自用华为ICT云赛道AI第三章知识点-AI应用开发流程
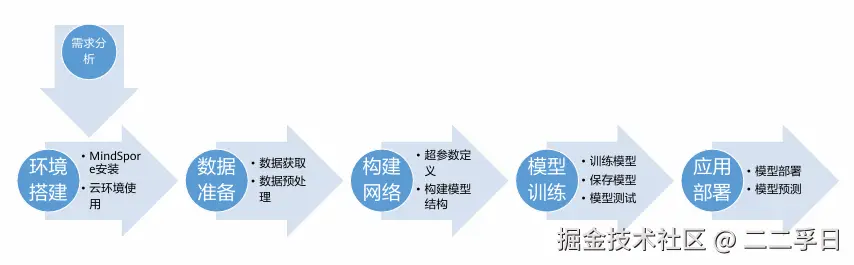
AI应用开发流程
ResNet50图像分类应用
- 图像分类是最基础的计算机视觉应用,属于有监督学习类别,如给定一张图像(猫、狗飞机、汽车等),判断图像所属的类别。本应用将介绍使用ResNet50网络对花卉数据集进行分类。

环境搭建
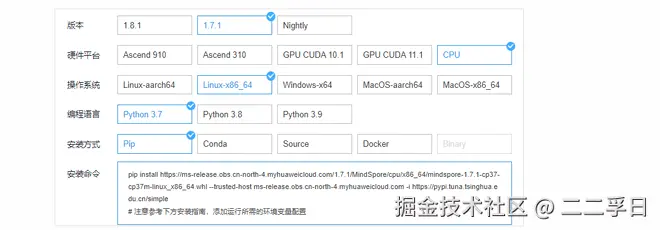
- 在选择适合自己的环境条件后,获取命令并按照指南进行安装。
- 如:在Linux、Python37中安装1.7.1的CPu版本,安装方式为pip:
云环境准备(可选)
- 若当前无可用环境,可以使用云平台ModelArts进行开发、模型训练或部署。
- ModelArts帮助用户快速创建和部署模型,管理全周期AI工作流。
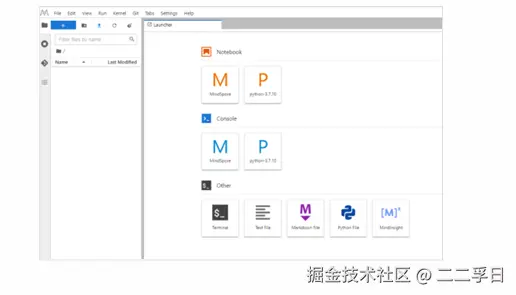
- 云环境相较于本地环境提供了充足的算力和存储空间,是开发过程中一个较好的选择。
数据准备
- 训练数据使用的是图像花卉数据集,该数据集是开源数据集,总共包括5种花的类型:分别是daisy(雏菊,633张),dandelion(蒲公英,898张),roses(玫瑰,641张),sunflowers(向日葵,699张),tulips(郁金香,799张),保存在5个文件夹当中,总共3670张。在这里分成了flower_photos_train和flower_photos_test两部分。

数据预处理
- 为了提升模型的准确率及保证模型的泛化能力,在使用数据训练模型前,通常会对数据做数据增强、标准化等操作。
- 在此处,通过定义函数read_dataset,来实现数据集的加载,包括以下功能:
- 读取数据集。
- 定义进行数据增强和处理所需要的一些参数。
- 根据参数,生成对应的数据增强操作。
- 使用map映射函数,将数据操作应用到数据集。
- 对生成的数据集进行处理。
- 对处理好的数据进行样例展示。
- 此次应用所使用的是开源数据集,所以不需要对数据集本身做太多处理。如果使用的数据是收集的相关业务数据,还需要对数据做清洗和整理等操作。
数据集处理API介绍

- mindspore.dataset.vision:此模块用于图像数据增强,包括c_transforms 和py_transforms两个子模块。c_transforms是使用 C++ OpenCv开发的高性能图像增强模块。py_transforms是使用PythonPillow开发的图像增强模块。
- mindspore.dataset.text:此模块用于文本数据增强,包括 transforms和utils两个子模块。
- transforms是一个高性能文本数据增强模块,支持常见的文本数据增强处理。
- utils提供了一些文本处理的工具方法。
- mindspore.dataset.audio:此模块用于音频数据增强,包括transforms和utils两个子模块。transforms是一个高性能音频数据增强模块,支持常见的音频数据增强操作。utils提供了一些音频处理的工具方法。
数据预处理代码实现

定义超参数
- 模型中不但有参数,还有超参数的存在。其目的是为了让模型能够学习到最佳的参数。

ResNet网络介绍
- ResNet50网络是2015年由微软实验室的何恺明提出,获得ILSVRC2015图像分类竞赛第一名。
- 残差网络结构(ResidualNetwork)是ResNet网络的主要亮点,ResNet使用残差网络结构后可有效地减轻退化问题,实现更深的网络结构设计。

