

很多开发者都试过做语音交互的 Agent:语音识别、语音合成、再接一个大模型,就能跑起来一个能聊的 Demo。流程不复杂,效果也够炫。
但真正用起来的时候,问题很快就暴露出来了:它根本记不住东西。
-
关掉窗口,所有上下文都没了;
-
重复问一个问题,它还是会重复犯错;
-
长时间的交互更像是一条“流水账”,没有积累,也谈不上进化。
要把这种“短期记忆的对话玩具”变成一个真正能陪伴、能成长的 Agent,缺的就是记忆层。
不久前,在硅星人 x TEN Framework 开发者 x memU 联合主办的「对话式 AI Workshop|零帧起手捏个 Her」Workshop 专场中,AI 开源记忆框架 memU 和 TEN Framework 的核心开发者和大家一起,从框架介绍到实操指引,帮助开发者现场动手体验:在一台笔记本上也能跑起来的语音对话 + 长期记忆 AI Agent。
-
MemU 提供长期记忆,让 Agent 能够持续理解和延续上下文;
-
TEN Framework 负责低延时、可打断的语音对话。
为什么需要优化 Agent 记忆?
当下,应用市场正从传统架构转向 Agent-native 应用。传统应用需要前端、后端和算法共同驱动。但在 Agent-native 应用里,前端可以很轻量,核心功能也可以交给 Agent 来实现。此时,真正缺失的一环,往往是记忆层。Agent 记忆便是要从复杂数据中抽取对业务场景有价值的信息。
在对话式 AI 或 Agent 系统中,理想的记忆功能并不是简单地“保存上下文”,而是能让 Agent **不断改进、逐步进化。**实际对话中,用户与 Agent 的交互会不断产生运行日志。记忆的核心作用就是从这些日志里提炼信息,帮助 Agent 在下一次对话、任务中做得更好。
什么是 Agentic memroy + File System?
