apache的一个开源项目
- 通过使用Log4j,我们可以控制日志信息输送的目的地:控制台,文本,GUI组件....
- 我们也可以控制每一条日志的输出格式;
- 通过定义每一条日志信息的级别,我们能够更加细致地控制日志的生成过程。最令人感兴趣的就是,这些可以通过一个配置文件来灵活地进行配置,而不需要修改应用的代码。
作用:进行排错,很清晰的展现给我们看
在我们之前排错都时用的sout和debug,今后就使用日志来进行排错
日志具体的实现是在设置中设定的,默认是没有开启的,要去手动打开
mybatis-config.xml配置文件中添加
<settings>
<!--name属性固定的,value可以换成你想要的日志-->
<setting name="logImpl" value=""/>
</settings>
有这几个value
- SLF4J
- LOG4J**(掌握)**
- LOG4J2
- JDK_LOGGING
- COMMONS_LOGGING
- STDOUT_LOGGING(mybatis自带的。需要掌握)
- NO_LOGGING
注意事项:空格一定不能要,有空格会报错的,名字也一定要正确
标准的(STDOUT_LOGGING)不用导包,其他的是要导包才能使用的
使用STDOUT_LOGGING
<settings>
<setting name="logImpl" value="STDOUT_LOGGING"/>
</settings>
说明:因为是自带的,所以直接设置就好了
使用LOG4J
1、导入log4j的包
通过maven仓库引入log4j
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
2、配置文件编写
#将等级为DEBUG的日志信息输出到console和file这两个目的地,console和file的定义在下面的代码
log4j.rootLogger=DEBUG,console,file
#控制台输出的相关设置
log4j.appender.console = org.apache.log4j.ConsoleAppender
log4j.appender.console.Target = System.out
log4j.appender.console.Threshold=DEBUG
log4j.appender.console.layout = org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=[%c]-%m%n
#文件输出的相关设置
log4j.appender.file = org.apache.log4j.RollingFileAppender
log4j.appender.file.File=./log/mybatis.log
log4j.appender.file.MaxFileSize=10mb
log4j.appender.file.Threshold=DEBUG
log4j.appender.file.layout=org.apache.log4j.PatternLayout
log4j.appender.file.layout.ConversionPattern=[%p][%d{yy-MM-dd}][%c]%m%n
#日志输出级别
log4j.logger.org.mybatis=DEBUG
log4j.logger.java.sql=DEBUG
log4j.logger.java.sql.Statement=DEBUG
log4j.logger.java.sql.ResultSet=DEBUG
log4j.logger.java.sql.PreparedStatement=DEBUG
3、setting设置日志实现
<settings>
<setting name="logImpl" value="LOG4J"/>
</settings>
4、在程序中使用Log4j进行输出!
常用的三个方法
- info 单纯输出的时候使用
- debug 调试的时候使用
- error try-catch中使用
public class UserMapperTest {
private static Logger logger = Logger.getLogger(UserMapperTest.class);
@Test
public void Test1() {
logger.info("info:进入到UserMapper方法");
logger.debug("debug:进入到UserMapper方法");
logger.error("error:进入到UserMapper方法");
SqlSession session = MybatisUtils.getSession();
UserMapper mapper = session.getMapper(UserMapper.class);
List<User> users = mapper.selectUser();
for (User user : users) {
System.out.println(user);
}
session.close();
}
}
5、测试,看控制台输出!
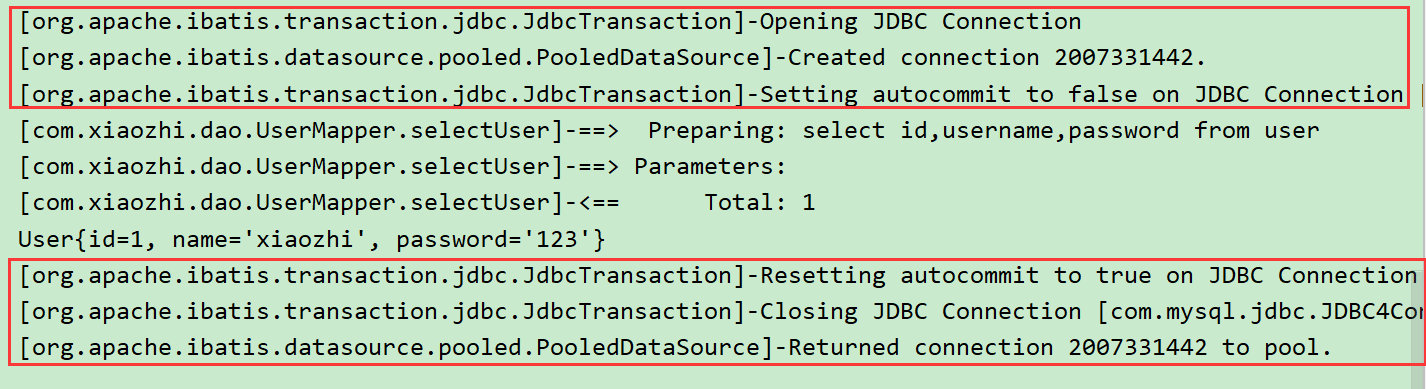
分页实现
方式一:SQL语句
做法:将分页的两个参数放到map中或者给直接设两个参数,然后传给sql语句执行
-
修改mapper文件
<select id="selectUserLimit" resultMap="User" parameterType="map"> select * from user limit #{startIndex} , #{pageSize} </select> -
Mapper接口,参数为map
// 获取所有的用户信息 List<User> selectUserLimit(Map<String,Integer> map); -
测试
方式二:RowBounds
我们除了使用Limit在SQL层面实现分页,也可以使用RowBounds在Java代码层面实现分页,当然此种方式作为了解即可。我们来看下如何实现的!