网络结构API介绍
- mindspore.nn,神经网络Cell,用于构建神经网络中的预定义构建块或计算单元。
- mindspore.nn.Cell,MindSpore的Cell类是构建所有网络的基类,也是网络的基本单元。
- mindspore.nn.LossBase,损失函数的基类。
- 神经网络结构API:
- mindspore.nn.Dense(in_channels, out_channels, weight_init='normal', bias_init='zeros',has_bias=True, activation=None):全连接层。
- in_channels (int),Dense层输入Tensor的空间维度。
- out_channels (int),Dense层输出Tensor的空间维度。
- weight_init,权重参数的初始化方法。
- 在MindSpore中,自定义网络结构、损失函数等可以通过继承对应的父类来快速创建。
- mindspore.nn.Conv2d: (in_channels, out_channels, kernel_size, stride=1,pad_mode="same", padding=0, dilation=1, group=1, has_bias=False, weight_init="normal”",bias_init="zeros”,data_format="NCHw”):二维卷积层。
- kerneL_size,指定二维卷积核的高度和宽度。
- stride,二维卷积核的移动步长。
- pad_mode,指定填充模式。可选值为”same”、”valid”、”pad”。默认值:”same”。
- mindspore.nn.MaxPool2d(kernel_size=1, stride=1, pad_mode='valid',data_format='NCHW'):二维最大池化层。
- mindspore.nn.RNN(*args,**kwargs):循环神经网络(RNN)层,其使用的激活函数为tanh或relu。
- input_size(int)-输入层输入的特征向量维度。
- hidden_size(int)-隐藏层输出的特征向量维度。
- num_layers (int) -堆叠RNN的层数。默认值:1。
- mindspore.nn.Dropout(keep_prob=0.5, dtype=mstype.float32):根据丢弃概率1-keep_prob,在训练过程中随机将一些神经元输出设置为0。
- keep_prob(float) -输入神经元保留率,数值范围在o到1之间。
- mindspore.nn.ReLU:修正线性单元激活函数。
- mindspore.nn.Softmax(axis=-1):Softmax激活函数
MindSpore构建网络
- 构建神经网络时,需要继承Cell类,并重写_init_方法和construct方法。

- MindSpore中神经网络的基本构成单元为nn.Cell。模型或神经网络层应当继承该基类。基类的成员函数construct是定义要执行的计算逻辑,所有继承类都必须重写此方法。
模型训练
- 完成数据预处理、网络模型构建等步骤之后,开始模型训练。
- 模型训练可以简单的分为两种形式:
- 直接基于自身数据集从零开始训练,适用于自身数据量较多,且训练资源充足的情况;
- 基于一个训练好的模型,在自身数据集上进行微调训练。适用于数据量较少的情况(本次使用)。
- 预训练模型:ImageNet数据集上训练好的ResNet模型文件。
- 修改预训练模型参数的最后一层参数(预训练模型是在ImageNet数据集上训练的1001分类任务,而任务是实现flowers数据集的5分类任务)。
- 基于自身训练集进行训练。
- 调参:训练时可以通过调整不同的超参数组合。
训练API介绍
- mindspore.Model(network,loss_fn=None,optimizer=None,metrics=None,eval_network=None,eval_indexes=None, amp_level="Oo",boost_level="Oo",**kwargs):Model会根据用户传入的参数封装可训练或推理的实例。
- network(Cell)-用于训l练或推理的神经网络。
- loss_fn (Cell) - 损失函数。
- optimizer(Cell)-用于更新网络权重的优化器。
- metrics(Union[dict,set])-用于模型评估的一组评价函数。
模型保存与加载

- 训练网络模型的过程中,实际上我们希望保存中间和最后的结果,用于微调(fine-tune)和后续的模型部署和推理。且当模型过于庞大时,需要边训练边保存。
- 第二种保存方式首先需要初始化一个CheckpointConfig类对象,用来设置保存策略。
- save_checkpoint_steps表示每隔多少个step保存一次。
- keep_checkpoint_max表示最多保留CheckPoint文件的数量。
- prefix表示生成CheckPoint文件的前缀名。
- directory表示存放文件的目录。
- 创建一个ModelCheckpoint对象把它传递给model.train方法,就可以在训练过程中使用CheckPoint功能了。
模型加载与预测
- 通过训练好的模型权重,调用model.predict(*predict_data)对测试数据进行测试。
- 训练完成后直接调用model.predict预测。
- 加载权重文件后进行预测。
- 要加载模型权重,需要先创建相同模型的实例,然后使用load_checkpoint和load_param_into_net方法加载参数。
- load_checkpoint方法会把参数文件中的网络参数加载到字典param_dict中。
- load_param_into_net方法会把字典param_dict中的参数加载到网络或者优化器中,加载后,网络中的参数就是CheckPoint保存的。

模型部署
- 移动端部署(以手机为例):
- 将CKPT文件转化为MindIR文件格式,再转换成Android手机上MindSporeLite可识别文件(ms模型文件);
- 在手机侧部署应用APK,即下载一个MindSporeVision套件AndroidAPK;
- 最后将ms模型文件导入到手机侧。
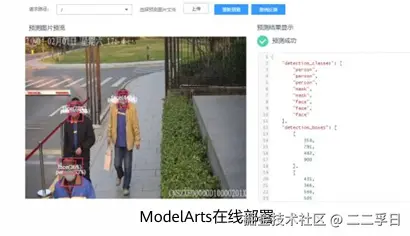
- 云端部署:
- 通过MindSpore Serving部署在云服务中。
- 基于ModelArts快速部署在云端。
- 基于AscendCL、Atlas计算平台实现部署。
- 由于移动端算力不足问题,需要考虑模型的大小和计算量。


