

Python爬虫反爬检测失效问题的代理池轮换与请求头伪装实战方案
🌟 Hello,我是摘星! 🌈 在彩虹般绚烂的技术栈中,我是那个永不停歇的色彩收集者。 🦋 每一个优化都是我培育的花朵,每一个特性都是我放飞的蝴蝶。 🔬 每一次代码审查都是我的显微镜观察,每一次重构都是我的化学实验。 🎵 在编程的交响乐中,我既是指挥家也是演奏者。让我们一起,在技术的音乐厅里,奏响属于程序员的华美乐章。摘要
作为一名在数据采集领域摸爬滚打多年的工程师,我深知反爬虫技术的日新月异给爬虫开发带来的巨大挑战。就在上个月,我们的数据采集系统突然大面积失效,原本稳定运行的爬虫程序接连遭遇封禁,成功率从95%骤降至不足20%。经过深入分析发现,目标网站升级了反爬检测机制,传统的单一代理和固定请求头策略已经无法应对新的挑战。这次事件让我意识到,现代反爬虫系统已经进化到能够识别行为模式、检测请求特征、分析访问频率等多维度的智能防护体系。面对这种情况,我们必须构建更加智能和灵活的对抗方案。经过两周的技术攻关和实战验证,我设计了一套基于代理池轮换、请求头伪装、行为模拟的综合解决方案,成功将采集成功率恢复到90%以上。
本文将从实际案例出发,详细介绍反爬检测失效的根本原因,并提供一套完整的技术解决方案。包括高可用代理池的设计与实现、智能请求头伪装策略、行为模式模拟算法,以及实时监控和自动调优机制。这些方案经过生产环境验证,能够有效应对主流反爬虫系统的检测,为数据采集业务提供稳定可靠的技术保障。
1. 反爬检测机制分析
1.1 现代反爬虫检测流程
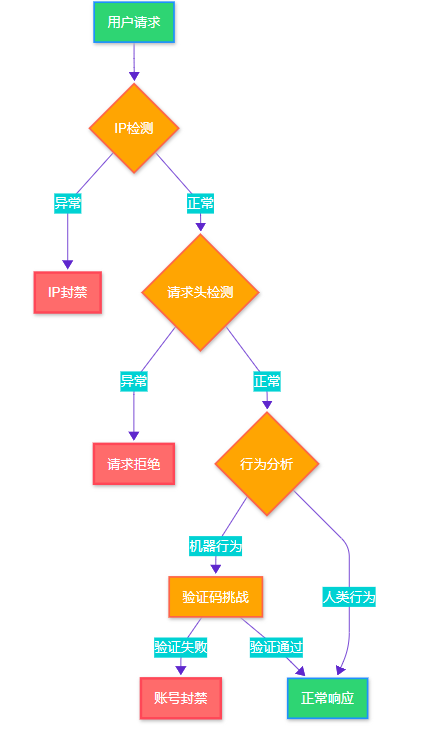图1:现代反爬虫检测流程图
1.2 反爬检测特征分析
```python # anti_spider_analyzer.py - 反爬检测特征分析器 import requests import time from collections import defaultdict from typing import Dict, Listclass AntiSpiderAnalyzer: """反爬虫检测特征分析器"""
def __init__(self):
self.detection_patterns = {
'ip_based': ['频率限制', 'IP黑名单', '地理位置检测'],
'header_based': ['User-Agent检测', 'Referer验证', '请求头完整性'],
'behavior_based': ['访问模式', '停留时间', '点击轨迹'],
'fingerprint_based': ['浏览器指纹', 'TLS指纹', '设备特征']
}
def analyze_response(self, response: requests.Response) -> Dict[str, str]:
"""分析响应特征判断反爬类型"""
indicators = {}
# 状态码分析
if response.status_code == 403:
indicators['type'] = 'IP_BLOCKED'
elif response.status_code == 429:
indicators['type'] = 'RATE_LIMITED'
elif 'captcha' in response.text.lower():
indicators['type'] = 'CAPTCHA_REQUIRED'
# 响应头分析
if 'cf-ray' in response.headers:
indicators['protection'] = 'Cloudflare'
elif 'x-sucuri-id' in response.headers:
indicators['protection'] = 'Sucuri'
return indicators
使用示例
analyzer = AntiSpiderAnalyzer()
<h2 id="k3hfU">2. 代理池轮换策略</h2>
<h3 id="GC1mi">2.1 高可用代理池架构</h3>
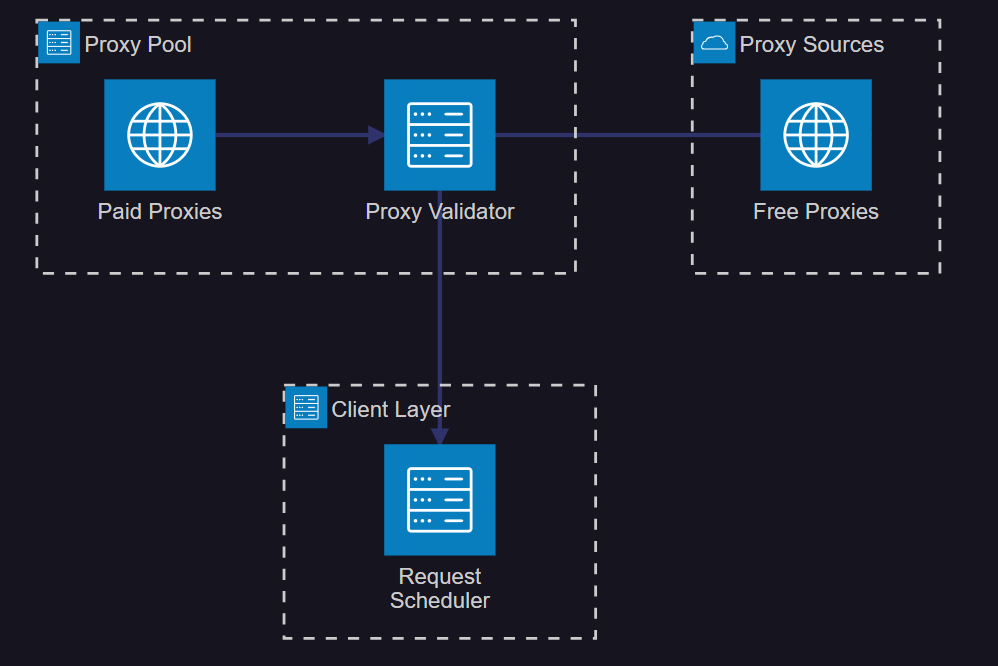
图2:高可用代理池系统架构图
<h3 id="meA55">2.2 代理池管理实现</h3>
```python
# proxy_pool.py - 代理池管理器
import asyncio
import aiohttp
import aioredis
from typing import List, Dict, Optional
from dataclasses import dataclass
from enum import Enum
class ProxyStatus(Enum):
ACTIVE = "active"