RowBounds实现分页的方式依赖于用全类名创建的方式,在创建RowBounds对象的时候传入两个参数,这两个参数分别是起始位置和一页的数量
代码实现
-
// 用RowBounds实现分页 List<User> getUserByRowBounds(); -
<select id="getUserByRowBounds" resultType="User"> select * from user </select> -
@Test public void Test2(){ SqlSession session = MybatisUtils.getSession(); RowBounds rowBounds = new RowBounds(0,4); List<User> users = session.selectList("com.xiaozhi.dao.UserMapper.getUserByRowBounds", null, rowBounds); for (User user : users) { System.out.println(user); } session.close(); }
方式三:mybatispageHelper插件
需要的时候看官方文档使用就可以了
1、添加依赖
<!-- https://mvnrepository.com/artifact/com.github.pagehelper/pagehelper -->
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper</artifactId>
<version>5.2.0</version>
</dependency>
2、配置分页插件
在Mybatis的核心配置文件中配置插件
<plugins>
<!--设置分页插件-->
<plugin interceptor="com.github.pagehelper.PageInterceptor"></plugin>
</plugins>
3、分页插件的使用
①在查询之前使用PageHelper.startPage(int pageNum, int pageSize)开启分页功能
- pageNum:当前页的页码
- pageSize:每页显示的条数
②在查询获取list集合之后,使用PageInfo<T> pageInfo = new PageInfo<>(List<T> list, int navigatePages)获取分页相关数据
- list:分页之后的数据
- navigatePages:导航分页的页码数
得到的页码数,除了1、2页在左边,其他的当前页都在中间显示,比如当前页是第五页,那么页码就会显示成
[3,4,5,6,7],第五页会在中间
③插件字段的解释:
- pageNum:当前页的页码
- pageSize:每页显示的条数
- size:当前页显示的真实条数
- total:总记录数
- pages:总页数
- prePage:上一页的页码
- nextPage:下一页的页码
- isFirstPage/isLastPage:是否为第一页/最后一页
- hasPreviousPage/hasNextPage:是否存在上一页/下一页
- navigatePages:导航分页的页码数
- navigatepageNums:导航分页的页码,[1,2,3,4,5]
④代码演示
/**
* 测试分页插件
*/
@Test
public void Test02(){
SqlSession session = MybatisUtils.getSession();
UserMapper mapper = session.getMapper(UserMapper.class);
Page<Object> page = PageHelper.startPage(2, 5);
List<User> users = mapper.selectByExample(null);
// 需要导航分页的页码就使用下面的这个
PageInfo<User> info = new PageInfo<>(users, 5);
users.forEach(System.out::println);
System.out.println(info);
}
使用注解开发
面向接口编程
- 大家之前都学过面向对象编程,也学习过接口,但在真正的开发中,很多时候我们会选择面向接口编程
- 根本原因 : 解耦 , 可拓展 , 提高复用 , 分层开发中 , 上层不用管具体的实现 , 大家都遵守共同的标准 , 使得开发变得容易 , 规范性更好
- 在一个面向对象的系统中,系统的各种功能是由许许多多的不同对象协作完成的。在这种情况下,各个对象内部是如何实现自己的,对系统设计人员来讲就不那么重要了;
- 而各个对象之间的协作关系则成为系统设计的关键。小到不同类之间的通信,大到各模块之间的交互,在系统设计之初都是要着重考虑的,这也是系统设计的主要工作内容。面向接口编程就是指按照这种思想来编程。
关于接口的理解
-
接口从更深层次的理解,应是定义(规范,约束)与实现(名实分离的原则)的分离。
-
接口的本身反映了系统设计人员对系统的抽象理解。
-
接口应有两类:
-
- 第一类是对一个个体的抽象,它可对应为一个抽象体(abstract class);
- 第二类是对一个个体某一方面的抽象,即形成一个抽象面(interface);
- 第一类是对一个个体的抽象,它可对应为一个抽象体(abstract class);
-
一个体有可能有多个抽象面。抽象体与抽象面是有区别的。
三个面向区别
- 面向对象是指,我们考虑问题时,以对象为单位,考虑它的属性及方法 .
- 面向过程是指,我们考虑问题时,以一个具体的流程(事务过程)为单位,考虑它的实现 .
- 接口设计与非接口设计是针对复用技术而言的,与面向对象(过程)不是一个问题.更多的体现就是对系统整体的架构
设置自动提交事物
在openSession中传一个true值即可!
// 获取sqlSession连接
public static SqlSession getSession() {
return sqlSessionFactory.openSession(true);
}
利用注解开发
-
mybatis最初配置信息是基于 XML ,映射语句(SQL)也是定义在 XML 中的。而到MyBatis 3提供了新的基于注解的配置。不幸的是,Java 注解的的表达力和灵活性十分有限。最强大的 MyBatis 映射并不能用注解来构建
-
sql 类型主要分成 :
-
- @select ()
- @update ()
- @Insert ()
- @delete ()
- @select ()
底层实现:利用了反射得到注解里面的sql语句,然后进行解析,本质上利用了jvm的动态代理机制
**注意:**利用注解开发就不需要mapper.xml映射文件了 .
使用注解来CRUD
查询
-
在接口的方法上添加注解
// 使用注解来写sql语句 @Select("select * from user") List<User> getAllUser(); -
在核心文件中注册绑定接口
<mappers> <!--mapper地址--> <mapper class="com.xiaozhi.dao.UserMapper"/> </mappers> -
测试
@Test public void Test3(){ SqlSession session = MybatisUtils.getSession(); UserMapper mapper = session.getMapper(UserMapper.class); List<User> allUser = mapper.getAllUser(); for (User user : allUser) { System.out.println(user); } }
增加
// 插入语句
@Insert("insert into user values(#{id},#{name},#{password})")
int addtUser(User user);
修改
// 更新
@Update("update user set username = #{name} ,password = #{password} where id = #{id}")
int updateUser(User user);
删除
// 删除
@Delete("delete from user where id = #{id}")
int deleteUser(@Param("id") int id);
mybatis流程解析
使用Debug查看流程
${} 和 #{} 的区别
-
#{} 的作用主要是替换预编译语句(PrepareStatement)中的占位符? 【推荐使用】
INSERT INTO user (name) VALUES (#{name}); INSERT INTO user (name) VALUES (?); -
${} 的作用是直接进行字符串替换
INSERT INTO user (name) VALUES ('${name}'); INSERT INTO user (name) VALUES ('kuangshen');
使用注解和配置文件协同开发,才是MyBatis的最佳实践!
Lombok插件
作用:偷懒,通过注释可以不用去写get、set方法、toString和equals、有参和无参构造器..等等。
缺点:不能对构造器进行重载,可以手动编写弥补缺点
使用步骤
-
去IDEA插件商店中下载
-
在项目中导入lombox的jar包,引入maven依赖
<dependencies> <!-- https://mvnrepository.com/artifact/org.projectlombok/lombok --> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>1.18.10</version> <scope>provided</scope> </dependency> </dependencies> -
使用注释
Features @Getter and @Setter @FieldNameConstants @ToString @EqualsAndHashCode @AllArgsConstructor, @RequiredArgsConstructor and @NoArgsConstructor @Log, @Log4j, @Log4j2, @Slf4j, @XSlf4j, @CommonsLog, @JBossLog, @Flogger, @CustomLog @Data @Builder @SuperBuilder @Singular @Delegate @Value @Accessors @Wither @With @SneakyThrows @val @var experimental @var @UtilityClass Lombok config system Code inspections Refactoring actions (lombok and delombok) -
测试
@Data @AllArgsConstructor @NoArgsConstructor public class User { private Integer id; private String name; private String passord; }