过去两年里,随着 LLM 和 Agent 技术的快速发展,业界也出现了多个记忆增强的方案。以往最常见的做法是总结用户和 Agent 的对话,再存储成一条条“备忘”,在需要时通过向量检索把相关记忆取回。但缺点也明显:检索不够精准,跨场景泛化差,效果大多停留在“能用,但不够好”的层面。
今年业界出现了新的方向——Agentic Memory。它的核心理念是:把记忆本身设计成一个独立的 Agent,而不是附属于主 Agent 的一个附加模块;同时通过多 Agent 协作,让记忆具备更细致的存储、分类、检索和推理能力。
但是单有 Agentic 的概念,还无法解决 RAG 存储与检索不够精确、信息碎片化等问题。
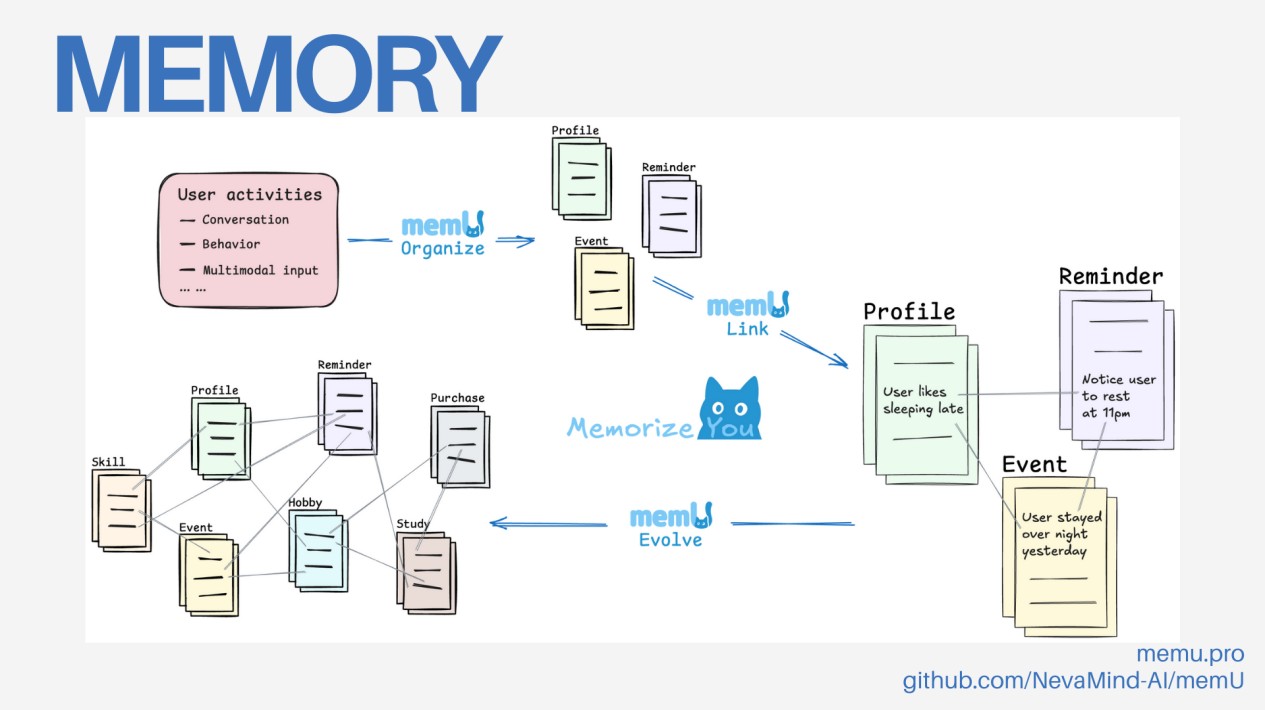
在 memU 的设计里,把 Agentic Memory 进一步扩展成一个**文件夹系统 File System,**从而实现记忆更加精准的效果:
-
当用户和环境交互产生数据时,记忆 Agent 会主动分类和整理,把内容分门别类地存入不同“文件夹”;
-
相似的记忆文件夹会自动建立关联,就像 Wikipedia 条目里的超链接一样,方便追溯和扩展;
-
查询时,不只是简单匹配,而是能从主档案(profile)逐层跳转到细化的事件页面,支持更深度的记忆检索;
-
基于已有记忆,系统可以生成新的推测性信息,并把这些结果也归档,以便未来调用。
换句话说,**传统记忆像一本笔记本,写下摘要然后翻找。**而 memU 的 **Agentic Memory + File System 设计更像一个带有索引和超链接的知识库 Wikipedia:**有主页面(profile),也有大量带超链接的子页面,既能快速索引,又能深入检索,还能不断扩展新的条目。
这也是 memU 的重点探索方向:为 Agent 提供的不仅仅是“上下文回溯”,而是一个可进化的记忆层,让语音 AI 逐步学会“理解、归档、联想、反思”。
如何在对话系统中使用 memU?
