

前言
随着「Deep Research」类功能正在产出越来越多有价值的研究报告、越来越强的 Coding Agent 被开发者认定能解决真实的开发问题,开发 AI Agent 程序,或对已有程序进行 Agentic 改造,已经被越来越多人所接受,认为这是提升 AI 应用性能的可行方向。
但在很多人还在理解什么是 Agent、摸索如何构建 Agent 的时候,Multi-Agent 的概念又开始被各类开发框架和厂商大量提及。直到近期 Anthropic 和开发了 Devin 智能体的 Cognition 分别发布了支持与反对 Multi-Agent 的热门博客,大家对 Multi-Agent 有效性的质疑也达到了新的高峰。
在接下来的文章中,我们会拆解高效构建 Agent 的几个要素,再进一步分析 Multi-Agent 在什么时候可以解决问题、如何解决问题,并最终发现 Anthropic、Cognition 以及各方观点实际上都能达成一致。
从 Single-Agent 说起
Agent/Agentic 为什么能提升性能
显然我们不能仅从 Deep Research、Coding Agent 等应用有良好的性能且它们都使用了 Agent 架构,就简单地推断 Agent 架构一定带来性能提升。
事实上,Anthropic 的博客中提出了一个重要的概念:token 的扩展性问题。简单来说,当以解决问题为目的与 LLM 对话时,随着 LLM 输出的 token 越多,如果问题得到了更好的解决,那么此时 token 的扩展性良好;反之如果问题的解决进度停滞不前,那么就遇到了 token 的扩展性瓶颈。
我们可以通过一个例子来进一步理解:
用户:解决这道数学题:...
LLM:我的思路是:...,答案是:...
用户:不对,再想想
LLM:好的,我换一个思路:...,答案是:...
用户:还是不对,再想想
LLM:好的,我再换一个思路:...,答案是:...
如果实际进行过这样的对话,大家应该会发现通常的结果是 LLM 在后续轮次中很难因为用户让它重新思考,就解决问题。同样的,早期一些加入让 LLM「非常努力、使劲工作」等提示词的理论,现如今也不再被大家视为有效的性能提升方法。
原因就是此时 LLM 已经遇到了 token 的扩展性瓶颈,不提供额外的信息,仅依靠 LLM 内部的知识,无法将解决问题的进度继续向前推进。但相应的,如果能提供一些有效的额外信息,例如数学题中提供正确答案,让 LLM 解析思路;或是编程场景中,提供编译错误让 LLM 重新修正代码,往往都能有效推进问题的解决。
这样就是 Agent 架构有效的根源,通过向 LLM 提供一组「获取有效额外信息的工具(tools)」,并引导 LLM 在问题尚未解决时使用 tools 获取额外信息,就突破了由信息不足导致的 token 的扩展性瓶颈。
本文中的 Agent 架构的技术定义
由于 Agent 一词已经被广泛甚至过多的使用在各种语境中,在本文我们延续上述思路,将 Agent 架构的技术定义具体为:
-
在与 LLM 对话时,提供一组 tools 供 LLM 使用
-
每一轮对话中,是否使用 tools、使用哪个 tool,由 LLM 决策
-
tool 提供额外信息之后,对话自动继续,形成多轮对话
-
与 LLM 的对话将持续进行,直到用户的原始问题得到解决、用户决定终止或程序判定问题不可能得到解决。
Agent 的几个要素
在描述 Agent 架构时,常见的说法是「与 LLM 不断对话的 while 循环」就可以是一个 Agent。
事实确实如此,不过我们可以进一步展开 Agent 内部的逻辑:
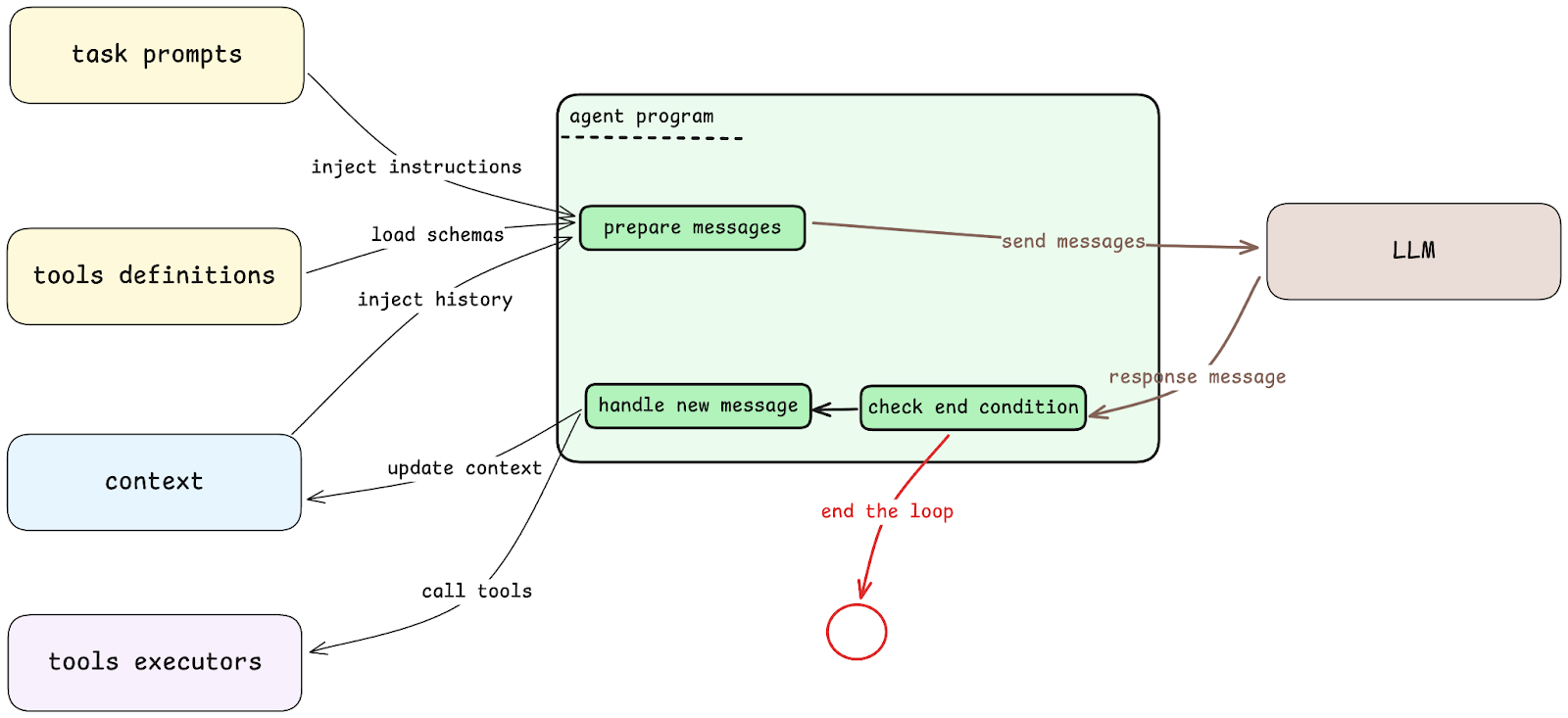
在 Agent 向 LLM 发送消息时,发出的内容实际上由几部分共同组成:
-
task prompts:用于描述如何解决问题的提示词。其中通常包括对问题常见解法的描述、tools 的使用建议、输出内容的格式要求等。
