

损失函数(Loss Function)
- 损失函数:它用于量化单样本预测值与真实值之间的差异,记为, 是第 i 个样本的真实值, 是模型对第 i 个样本的预测值,w 表示模型的参数。
成本函数(Cost Function)/经验风险函数(Risk Function)
- 成本函数就是全部训练样本损失函数的平均值。
- 风险函数(经验风险),是从模型泛化推测能力角度解释,计算公式与成本函数相同
其中,N 是训练样本的数量,L 是损失函数。
-
作用:评价模型,指导训练
- 成本函数用于评估预测值和真实值的差距,成本函数越小,模型越精准
-
局限性:仅仅最小化经验风险可能会导致模型过拟合(Overfitting)。 为了提高模型的泛化能力(即模型在新数据上的表现),我们通常会在经验风险的基础上引入正则化项,得到结构风险(Structural Risk),并通过最小化结构风险来训练模型。
常见损失函数
回归损失函数
用于连续值回归训练和预测
均方误差(MSE, Mean Squared Error)
-
算法:计算预测值与真实值差值的平方的平均值。
-
公式: ,为真实值,\hat{y}_i$为预测值,n为样本数)
-
特点:对异常值敏感(平方会放大偏差)
-
场景: 适合数据无明显异常、追求预测精度的场景(如房价预测、销售额预测,SBERT中预测句子对的相似性分数)。
平均绝对误差(MAE, Mean Absolute Error)
-
算法:计算预测值与真实值差值的绝对值的平均值。
-
公式:
-
特点:对异常值鲁棒(无平方放大),但导数不连续(在0点不可导,可能影响优化效率)
-
场景:适合数据存在较多异常值的场景(如预测受极端天气影响的销量)。
Huber损失
- 算法:结合MSE和MAE的优点,误差小时用MSE(优化更平滑),误差大时用MAE(避免异常值干扰),是兼顾精度与鲁棒性的折中选择。
- 公式:结合MSE和MAE,当误差时用MSE,否则用MAE(为超参数)
- 特点:平衡了对异常值的鲁棒性和优化效率,适用于希望兼顾误差平滑性与抗干扰能力的场景,如金融风险预
交叉熵损失函数
在统计学习理论中,经验风险和结构风险是两个核心概念,用于衡量模型在训练过程中的表现,并指导模型的优化方向。 表现,并指导模型的优化方向。
结构风险与正则项
-
背景:成本函数(经验风险)在样本量不足时易过拟合
-
解决方法: 结构风险是在成本函数上附加正则化项(也叫惩罚项)
或
正则化项J(f) 表示模型的复杂度,它是定义在假设空间上的泛函。模型越复杂,J(f) 的值就越大;反之,模型越简单,J(f) 的值就越小。复杂度项表示了对复杂模型的惩罚。
λ是正则化系数(大于0的超参数),用于权衡经验风险和模型复杂度,λ越大,正则化项在损失函数中占比越大,能控制原损失函数取值尽可能偏大,避免过拟合。
- 结构风险最小化的目标,本质是通过调整两者的权重,找到“模型拟合能力”与“模型复杂度”的最优平衡参数,以确保模型在训练数据和未知数据上都能表现良好。
L1范数正则化
- 稀疏性:L1范数即参数绝对值和,L1范数正则化倾向于将部分参数压缩为零,实现特征选择,适用于高维稀疏数据(如文本分类)。
- 解的不稳定性:在参数接近零时,梯度可能不连续,导致解不稳定。
L2范数正则化
- 平滑性:L2范数即参数平方和,L2范数正则化将参数均匀压缩,不会产生稀疏解,但能防止参数过大。
- 稳定性:梯度连续,解更稳定,适用于特征高度相关的数据。
L1与L2对比
下图以线性回归均方成本函数为例,,在图中,均方成本函数的等值线为椭圆,红色箭头为梯度下降方向;成本函数等值线与L1或L2等值线交点处即为参数取值,黑色箭头表示λ越大,参数取值越小,原成本函数越不容易过拟合。
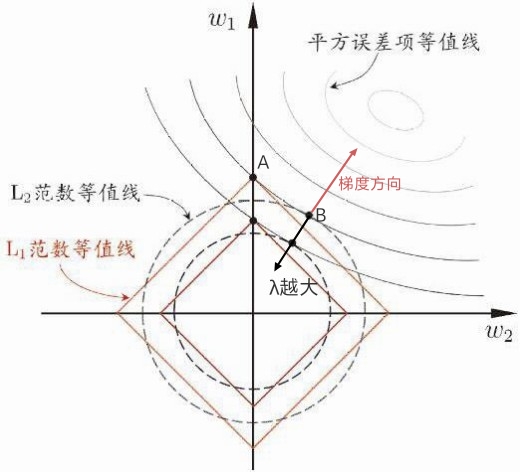
L1与L2选择方法
-
实验对比 可以分别在模型中应用 L1 和 L2 正则化,固定相同的正则项大小,然后在验证集上评估模型的性能,如准确率、均方误差等。选择在验证集上性能更优的正则化方式。例如在一个文本分类任务中,分别使用 L1 和 L2 正则化进行训练,对比验证集上的分类准确率,选择准确率更高的那种。
-
结合先验知识 根据问题的领域知识和经验来选择。如果已知某些特征之间存在较强的相关性,L2 正则化可以更好地处理这种情况;如果希望突出某些重要特征,忽略一些不重要的特征,L1 正则化可能更合适。例如在金融风险评估中,根据以往的经验知道某些指标对风险评估的影响较大,使用 L1 正则化可能有助于筛选出这些关键指标。
详细介绍可以参见Forrest老师的讲解L1正则化为什么具有稀疏性
弹性网络正则化(Elastic Net)
同时使用L1正则化和L2正则化
- 公式
特点:
- L1与L2正则结合优势:同时具备L1的特征选择和L2的稳定性,适用于特征数量多且存在多重共线性的情况。
A&Q
损失函数必须除以样本个数吗
- 不必须,是否除以样本个数不影响参数更新方向,仅对学习速率有影响
损失函数什么时候除以样本个数n,什么除以2n
有时会看到损失函数除以n或2n,除以2n后续导数计算更方便些。
如果固定正则项大小,是否还需要选择正则项类型
需要,即使固定正则项大小,仍需要调整不同参数权重,甚至稀疏某些参数
关于 L1 和 L2 正则项的决策过程
即使固定了正则项大小,也需要进行 L1 和 L2 正则项的决策:
