自用华为ICT云赛道AI第二章知识点-神经网络类型
卷积神经网络
- 卷积神经网络(ConvolutionalNeuralNetwork,CNN)是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的单元,对于图像处理有出色表现。它包括卷积层(convolutional layer),池化层(pooling layer)和全连接层(fully connected layer)。
- 20世纪60年代,Hubel和Wiesel在研究猫脑皮层中用于局部敏感和方向选择的神经元时发现其独特的网络结构可以有效地降低反馈神经网络的复杂性,继而提出了卷积神经网络(Convolutional Neural Networks-简称CNN)。
- 现在,CNN已经成为众多科学领域的研究热点之一,特别是在模式分类领域,由于该网络避免了对图像的复杂前期预处理,可以直接输入原始图像,因而得到了更为广泛的应用。
- 对图像(不同的数据窗口数据)和滤波矩阵(一组固定的权重:因为每个神经元的权重固定,所以又可以看做一个恒定的滤波器filter(kernel))做内积(逐个元素相乘再求和)的操作就是所谓的卷积操作,也是卷积神经网络的名字来源。
- 局部感知,一般认为人对外界的认知是从局部到全局的,而图像的空间联系也是局部的像素联系较为紧密,而距离较远的像素相关性则较弱。因而,每个神经元其实没有必要对全局图像进行感知,只需要对局部进行感知,然后在更高层将局部的信息综合起来就得到了全局的信息。网络部分连通的思想,也是受启发于生物学里面的视觉系统结构。视觉皮层的神经元就是局部接受信息的(即这些神经元只响应某些特定区域的刺激)。
- 参数共享,对输入的照片,用一个或者多个filter扫描照片,filter自带的参数就是权重,在同一个filter扫描的图层当中,每个filter使用同样的参数进行加权计算。权值共享意味着每一个过滤器在遍历整个图像的时候,过滤器的参数(即过滤器的参数的值)是固定不变的,比如我有3个特征过滤器,每个过滤器都会扫描整个图像,在扫描的过程中,过滤器的参数值是固定不变的,即整个图像的所有元素都“共享”了相同的权值。
卷积神经网络核心思想