一对多和多对一处理
说明:result只能处理简单额属性,不能处理复杂属性,比如对象、集合。
// association元素用于处理实体类对象,对应多对一
/collection元素用于处理集合,对应一对多
环境搭建
1、导入lombok,引入Maven依赖
<dependencies>
<!-- https://mvnrepository.com/artifact/org.projectlombok/lombok -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.10</version>
<scope>provided</scope>
</dependency>
</dependencies>
2、创建两个表并插入数据
CREATE TABLE `teacher` (
`id` INT(10) NOT NULL,
`name` VARCHAR(30) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=INNODB DEFAULT CHARSET=utf8
INSERT INTO teacher(`id`, `name`) VALUES (1, '小智老师');
CREATE TABLE `student` (
`id` INT(10) NOT NULL,
`name` VARCHAR(30) DEFAULT NULL,
`tid` INT(10) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `fktid` (`tid`),
CONSTRAINT `fktid` FOREIGN KEY (`tid`) REFERENCES `teacher` (`id`)
) ENGINE=INNODB DEFAULT CHARSET=utf8
INSERT INTO `student` (`id`, `name`, `tid`) VALUES ('1', '小明', '1');
INSERT INTO `student` (`id`, `name`, `tid`) VALUES ('2', '小红', '1');
INSERT INTO `student` (`id`, `name`, `tid`) VALUES ('3', '小张', '1');
INSERT INTO `student` (`id`, `name`, `tid`) VALUES ('4', '小李', '1');
INSERT INTO `student` (`id`, `name`, `tid`) VALUES ('5', '小王', '1');
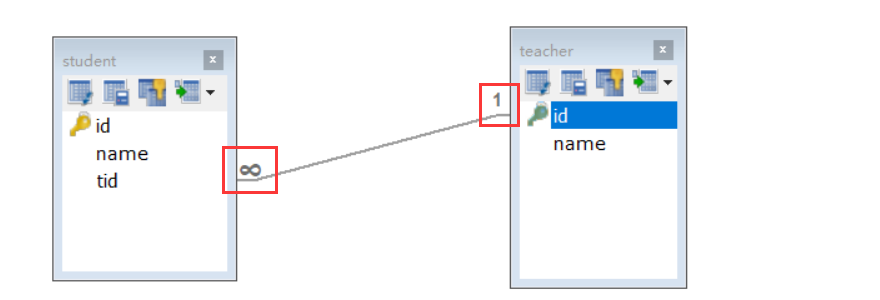
3、创建对应的两实体类
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Student {
private Integer id;
private String name;
private Teacher teacher;
}
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Teacher {
private String name;
private Integer id;
}
4、编写对应的xml文件
TeacherMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.xiaozhi.dao.TeacherMapper">
</mapper>
StudentMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.xiaozhi.dao.StudentMapper">
</mapper>
多对一处理
情况:查询学生,学生和老师的关系时多对一
association元素:用于处理实体类对象,对应多对一
代码实现
1、给StudentMapper接口增加方法
// 查询所有学生
// 子查询
public List<Student> getStudentTeacher();
// 连表查询
public List<Student> getStudentTeacher2();
2、编写对应的Mapper文件
<!--方式二:对应数据库连表查询-->
<select id="getStudentTeacher2" resultMap="StudentTeacher2">
select t1.id sid,t1.name sname,t2.name tname
from student t1,teacher t2
where t1.tid = t2.id
</select>
<resultMap id="StudentTeacher2" type="Student">
<id property="id" column="sid"/>
<result property="name" column="sname"/>
<association property="teacher" javaType="Teacher">
<result property="name" column="tname"/>
</association>
</resultMap>
<!--========================================================-->
<!--方式一:对应数据库子查询的-->
<select id="getStudentTeacher" resultMap="StudentTeacher">
select * from student
</select>
<resultMap id="StudentTeacher" type="Student">
<association property="teacher" column="tid"
javaType="Teacher" select="getTeacher"/>
</resultMap>
<select id="getTeacher" resultType="teacher">
select * from teacher where id = #{id}
</select>
3、测试
一对多处理
情况:查询老师,老师和学生的关系是一对多
collection元素:用于处理集合,对应一对多
ofType属性是指集合中的泛型
代码实现
1、给TeacherMapper接口增加方法
public interface TeacherMapper {
// 实现一对多
// 连表查询的方式
public Teacher getTeacher(@Param("id") int id);
// 子查询的方式
public Teacher getTeacher2(@Param("id") int id);
}
2、编写对应的Mapper文件
<!--连表查询的方式-->
<select id="getTeacher" resultMap="TeacherStudent">
SELECT t2.id sid,t2.name sname,t1.id tid,t1.name tname
FROM teacher t1,student t2
WHERE t1.`id` = t2.`tid` and t1.id = #{id}
</select>
<resultMap id="TeacherStudent" type="Teacher" >
<id property="id" column="tid"/>
<result property="name" column="tname"/>
<collection property="students" ofType="Student">
<id property="id" column="sid"/>
<result property="name" column="sname"/>
<result property="tid" column="tid"/>
</collection>
</resultMap>
<!--==============================================-->
<!--子查询的方式-->
<!--通过id查询出是那个老师,再通过tid查询出有这个tid学生-->
<select id="getTeacher2" resultMap="TeacherStudent2">
select * from teacher where id = #{id}
</select>
<resultMap id="TeacherStudent2" type="Teacher">
<!--因为是同名的,所以这里省略不写-->
<collection property="students" column="id" ofType="Student" select="getStudentByTeacherId"/>
</resultMap>
<select id="getStudentByTeacherId" resultType="Student">
select * from student where tid = #{id}
</select>
3、测试
小结
1、关联-association
2、集合-collection
3、所以association是用于一对一和多对一,而collection是用于一对多的关系
4、JavaType和ofType都是用来指定对象类型的
- JavaType是用来指定pojo中属性的类型
- ofType指定的是映射到list集合属性中pojo的类型。
5、映射无非就是将属性和序列对应起来,比如学生表中的tid(外键)可以映射成是老师的id,然后再进行查询,这也就是我们所说的结果嵌套查询(子查询)
高级结果映射

⬆官网描述
1、constructor
将结果注入到构造方法中来进行结构映射
从3.4.3开始,可以在指定参数名称的前提下,任意顺序编写arg元素
可以通过添加@Param注释来通过名称应用构造方法参数
| 属性 | 描述 |
|---|---|
column | 数据库中的列名,或者是列的别名。一般情况下,这和传递给 resultSet.getString(columnName) 方法的参数一样。 |
javaType | 一个 Java 类的完全限定名,或一个类型别名(关于内置的类型别名,可以参考上面的表格)。 如果你映射到一个 JavaBean,MyBatis 通常可以推断类型。然而,如果你映射到的是 HashMap,那么你应该明确地指定 javaType 来保证行为与期望的相一致。 |
jdbcType | JDBC 类型,所支持的 JDBC 类型参见这个表格之前的“支持的 JDBC 类型”。 只需要在可能执行插入、更新和删除的且允许空值的列上指定 JDBC 类型。这是 JDBC 的要求而非 MyBatis 的要求。如果你直接面向 JDBC 编程,你需要对可能存在空值的列指定这个类型。 |
typeHandler | 我们在前面讨论过默认的类型处理器。使用这个属性,你可以覆盖默认的类型处理器。 这个属性值是一个类型处理器实现类的完全限定名,或者是类型别名。 |
select | 用于加载复杂类型属性的映射语句的 ID,它会从 column 属性中指定的列检索数据,作为参数传递给此 select 语句。具体请参考关联元素。 |