-
tools definition:也就是我们提到的 tools,不过输入给 LLM 的信息仅包括这些工具的 schema,而不包含实际的执行能力。因为 LLM 只需要决策下一步执行哪个工具、参数是什么即可,具体的执行在 Agent 程序中完成。
-
context:因为 Agent 会与 LLM 进行多轮对话,因此需要将多轮对话的内容记录为上下文,提供给下一轮对话,让 LLM 在每一次对话中都理解「前因后果」。
当 LLM 返回消息时,会依次执行两个流程。
首先需要判断终止条件是否已经达成,也就是我们上文提到的,问题是否得以解决,或问题是否判定无法自动解决。
如果判定终止条件未达成,则继续处理 LLM 返回的新消息:
-
tools executors:如果新的消息中包含对工具的调用决策,那么 Agent 根据选择的工具与参数,进行实际执行。
-
新的消息也需要加入上下文中,作为下一轮对话的基础。
新的 token 扩展性瓶颈
虽然 Agent 架构通过使用工具获取额外有效信息,突破了一次 token 扩展性瓶颈。但由于 LLM 自身的能力限制,Agent 架构也会遇到新的 token 扩展性瓶颈。
我们同样从 Agent 的几个要素逐一分析:
-
task prompts:当 LLM 的指令跟随能力不足时,提示词包含的流程、细节过多,LLM 容易忽略或不严格遵守,导致问题解决进度没有按预期持续深入,反而因为持续的错误决策,进度停滞。
-
tools definitions:同样地,当一个复杂问题需要大量 tools 参与时,tools 的数量过多、参数过多,超出 LLM 理解上限之后,也会因为没有调用预期的工具,导致进度停滞。
-
context:上下文是最明显的新的瓶颈。此处我们说的上下文是整个问题解决过程的真实上下文,当它较小时,我们可以将它完整传入 LLM 对话中,成为 LLM 对话上下文。但当问题解决轮次不断增多,真实上下文很可能超出 LLM 对话上下文,这时候 Agent 程序就需要基于特定的规则从真实上下文中挑选部分信息,作为 LLM 对话上下文。但如果未被挑选的信息是解决问题依赖的有效信息,则进度很可能停滞。
由此可见,Agent 架构解决问题的思路是合理的,但 LLM 的能力不足会让 Agent 在更复杂的问题中失效。相应的,头部 LLM 每一代更新时都会优化指令跟随能力和上下文大小,目标也是让 Agent 失效的阈值更不容易被触达。
Multi-Agent 如何突破 token 扩展性瓶颈
在等待能力更强的 LLM 出现的同时,Multi-Agent 架构也被提出,目标是在 LLM 能力不变的前提下,突破 Agent 所遭遇的 token 扩展性瓶颈。
Multi-Agent 如何解决问题
Multi-Agent 架构的思路并不复杂,将 Single-Agent 中的各个要素,按照解决问题的不同步骤/阶段进行拆分,变为多个 Agent。
每个 Agent 将问题解决到一定阶段,或判定自己无法继续解决时,也触发终止条件,但不一定是彻底终止,而也可能是交给其他 Agent 继续处理。
拆分的目的是为了突破上文提到的瓶颈:
-
task prompts:通过拆分,拆分后的 Agent 提示词流程、细节变少,更不容易超出 LLM 理解能力上限。
-
tools definitions:同样通过拆分之后,每个 Agent 的 tools 数量理论上将小于等于总的 tools 数量,更不容易超出 LLM 理解能力上限。
-
context:通过拆分,每个 Agent 有自己独立的上下文,因此解决问题时可用的总上下文空间变为了多个 Agent 上下文空间之和,再减去 Agent 交接时额外重复传递的上下文。
除去突破 token 扩展性瓶颈,Multi-Agent 在 LLM 自身的选择上也存在额外的优势。多个 Agent 可以选择不同的 LLM,这能够:
-