- 局部感知:一般认为,人对外界的认知是从局部到全局的,而图像的空间联系也是局部的像素联系较为紧密,而距离较远的像素相关性则较弱。因而,每个神经元没有必要对全局图像进行感知,只需要对局部进行感知,然后在更高层将局部的信息综合起来就得到了全局的信息。
- 参数共享:对输入的图片,用一个或者多个卷积核扫描照片,卷积核自带的参数就是权重,在同一个卷积核扫描的图层当中,每个卷积核使用同样的参数进行加权计算。权值共享意味着每一个卷积核在遍历整个图像的时候,卷积核的参数是固定不变的。
卷积神经网络架构
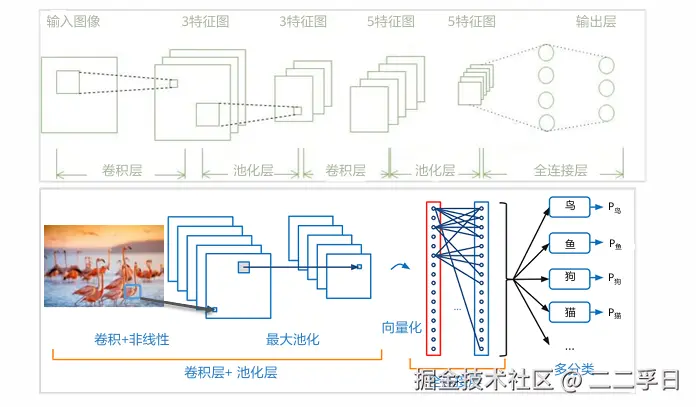
- 输入层,用于数据的输入。
- 卷积层(Convolutionallayer),卷积神经网路中每层卷积层由若干卷积单元组成,每个卷积单元的参数都是通过反向传播算法优化得到的。卷积运算的目的是提取输入的不同特征,第一层卷积层可能只能提取一些低级的特征如边缘、线条和角等层级,更多层的网络能从低级特征中选代提取更复杂的特征。
- 线性整流层(Rectified Linear Units layer,ReLU layer),这一层神经的活性化函数(Activation function)使用线性整流(Rectified Linear Units, ReLU)f(x)=max(0,x)。
- 池化层(Poolinglayer),通常在卷积层之后会得到维度很大的特征,将特征切成几个区域,取其最大值或平均值,得到新的、维度较小的特征。
- 全连接层(Fully-Connected layer),把所有局部特征结合变成全局特征,用来计算最后每一类的得分。
- 输出层,用于输出最终结果。
单卷积核计算
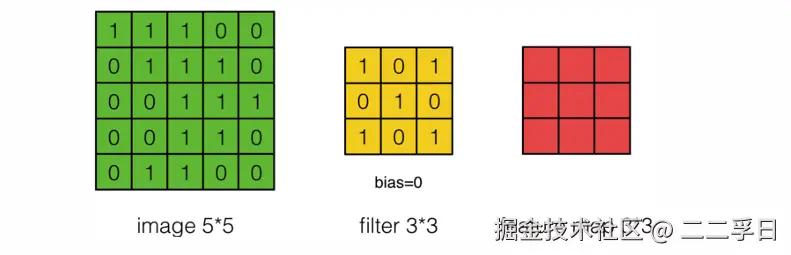
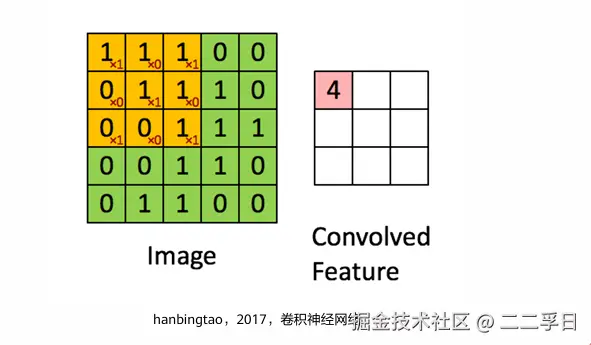
卷积层
- 卷积神经网络的基本结构,就是多通道卷积(由多个单卷积构成)。上一层的输出(或者第一层的原始图像),作为本层的输入,然后和本层的卷积核卷积,作为本层输出。而各层的卷积核,就是要学习的权值。和全连接层类似,卷积完成后,输入下一层之前,也需要经过偏置和通过激活函数进行激活。
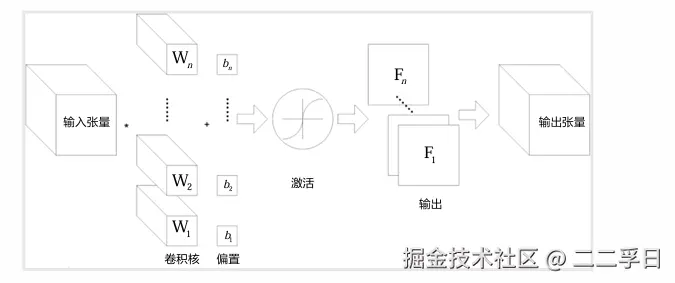
池化层