resultMap | 结果映射的 ID,可以将嵌套的结果集映射到一个合适的对象树中。 它可以作为使用额外 select 语句的替代方案。它可以将多表连接操作的结果映射成一个单一的 ResultSet。这样的 ResultSet 将会将包含重复或部分数据重复的结果集。为了将结果集正确地映射到嵌套的对象树中,MyBatis 允许你 “串联”结果映射,以便解决嵌套结果集的问题。想了解更多内容,请参考下面的关联元素。 |
name | 构造方法形参的名字。从 3.4.3 版本开始,通过指定具体的参数名,你可以以任意顺序写入 arg 元素。 |
代码实现
-
首先在数据库中创建一个user表,有id,name,age三个字段
-
然后在创建user类,定义对应的是哪个属性,定义一个构造器
@Data @NoArgsConstructor @AllArgsConstructor public class User { private Integer id; private String name; private Integer age; } -
创建mapper文件
<mapper namespace="com.xiaozhi.mapper.UserMapper"> <select id="selectUser" resultMap="mapUser"> select * from t_user </select> <resultMap id="mapUser" type="User"> <constructor> <idArg column="id" javaType="int"/> <arg column="name" javaType="String"/> <arg column="age" javaType="int"/> </constructor> </resultMap> </mapper> -
结构就是按照我们设定好的映射注入到构造器中
2、id和result
类属性和数据库字段的映射,id对应的属性会被标记为对象的标识符,提高整体性能
id和Result属性
| 属性 | 描述 |
|---|---|
property | 映射到列结果的字段或属性。如果 JavaBean 有这个名字的属性(property),会先使用该属性。否则 MyBatis 将会寻找给定名称的字段(field)。 无论是哪一种情形,你都可以使用常见的点式分隔形式进行复杂属性导航。 比如,你可以这样映射一些简单的东西:“username”,或者映射到一些复杂的东西上:“address.street.number”。 |
column | 数据库中的列名,或者是列的别名。一般情况下,这和传递给 resultSet.getString(columnName) 方法的参数一样。 |
javaType | 一个 Java 类的全限定名,或一个类型别名(关于内置的类型别名,可以参考上面的表格)。 如果你映射到一个 JavaBean,MyBatis 通常可以推断类型。然而,如果你映射到的是 HashMap,那么你应该明确地指定 javaType 来保证行为与期望的相一致。 |
jdbcType | JDBC 类型,所支持的 JDBC 类型参见这个表格之后的“支持的 JDBC 类型”。 只需要在可能执行插入、更新和删除的且允许空值的列上指定 JDBC 类型。这是 JDBC 的要求而非 MyBatis 的要求。如果你直接面向 JDBC 编程,你需要对可以为空值的列指定这个类型。 |
typeHandler | 我们在前面讨论过默认的类型处理器。使用这个属性,你可以覆盖默认的类型处理器。 这个属性值是一个类型处理器实现类的全限定名,或者是类型别名。 |
支持的JDBC类型
为了以后可能的使用场景,MyBatis 通过内置的 jdbcType 枚举类型支持下面的 JDBC 类型。
BIT | FLOAT | CHAR | TIMESTAMP | OTHER | UNDEFINED |
|---|---|---|---|---|---|
TINYINT | REAL | VARCHAR | BINARY | BLOB | NVARCHAR |
SMALLINT | DOUBLE | LONGVARCHAR | VARBINARY | CLOB | NCHAR |
INTEGER | NUMERIC | DATE | LONGVARBINARY | BOOLEAN | NCLOB |
BIGINT | DECIMAL | TIME | NULL | CURSOR | ARRAY |
3、关联
多对一的情况使用关联,比如多个博客对应一个用户
关联结果映射和其它类型的映射工作方式差不多。 你需要指定目标属性名以及属性的javaType(很多时候 MyBatis 可以自己推断出来),在必要的情况下你还可以设置 JDBC 类型,如果你想覆盖获取结果值的过程,还可以设置类型处理器。
两种关联方式:
- 嵌套 Select 查询:通过执行另外一个 SQL 映射语句来加载期望的复杂类型。
- 嵌套结果映射:使用嵌套的结果映射来处理连接结果的重复子集。
| 属性 | 描述 |
|---|---|
property | 映射到列结果的字段或属性。如果用来匹配的 JavaBean 存在给定名字的属性,那么它将会被使用。否则 MyBatis 将会寻找给定名称的字段。 无论是哪一种情形,你都可以使用通常的点式分隔形式进行复杂属性导航。 比如,你可以这样映射一些简单的东西:“username”,或者映射到一些复杂的东西上:“address.street.number”。 |
javaType | 一个 Java 类的完全限定名,或一个类型别名(关于内置的类型别名,可以参考上面的表格)。 如果你映射到一个 JavaBean,MyBatis 通常可以推断类型。然而,如果你映射到的是 HashMap,那么你应该明确地指定 javaType 来保证行为与期望的相一致。 |
jdbcType | JDBC 类型,所支持的 JDBC 类型参见这个表格之前的“支持的 JDBC 类型”。 只需要在可能执行插入、更新和删除的且允许空值的列上指定 JDBC 类型。这是 JDBC 的要求而非 MyBatis 的要求。如果你直接面向 JDBC 编程,你需要对可能存在空值的列指定这个类型。 |
typeHandler | 我们在前面讨论过默认的类型处理器。使用这个属性,你可以覆盖默认的类型处理器。 这个属性值是一个类型处理器实现类的完全限定名,或者是类型别名。 |
3.1 关联的嵌套select查询
| 属性 | 描述 |
|---|---|
column | 数据库中的列名,或者是列的别名。 |
select | 用于加载复杂类型属性的映射语句的 ID,它会从 column 属性指定的列中检索数据,作为参数传递给目标 select 语句。 |
fetchType | 可选的。有效值为 lazy 和 eager。 指定属性后,将在映射中忽略全局配置参lazyLoadingEnabled,使用属性的值。 |
示例:
<resultMap id="blogResult" type="Blog">
<association property="author" column="author_id" javaType="Author" select="selectAuthor"/>
</resultMap>
<select id="selectBlog" resultMap="blogResult">
SELECT * FROM BLOG WHERE ID = #{id}
</select>
<select id="selectAuthor" resultType="Author">
SELECT * FROM AUTHOR WHERE ID = #{id}
</select>
就是这么简单。我们有两个 select 查询语句:一个用来加载博客(Blog),另外一个用来加载作者(Author),而且博客的结果映射描述了应该使用 selectAuthor 语句加载它的 author 属性。
3.2 关联的嵌套结果映射
| 属性 | 描述 |
|---|---|
resultMap | 结果映射的 ID,可以将此关联的嵌套结果集映射到一个合适的对象树中。 |
columnPrefix | 当连接多个表时,你可能会不得不使用列别名来避免在 ResultSet 中产生重复的列名。 |
notNullColumn | 默认情况下,在至少一个被映射到属性的列不为空时,子对象才会被创建。 你可以在这个属性上指定非空的列来改变默认行为,指定后,Mybatis 将只在这些列非空时才创建一个子对象。可以使用逗号分隔来指定多个列。默认值:未设置(unset)。 |
autoMapping | 如果设置这个属性,MyBatis 将会为本结果映射开启或者关闭自动映射。 这个属性会覆盖全局的属性 autoMappingBehavior。注意,本属性对外部的结果映射无效,所以不能搭配 select 或 resultMap 元素使用。默认值:未设置(unset)。 |
<select id="selectBlog" resultMap="blogResult">
select
B.id as blog_id,
B.title as blog_title,
B.author_id as blog_author_id,
A.id as author_id,
A.username as author_username,
A.password as author_password,
A.email as author_email,
A.bio as author_bio
from Blog B left outer join Author A on B.author_id = A.id
where B.id = #{id}
</select>
<resultMap id="blogResult" type="Blog">
<id property="id" column="blog_id" />
<result property="title" column="blog_title"/>
<association property="author" column="blog_author_id" javaType="Author" resultMap="authorResult"/>
</resultMap>
<resultMap id="authorResult" type="Author">
<id property="id" column="author_id"/>
<result property="username" column="author_username"/>
<result property="password" column="author_password"/>
<result property="email" column="author_email"/>
<result property="bio" column="author_bio"/>
</resultMap>
<!--和上面的方式是等效的,上面的方式可以复用-->
<resultMap id="blogResult" type="Blog">
<id property="id" column="blog_id" />
<result property="title" column="blog_title"/>
<association property="author" javaType="Author">
