

Qwen:
1.分词器采用BPE:
核心思想:先按照字符切分,逐渐合并出现频率高的子词。
-
问题:
- BPE理论上还是会出现OOV的,当词汇表受限,语料中又没有出现过某个子词,这个子词就无法进入词典中。而BBPE理论上不会出现这种问题。
参考:
2.使用Untied Embedding
输入嵌入(input embedding)和输出投影(output projection)使用独立的权重矩阵,而不是共享的权重。会增加内存消耗,但是可以获得更好的性能。
3.采用FP32精度的旋转位置编码(RoPE)
并选择使用FP32精度的逆频率矩阵
4.在QKV层中添加bias,其他层移除bias
移除大多数层的bias有助于提高模型稳定性和性能,这种做法减少参数量,从而降低模型复杂度和过拟合风险。在QKV注意力层中添加bias,可以更好捕捉输入数据的特征,从而提升模型在处理未知或者未见数据时候的表现,这点能增强模型的外推能力。
5.采用Pre-Norm
- Pre-Norm:LN在MHA和FFN之前(->LN->MHA->残差->LN->FFN->残差->)
- Post-Norm: LN再MHA和FFN之后(->MHA->残差->LN->FFN->残差->LN->)
- Pre-Norm收敛速度更快、有助于训练早期阶段梯度稳定。Post-Norm效果更好。
6.替换LN,采用RMSNorm
-
LN:Layer Normalization是模型每一层对输入进行归一化的技术。
-
,其中和是输入x的均值和标准差,后面两个是可学习的参数。
-
优点:
- 稳定性:通过对每一层的输入进行归一化,可以缓解梯度消失和梯度爆炸的问题。
- 无batch依赖:LN是在句子内部做归一化,BN是在batch维度做归一化。因此LN在小batch或者单样本依然有以下。
-
缺点:
- 计算复杂度高:LN需要计算均值和标准差,计算相对复杂。
- 对特征缩放不敏感:有时候会对特征缩放不敏感,需要额外调整超参数。
-
-
RMS Norm:
RMS Norm是一种通过均方根值( Root Mean Square ) 对输入进行归一化的方法:
-
优点:
- 计算效率高:RMS Norm比LN计算复杂度低,因为不需要计算均值和标准差,只需要计算均方根值。
- 稳定性好:RMS Norm也可以缓解梯度消失和梯度爆炸的问题,提升模型的训练稳定性。
-
缺点:
- 信息损失:由于RMS Norm只考虑了均方根值,会丢失一些与输入分布相关的信息。
7.激活函数采用SwiGLU
结合了Swish和Gated Linear Units(GLU)的优点,提供更强的表达能力和更好的性能。
- Swish激活函数是对ReLU激活函数的改进,在0附近提供更平滑的转换。在零点可微的。
- GLU激活函数具有门控机制, 可以帮助网络更好的捕获序列数据中的长距离依赖。在大语言模型中,对于处理长序列、长距离依赖的文本更适合。
8.注意力模块采用Flash Attenion,提高训练速度
9.外推能力扩展
Transformer在注意力机制的上下文方面有限制,直接增加训练阶段上下文,会导致训练成本急剧增长。
Qwen在推理阶段实现上下文长度的扩展。
经过下面的优化,Qwen模型在inferenc可以处理8192(训练使用的是2048,提升了4倍)个token的长序列。
9.1 RoPE的问题:直接外推会出现比较大的Attention score
Qwen使用位置编码是RoPE,虽然RoPE相对绝对位置编码有可外推的优点,但是直接使用,会有一些问题,QWen针对这些问题做了改进:
-
cos和sin函数的周期性:
- 由于cos和sin的周期性,训练数据中,位置通常在一个相对较小的周期内(例如:0到512或者0-到2048),这些位置的编码值会保持在周期的某一部分。
- 当位置超出这个范围(如位置到3000或者5000),编码值会进入cos和sin的另一个周期。由于函数的周期性,这些位置的编码值可能与训练数据中的位置编码值非常不同,导致模型在计算attention score的时候出现剧烈变化。
-
高频成分的影响:
-
RoPE编码中,较高维度的编码会对位置变化更加敏感。这一位置,随着位置数据的增加,这些高频成分会迅速变化。
-
对于较大位置的编码值,cos和sin的值会经历迅速变化,这会导致计算Attenion score出现剧烈变化。
-
9.2 解决办法:“动态NTK感知差值”来实现Inference阶段的上下文长度扩展- 位置插值法: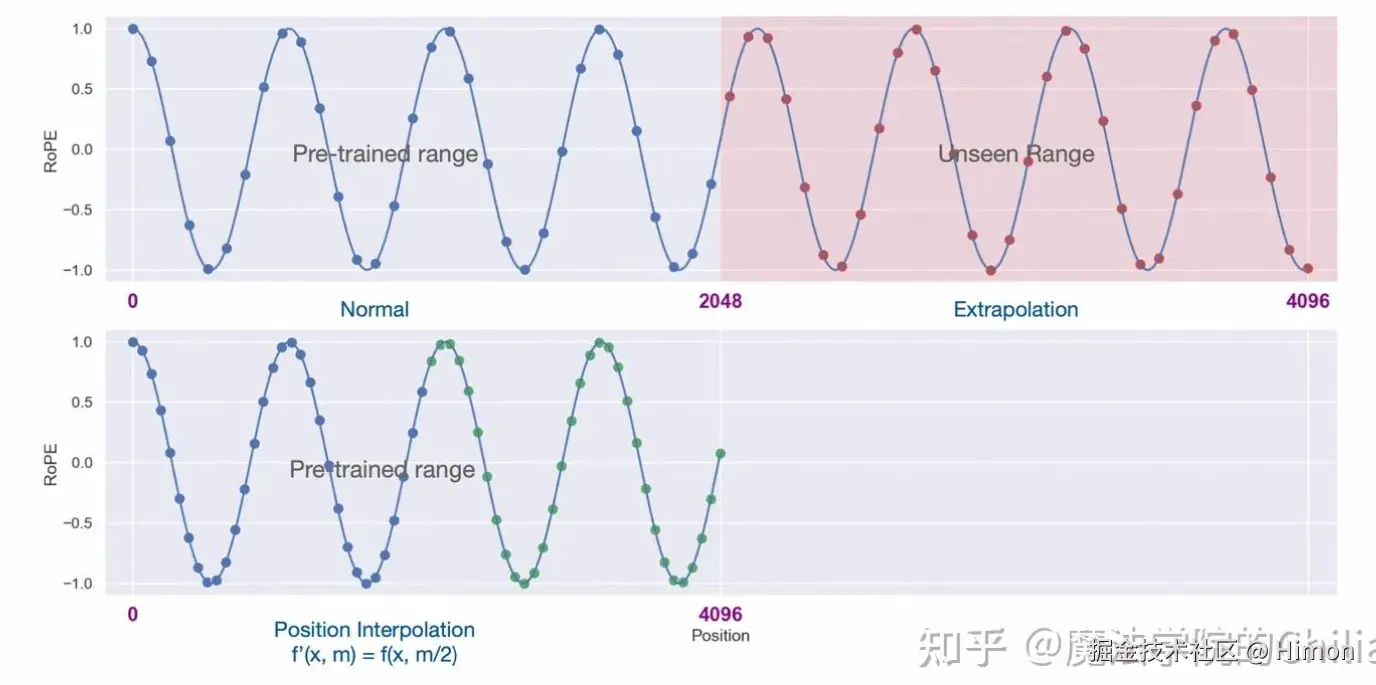 直观理解:右上角是预训练阶段位置向量范围[0,2048],右上角微长度外推部分(2048,4096],如果直接使用位置(2048,4096]进行推理,因为模型没有见过这部分位置,效果就会出现灾难性下降。 因此把[0,4096]这个区间压缩到[0,2048],这就是位置内插法。- NTK-aware差值法 位置插值法的问题:如果差值是正对绝对位置m,那么对每个维度j都同等生效,公平对待。但是在高频维度,差值之后会变得很密集,这样高频的维度就变得很拥挤。 NTK-aware差值的核心思想:高频外推,低频内插。
直观理解:右上角是预训练阶段位置向量范围[0,2048],右上角微长度外推部分(2048,4096],如果直接使用位置(2048,4096]进行推理,因为模型没有见过这部分位置,效果就会出现灾难性下降。 因此把[0,4096]这个区间压缩到[0,2048],这就是位置内插法。- NTK-aware差值法 位置插值法的问题:如果差值是正对绝对位置m,那么对每个维度j都同等生效,公平对待。但是在高频维度,差值之后会变得很密集,这样高频的维度就变得很拥挤。 NTK-aware差值的核心思想:高频外推,低频内插。
9.2 采用LogN-Scaling 在attention计算时使用 LogN-Scaling,根据上下文长度调整点乘,注意力的熵在上下文长度增加的时候也保持稳定,提高外推能力。 n是输入长度,k是超参。
9.3 SWA(sliding window attention)1. 只在一段窗口内做注意力计算。
- 发现较低的层对上下文长度更敏感,因此在底层采用更短的窗口。
Qwen2
1. 采用BBPE(Byte-leve BPE):
与BPE的区别:BPE是字符级别,BBPE是字节级别。
在UTF-8编码下,每个中文字符由3个字节表示,如“我爱北京天安门”,“我”对应的UTF-8字节是
合并算法与BPE一样。
-
BBPE优势:
- 理论上不会存在OOV的问题。
- 解决生僻字:如emoji等。
参考:
2. 采用了GQA(Grouped Query Attention)
代替了传统的MHA(multi head attention)。GQA通过KV-cache,在推理阶段显著提高了吞吐量。
3.采用双块注意力:
为了扩展大模型的上下文窗口,Qwen2实现了双快注意力机制,将长序列分割成可管理的长度快。
如果整个序列分成4个块,C1,C2,C3,C4,具体的做法:
- 计算块内的局部注意力:就是在块内执行Self-attention,得到attention score。
- 对每个块,计算一个块表示:计算平均值或者最大值。
- 计算全局注意力:在上面的快表示之间计算全局注意力。
