


🏆🏆🏆教程全知识点简介:1.机器学习常用科学计算库包括基础定位、目标。2. 人工智能概述涵盖人工智能应用场景、人工智能小案例、人工智能发展必备三要素、人工智能机器学习和深度学习。3. 机器学习概述包括机器学习工作流程、什么是机器学习、模型评估(回归模型评估、拟合)、Azure机器学习模型搭建、完整机器学习项目流程。4. 机器学习基础环境安装与使用包括Jupyter Notebook使用(一级标题、Jupyter Notebook中自动补全代码等相关功能拓展)。5. Matplotlib可视化涵盖Matplotlib HelloWorld(什么是Matplotlib、实现简单Matplotlib画图折线图、画出温度变化图、准备数据、创建画布、绘制折线图、显示图像、构造x轴刻度标签、修改坐标刻度显示、设置中文字体、设置正常显示符号、保存图片)、添加坐标轴刻度、添加网格显示、添加描述信息、图像保存、设置图形风格、常见图形绘制(常见图形种类意义、散点图绘制)。6. Numpy包括Numpy优势、N维数组ndarray(ndarray属性)、基本操作(生成数组方法、生成0和1数组、从现有数组生成、创建符合正态分布股某票涨跌幅数据)、数组间运算(数组与数的运算)。7. Pandas数据结构包括Series、DataFrame。8. 文件读取与存储涵盖CSV(read_csv)、HDF(read_hdf与to_hdf)、JSON(read_josn)。9. 高级处理数据离散化包括为什么要离散化、什么是数据离散化、股某票涨跌幅离散化(读取股某票数据、将股某票涨跌幅数据进行分组、股某票涨跌幅分组数据变成one_hot编码)、案例实现。

📚📚👉👉👉本站这篇博客: juejin.cn/post/753618… 中查看
📚📚👉👉👉本站这篇博客: juejin.cn/post/753618… 中查看
✨ 本教程项目亮点
🧠 知识体系完整:覆盖从基础原理、核心方法到高阶应用的全流程内容
💻 全技术链覆盖:完整前后端技术栈,涵盖开发必备技能
🚀 从零到实战:适合 0 基础入门到提升,循序渐进掌握核心能力
📚 丰富文档与代码示例:涵盖多种场景,可运行、可复用
🛠 工作与学习双参考:不仅适合系统化学习,更可作为日常开发中的查阅手册
🧩 模块化知识结构:按知识点分章节,便于快速定位和复习
📈 长期可用的技术积累:不止一次学习,而是能伴随工作与项目长期参考
🎯🎯🎯全教程总章节


🚀🚀🚀本篇主要内容
Pandas
学习目标
- 了解Numpy与Pandas的不同
- 说明Pandas的Series与Dataframe两种结构的区别
- 了解Pandas的MultiIndex与panel结构
- 应用Pandas实现基本数据操作
- 应用Pandas实现数据的合并
- 应用crosstab和pivot_table实现交叉表与透视表
- 应用groupby和聚合函数实现数据的分组与聚合
- 了解Pandas的plot画图功能
- 应用Pandas实现数据的读取和存储
5.1Pandas介绍
学习目标
-
目标
- 了解什么是pandas
- 了解Numpy与Pandas的不同
- 知道使用pandas的优势
1 Pandas介绍

