最近再次推到了ROPE,又产生了很多疑惑,故而做如下笔记记录。苏神科学空间,原文:spaces.ac.cn/archives/82…
一、背景知识
1. 二维向量复数表示
二维向量的复数表示是什么意思?
二维向量的复数表示是指将二维向量 (a,b) 映射为复数 a+bi,其中:
- a 是向量的实部(横坐标),对应实轴方向的分量。
- b 是向量的虚部(纵坐标),对应虚轴方向的分量。
- i 是虚数单位,满足 i2=−1。
这种表示的本质是将二维向量与复平面中的点或向量一一对应。复数的几何意义在于:
- 模(长度):复数的模 r=a2+b2 对应向量的长度。
- 辐角(相位角):复数的辐角 θ=arctan(b/a) 对应向量与实轴正方向的夹角。
为什么要用复数表示二维向量?
复数表示二维向量的核心优势在于 简化几何变换的运算,尤其是在旋转、缩放等操作中。
复数乘法在几何上可以分解为:
- 模的乘积:两个复数相乘,其模等于各自模的乘积。
- 辐角的相加:两个复数相乘,其辐角等于各自辐角的和。
例如,将复数 z1=a+bi 乘以 z2=cosθ+isinθ(即单位复数表示旋转),结果为:
z1⋅z2=(acosθ−bsinθ)+i(asinθ+bcosθ),
这相当于将向量 (a,b) 逆时针旋转 θ 角度后的向量。
对比传统方法:
- 若用矩阵表示旋转,需要计算旋转矩阵:
[cosθsinθ−sinθcosθ]⋅[ab].
- 复数乘法直接通过代数运算完成旋转,无需显式构造矩阵。
复数表示的本质是 将代数与几何统一,通过复数的代数性质(如乘法、极坐标形式)高效地描述二维向量的几何变换。这种表示方式在数学理论和工程实践中均具有重要价值。
2. 矩阵
正交矩阵
- 定义:一个 n×n 的实数方阵 Q 满足 QTQ=I,即其列向量(或行向量)两两正交且为单位向量。
- 行列式:det(Q)=±1。
- 若 det(Q)=1,称为旋转矩阵(纯旋转)。
- 若 det(Q)=−1,称为反射矩阵(包含反射操作)。
- 逆矩阵:正交矩阵的逆矩阵为其转置,即 Q−1=QT。
- 几何意义:保持向量长度和角度不变,但可能改变方向(反射时反转方向)。
- 封闭性:正交矩阵的乘积、逆矩阵仍是正交矩阵。
旋转矩阵
- 定义:行列式为1的正交矩阵,即 RTR=I 且 det(R)=1。
- 几何意义:仅表示纯旋转操作,不改变空间方向(如右手定则)。
- 迹与旋转角的关系:在三维空间中,旋转矩阵的迹为 1+2cosθ,其中 θ 是旋转角。
- 封闭性:旋转矩阵的乘积仍为旋转矩阵。
- 旋转矩阵的乘积:两个旋转矩阵相乘的结果仍为旋转矩阵,其对应的旋转角度是两者的和。例如,R(α)⋅R(β)=R(α+β)。
验证示例(二维空间)
- 旋转矩阵公式:
R(θ)=[cosθsinθ−sinθcosθ]
- 计算 R(−m)⋅R(n):
R(−m)=[cosm−sinmsinmcosm],R(n)=[cosnsinn−sinncosn]
乘积结果为:
R(−m)⋅R(n)=[cos(n−m)sin(n−m)−sin(n−m)cos(n−m)]=R(n−m)
二、 ROPE解释
1. Transformer 的局限性
Transformer 架构的核心是自注意力机制,其计算方式 Attention(Q,K,V)=softmax(QKT/sqrt(dk))V。这种计算方式的本质是计算 Query 和 Key 之间的点积相似度。
然而,点积操作本身不包含任何位置信息。这意味着,如果我们将输入序列的词序打乱,Transformer 在理论上会得到相同的注意力分数(因为 QKT 是对所有 Q 和 K 的点积,与它们的原始顺序无关)。这就是 Transformer 的置换不变性。
为了引入位置信息,传统的做法有:
-
绝对位置编码 (Absolute PE):将位置编码pi 直接加到词向量 xi 上,即 qi=xi+pi,kj=xj+pj。
- 此时 qiTkj=(xi+pi)T(xj+pj)=xiTxj+xiTpj+piTxj+piTpj。
- 这种方法的问题在于,点积结果包含了词向量自身的相似度、词向量与位置编码的交互、以及位置编码自身的相似度。相对位置信息 (i−j) 无法被简洁地表示,并且在外推(训练时没见过的长序列)时表现不佳。
-
相对位置编码 (Relative PE):尝试直接在 QKT 中引入相对位置信息。例如 Shaw et al. (Transformer-XL) 的方法在计算注意力分数时额外考虑相对位置。
RoPE 的目标是设计一种简洁、高效的位置编码方法,使得点积操作天然地包含相对位置信息,并且能够很好地外推。
2. 核心思想:通过旋转引入相对位置
RoPE 的核心思想是:能否找到一种函数 f(x,m),它能将位置 m 的信息编码到向量 x 中,使得任意两个向量 q 和 k 在经过位置编码后,它们的点积只依赖于它们的相对位置 m−n?