- 池化(Pooling),它合并了附近的单元,减小了下层输入的尺寸,起到降维的作用。常用的池化有最大池化(MaxPooling)和平均池化(AveragePooling),顾名思义,最大池化选择一小片正方形区域中最大的那个值作为这片小区域的代表,而平均池化则使用这篇小区域的均值代表之。这片小区域的边长为池化窗口尺寸。下图演示了池化窗口尺寸为2的一般最大池化操作。
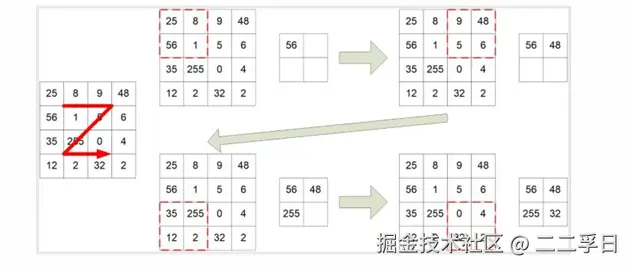
- 实际的分类网络,基本上都是卷基层和Pooling层交替互联,形成的前馈网络。Pooling层有如下作用:
- 不变性:MaxPooling在一定范围内保证了不变性,因为一片区域的最大值无论在这篇区域的何处,最后输出都是它。
- 减小下一层输入大小:Pooling有效降低了下一层输入数据的尺寸,减少了参数个数,减小了计算量。
- 获得定长数据:通过合理设置Pooling的窗口尺寸和Stride,可以在变长输入中得到定长的输出。
- 增大尺度:相当于扩大了尺度,可以从更大尺度上提炼上一层的特征。
- 防止过拟合:Pooling简化了网络,降低了拟合的精度,因此可以防止过拟合(注意有可能带来的欠拟合)。
全连接层
- 全连接层实质上就是一个分类器,将前面经过卷积层与池化层所提取的特征,拉直后放到全连接层中,输出结果并分类。
- 通常我们使用Softmax函数作为最后全连接输出层的激活函数,把所有局部特征结合变成全局特征,用来计算最后每一类的得分。
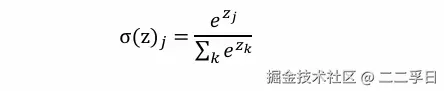
循环神经网络
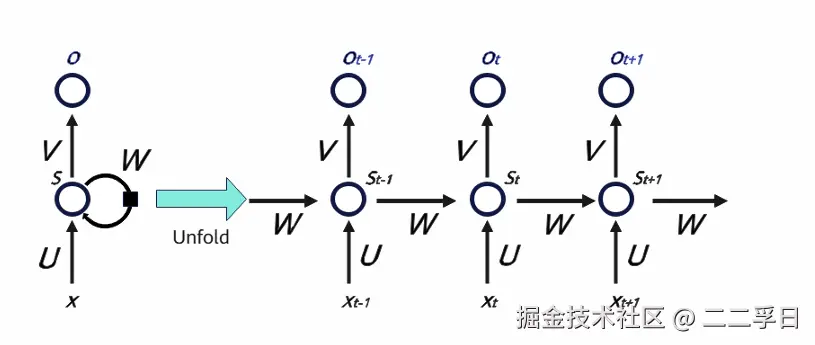
- 循环神经网络(Recurrentneuralnetworks,简称RNN)是一种通过隐藏层节点周期性的连接,来捕捉序列化数据中动态信息的神经网络,可以对序列化的数据进行分类。
- 和其他前向神经网络不同,RNN可以保存一种上下文的状态,甚至能够在任意长的上下文窗口中存储、学习、表达相关信息,而且不再局限于传统神经网络在空间上的边界,可以在时间序列上有延拓,直观上讲,就是本时间的隐藏层和下一时刻的隐藏层之间的节点间有边。
- RNN广泛应用在和序列有关的场景,如如一帧帧图像组成的视频,一个个片段组成的音频,和一个个词汇组成的句子。
循环神经网络架构

循环神经网络类型

时序反向传播(BPTT)
- 时序反向传播(BPTT):
- 传统反向传播(BP)在时间序列上的拓展
- 在t时序记忆单元的误差有两个来源,分别是t时序误差Ct对记忆单元的偏微分和记忆单元在下一个时序t+1的误差对t时
- 序记忆单元的偏微分,需要将两者相加
- 时序越长,最后一个时序的损失对第一个时序中w的梯度越容易出现梯度消失或梯度爆炸现象
- 某个权重w的梯度是该权重在所有时序上梯度的累加
- BPTT的三个步骤:
- 前向计算每个神经元的输出值
- 反向计算每个神经元的误差值&j
- 计算每个权重的梯度
- 最后使用随机梯度下降算法更新权重。
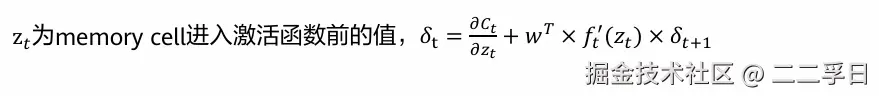
循环神经网络问题

长短记忆性网络
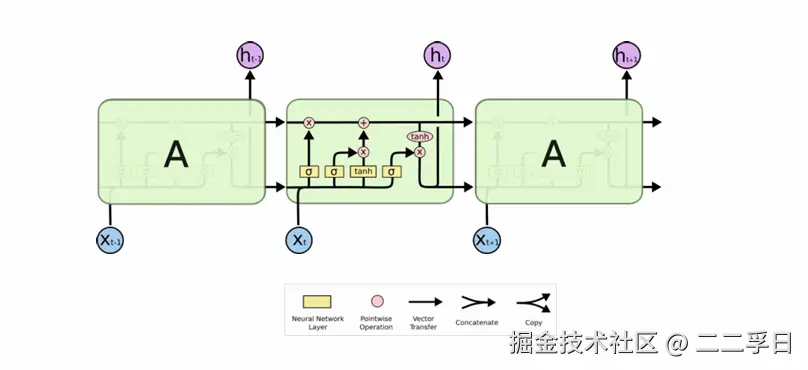
LSTM核心知识点:遗忘门
- LSTM中的第一步是决定从细胞状态中丢弃什么信息。
- 这个决定通过遗忘门完成。该门会读取ht-1和xt,输出一个在0到1之间的数值给每个在细胞状态Ct-1中的数字。1表示“完全保留”,0表示“完全舍弃”。
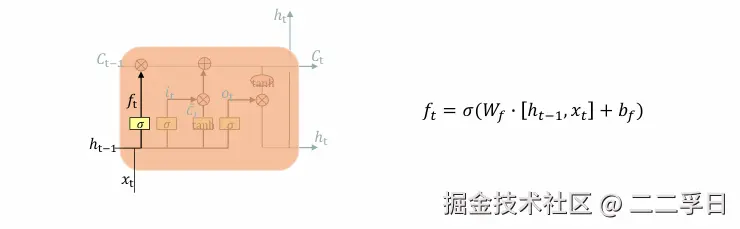
LSTM核心知识点:输入门
- 这一步确定什么样的新信息被存放在细胞状态中。
- 这里包含两个部分:
- Sigmoid层称“输入门层”决定什么值将要更新;
- 一个tanh层创建一个新的候选值向量,会被加入到状态中。
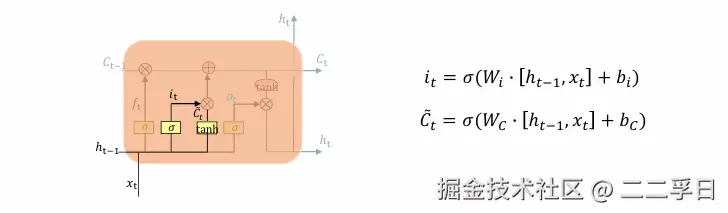
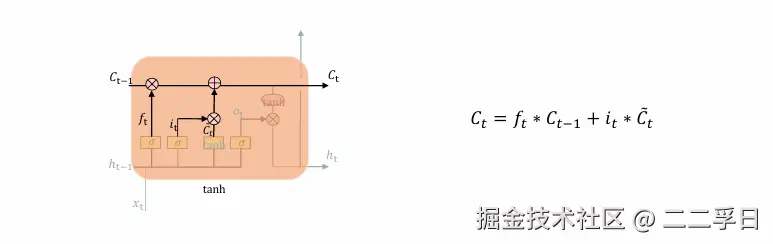
LSTM核心知识点:更新信息
- 更新I旧细胞状态的时间:Ct-更新为Ct。
- 我们把旧状态与f相乘,丢弃掉我们确定需要丢弃的信息。接着加上it*Ct。这就是新的候选值,根据我们决定更新每个状态的程度进行变化。
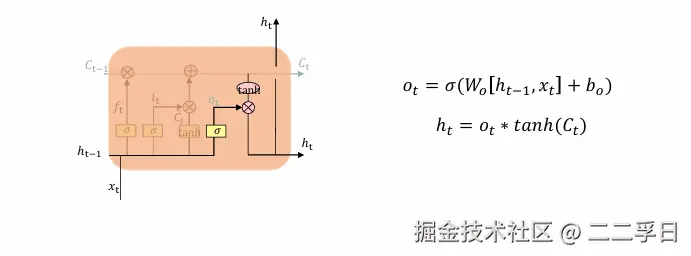
LSTM核心知识点:输出门
- 运行一个Sigmoid层来确定细胞状态的哪个部分将输出出去。
- 接着,细胞状态通过tanh进行处理(得到一个在-1到1之间的值)并将它和Sigmoid门的输出相乘,最终我们仅仅会输出我们确定输出的那部分。