避免单个 LLM 能力不够多样的局限性。例如一个问题需要通过音频、视频的多模态输入,最终要生成图片作为结果,但如果没有单一 LLM 同时具备多模态输入和图片生成能力,Single-Agent 就无法完成任务。而 Multi-Agent 可以把不同 LLM 能力要求拆分至不同 Agent。
-
对拆分后任务较为简单的 Agent,选择性价比更好的 LLM 进行使用。
核心难点:context 拆分
在 Multi-Agent 架构中,task prompts、tools definitions、LLM 这几个要素获得的改进是明显的,且基本没有副作用。
但在 context 的拆分中,改进与副作用同样显著,且由于工程实现上的难度,副作用实际上可能会更为显著。
上文中我们已经解释过 Multi-Agent 架构下:总上下文空间 = 多个 Agent 上下文空间之和 - 交接时额外重复传递的上下文。
所以重复传递的上下文有多少,就决定了改进效果与副作用的大小。如果完全不重复传递,上下文空间提升最大,但因上下文缺失带来的准确性下降也最严重;反之如果完全重复传递,上下文空间无提升,但也没有准确性下降。
细化 Multi-Agent 拆分方式
因为 Agent 几个要素在进行 Multi-Agent 拆分时有着明显的差异,所以我们把唯一会因为拆分产生副作用的 context 单独拆出,形成两种 Multi-Agent 拆分方式。
对于拆分后,多个 Agent 完全共享上下文的拆分方式,我们称为 Multi-Agent-Single-Context。这种方式在除 context 之外的各个要素中,都获得了拆分带来的好处;在 context 中,与 Single-Agent 面临同样的瓶颈。
对于拆分后,多个 Agent 不完全共享上下文的拆分方式,我们称为 Multi-Agent-Multi-Context。这种方式可以在 context 层面突破 SIngle-Agent 的瓶颈,但会带来信息丢弃导致的准确率下降副作用,程度取决于信息丢弃的数量与内容。
细化拆分方式后,我们对于几种架构的选择逻辑也就变得明确了:
-
何时选择 Single-Agent
-
在各个要素上都没有遇到 token 的扩展性瓶颈。
-
单个 LLM 的能力(例如多模态输入输出)可以满足所有业务需求。
-
没有将现有较强 LLM 降级为较弱 LLM 优化成本的需求。
-
-
何时选择 Multi-Agent-Single-Context
-
在除 context 之外的要素上遇到了 token 的扩展性瓶颈。
-
单个 LLM 的能力不能满足所有的业务需求。
-
有较弱 LLM 能够稳定完成一部分子问题,需要将该部分拆出优化成本。
-
-
何时选择 Multi-Agent-Multi-Context
-
在 context 上遇到了 token 的扩展性瓶颈。
-
基于业务逻辑,验证了有效的信息丢弃规则,提升总上下文大小的同时,准确率下降幅度可接受。
-
context 是一个独立问题
需要注意的是,context 中的 token 扩展性瓶颈,并非只有拆分 Multi-Agent 这一种解决方法。
例如目前很多已被证明有效的 Agent(如 Github Copilot Agent 模式、Gemini CLI、Cursor 等)都会通过 LLM 定期总结上下文的方式,对 context 实现合并压缩。虽然这种压缩通常意味着大量有效信息也被丢弃,会带来明显的性能骤降,但也确实能够让 context 空间问题得到缓解。
这样的解决方式在 Single-Agent 架构中同样有效,而这也使得 Single-Agent 的适用范围变得更广。
后续我们也会在另一篇文章中单独分析目前常见的 context 瓶颈解决方式与选择逻辑。
重读业界观点
在完成上述分析之后,我们可以重新整理业界观点,读懂其中的「潜台词」,印证我们的分析结果。
热门文章解读