-
2008年WesMcKinney开发出的库
-
专门用于数据挖掘的开源python库
-
以Numpy为基础,借力Numpy模块在计算方面性能高的优势
-
基于matplotlib,能够简便的画图
-
独特的数据结构
2 为什么使用Pandas
Numpy已经能够帮助 处理数据,能够结合matplotlib解决部分数据展示等问题,那么pandas学习的目的在什么地方呢?
-
增强图表可读性
-
回忆 在numpy当中创建学生成绩表样式:
-
返回结果:
-
array([[92, 55, 78, 50, 50], [71, 76, 50, 48, 96], [45, 84, 78, 51, 68], [81, 91, 56, 54, 76], [86, 66, 77, 67, 95], [46, 86, 56, 61, 99], [46, 95, 44, 46, 56], [80, 50, 45, 65, 57], [41, 93, 90, 41, 97], [65, 83, 57, 57, 40]])
如果数据展示为这样,可读性就会更友好:
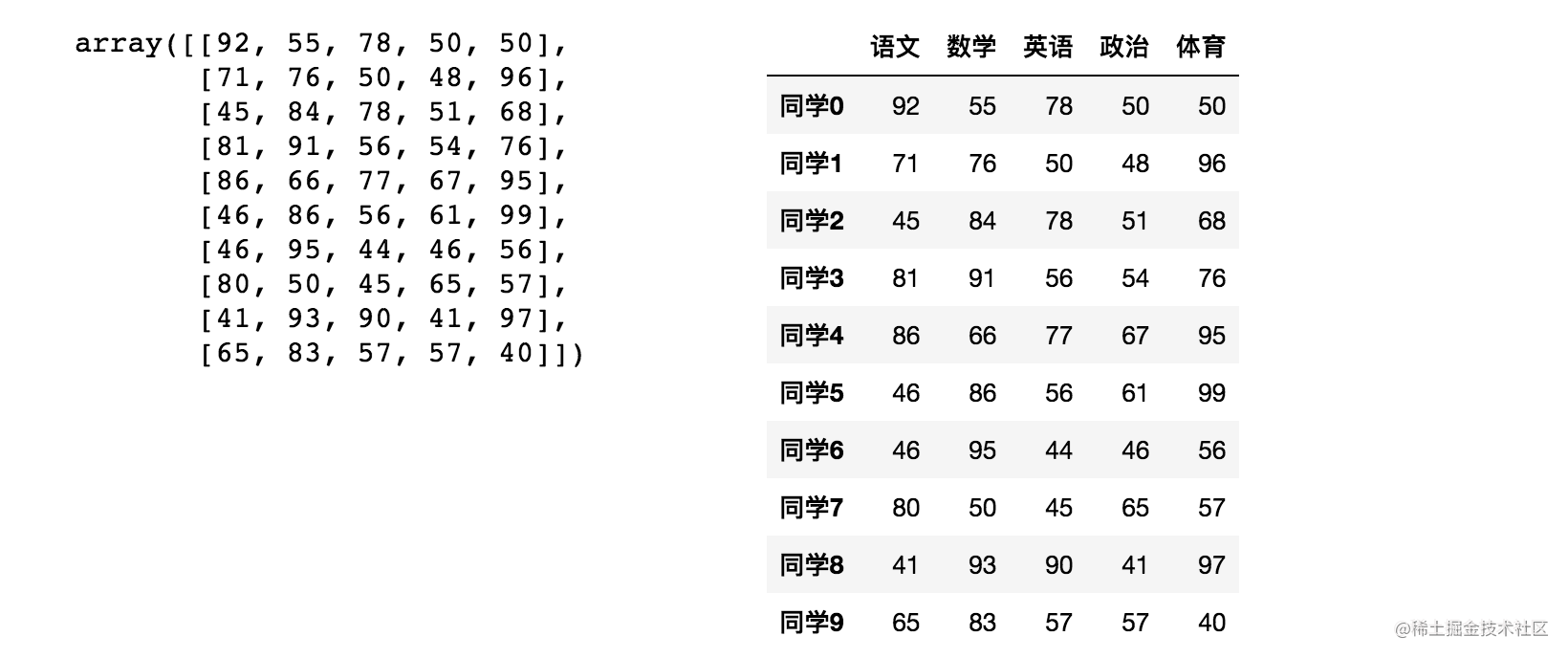
* **便捷的数据处理能力**
* **读取文件方便**
* **封装了Matplotlib、Numpy的画图和计算**
## 3 小结
* pandas的优势【了解】
* 增强图表可读性
* 便捷的数据处理能力
* 读取文件方便
* 封装了Matplotlib、Numpy的画图和计算
# 5.2 Pandas数据结构
## 学习目标
* 目标
* 知道Pandas的Series结构
* 掌握Pandas的Dataframe结构
* 了解Pandas的MultiIndex与panel结构
---
Pandas中一共有三种数据结构,分别为:Series、DataFrame和MultiIndex(老版本中叫Panel )。
其中Series是一维数据结构,DataFrame是二维的表格型数据结构,MultiIndex是三维的数据结构。
[threading 文档](https://docs.python.org/3/library/threading.html)
## 1.Series
Series是一个类似于一维数组的数据结构,它能够保存任何类型的数据,比如整数、字符串、浮点数等,**主要由一组数据和与之相关的索引两部分构成。**

### 1.1 Series的创建
```python
# 导入pandas
import pandas as pd
pd.Series(data=None, index=None, dtype=None)
-
参数:
- data:传入的数据,可以是ndarray、list等
- index:索引,必须是唯一的,且与数据的长度相等。如果没有传入索引参数,则默认会自动创建一个从0-N的整数索引。
- dtype:数据的类型
通过已有数据创建
- 指定内容,默认索引
pd.Series(np.arange(10))
# 运行结果
0 0
1 1
2 2
3 3
4 4
5 5
6 6
7 7
8 8
9 9
dtype: int64
- 指定索引
pd.Series([6.7,5.6,3,10,2], index=[1,2,3,4,5])
# 运行结果
1 6.7
2 5.6
3 3.0
4 10.0
5 2.0
dtype: float64
- 通过字典数据创建
color_count = pd.Series({'red':100, 'blue':200, 'green': 500, 'yellow':1000})
color_count
# 运行结果
blue 200
green 500
red 100
yellow 1000
dtype: int64
1.2 Series的属性
为了更方便地操作Series对象中的索引和数据,Series中提供了两个属性index和values
- index
color_count.index
# 结果
Index(['blue', 'green', 'red', 'yellow'], dtype='object')
- values
color_count.values
# 结果
array([ 200, 500, 100, 1000])
也可以使用索引来获取数据:
color_count[2]
# 结果
100
2.DataFrame
DataFrame是一个类似于二维数组或表格(如excel)的对象,既有行索引,又有列索引
- 行索引,表明不同行,横向索引,叫index,0轴,axis=0
- 列索引,表名不同列,纵向索引,叫columns,1轴,axis=1

2.1 DataFrame的创建
# 导入pandas
import pandas as pd
pd.DataFrame(data=None, index=None, columns=None)
-
参数:
- index:行标签。如果没有传入索引参数,则默认会自动创建一个从0-N的整数索引。
- columns:列标签。如果没有传入索引参数,则默认会自动创建一个从0-N的整数索引。
-
通过已有数据创建
举例一:
pd.DataF