<id property="id" column="author_id"/>
<result property="username" column="author_username"/>
<result property="password" column="author_password"/>
<result property="email" column="author_email"/>
<result property="bio" column="author_bio"/>
</association>
</resultMap>
==非常重要: id 元素在嵌套结果映射中扮演着非常重要的角色。你应该总是指定一个或多个可以唯一标识结果的属性。 虽然,即使不指定这个属性,MyBatis 仍然可以工作,但是会产生严重的性能问题。 只需要指定可以唯一标识结果的最少属性。显然,你可以选择主键(复合主键也可以)。==
4、集合
集合元素和关联元素几乎是一样的,但是有些也是不一样的
ofType属性:用来指定集合中的元素都是什么类型的
4.1 集合的嵌套select查询
案例:一个博客中有多篇文章
private List<Post> posts;
<resultMap id="blogResult" type="Blog">
<collection property="posts" javaType="ArrayList" column="id" ofType="Post" select="selectPostsForBlog"/>
</resultMap>
<select id="selectBlog" resultMap="blogResult">
SELECT * FROM BLOG WHERE ID = #{id}
</select>
<select id="selectPostsForBlog" resultType="Post">
SELECT * FROM POST WHERE BLOG_ID = #{id}
</select>
一般情况下,mybatis可以推断javaType的属性,因此可以忽略
<collection property="posts" column="id" ofType="Post" select="selectPostsForBlog"/>
4.2 集合的嵌套结果映射
还是刚才的案例,集合的嵌套结果映射和关联是一样的
<select id="selectBlog" resultMap="blogResult">
select
B.id as blog_id,
B.title as blog_title,
B.author_id as blog_author_id,
P.id as post_id,
P.subject as post_subject,
P.body as post_body,
from Blog B
left outer join Post P on B.id = P.blog_id
where B.id = #{id}
</select>
<resultMap id="blogResult" type="Blog">
<id property="id" column="blog_id" />
<result property="title" column="blog_title"/>
<collection property="posts" ofType="Post">
<id property="id" column="post_id"/>
<result property="subject" column="post_subject"/>
<result property="body" column="post_body"/>
</collection>
</resultMap>
<!--复用形式-->
<resultMap id="blogResult" type="Blog">
<id property="id" column="blog_id" />
<result property="title" column="blog_title"/>
<collection property="posts" ofType="Post" resultMap="blogPostResult" columnPrefix="post_"/>
</resultMap>
<resultMap id="blogPostResult" type="Post">
<id property="id" column="id"/>
<result property="subject" column="subject"/>
<result property="body" column="body"/>
</resultMap>
3.3 集合的多结果集
5 自动映射
通常数据库列使用大写字母组成的单词命名,单词间用下划线分隔;而 Java 属性一般遵循驼峰命名法约定。为了在这两种命名方式之间启用自动映射,需要将 mapUnderscoreToCamelCase 设置为 true。
有三种自动映射等级:
NONE- 禁用自动映射。仅对手动映射的属性进行映射。PARTIAL- 对除在内部定义了嵌套结果映射(也就是连接的属性)以外的属性进行映射FULL- 自动映射所有属性(谨慎使用)。
默认是PARTIAL
<select id="selectUsers" resultMap="userResultMap">
select
user_id as "id",
user_name as "userName",
hashed_password
from some_table
where id = #{id}
</select>
<!--使用自动映射-->
<resultMap id="userResultMap" type="User">
<result property="password" column="hashed_password"/>
</resultMap>
动态SQL
==什么是动态SQL:动态SQL指的是根据不同的查询条件 , 生成不同的Sql语句,就是sql语句拼接==
作用:如果你使用过 JDBC 或其它类似的框架,你应该能理解根据不同条件拼接 SQL 语句有多痛苦,例如拼接时要确保不能忘记添加必要的空格,还要注意去掉列表最后一个列名的逗号。利用动态 SQL,可以彻底摆脱这种痛苦。
如果你之前用过 JSTL 或任何基于类 XML 语言的文本处理器,你对动态 SQL 元素可能会感觉似曾相识。在 MyBatis 之前的版本中,需要花时间了解大量的元素。借助功能强大的基于 OGNL 的表达式,MyBatis 3 替换了之前的大部分元素,大大精简了元素种类,现在要学习的元素种类比原来的一半还要少。
- if
- choose (when, otherwise)
- trim (where, set)
- foreach
搭建环境
CREATE TABLE `blog` (
`id` VARCHAR(50) NOT NULL COMMENT '博客id',
`title` VARCHAR(100) NOT NULL COMMENT '博客标题',
`author` VARCHAR(30) NOT NULL COMMENT '博客作者',
`create_time` DATETIME NOT NULL COMMENT '创建时间',
`views` INT(30) NOT NULL COMMENT '浏览量'
) ENGINE=INNODB DEFAULT CHARSET=utf8
实体类
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Blog {
private Integer id;
private String title;
private String author;
private Date createTime;
private Integer views;
}
接口
public interface BlogMapper {
}
mybatis-config.xml配置文件
<mappers>
<!--mapper地址-->
<mapper class="com.xiaozhi.dao.BlogMapper"/>
</mappers>
IF标签
说明:类似java中的if语句
1、BlogMapper接口添加
// 查询数据
List<Blog> selectBlog(Map map);
2、编写BlogMapper.xml文件
<!--查询数据-->
<select id="selectBlog" parameterType="map" resultType="blog">
select * from blog where 1 = 1
<if test="title != null">
AND title = #{title}
</if>
<if test="author != null">
AND author = #{author}
</if>
</select>
3、测试
trim (where, set)
说明:在if语句的列子中我们可以看到where后面跟着的是 1 = 1,这种写法是错误的,我们可以使用where标签来代替我们的where关键字
where标签的使用
我们可以直接写我们的SQL语句,不用在后面加where关键字,where它会帮我们判断,如果标签中有条件匹配的它会自动给我们加上where关键字,第一个判断的不用加AND或OR关键字,只需要写上接在where关键字后面的内容就可以了,如果第一个没有被匹配到,那么往后的匹配到了它就会自动帮我们删除AND或OR关键字,然后加上where关键字
注意:除了第一个之外不用加关键字,往后都要加
代码实现
<!--查询数据-->
<select id="selectBlog" parameterType="map" resultType="blog">
select * from blog
<where>
<if test="title != null">
title = #{title}
</if>
<if test="author != null">
AND author = #{author}
</if>
</where>
</select>
set标签的使用
在进行修改语句的时候我们都会在字段后面加逗号将每个字段隔开,如果我们按平常的语句来进行拼接,那么最后一个字段后面就会有逗号,这个时候就会导致SQL语句出问题,因此我们可以用set标签来解决这个问题,它可以进行加set关键字和删除逗号的操作
代码实现
<!--更新数据-->
<update id="updateBlog" parameterType="map">
update blog
<set>
<if test="title != null">
title = #{title},
</if>
<if test="author != null">
author = #{author},
</if>
</set>
where id = #{id}
</update>
trim标签的使用
==是where标签和set标签的老大,它负责来定制他们两个==
这是官网中的两个例子,我们可以看到它可以定制where的前缀和定义set标签的后缀,根据需求来定制
<trim prefix="WHERE" prefixOverrides="AND |OR ">
...
</trim>
<trim prefix="SET" suffixOverrides=",">
...