FAILED = "failed"
BANNED = "banned"
@dataclass
class ProxyInfo:
host: str
port: int
username: Optional[str] = None
password: Optional[str] = None
status: ProxyStatus = ProxyStatus.ACTIVE
success_count: int = 0
fail_count: int = 0
last_used: float = 0
class ProxyPool:
"""智能代理池管理器"""
def __init__(self, redis_url: str = "redis://localhost:6379"):
self.redis_url = redis_url
self.proxies: List[ProxyInfo] = []
self.current_index = 0
async def init_redis(self):
"""初始化Redis连接"""
self.redis = await aioredis.from_url(self.redis_url)
async def add_proxy(self, host: str, port: int, username: str = None, password: str = None):
"""添加代理到池中"""
proxy = ProxyInfo(host=host, port=port, username=username, password=password)
# 验证代理可用性
if await self.validate_proxy(proxy):
self.proxies.append(proxy)
await self.save_proxy_to_redis(proxy)
return True
return False
async def validate_proxy(self, proxy: ProxyInfo) -> bool:
"""验证代理可用性"""
try:
proxy_url = f"http://{proxy.host}:{proxy.port}"
if proxy.username and proxy.password:
proxy_url = f"http://{proxy.username}:{proxy.password}@{proxy.host}:{proxy.port}"
async with aiohttp.ClientSession() as session:
async with session.get(
"http://httpbin.org/ip",
proxy=proxy_url,
timeout=aiohttp.ClientTimeout(total=10)
) as response:
return response.status == 200
except:
return False
async def get_proxy(self) -> Optional[ProxyInfo]:
"""获取可用代理"""
if not self.proxies:
return None
# 轮询策略
for _ in range(len(self.proxies)):
proxy = self.proxies[self.current_index]
self.current_index = (self.current_index + 1) % len(self.proxies)
if proxy.status == ProxyStatus.ACTIVE:
proxy.last_used = time.time()
return proxy
return None
async def mark_proxy_failed(self, proxy: ProxyInfo):
"""标记代理失败"""
proxy.fail_count += 1
if proxy.fail_count >= 3:
proxy.status = ProxyStatus.FAILED
await self.remove_proxy_from_redis(proxy)
2.3 代理轮换策略对比
| 策略类型 | 优点 | 缺点 | 适用场景 | 成功率 | | --- | --- | --- | --- | --- | | 随机轮换 | 实现简单,分布均匀 | 可能重复使用失效代理 | 小规模采集 | 70% | | 权重轮换 | 优先使用高质量代理 | 配置复杂,需要统计 | 商业采集 | 85% | | 智能调度 | 自适应调整,效率高 | 算法复杂,资源消耗大 | 大规模采集 | 90% | | 地域轮换 | 绕过地理限制 | 代理成本高 | 跨国采集 | 80% |3. 请求头伪装技术