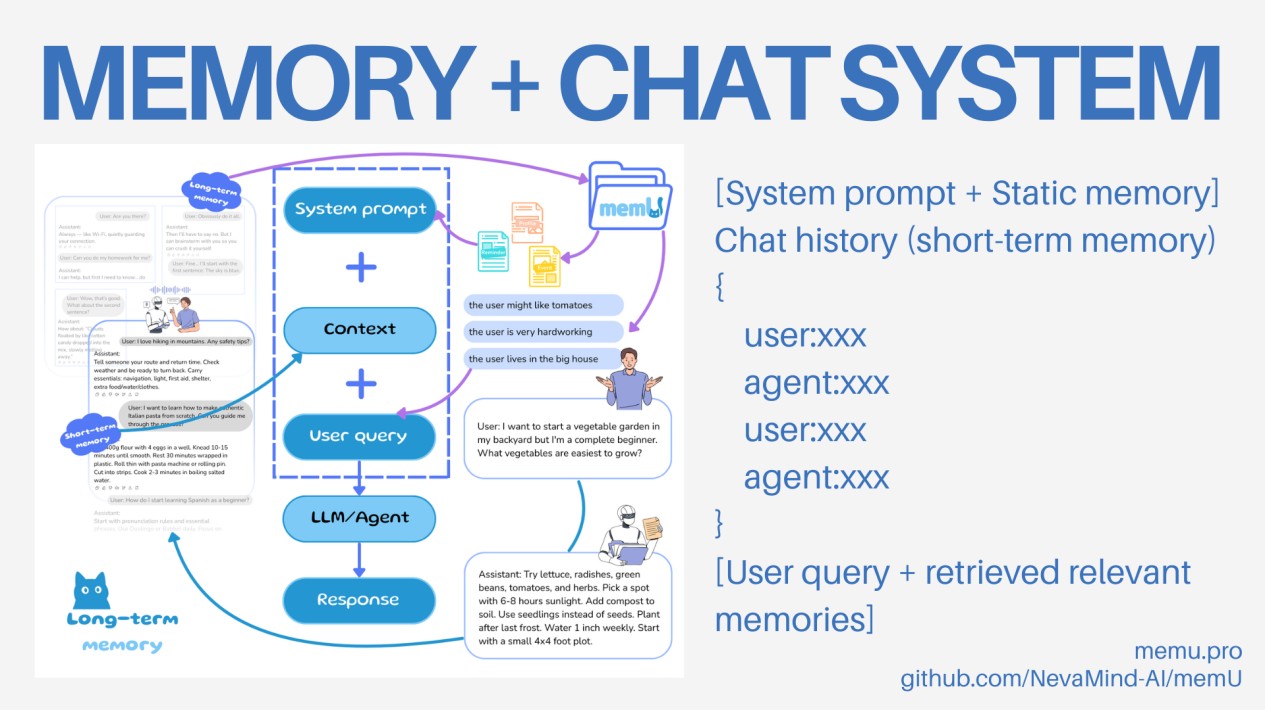
一个传统的 Chat System工作流主要有 3 个步骤,可以实现短期对话的记忆存储:
- 系统通常会有一个 system prompt;
- 短期记忆(short-term memory,例如最近几轮对话)会放在上下文中;
- 每一轮新的交互就是「用户 query → Agent response」的循环。
那么,长期记忆应该如何嵌入其中?
在 memU 的设计里。Static Memory 可以直接放入 system prompt。比如人与人之间刚认识时,会对对方形成一个大致的印象,这些**“核心信息”长期保留**。好处是模型在后续的对话中不需要反复重新计算这些基础内容,能保证对话的稳定性和一致性。
此外每当有新的用户 query,系统会触发一次检索,从 memU 的记忆库里找到与当前问题最相关的内容。检索方式可以有两种:
- 相似度搜索(similarity search):通过 embedding 检索,快速找出语义上最接近的历史对话;
- 图谱式深度检索(graph-based deep research):通过记忆之间的链接关系,进行更深入的关联与推理,拿到更准确的结果。
最终这个工作流就能保证:
- 静态信息始终保持在对话上下文中;
- 动态信息能随时按需提取。
这样 Agent 不仅能保持“对用户的长期印象”,还能在具体问题上调用过往的经验,从而让对话更连贯、更智能。
快速开始
目前,memU 特别适合被用在一些需要长期记忆的场景,比如:
-
陪伴类 Agent:记住用户的习惯和心情,提供更个性化的互动;
-
硬件语音助手:让设备能“记得住”家庭环境和使用偏好;
-
医疗与工具场景:帮助 Agent 追踪长期任务、持续积累知识。
memU 也提供了一个开箱即用的界面,开发者可以很快地搭建起带有长期记忆的语音或是其他功能的 Agent,直接验证这些能力在自己项目中的效果。