即,我们希望 f(q,m)Tf(k,n)=g(q,k,m−n)。
考虑二维向量 v=(x,y),我们可以将其看作复数 z=x+iy。
复数乘法 z∗e(iθ) 对应于在复平面上将 z 旋转 θ 角。
e(iθ)=cos(θ)+isin(θ)。
那么 (x+iy)(cos(θ)+isin(θ))=(xcos(θ)−ysin(θ))+i(xsin(θ)+ycos(θ))。
这在实数域中,对应于对向量 (x,y) 应用一个旋转矩阵:
R(θ)=[cosθsinθ−sinθcosθ]
所以,R(θ)∗[x,y] 就是将向量 (x,y) 旋转 θ 角。
现在,我们将这个旋转操作应用到我们的 f(x,m) 函数中:
令 f(q,m)=R(mθ)q 和 f(k,n)=R(nθ)k,其中 θ 是一个与位置相关的角度参数。
那么,它们的点积为:
f(q,m)Tf(k,n)=(R(mθ)q)T(R(nθ)k)=qTR(mθ)TR(nθ)k
由于 R(θ) 是正交矩阵,所以 R(θ)T=R(−θ)。
qTR(mθ)TR(nθ)k=qTR(−mθ)R(nθ)k
由于 R(θ) 是旋转矩阵,有 R(A)R(B)=R(A+B) (两次旋转等价于一次旋转角度之和),
qTR(−mθ)R(nθ)k=qTR(nθ−mθ)k=qTR((n−m)θ)k
我们得到了一个非常漂亮的结果:f(q,m)Tf(k,n) 只依赖于相对位置 (n−m)!这正是我们想要的 g(q,k,n−m) 形式。
3. 从二维推广到高维
要将二维旋转矩阵进行推广,最直接的思路是,把维度两两分组。假设词向量维度为 d(d 为 2 的倍数):
M⋅q=cosmθ0sinmθ0⋮00−sinmθ0cosmθ0⋮00⋯⋯⋱⋯⋯00⋮cosmθd/2−1sinmθd/2−100⋮−sinmθd/2−1cosmθd/2−1q0q1⋮qd−2qd−1
如此,d 个维度被分为了 d/2 组,θ 也有了分别 d/2个取值。
在代码实现上可以用以下思路来等效计算 M⋅q,节省资源:
M⋅q=q0q1q2q3⋮qd−2qd−1⊙cosmθ0cosmθ0cosmθ1cosmθ1⋮cosmθd/2−1cosmθd/2−1+−q1q0−q3q2⋮−qd−1qd−2⊙sinmθ0sinmθ0sinmθ1sinmθ1⋮sinmθd/2−1sinmθd/2−1
这样,RoPE 巧妙地将位置信息编码到了 Query 和 Key 向量中,使得它们在计算点积时,天然地反映了相对位置。
4. θ 函数
θk 是 RoPE 中非常关键的参数,它决定了每个维度对的旋转频率。
(1) θk 的公式
RoPE 中 θk 的计算方式与原始 Transformer 的正弦/余弦位置编码中的频率设置非常相似:
θk=(base(2k/d))1=base−(2k/d)
其中:
- k:维度对的索引,从 0 到 d/2−1。
- d:向量的维度 (hidden size)。
- base:一个超参数,通常取 10000 (与原始 Transformer PE 相同),LLaMA 1 用的是 10000,LLaMA 2 则将其扩展到了 500000, Qwen3更是扩展到 1,000,000
(2) 为什么选择10000作为基数?