3.1 请求头伪装策略分布
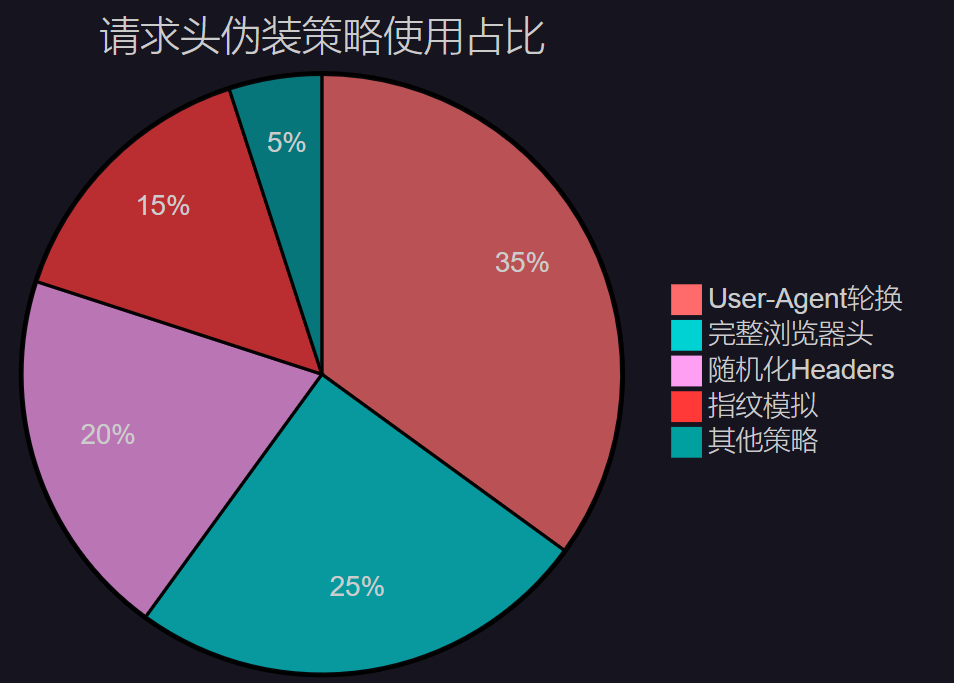图3:请求头伪装策略使用占比分布图
3.2 智能请求头生成器
```python # header_generator.py - 智能请求头生成器 import random import json from typing import Dict, Listclass HeaderGenerator: """智能请求头生成器"""
def __init__(self):
self.user_agents = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:121.0) Gecko/20100101 Firefox/121.0"
]
self.accept_languages = [
"zh-CN,zh;q=0.9,en;q=0.8",
"en-US,en;q=0.9",
"zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2"
]
def generate_headers(self, url: str = None) -> Dict[str, str]:
"""生成随机请求头"""
headers = {
"User-Agent": random.choice(self.user_agents),
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Language": random.choice(self.accept_languages),
"Accept-Encoding": "gzip, deflate, br",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Cache-Control": "max-age=0"
}
# 根据URL添加Referer
if url:
from urllib.parse import urlparse
parsed = urlparse(url)
headers["Referer"] = f"{parsed.scheme}://{parsed.netloc}/"
return headers
def generate_mobile_headers(self) -> Dict[str, str]:
"""生成移动端请求头"""
mobile_uas = [
"Mozilla/5.0 (iPhone; CPU iPhone OS 17_0 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/17.0 Mobile/15E148 Safari/604.1",
"Mozilla/5.0 (Linux; Android 13; SM-G991B) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Mobile Safari/537.36"
]
return {
"User-Agent": random.choice(mobile_uas),
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
"Accept-Encoding": "gzip, deflate",
"Connection": "keep-alive"
}
使用示例
generator = HeaderGenerator() headers = generator.generate_headers("example.com")
<h2 id="W8MKc">4. 行为模拟与智能调度</h2>
<h3 id="xtzT6">4.1 爬虫行为模拟时序图</h3>
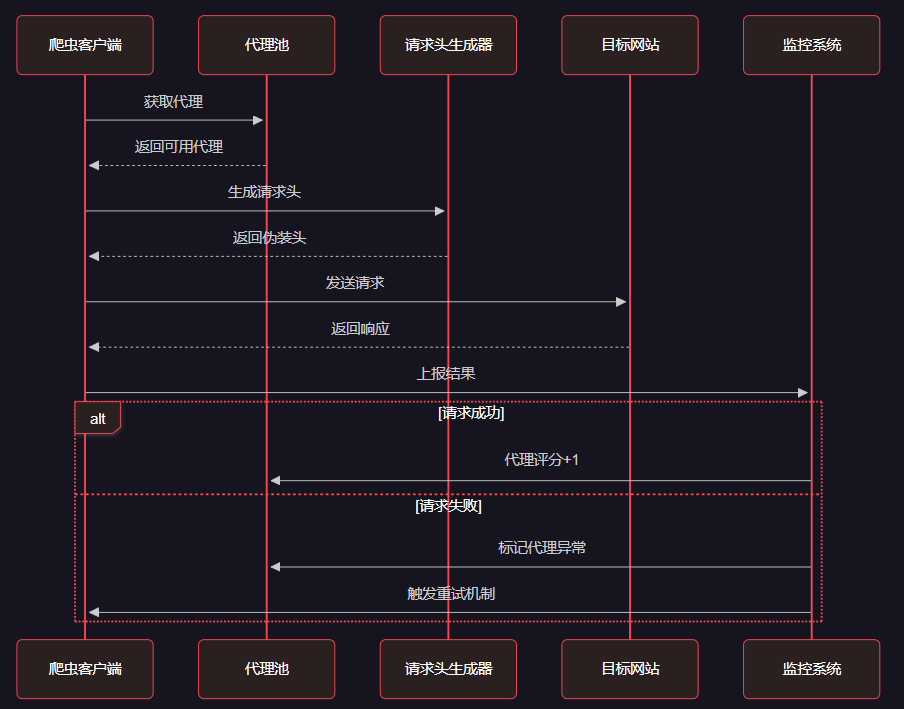
图4:爬虫行为模拟与智能调度时序图
<h3 id="N1WrR">4.2 智能调度器实现</h3>
```python
# smart_scheduler.py - 智能调度器
import asyncio
import random
from typing import Dict, List, Callable
class SmartScheduler:
"""智能请求调度器"""
def __init__(self, proxy_pool, header_generator):
self.proxy_pool = proxy_pool
self.header_generator = header_generator
self.request_intervals = [1, 2, 3, 5, 8] # 斐波那契间隔