</trim>
sql片段
==作用:将公共部分独立出来,需要的时候就引用,重复的代码不用多次写,便利==
- id属性:sql片段的名字
- include标签:将sql片段引入到sql语句中
代码实现
<sql id="public">
<if test="title != null">
title = #{title}
</if>
<if test="author != null">
AND author = #{author}
</if>
</sql>
<!--查询数据-->
<select id="selectBlog" parameterType="map" resultType="blog">
select * from blog
<where>
<include refid="public"></include>
</where>
</select>
<!--更新数据-->
<update id="updateBlog" parameterType="map">
update blog
<set>
<include refid="public"></include>
</set>
where id = #{id}
</update>
choose (when, otherwise)标签
==说明:类似java中的switch语句,它只能选择其中一个进行sql语句拼接,同时还要注意它的结果和传参数的顺序是没有关系的。==
代码实现
1、添加方法
// 根据不同值查询结果
List<Blog> selectBlogChoose (Map map);
2、编写xml文件
<select id="selectBlogChoose" parameterType="map" resultType="blog">
select * from blog
<where>
<choose>
<when test="author != null">
author = #{author}
</when>
<when test="title != null">
and title = #{title}
</when>
</choose>
</where>
</select>
3、测试
@Test
public void Test3(){
SqlSession session = MybatisUtils.getSession();
BlogMapper mapper = session.getMapper(BlogMapper.class);
Map map = new HashMap();
map.put("title","我的世界");
map.put("author","小智");
List<Blog> blogs = mapper.selectBlogChoose(map);
for (Blog blog : blogs) {
System.out.println(blog);
}
session.close();
}
foreach
==说明:类似java中的for循环==
只能进行集合的遍历,其他的不可以
- collection属性:取出放在集合中的集合
- item:接收元素的变量
- open:开始
- close:结束
- separator:以什么字段分隔
- foreach标签里面的语句就是open和close之间的拼接的sql语句
说明:集合中有多少个值它就会取多少个值进行拼接
代码实现
1、编写接口
List<Blog> selectBlogForEach(Map map);
2、编写xml文件
<!--查找多个条件的信息-->
<!--
SELECT * FROM blog WHERE (author = '霍金' OR author = '小智' OR author = '花花公子');
在map里面放入一个List集合存放信息,然后对这个集合进行遍历
-->
<select id="selectBlogForEach" parameterType="map" resultType="blog">
SELECT * FROM blog
<where>
<foreach collection="list" item="item" open="(" close=")" separator="or">
author = #{item}
</foreach>
</where>
</select>
3、测试
@Test
public void Test5(){
SqlSession session = MybatisUtils.getSession();
BlogMapper mapper = session.getMapper(BlogMapper.class);
HashMap map = new HashMap();
ArrayList<String> list = new ArrayList<>();
list.add("小智");
list.add("花花公子");
list.add("霍金");
map.put("list",list);
mapper.selectBlogForEach(map);
session.close();
}
最终的结果

缓存
一级缓存
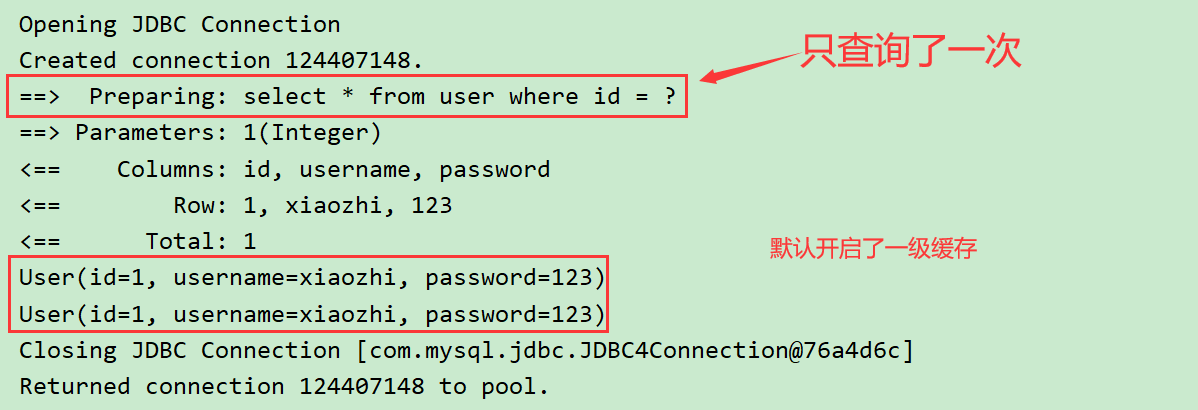
一级缓存是SqlSession级别的,通过同一个SqlSession查询的数据会被缓存,下次查询相同的数据,就 会从缓存中直接获取,不会从数据库重新访问 使一级缓存失效的四种情况:
- 不同的SqlSession对应不同的一级缓存
- 同一个SqlSession但是查询条件不同
- 同一个SqlSession两次查询期间执行了任何一次增删改操作
- 同一个SqlSession两次查询期间手动清空了缓存
代码示例
1、创建一个实体类
@Data
@NoArgsConstructor
@AllArgsConstructor
public class User implements Serializable {
private Integer id;
private String username;
private String password;
}
2、创建一个Mapper接口
// 根据id查询用户
User selectUserById(@Param("id") int id);
3、编写对应的xml文件
<select id="selectUserById" resultType="user">
select * from user where id = #{id}
</select>
4、测试
@Test
public void Test1(){
SqlSession session = MybatisUtils.getSession();
UserMapper mapper = session.getMapper(UserMapper.class);
User user1 = mapper.selectUserById(1);
System.out.println(user1);
User user2 = mapper.selectUserById(1);
System.out.println(user2);
session.close();
}
结果显示
二级缓存
可以这样写
<cache/>
也可以给它增加参数值
<cache
eviction="FIFO"
flushInterval="60000"
size="512"
readOnly="true"/>
这个更高级的配置创建了一个 FIFO 缓存,每隔 60 秒刷新,最多可以存储结果对象或列表的 512 个引用,而且返回的对象被认为是只读的,因此对它们进行修改可能会在不同线程中的调用者产生冲突。
==注意:在没有策略的时候,需要对实体类进行序列化==
可用的清除策略有:
