自用华为ICT云赛道AI第二章知识点-深度学习正则化
正则化
过拟合问题
- 过拟合问题描述:模型在训练集表现优异,但在测试集上表现较差。
- 根本原因:特征维度过多,模型假设过于复杂,参数过多,训练数据过少,噪声过多,导致拟合出的函数几乎完美的对训练集做出预测,但对新数据的测试集预测结果差。过度的拟合了训练数据,而没有考虑到模型的泛化能力。
- 过拟合主要是有两个原因造成的:数据太少+模型太复杂:在深度学习中,经常出现的问题是,训练数据量小,模型复杂度高,这就使得模型在训练数据上的预测准确率高,但是在测试数据上的准确率低,这时就是出现了过拟合。
- 获取更多数据:从数据源头获取更多数据;数据增强(DataAugmentation)。
- 使用合适的模型:减少网络的层数、神经元个数等均可以限制网络的拟合能力。
- dropout 。
- 正则化,在训练的时候限制权值变大。
- 限制训练时间;通过评估测试。
- 增加噪声Noise:输入时+权重上(高斯初始化)。
- 数据清洗(datackeaning/Pruning):将错误的label纠正或者删除错误的数据。
- 结合多种模型:Bagging用不同的模型拟合不同部分的训练集;Boosting只使用简单的神经网络。
正则化
- 正则化是机器学习中非常重要并且非常有效的减少泛化误差的技术,特别是在深度学习模型中,由于其模型参数非常多非常容易产生过拟合。因此研究者也提出很多有效的技术防止过拟合,比较常用的技术包括:
- 参数添加约束,例如L1、L2范数等。
- 训练集合扩充,例如添加噪声、数据变换等。
- Dropout
- 提前停止
参数惩罚

L1正则


L2正则


L2 VS L1
- L2与L1的主要区别如下:
- 通过上面的分析,L1相对于L2能够产生更加稀疏的模型,即当L1正则在参数w比较小的情况下,能够直接缩减至0,因此可以起到特征选择的作用。
- 如果从概率角度进行分析,很多范数约束相当于对参数添加先验分布,其中L2范数相当于参数服从高斯先验分布;L1范数相当于拉普拉斯分布。
数据增强
- 防止过拟合最有效的方法是增加训练集合,训练集合越大过拟合概率越小。数据增强是一个省时有效的方法,但是在不同领域方法不太通用。
- 在目标识别领域常用的方法是将图片进行旋转、缩放等(图片变换的前提是通过变换不能改变图片所属类别,例如手写数字识别,类别6和9进行旋转后容易改变类目)。
- 语音识别中对输入数据添加随机噪声。
- NLP中常用思路是进行近义词替换。
提前停止训练
- 在训练过程中,插入对验证集数据的测试。当发现验证集数据的Loss上升时,提前停止训练。
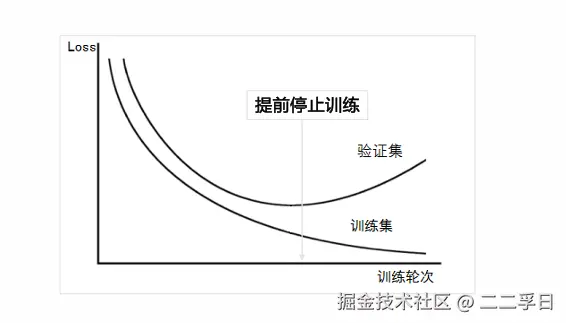
- 我们往往会设置一个比较大的迭代次数n。首先我们要保存好现在的模型(网络结构和权值),训练num_batch次(即一个epoch),得到新的模型。将测试集作为新模型的输入,进行测试。如果我们发现测试误差比上次得到的测试误差大,我们并不会马上终止测试,而是再继续进行几个epoch的训练与测试,如果测试误差依旧没有减小,那么我们就认为该试验在上一次达到最低测试误差时停下来训练模型时,
- 一般的做法是记录到目前为止最好的测试集准确率p,之后连续m个周期没有超过最佳测试集准确率p时,则可以认为p不再提高了,此时便可以提前停止迭代(Early-Stopping)。
- 从图中可以看出,测试误差在前几个epoch中逐渐减小,但是训练到某个epoch后,测试误差又有了小幅度的增大。这说明此时发生了过拟合。
- 发生过拟合是我们所不愿意看见的,我们可以利用提前终止(earlystopping)来防止过拟合的发生。
- 提前终止是指:在测试误差开始上升之前,就停止训练,即使此时训练尚未收敛(即训练误差未达到最小值)。
Dropout
- Dropout是一类通用并且计算简洁的正则化方法,在2014年被提出后广泛的使用。简单的说,Dropout在训练过程中,随机的丢弃一部分输入,此时丢弃部分对应的参数不会更新。相当于Dropout是一个集成方法,将所有子网络结果进行合并,通过随机丢弃输入可以得到各种子网络。如图:
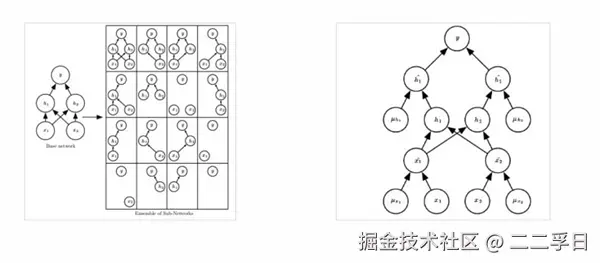
- 在每一轮的样本输入到神经网络进行训练时,设定一个概率p,使得每个神经元有一定的概率死亡,不参与网络的训练。
- 其流程为:1.首先以一定的概率p随机删除掉网络隐藏层中的神经元(暂时死亡),输入输出神经元保持不变。2.然后把输入x通过修改后的网络前向传播,把得到的损失结果通过修改的网络反向传播。一小批训练样本执行完这个过程后,在没有被删除的神经元上按照随机梯度下降法更新对应的参数(w,b)。3.然后继续重复这一过程:恢复被删掉的神经元(此时被删除的神经元保持原样,而没有被删除的神经元已经有
- 所更新)从隐藏层神经元中随机选择一个一半大小的子集临时删除掉(备份被删除神经元的参数)。对一小批训练样本,先前向传播然后反向传播损失并根据随机梯度下降法更新参数(w,b)(没有被删除的那一部分参数得到更新,删除的神经元参数保持被删除前的结果)。
- 原始输入每一个节点选择概率0.8,隐藏层选择概率为0.5。
- Dropout的优点:
- 相比于weight decay、范数约束等,该策略更有效。
- 计算复杂度低,实现简单而且可以用于其他非深度学习模型。
- 但是当训练数据较少时,效果不好。
- Dropout训练过程中的随机过程不是充分也不是必要条件,可以构造不变的屏蔽参数,也能够得到足够好的解。
- 除上述的方法以外,还有半监督学习、多任务学习、提前停止、参数共享、集成化方法、对抗训练等方法。
数据不平衡问题
- 问题描述:在分类任务的数据集中,各个类别的样本数目不均衡,出现巨大的差异,预测的类别里有一个或者多个类别的样本量非常少。
- 比如:图像识别实验中,在4251个训练图片中,有超过2000个类别中只有一张图片。还有一些类中有2-5个图片。
- 导致问题:
- 对于不平衡类别,我们不能得到实时的最优结果,因为模型/算法从来没有充分地考察隐含类。
- 它对验证和测试样本的获取造成了一个问题,因为在一些类观测极少的情况下,很难在类中有代表性。
- 随机欠采样
- 随机过采样
- 合成采样


