摘要
学习动态描述了特定训练样本的学习如何影响模型对其他样本的预测,为我们理解深度学习系统的行为提供了一个强大的工具。我们通过分析不同潜在响应之间影响如何逐步累积的分解过程,研究了大型语言模型在不同类型的微调过程中的学习动态。我们的框架使得对流行指令微调和偏好微调算法训练过程中的许多有趣现象进行统一解释成为可能。特别是,我们提出了一个假设性的解释,说明为什么特定类型的幻觉(hallucination)会在微调后得到加强,例如,模型可能会使用对问题B的回答中的短语或事实来回答问题A,或者模型在生成回答时可能会不断重复类似的简单短语。我们还扩展了我们的框架,并强调了一个独特的“挤压效应”(squeezing effect),以解释在离策略直接偏好优化(off-policy direct preference optimization, DPO)中之前观察到的一个现象,即运行DPO过长时间甚至会使期望的输出变得不那么可能。这个框架还提供了关于在线策略DPO和其他变体优势来源的见解。这种分析不仅为理解大型语言模型的微调提供了一个新的视角,还激发了一种简单而有效的方法来提高对齐性能。实验代码可在GitHub - Joshua-Ren/Learning_dynamics_LLM上找到。
1 引言
深度神经网络通常通过梯度下降(GD)更新其参数来获取新知识。这个过程可以通过学习动态来描述,学习动态将模型预测的变化与学习特定示例产生的梯度联系起来。借助学习动态,研究人员不仅解释了训练期间许多有趣的现象,例如“锯齿形”学习路径(Ren et al. 2022)和组合概念空间的形成(Park et al. 2024),而且利用这些见解提出了不同问题中的新颖、改进的算法(例如 Pruthi et al. 2020; Ren, S. Guo, et al. 2023; Xia et al. 2024)。
大型语言模型(LLM)的研究因其在各种任务上的惊人能力而越来越受欢迎。为了确保LLM遵循人类指令并与人类偏好保持一致,微调吸引了大量近期的关注。实践者通常从指令微调开始,模型学习执行下游任务所需的额外知识,然后进行偏好微调,模型将其输出与人类偏好对齐(Ouyang et al. 2022)。已经提出了各种微调算法来适应这一流程,对模型性能提升的原因有不同的解释。
与大多数现有的LLM微调分析相反,这些分析使用其训练目标、训练结束时的状态或它们与强化学习的关系(例如 Ji et al. 2024; Rafailoglu et al. 2024; Tajwar et al. 2024)的角度,本文试图从动态的角度理解LLM的演化。具体来说,我们通过将模型预测的变化分解为三个扮演不同角色的术语来形式化LLM微调的学习动态。这个框架可以很容易地适应到各种具有不同的目标微调算法上,包括有监督微调(SFT,Wei et al. 2022)、直接偏好优化(DPO,Rafailov et al. (2023),及其变体)甚至基于强化学习的微调方法(例如,PPO,Schulman et al. 2017)在内的各种微调算法,具有不同的目标。这个框架有助于解释训练期间的几个有趣且反直觉的观察结果——包括偏好微调后的“重复”现象(Holtzman et al. 2020)、幻觉(L. Huang et al. 2023)、在离策略DPO期间所有响应的置信度下降(Rafailov et al. 2024)等等。
此外,我们还提供了一个新的视角来理解为什么离策略DPO和其他变体的表现不如其在线策略的对应方法(S. Guo, B. Zhang, et al. 2024)。我们的解释从观察一个有趣的“挤压效应”开始,我们证明这是在DPO和类似算法中,模型在softmax层后使用交叉熵损失进行梯度上升的结果。简而言之,对于每个token的预测,负梯度会降低模型对(几乎)所有可能输出标签的预测,将这种概率质量转移到最可能的标签上。这可能对我们试图实现的对齐产生不利影响。当负梯度施加在一个已经不太可能的标签上时,这种影响最为严重,这也是为什么在离策略DPO期间几乎所有响应的置信度都会下降的原因。受此启发,我们提出了一种简单、反直觉但非常有效的方法来进一步提高对齐性能。
2 学习动态的定义和一个MNIST示例
学习动态通常是一个总称,描述特定因素的变化如何影响模型的预测。在本文中,我们将其缩小到描述“模型参数θ的变化如何影响相应fθ的变化”,即Δθ和Δfθ之间的关系。当模型使用梯度下降(GD)更新其参数时,我们有
Δθ≜θt+1−θt=−η⋅∇L(fθ(xu,yu));Δf(xo)≜fθt+1(xo)−fθt(xo),
其中θ在步骤t→t+1期间的更新由样本对(xu,yu)上的一个梯度更新给出,学习率为η。简而言之,本文中的学习动态解决了以下问题:
在xu上进行GD更新后,模型对xo的预测如何变化?
研究学习动态可以揭示深度学习中的许多重要问题,并有助于理解各种反直觉现象。附录A进一步讨论了相关工作。
作为热身,我们首先考虑一个标准的监督学习问题,其中模型学习将x映射到预测y={y1,…,yL}∈VL,其中V是大小为V的词汇表。模型通常首先生成一个logits矩阵z=hθ(x)∈RV×L,然后对每一列取Softmax。我们可以通过观察logπθ(y∣x)来跟踪模型信心的变化。
逐步影响分解 学习动态(1)变为,
Δlogπt(y∣xo)≜logπθt+1(y∣xo)−logπθt(y∣xo).