4.YARN
采用YARN(Yet Another Rescaling Method),用于重新调整注意力权重,以更好的处理不同长度的序列。
具体实现过程:
- 计算原始注意力权重:如常规的dot-product attention。
- 计算缩放因子:这个因子通常是一个与序列长度相关的函数,用来调整注意力权重的分布。比如:
- 应用缩放因子:将前面的缩放因子应用在原始注意力权重上。
- 归一化:对调整后的注意力权重进行归一化处理,确保权重总和为1。
5.MoE架构
6.RLHF采用DPO算法
7.源码解读
参考:
Qwen3:
1.q,k做了RMSNorm归一
2.混合推理
- 具体应用
AIP中提供了一个“enable_thinking”的字段
apply_chat_template()这个函数是transformers中构建对话模版的方法
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False # True is the default value for enable_thinking.
)
- 实现原理
在千问3.0模型中,通过Jinja2模版来定义文本模板,包括:
<|im_start|>和<|im_end|>:标记消息的开始和结束role:标识消息发送者(system、user、assistant、tool)<think></think>:围绕助手的思考过程<tool_call></tool_call>:包含工具调用信息<tool_response></tool_response>:包含工具响应信息
其中有一段内容:
{%- if add_generation_prompt %}
{{- '<|im_start|>assistant\n' }}
{%- if enable_thinking is defined and enable_thinking is false %}
{{- '<think>\n\n</think>\n\n' }}
{%- endif %}
{%- endif %}
会根据config中enable_thinking的值来生成不同格式的输入:
"""
<|im_start|>system
你是一名乐于助人的助手。<|im_end|>
<|im_start|>user
给我讲讲大语言模型。<|im_end|>
<|im_start|>assistant
"""
"""
<|im_start|>system
你是一名乐于助人的助手。<|im_end|>
<|im_start|>user
给我讲讲大语言模型。<|im_end|>
<|im_start|>assistant
<think>
</think>
"""
相当于在enable_thinking=False的情况下,在构建context的时候,把内容已经放进去了,那么大模型就不会再生成部分了。
- 高级用法-软控制
可以直接在用户输入中添加 "/think"和“/no_think”来实现,比如:
参考:
3.qwen3.0 post-train的四个阶段
- 长思维链冷启动:使用math、code、long-cot、STEM等问题做全参SFT,让LLM具备基础的推理能力。
- 长思维链强化学习:利用基于规则的奖励增强模型的探索和钻研能力。
- 思考模式融合:同时使用长思维链数据和常用的指令微调数据对模型进行微调,将非思考模式整合到思考模式中,实现混合思考的能力。
- 通用强化学习:在指令遵循、格式遵循和Agent能力等20多个通用领域的任务上做强化学习,以进一步增强模型的通用能力并纠正不良行为。
