自用华为ICT云赛道AI第二章知识点-深度学习优化器
优化器
- 在梯度下降算法中,有各种不同的改进版本。在面向对象的语言实现中,往往把不同的梯度下降算法封装成一个对象,称为优化器。
- 算法改进的目的,包括但不限于:
- 加快算法收敛速度;
- 尽量避过或冲过局部极值;
- 减小手工参数的设置难度,主要是Learning Rate(LR)。
- 常见的优化器如:普通GD优化器、动量优化器、Nesterov、Adagrad、Adadelta、RMSprop、Adam、AdaMax、Nadam。
动量优化器


动量优化器优缺点
- 动量优化器的优点是:
- 增加了梯度修正方向的稳定性,减小突变。
- 在梯度方向比较稳定的区域,小球滚动会越来越快(当然,因为α<1,其有一个速度上限),这有助于小球快速冲过平坦区域,加快收敛。
- 带有惯性的小球更容易滚过一些狭窄的局部极值。
- 动量优化器的缺点是:
- 学习率n以及动量α仍需手动设置,这往往需要较多的实验来确定合适的值。
Adagrad优化器
- 随机梯度下降算法(SGD)、小批量梯度下降算法(MBGD)、动量优化器的共同特点是:对于每一个参数都用相同的学习率进行更新。
- Adagrad的思想则是应该为不同的参数设置不同的学习率。

- 从Adagrad优化算法中可以看出,随着算法不断迭代,r会越来越大,整体的学习率会越来越小。这样做的原因是随着更新次数的增大,我们希望学习率越来越慢。因为我们认为在学习率的最初阶段,我们距离损失函数最优解还很远,随着更新次数的增加,越来越接近最优解,所以学习率也随之变慢。
- 优点:
- 范学习率自动更新,随着更新次数增加,学习率随之变慢。
- 缺点:
- 分母会不断累积,最终学习率变得非常小,算法会失去效用。
RMSprop优化器
- RMSprop优化器是一种改进的Adagrad优化器,通过引入一个衰减系数,让r每回合都衰减一定的比例。
- RMSprop优化器很好的解决了Adagrad优化器过早结束的问题,很合适处理非平稳目标,对于RNN网络效果很好。


Adam优化器
- Adam(Adaptive Moment Estimation):是从Adagrad、Adadelta上发展而来,Adam为每个待训练的变量,维护了两个附加的变量mt和vt:
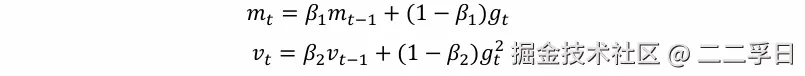
- 其中t表示第t次迭代,gt是本次计算出的梯度,从形式上来看m﹝和v分别是梯度和梯度平方的移动均值。从统计意义上看,m﹝和v是梯度的一阶矩(均值)和二阶矩(非中心方差)的估计,因此而得名。



