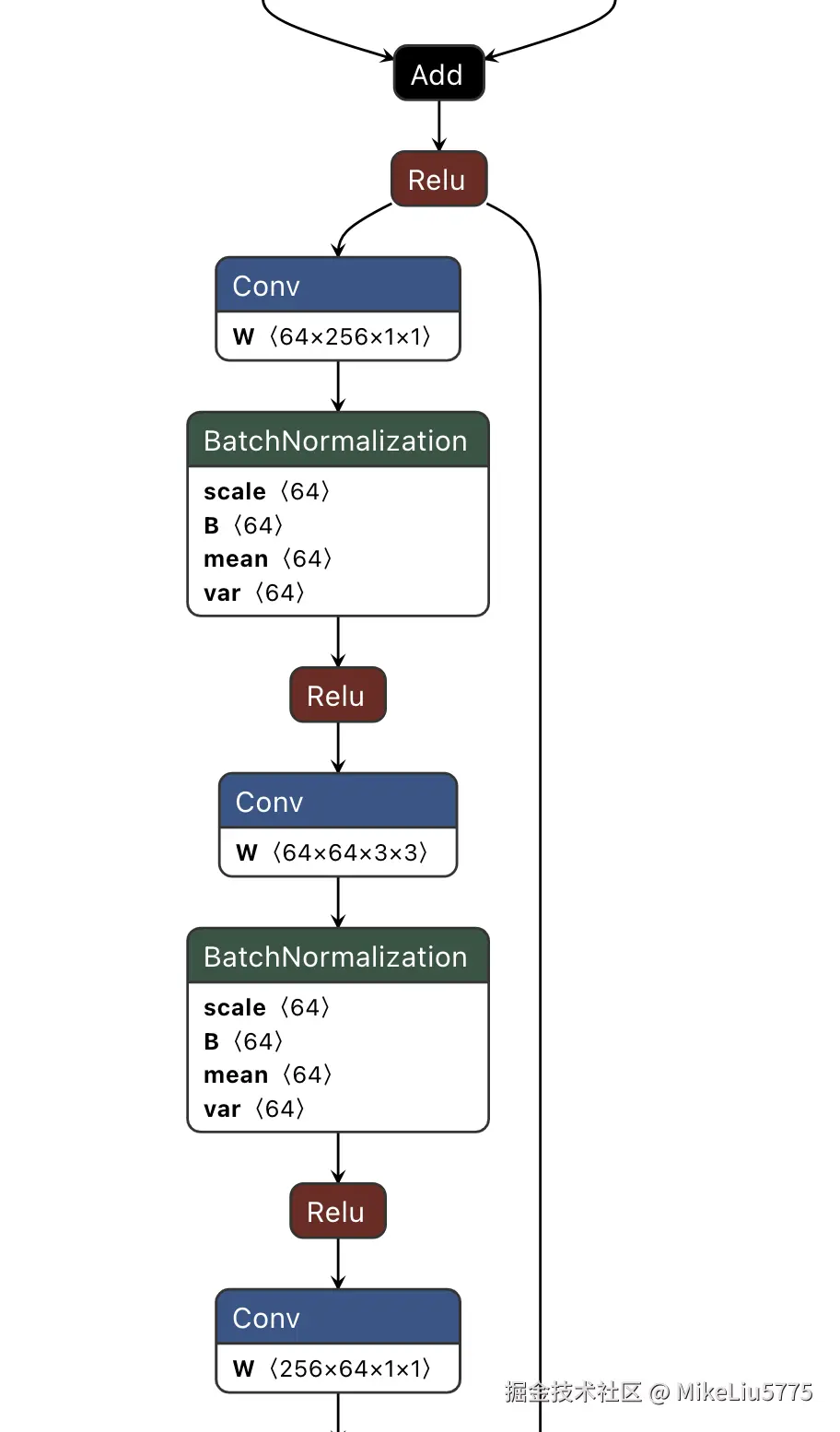
这里我们以视觉网络中常见的 conv+ bn 说起
一、推理融合
1. BatchNorm 的公式
对于通道 c 的输入特征图 x,BatchNorm 在训练时公式为:
y=γ⋅σ2+ϵx−μ+β
其中:
- μ,σ2:均值和方差(训练后会存成推理时固定的 running_mean 和 running_var)
- γ,β:可学习的缩放和偏移参数
- ϵ:防止除零的小常数
2. Conv 的公式
假设卷积层的权重为 W,偏置为 b,卷积计算为:
z=W*x+b
其中 * 表示卷积操作。
3. Conv + BN 融合原理
把 BN 的线性变换合并进卷积:
- BN 先把卷积结果标准化:
y=γ⋅σ2+ϵ(W∗x+b)−μ+β
- 重新整理成:
y=(σ2+ϵγ)(W∗x)+(σ2+ϵγ(b−μ)+β)
-
定义新的卷积参数:
W′=W⋅σ2+ϵγ
b′=σ2+ϵγ(b−μ)+β
最终得到等效的 Conv-only 层:
y=W′∗x+b′y = W' * x + b'
4. 融合的好处
- 减少推理开销:少了一层 BN 计算和访存。
- 简化计算图:利于部署到 TensorRT、TVM、ONNXRuntime、NCNN 等推理框架。
二、训练融合
前向融合
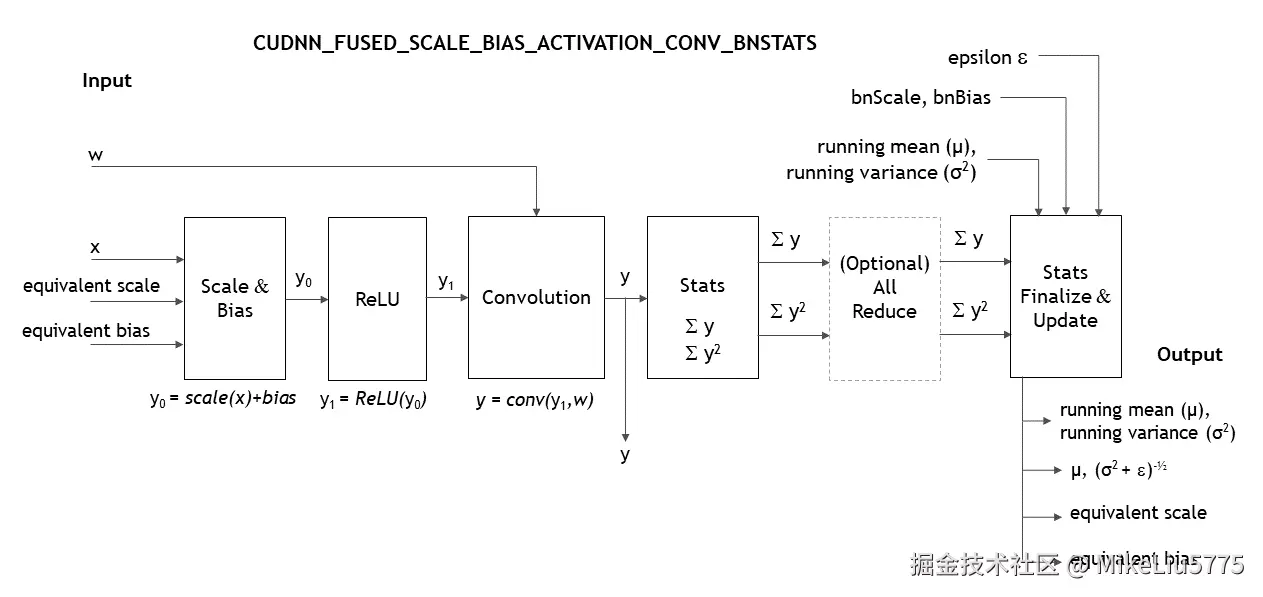
我们继续以该图分析
bn 训练前向
给定的某一通道内:
1、批统计:求均值 标准差
μB=m1i=1∑mxi,σB2=m1i=1∑m(xi−μB)2
2、求归一化
x^i=σB2+εxi−μB,yi=γx^i+β
以上两步都需要遍历当前通道内NHW个点
卷积前向:
假设卷积层的权重为 W,偏置为 b,卷积计算为:
z=W*x+b
其中 * 表示卷积操作。
这里我们以cuda 编程模型来考虑,为了追求性能,卷积和 bn 训练的滑块无法做到统一。所以对于训练融合我们换个思路,将 bn 训练第一步和第二步在计算图上拆为两个计算节点,归一化节点结合 relu,conv 进行融合。第一部分不进行融合,这样计算图可以粗略概括为,conv+bn+relu+bn==>conv+stats+(scale+bias+relu+conv)

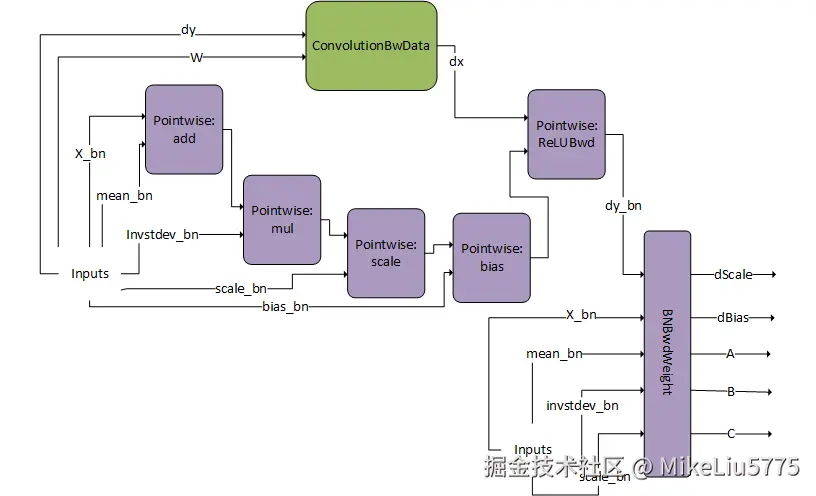
反向融合
反向融合首先要明白反向传播的原理,其本质就是链式求导
bn 的反向传播也主要分为两部分
第一步求 db ds
第二步求 A B C 三个系数并进行运算得出 dinput
推导如下
首先明白最终目标是求得 ∂xi∂L。
回顾前向公式
μ=m1j=1∑mxj,σ2=m1j=1∑m(xj−μ)2,x^i=σ2+εxi−μ,yi=γx^i+β.
所以反向公式分为三部分
∂xi∂L=∂x^i∂L∂xi∂x^i+∂μ∂L∂xi∂μ+∂σ2∂L∂xi∂σ2
1、∂x^i∂L∂xi∂x^i=∂yi∂L∂x^i∂yi∂xi∂x^i=∂yi∂Lγ
2、∂μ∂L∂xi∂μ
对于∂μ∂L,由两部分组成,一个是x^i中μ,另一部分是σ2中的μ,所以
∂μ∂L=i=1∑m∂x^i∂L∂μ∂x^i+i=1∑m∂x^i∂L∂σ2∂x^i∂μ∂σ2,
首先我们看下
∂μ∂σ2=m−2∑j=1m(xj−μ)这个导数恒等于0,所以∂μ∂L的值由前半部分∑i=1m∂x^i∂L∂μ∂x^i决定
i=1∑m∂x^i∂L∂μ∂x^i=i=1∑m∂x^i∂Lσ2+ε−1
又由于∂xi∂μ=m1,所以∂μ∂L∂xi∂μ=m1∑∂x^i∂Lσ−1
3、继续分析∂σ2∂L∂xi∂σ2
把 x^i=(xi−μ)inv_std,把inv_std看作σ2+ε1 看作 x^i 对 σ2 的函数:
∂σ2∂x^i=(xi−μ)⋅∂σ2∂inv_std=(xi−μ)⋅(−21)(σ2+ε)−3/2.
于是
∂σ2∂L=i∑dx^i∂σ2∂x^i=(−21)(σ2+ε)−3/2i∑dx^i(xi−μ).
又由于
∂xi∂σ2=m2(xi−μ)
所以
∂σ2∂L∂xi∂σ2=m2(xi−μ)∗(−21)(σ2+ε)−3/2j∑dx^j(xj−μ)
将以上求得的三部分相加
∂xi∂L=minv_std(mdx^i−S1−x^iS2)
S1(db)=j∑dx^j,S2(ds)=j∑dx^jx^j.
relu 的反向传播
relu 前向公式
y=ReLU(x)=max(0,x)
对输入 x 求导:
∂x∂y={10如果 x>0如果 x<0
假设我们有损失函数 L,它依赖于 ReLU 的输出 y,我们要求
∂x∂L
由链式法则:
∂x∂L=∂y∂L⋅∂x∂y
其中:
- ∂y∂L 来自上游(前一层传下来的梯度)
- ∂x∂y 是 ReLU 的导数(0 或 1)
所以:
∂x∂L={∂y∂L0如果 x>0如果 x≤0
在实际框架里,比如 PyTorch,ReLU backward 常写成:
grad_input = grad_output * (x > 0)
所以整个bn+relu+卷积的反向流程如图所示,这里类似前向分为两个算子,卷积 relu 为一个融合算子,求db ds为另一个算子
三、融合方式
预编译模式 不灵活但是算子可定制优化
动态生成编译模式 灵活但是算子不好定制优化性能略差