LRU– 最近最少使用:移除最长时间不被使用的对象。FIFO– 先进先出:按对象进入缓存的顺序来移除它们。SOFT– 软引用:基于垃圾回收器状态和软引用规则移除对象。WEAK– 弱引用:更积极地基于垃圾收集器状态和弱引用规则移除对象。
默认的清除策略是 LRU。
flushInterval(刷新间隔)属性可以被设置为任意的正整数,设置的值应该是一个以毫秒为单位的合理时间量。 默认情况是不设置,也就是没有刷新间隔,缓存仅仅会在调用语句时刷新。
size(引用数目)属性可以被设置为任意正整数,要注意欲缓存对象的大小和运行环境中可用的内存资源。默认值是 1024。
readOnly(只读)属性可以被设置为 true 或 false。只读的缓存会给所有调用者返回缓存对象的相同实例。 因此这些对象不能被修改。这就提供了可观的性能提升。而可读写的缓存会(通过序列化)返回缓存对象的拷贝。 速度上会慢一些,但是更安全,因此默认值是 false。
提示 二级缓存是事务性的。这意味着,当 SqlSession 完成并提交时,或是完成并回滚,但没有执行 flushCache=true 的 insert/delete/update 语句时,缓存会获得更新。
代码实现
1、在mybatis-config.xml文件中显示出来开启了,二级缓存的默认值是true,显示出来增加可读性
<settings>
<setting name="cacheEnabled" value="true"/>
</settings>
2、在mapper对应的xml文件中添加cache标签
<mapper namespace="com.xiaozhi.dao.UserMapper">
<cache/>
<select id="selectUserById" resultType="user">
select * from user where id = #{id}
</select>
</mapper>
3、测试
// 二级缓存
@Test
public void Test2(){
SqlSession session = MybatisUtils.getSession();
SqlSession session2 = MybatisUtils.getSession();
UserMapper mapper1 = session.getMapper(UserMapper.class);
UserMapper mapper2 = session2.getMapper(UserMapper.class);
User user = mapper1.selectUserById(1);
System.out.println(user);
session.close();
User user2 = mapper2.selectUserById(1);
System.out.println(user2);
session2.close();
}
结果显示
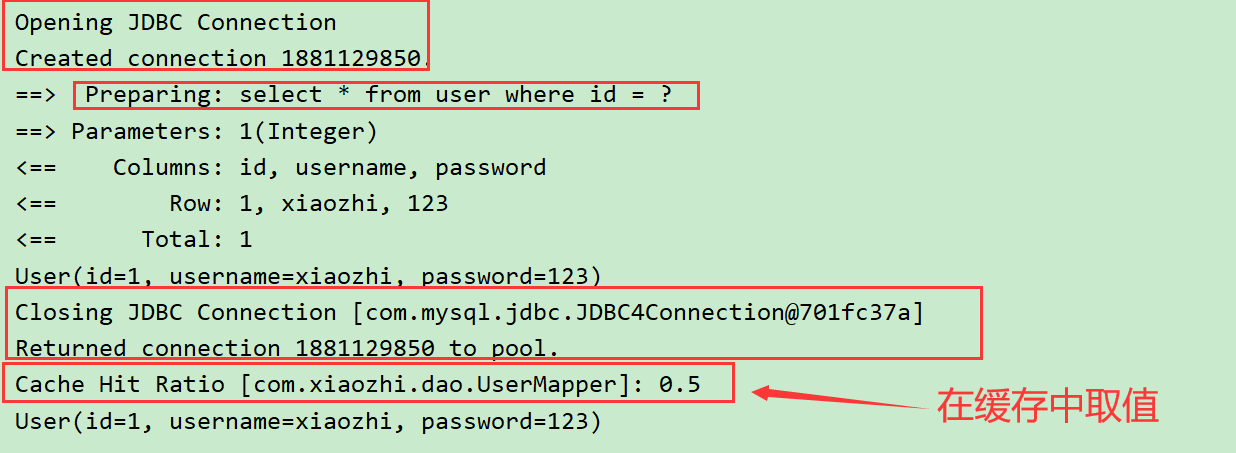
说明:我们可以看到第二次查询的时候它是和缓存交互的,并没有到数据库中查询
缓存执行流程图
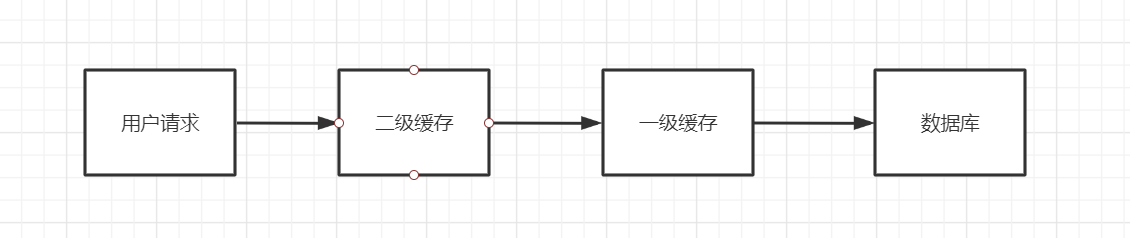
==说明:用户请求过来先去查找二级缓存有没有数据,有的话就返回,没有的话就往一级缓存找,有就返回,没有就到数据库中查询==
自定义缓存EhCache
EhCache 是一个纯Java的进程内缓存框架,具有快速、精干等特点,是Hibernate中默认的CacheProvider。
Ehcache是一种广泛使用的开源Java分布式缓存。主要面向通用缓存,Java EE和轻量级容器。它具有内存和磁盘存储,缓存加载器,缓存扩展,缓存异常处理程序,一个gzip缓存servlet过滤器,支持REST和SOAP api等特点。
实现:cache标签中的type属性中指定自定义的缓存实现类
1、导入依赖
<!-- https://mvnrepository.com/artifact/org.mybatis.caches/mybatis-ehcache -->
<dependency>
<groupId>org.mybatis.caches</groupId>
<artifactId>mybatis-ehcache</artifactId>
<version>1.1.0</version>
</dependency>
2、在mapper.xml中使用对应的缓存即可
<mapper namespace="com.xiaozhi.dao.UserMapper">
<cache type = "org.mybatis.caches.ehcache.EhcacheCache" />
<select id="selectUserById" resultType="user">
select * from user where id = #{id}
</select>
</mapper>
3、编写ehcache.xml文件,如果在加载时未找到/ehcache.xml资源或出现问题,则将使用默认配置。
<?xml version="1.0" encoding="UTF-8"?>
<ehcache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="http://ehcache.org/ehcache.xsd"
updateCheck="false">
<!--
diskStore:为缓存路径,ehcache分为内存和磁盘两级,此属性定义磁盘的缓存位置。参数解释如下:
user.home – 用户主目录
user.dir – 用户当前工作目录
java.io.tmpdir – 默认临时文件路径
-->
<diskStore path="./tmpdir/Tmp_EhCache"/>
<defaultCache
eternal="false"
maxElementsInMemory="10000"
overflowToDisk="false"
diskPersistent="false"
timeToIdleSeconds="1800"
timeToLiveSeconds="259200"
memoryStoreEvictionPolicy="LRU"/>
<cache
name="cloud_user"
eternal="false"
maxElementsInMemory="5000"
overflowToDisk="false"
diskPersistent="false"
timeToIdleSeconds="1800"
timeToLiveSeconds="1800"
memoryStoreEvictionPolicy="LRU"/>
<!--
defaultCache:默认缓存策略,当ehcache找不到定义的缓存时,则使用这个缓存策略。只能定义一个。
-->
<!--
name:缓存名称。
maxElementsInMemory:缓存最大数目
maxElementsOnDisk:硬盘最大缓存个数。
eternal:对象是否永久有效,一但设置了,timeout将不起作用。
overflowToDisk:是否保存到磁盘,当系统当机时
timeToIdleSeconds:设置对象在失效前的允许闲置时间(单位:秒)。仅当eternal=false对象不是永久有效时使用,可选属性,默认值是0,也就是可闲置时间无穷大。
timeToLiveSeconds:设置对象在失效前允许存活时间(单位:秒)。最大时间介于创建时间和失效时间之间。仅当eternal=false对象不是永久有效时使用,默认是0.,也就是对象存活时间无穷大。
diskPersistent:是否缓存虚拟机重启期数据 Whether the disk store persists between restarts of the Virtual Machine. The default value is false.
