

为什么很多 Agent 在 Demo 阶段惊艳,一上线就失效?
不是模型的问题,而是它忘得太快。
没有记忆,AI 无法理解上下文、无法积累知识,更无法形成真正的个性。
memU 的出现就是补全这块缺失的基础设施,让 AI 不再只是“即时反应”,而是能不断学习、进化,成为真正长期可依赖的伙伴。
但是企业和开发者若想为 AI 应用添加长期记忆能力,往往面临开发难度大、实现复杂、周期长的挑战。为了解决这个问题,memU 正式上线 Response API 🚀
它不仅让你的 AI 快速拥有长期记忆,更能轻松集成各类 LLMs,无论是 GPT、DeepSeek、Gemini、Qwen 还是其他模型,都能一行代码接入,避免复杂开发。

更易用的企业级长记忆 API
对于正在构建下一代 Agent 应用的团队而言,实现可用的长期记忆系统远非简单的数据持久化——它需要解决记忆的管理与关联、动态检索、相关性衰减、多会话融合等一系列复杂问题。
这些底层挑战不仅消耗大量工程资源,更会分散团队对核心业务逻辑的专注。memU Response API 将这套复杂系统封装为一次简单调用,打造了全球首个将响应生成与记忆管理合二为一的统一接口,让你无需成为记忆架构专家,不用改动任何现有架构,也能为应用注入稳定可靠的长期记忆能力——把时间还给创新,让记忆成为基础设施。
一次调用 = 响应 + 记忆。
无需手动内存管理: 无需调用 retrieve_memory 或 memorize_conversation
自动上下文处理: 系统智能管理对话上下文
简化集成: 单一 API 调用即可实现完整的对话式 AI
通过 memU Response API 可以快速实现 memU 的核心记忆能力:
文件化记忆管理:所有交互由 Memory Agent 自动索引、分类并转为结构化记忆,无需预设 Schema 或记忆槽位。
关联与知识图谱:系统将每段记忆视为知识节点,自动构建跨模态、跨时间的“经验网络”,支持检索与遍历。
自我反思与进化:后台自动分析、合并冗余记忆,总结主题、填补知识空白,推理隐含关联,实现记忆持续优化。
上下文保留与遗忘:根据使用频率与场景动态调整记忆优先级,实现自适应记忆保留与有序遗忘,避免信息过载。

更多场景支持
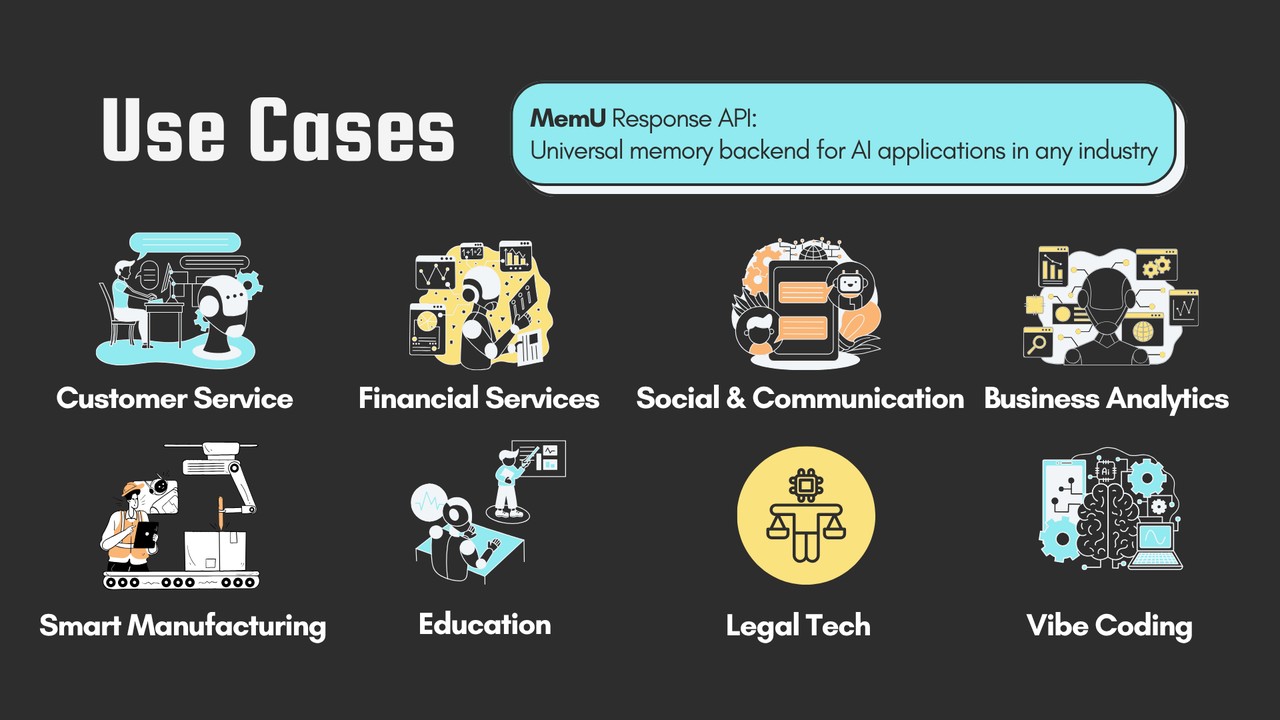
在企业、陪伴型 Agent、语音助手、医疗、法律咨询、销售管理、车载与智能家居助手等不同应用场景中,AI 系统普遍面临长期记忆需求:需要在多轮交互中保持上下文一致,积累用户偏好或历史数据,并能够随时间演化形成有价值的知识沉淀。
然而,这类能力的实现通常伴随高开发成本和技术复杂度——开发者必须手动管理上下文、设计存储和检索逻辑、处理数据清洗与结构化问题,且不同大模型和平台之间缺乏统一接口,使得构建可扩展、跨场景的长期记忆功能变得困难。
memU Response API 将响应生成与记忆管理合并为单一调用,提供统一、可插拔的长记忆层,降低开发复杂度。通过这一 API,AI 可以自动管理上下文、存储与检索历史信息,无需额外架构改动或手工处理。无论是企业级 Agent 的知识库建设、陪伴型或语音助手的个性化交互、医疗与法律 AI 的历史信息管理,还是销售 AI 的客户信息沉淀,memU Response API 都能够快速赋予 AI 系统长期记忆能力,使其从单次响应工具演化为可持续学习与积累的智能系统。
MemU Response API 在多个行业中展现价值:
📞 客户服务:AI 或人工客服可即时访问完整交互记录,快速理解客户偏好与历史问题。
🤖 陪伴助手:记忆用户偏好与习惯,实现连贯的个性化交互,成为长期陪伴伙伴。
🏥 医疗健康:智能助手可追踪患者交互历史,提供持续、个性化的健康指导。
💰 金融服务:顾问系统可保留客户关系上下文,生成真正个性化的理财建议。
🎓 教育领域:学习平台能根据学生进度个性化推荐学习路径,打造独特的学习旅程。
🏢 企业知识管理:内部系统随使用而不断进化,持续积累价值与洞察。
更灵活的部署方式
memU 提供托多种部署方式,无论是想要立即访问,还是私有化功能定制与部署,均可实现。
☁️ 云端部署:快速上线
🏠 本地部署:数据主权可控
🏢 企业部署:满足定制化需求
复制下方链接,快速开始