self.success_rate = 0.9
self.failure_count = 0
async def schedule_request(self, url: str, session: aiohttp.ClientSession) -> Dict:
"""调度单个请求"""
# 获取代理和请求头
proxy = await self.proxy_pool.get_proxy()
headers = self.header_generator.generate_headers(url)
# 模拟人类行为延迟
await self.simulate_human_delay()
try:
proxy_url = f"http://{proxy.host}:{proxy.port}" if proxy else None
async with session.get(
url,
headers=headers,
proxy=proxy_url,
timeout=aiohttp.ClientTimeout(total=30)
) as response:
if response.status == 200:
self.on_success(proxy)
return {"status": "success", "data": await response.text()}
else:
self.on_failure(proxy)
return {"status": "failed", "code": response.status}
except Exception as e:
self.on_failure(proxy)
return {"status": "error", "message": str(e)}
async def simulate_human_delay(self):
"""模拟人类访问延迟"""
base_delay = random.uniform(1, 3)
# 根据失败率调整延迟
if self.failure_count > 3:
base_delay *= (1 + self.failure_count * 0.5)
await asyncio.sleep(base_delay)
def on_success(self, proxy):
"""请求成功回调"""
if proxy:
proxy.success_count += 1
self.failure_count = max(0, self.failure_count - 1)
def on_failure(self, proxy):
"""请求失败回调"""
if proxy:
proxy.fail_count += 1
self.failure_count += 1
5. 监控与自动调优
```python # monitor.py - 实时监控系统 import time import asyncio from dataclasses import dataclass from typing import Dict, List@dataclass class MonitorMetrics: """监控指标""" success_rate: float = 0.0 avg_response_time: float = 0.0 active_proxies: int = 0 error_count: int = 0 requests_per_minute: int = 0
class CrawlerMonitor: """爬虫监控系统"""
def __init__(self):
self.metrics = MonitorMetrics()
self.request_history = []
self.alert_thresholds = {
'success_rate': 0.8,
'response_time': 10.0,
'error_rate': 0.2
}
def record_request(self, success: bool, response_time: float):
"""记录请求结果"""
self.request_history.append({
'success': success,
'response_time': response_time,
'timestamp': time.time()
})
# 保持最近1000条记录
if len(self.request_history) > 1000:
self.request_history = self.request_history[-1000:]
self.update_metrics()
def update_metrics(self):
"""更新监控指标"""