diskSpoolBufferSizeMB:这个参数设置DiskStore(磁盘缓存)的缓存区大小。默认是30MB。每个Cache都应该有自己的一个缓冲区。
diskExpiryThreadIntervalSeconds:磁盘失效线程运行时间间隔,默认是120秒。
memoryStoreEvictionPolicy:当达到maxElementsInMemory限制时,Ehcache将会根据指定的策略去清理内存。默认策略是LRU(最近最少使用)。你可以设置为FIFO(先进先出)或是LFU(较少使用)。
clearOnFlush:内存数量最大时是否清除。
memoryStoreEvictionPolicy:可选策略有:LRU(最近最少使用,默认策略)、FIFO(先进先出)、LFU(最少访问次数)。
FIFO,first in first out,这个是大家最熟的,先进先出。
LFU, Less Frequently Used,就是上面例子中使用的策略,直白一点就是讲一直以来最少被使用的。如上面所讲,缓存的元素有一个hit属性,hit值最小的将会被清出缓存。
LRU,Least Recently Used,最近最少使用的,缓存的元素有一个时间戳,当缓存容量满了,而又需要腾出地方来缓存新的元素的时候,那么现有缓存元素中时间戳离当前时间最远的元素将被清出缓存。
-->
</ehcache>
==说明:一般都是使用redis缓存数据库来进行缓存的,所以自定义缓存了解一下即可==
MyBatis逆向工程
一、环境搭建
引入依赖
<dependencies>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.7</version>
</dependency>
</dependencies>
<!-- 控制Maven在构建过程中相关配置 -->
<build>
<!-- 构建过程中用到的插件 -->
<plugins>
<!-- 具体插件,逆向工程的操作是以构建过程中插件形式出现的 -->
<plugin>
<groupId>org.mybatis.generator</groupId>
<artifactId>mybatis-generator-maven-plugin</artifactId>
<version>1.3.0</version>
<!-- 插件的依赖 -->
<dependencies>
<!-- 逆向工程的核心依赖 -->
<dependency>
<groupId>org.mybatis.generator</groupId>
<artifactId>mybatis-generator-core</artifactId>
<version>1.3.2</version>
</dependency>
<!-- 数据库连接池 -->
<dependency>
<groupId>com.mchange</groupId>
<artifactId>c3p0</artifactId>
<version>0.9.2</version>
</dependency>
<!-- MySQL驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.8</version>
</dependency>
</dependencies>
</plugin>
</plugins>
</build>
maven中就会出现

二、配置逆向工程配置文件
==必须是generatorConfig.xml==,将对应的参数修改成自定义的
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE generatorConfiguration
PUBLIC "-//mybatis.org//DTD MyBatis Generator Configuration 1.0//EN"
"http://mybatis.org/dtd/mybatis-generator-config_1_0.dtd">
<generatorConfiguration>
<!--
targetRuntime: 执行生成的逆向工程的版本
MyBatis3Simple: 生成基本的CRUD(清新简洁版)
MyBatis3: 生成带条件的CRUD(奢华尊享版)
-->
<context id="DB2Tables" targetRuntime="MyBatis3Simple">
<!-- 数据库的连接信息 -->
<jdbcConnection driverClass="com.mysql.jdbc.Driver"
connectionURL="jdbc:mysql://192.168.6.156:3306/db1"
userId="root"
password="abc123">
</jdbcConnection>
<!-- javaBean的生成策略-->
<javaModelGenerator targetPackage="com.xiaozhi.pojo"
targetProject=".\src\main\java">
<property name="enableSubPackages" value="true" />
<property name="trimStrings" value="true" />
</javaModelGenerator>
<!-- SQL映射文件的生成策略 -->
<sqlMapGenerator targetPackage="com.xiaozhi.mapper"
targetProject=".\src\main\resources">
<property name="enableSubPackages" value="true" />
</sqlMapGenerator>
<!-- Mapper接口的生成策略 -->
<javaClientGenerator type="XMLMAPPER"
targetPackage="com.xiaozhi.mapper" targetProject=".\src\main\java">
<property name="enableSubPackages" value="true" />
</javaClientGenerator>
<!-- 逆向分析的表 -->
<!-- tableName设置为*号,可以对应所有表,此时不写domainObjectName -->
<!-- domainObjectName属性指定生成出来的实体类的类名 -->
<table tableName="t_user" domainObjectName="User"/>
<table tableName="teacher" domainObjectName="Teacher"/>
<table tableName="student" domainObjectName="Student"/>
</context>
</generatorConfiguration>
最后,运行插件,就可以生成对应的文件了
有两个版本:
- 简单版本(简单的增删改查),
targetRuntime="MyBatis3Simple" - 全面版本(推荐使用),
targetRuntime="MyBatis3",它包含了简单版本的
三、逆向生成的使用
这里主要讲一下全面版本的
- 比简单版本多出一个类,带后缀为Example,在这里我把它叫做增强类
- 简单的增删改查用普通类就好了,复杂的操作用增强类
- 可以根据条件进行查询,可以做复杂的查询
代码演示
@Test
public void Test01(){
SqlSession session = MybatisUtils.getSession();
UserMapper mapper = session.getMapper(UserMapper.class);
// 没有条件就是查询全部
/* List<User> users = mapper.selectByExample(null);
users.forEach(System.out::println);*/
// 有条件情况
UserExample userExample = new UserExample();
// 查询名字等于a的和年龄大于等于2的
// 通过userExample.createCriteria()创建Criteria对象来进行操作
userExample.createCriteria().andNameEqualTo("b")
.andAgeGreaterThanOrEqualTo(2);
List<User> users = mapper.selectByExample(userExample);
users.forEach(System.out::println);
}
{
"graphs": [
{
"graphId": "1",
"compositeRequest": [
{
"url": "/services/data/v50.0/sobjects/Account",
"body": {
"Id": null,
"CLS_ID__c": "6729f1856c551f6d7f656067",
"RecordTypeId": "012D000000039wUIAQ",
"Tencent_Union_ID__c": null,
"PersonLeadSource": null,
"Customer_Segment__c": null,
"Salutation": "Mr.",
"PersonTitle": "1",
"Gender__c": null,
"LastName": "京东渠道",
"FirstName": " 陈",
"Nickname__c": null,
"International_LastName__pc": null,
"International_FirstName__pc": null,
"PersonBirthdate": null,
"Wedding_Anniversary_Date__pc": null,
"Recommender__c": null,
"Watches__c": false,
"Jewelry__c": false,
"Ladies_Watches__c": false,
"Mechanical_Watches__c": false,
"High_Jewelry__c": false,
"Sport_Watches__c": false,
"Accessories__c": false,
"BRIDAL_Jewellery__c": false,
"PersonMobilePhone": "12222222222",
"Phone": null,
"WeChatID__c": null,
"PersonEmail": null,
"Preferred_Communication__pc": null,
"Preferred_language__c": null,
"Consent_Warranty_Extension__c": false,
"is_weChat_visible__c": true,
"Primary_Boutique__c": "001FS00000DrmyXYAR",
"Permission_to_Contact__c": "No",
"Description": null
},
"method": "POST",
"referenceId": "add_main"
},
{
"url": "/services/data/v50.0/sobjects/Address__c",
"body": [
{
"AccountId__c": "@{add_main.id}",
"LocalAddress1__c": "广东省",
"LocalAddress2__c": "深圳市",
"LocalAddress3__c": "龙岗区 深圳大学1号",
"LocalPostalCode__c": "518000",
"LocalCountry__c": "CN"
},
{
"AccountId__c": "@{add_main.id}",
"LocalAddress1__c": "广东省",
"LocalAddress2__c": "深圳市",
"LocalAddress3__c": "龙岗区 深圳大学1号",
"LocalPostalCode__c": "518000",
"LocalCountry__c": "CN"
}
],
"method": "POST",
"referenceId": "1"
},
{
"url": "/services/data/v50.0/sobjects/Account/@{add_main.id}",
"body": {
"OwnerId": "00557000007KkknAAC"
},
"method": "PATCH",
"referenceId": "update_ownerid"
}
]
}
]
}