我们开篇提到的两篇热门文章,实际上讨论的都是 Multi-Agent-Multi-Context 这种最为复杂、理论潜力也最强的架构。
Anthropic 的《How we built our multi-agent research system》看似推崇 Multi-Agent,实则理性分析了 Multi-Agent 的局限性。核心观点如下:
-
强调 token 的扩展性出现问题时(例如因为 LLM 智力达到阈值,触发 task prmpts、tools definitions 瓶颈),才需要考虑 Multi-Agent。
-
指出 Multi-Agent 虽然能突破 token 的扩展性瓶颈,但用于传递上下文、重新获取丢弃信息时,会产生成倍的 token 消耗,要考虑目标问题的经济价值是否值得付出这些成本。
-
Multi-Context 带来的副作用是否能规避,很大程度上由业务逻辑决定。在文中他们的 Deep Research 系统中,Context 可以被拆分为「多个方向、广度优先的查询任务」,所以查询过程是比较容易识别的可丢弃信息,最终传递汇总的查询结果即可。
Cognition 的《Don’t Build Multi-Agents》看似极力反对 Multi-Agent,实则承认了 Single-Agent 的困境。核心观点如下:
-
在 Agent 几个要素中,context 对性能的影响是最显著的,也最容易遇到瓶颈。Cognition 的核心产品 Devin 是一个 Coding Agent,在该场景下 context 之外的因素几乎都不是瓶颈。
-
Single-Agent 简单有效,大部分时候已经可以走得很远。
-
context 瓶颈不一定需要 Multi-Agent 解决,例如可以用 LLM 定期总结压缩。
由此我们可以看出,两篇文章都没有错,结合他们具体的业务逻辑,两者的架构选择都是合理的。
框架、厂商逐鹿,苦了用户
在 Cognition 的文章中,还提到了他们编写文章的其中一个动机,就是认为微软的 Autogen、OpenAI 的 Swarm 等框架过于推崇 Multi-Agent 架构,带偏了用户。
查看一些强调 Multi-Agent 概念的开发框架和厂商的文档之后,我们发现确实存在营销过度的问题。例如在 Autogen 的文档中,简单地将 Multi-Agent 描述为可以提升性能的方法,但没有讲解能够提升的原因以及会引入的问题;在 crewai 的官网中,宣称有 5 亿以上 Multi-Agent crew 运行在平台中,但是关于 Multi-Agent 与 Single-Agent 的对比,只在论坛一个用户提问中给出了泛泛的简单解释;表现的更为理性的是 LangGrpah,文档中强调了 Multi-Agent 的适用前提是我们所说的几个要素遇到了瓶颈。
进一步对部分项目的代码进行了分析,我们发现许多强调 Multi-Agent 概念的框架,实际上提供的都是 Multi-Agent-Single-Context 的架构,来规避复杂的 context 拆分问题。
构建高效 Agent 有迹可循
在理解 Agent 的几个要素并细分了三种架构之后,再构建 Agent 之时,如何提升 Agent 性能也就有迹可循了。
在没有遇到明确问题之前,可以使用 Single-Agent 开发早期版本,降低工程复杂度。随着开发深入,如果遇到不同的瓶颈,则按照我们的架构选择逻辑进行切换。
除了 context 之外,task prompts、tools definitions 这些要素中同样也还有一些实用技巧,在各种架构下均能提升 Agent 性能,我们也会在后续的多篇文章中分别讲解。
各种技巧、解决方案在各种开源 Agent、开发框架中也有所体现。因此可以以此为目标去阅读开源 Agent 代码,分析它们使用了哪些可以借鉴的技巧。在选择开发框架时,也应该重点调研它提供了哪些要素的解决方案,是否与当前开发所遇到的问题相匹配。