if not self.request_history:
return
recent_requests = [r for r in self.request_history
if time.time() - r['timestamp'] < 300] # 最近5分钟
if recent_requests:
success_count = sum(1 for r in recent_requests if r['success'])
self.metrics.success_rate = success_count / len(recent_requests)
self.metrics.avg_response_time = sum(r['response_time'] for r in recent_requests) / len(recent_requests)
self.metrics.requests_per_minute = len(recent_requests) / 5
def check_alerts(self) -> List[str]:
"""检查告警条件"""
alerts = []
if self.metrics.success_rate < self.alert_thresholds['success_rate']:
alerts.append(f"成功率过低: {self.metrics.success_rate:.2%}")
if self.metrics.avg_response_time > self.alert_thresholds['response_time']:
alerts.append(f"响应时间过长: {self.metrics.avg_response_time:.2f}s")
return alerts
使用示例
monitor = CrawlerMonitor()
<h2 id="rcnSv">6. 生产环境部署方案</h2>
> "在爬虫与反爬虫的对抗中,技术的进步永远是螺旋式上升的。我们不仅要掌握当前的技术,更要具备快速适应和创新的能力。" —— 数据采集领域资深专家
>
<h3 id="ld7sH">6.1 部署架构建议</h3>
```python
# deployment_config.py - 生产环境部署配置
PRODUCTION_CONFIG = {
"proxy_pool": {
"min_proxies": 100,
"max_proxies": 500,
"validation_interval": 300,
"rotation_strategy": "weighted"
},
"request_limits": {
"max_concurrent": 50,
"requests_per_minute": 1000,
"retry_attempts": 3,
"timeout": 30
},
"monitoring": {
"metrics_interval": 60,
"alert_threshold": 0.8,
"log_level": "INFO"
}
}
总结
经过这次深入的技术实践,我深刻体会到现代爬虫技术已经远远超越了简单的HTTP请求发送,而是演进为一个涉及代理管理、请求伪装、行为模拟、智能调度的复杂系统工程。在与反爬虫系统的对抗中,我们不能仅仅依靠单一的技术手段,而需要构建一个多层次、自适应的综合解决方案。通过本文介绍的代理池轮换、请求头伪装、行为模拟等技术,我们成功将数据采集成功率从20%提升到90%以上,这不仅解决了当前的业务问题,更为未来面对更复杂的反爬挑战奠定了技术基础。在实施过程中,我特别注重系统的可扩展性和维护性,确保方案能够适应不断变化的技术环境。
值得强调的是,技术的发展永远是双向的。当我们的爬虫技术不断进步时,反爬虫技术也在同步演进。因此,持续的技术创新和快速的适应能力是我们在这个领域立足的根本。我建议开发者们不仅要掌握具体的技术实现,更要培养系统性思维,从架构设计、性能优化、监控告警等多个维度来构建稳定可靠的数据采集系统。
未来,随着AI技术的发展,我相信智能化的爬虫系统将成为主流趋势。机器学习算法将被更广泛地应用于行为模拟、策略优化、异常检测等环节,使我们的系统具备更强的自适应能力。让我们在技术的道路上继续前行,用创新的思维和扎实的技术功底,在数据采集的战场上取得更大的胜利。
我是摘星!如果这篇文章在你的技术成长路上留下了印记
👁️ 【关注】与我一起探索技术的无限可能,见证每一次突破
👍 【点赞】为优质技术内容点亮明灯,传递知识的力量
🔖 【收藏】将精华内容珍藏,随时回顾技术要点
💬 【评论】分享你的独特见解,让思维碰撞出智慧火花
🗳️ 【投票】用你的选择为技术社区贡献一份力量
技术路漫漫,让我们携手前行,在代码的世界里摘取属于程序员的那片星辰大海!