- 历史借鉴:RoPE的θ设计借鉴了Transformer的Sinusoidal位置编码,后者同样使用10000作为基数。这种设计保证了不同维度的频率范围合理,且具有一定的外推性(能够处理超出训练长度的序列)。
- 频率分布:10000的指数衰减使得不同维度的频率覆盖从高频到低频的连续范围,从而能够捕捉不同尺度的相对位置关系。
(3) θ的作用示例
假设一个128维的向量,其θ的计算如下:
- 第0维(i=0):θ0=10000−2⋅0/128=1
- 第1维(i=2):θ2=10000−2⋅2/128=10000−1/32≈0.95
- 第64维(i=128):θ64=10000−2⋅64/128=10000−1=0.0001
结果:低维(如i=0)的θ较大,对应高频旋转;高维(如i=64)的θ较小,对应低频旋转。
(4) 远程衰减
import numpy as np
import matplotlib.pyplot as plt
d = 128
def theta(t):
return 10000 **(-2 * t / d)
def f(m):
total = 0.0
for j in range(int(d/2)):
inner_sum = 0.0j
for i in range(j + 1):
inner_sum += np.exp(1j * m * theta(i))
total += np.abs(inner_sum)
return total / (d/2)
m_values = np.linspace(0, 256, 1000)
f_values = [f(m) for m in m_values]
plt.figure(figsize=(10, 6))
plt.plot(m_values, f_values)
plt.xlabel('相对距离')
plt.ylabel('相对大小')
plt.title('f(m)的图像')
plt.grid(True)
plt.show()
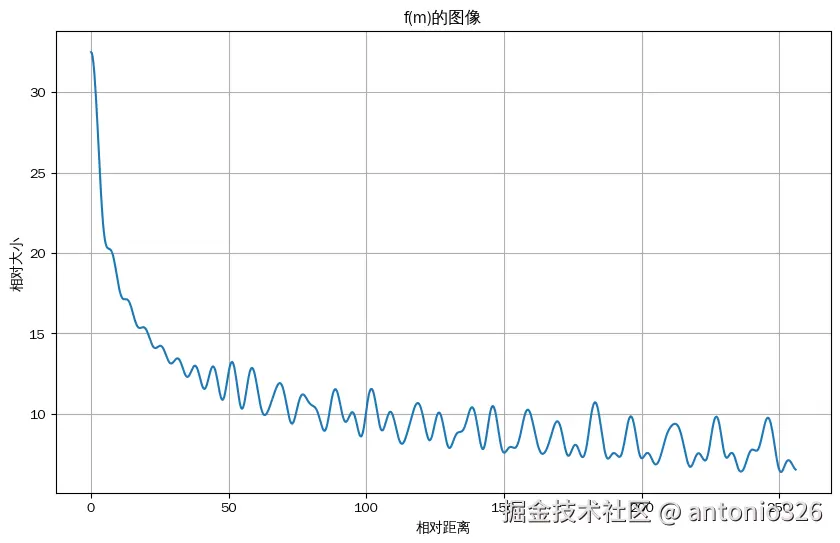 从图中可以看到随着相对距离的变大,内积结果有衰减趋势的出现。因此,选择θi=10000−2i/d,确实能带来一定的远程衰减性。几乎任意的光滑单调函数都可以,带来远程衰减性。
从图中可以看到随着相对距离的变大,内积结果有衰减趋势的出现。因此,选择θi=10000−2i/d,确实能带来一定的远程衰减性。几乎任意的光滑单调函数都可以,带来远程衰减性。
苏神还试过以θi=10000−2i/d为初始化,将θi视为可训练参数,然后训练一段时间后发现θi并没有显著更新,因此干脆就直接固定θi=10000−2i/d了。