为了简单起见,我们从L=1的情况开始,Δθ和Δlogπ可以通过以下结果联系起来,这是Ren等人(2022)证明的,并在附录B中进一步讨论。对于多标签分类(L>1),更新是分开的;我们可以计算L个不同的Δlogπt并将它们堆叠在一起。
命题1 设π=Softmax(z)且z=hθ(x)。一步学习动态分解为
Δlogπt(y∣xo)=−ηAt(xo)Kt(xo,xu)Gt(xu,yu)+O(η2∥∇θz(xu)∥op2),
其中At(xo)=∇zlogπθt(xo)=I−1πθt(xo)⊤,Kt(xo,xu)=(∇θz(xo)∣θt)⊤(∇θz(xu)∣θt)⊤是经验神经切线核的logit网络z,Gt(xu,yu)=∇zL(xu,yu)∣zt。
//TODO
3 大型语言模型微调的学习动态
尽管学习动态已被应用于许多深度学习系统,但将其框架扩展到大型语言模型(LLM)微调并非易事。第一个问题是输入和输出信号的高维度和序列性质。高维特性使得很难观察模型的输出,而序列特性使得不同维度上的分布相互依赖,这比大多数先前工作中考虑的标准多标签分类问题更为复杂。此外,由于LLM微调有许多不同的算法——SFT (Wei et al. 2022), RLHF (Ouyang et al. 2022), DPO (Rafalov et al. 2023) 等——在统一框架下分析它们是具有挑战性的。最后,与通常假设所有可能输出具有大致均匀分布的训练从头开始的场景相比,LLM的微调动态严重依赖于预训练的基模型,这可能使分析更加困难。例如,预训练模型通常对不太可能的标记分配很小的概率质量,这对大多数应用是有益的,但会导致我们稍后展示的“挤压效应”的风险。我们现在解决这些问题,并提出一个不同微调方法的统一框架。
3.1 SFT损失的逐步分解
用于监督微调的典型损失函数是给定完成yu+=[y1+,…,yL+]∈VL条件下提示xu的负对数似然(NLL):
LSFT(xu,yu+)≜−l=1∑Llogπ(y=yl+∣y<l+,xu)=−l=1∑Leyl+⋅logπ(y∣xu,y<l+).
注意,与之前讨论的多标签分类问题相比,所有标签的联合分布可以分解为π(y∣x)=∏lπ(yl∣x),语言建模的序列性质使分析更加复杂,因为我们必须有π(y∣x)=∏lπ(yl∣x,y<l)。为了解决这个问题,我们可以将这种分解合并到后验hθ的定义中,同时保持命题1的格式。具体来说,让x成为x和y的连接,y的预测是
z=hθ(x);
π(y∣x)=Softmax_column(z).
这里z是一个V×L矩阵,其中每一列包含第l个标记的预测的对数,即使它将整个序列x作为输入,也会迫使模型在对第l个标记进行预测时不参考未来的标记y>l,通常通过“因果掩蔽”(Vaswani et al. (2017) 提出,附录D的图10a中详细说明)实现。然后,我们可以计算(∇θzl(xo)∣θt)(∇θzl(xu)∣θt)T的每一列上,并堆叠它们形成V×V×L张量Kt(xo,xu)。Gt和At的计算也遵循类似的过程。由于在hθ中实现了因果掩蔽,结果分解几乎与多标签分类问题相同。假设有一个与xu相关联的响应yu,长度为L,堆叠到xo中,模型对yo的第m个标记的预测变化可以表示为,当z梯度具有有界范数时,
[Δlogπt(y∣xo)]m=−l=1∑Lη[At(xo)]m,l[Kt(xo,xu)][Gt(xu,yu)]l+O(η2),
其中GSFTt(xu)=πθ(y∣xu)−yu。与命题1相比,主要区别是eNTK项也依赖于响应yu和yo,这使我们能够回答诸如
对于提示xu,学习响应yu+如何影响模型对响应yo+的信念?
当跟踪模型对给定问题xu的不同响应的信心时,从yu+学习会在yu+上施加强大的“向上”压力,如
4.实验验证
我们现在在实际环境中验证我们的分析。我们首先通过从数据集的训练分割中随机选择5000个样本来创建训练集Dtrain。我们考虑两个常见数据集,Antropic-HH (Y. Bai et al. 2022) 和 UltraFeedback (G. Cui et al. 2023),在所有实验中。每个Dtrain中的例子包含三个组件:提示(或问题)x,首选响应y+,以及不太首选的响应y−。SFT使用x和y+进行微调,而DPO使用x的所有三个(子集)y进行微调,并为了简洁起见移除y−。我们在两个系列的模型上重复实验:pythia-410M/1B/1.4B/2.8B (Biderman et al. 2023) 和 Qwen1.5-0.5B/1.8B (J. Bai et al. 2023)。
为了更详细地观察学习动态,我们进一步创建了一个探测数据集Dprob,通过从Dtrain中随机选择500个样本,并根据相应的x,y+,或y−生成几个典型的响应。(我们还研究了另一个探测数据集,其中所有x都来自附录中的消融研究。)然后对于每个Dprob中的x,我们可以观察logπθ(y∣x)在y的不同类型上如何逐渐变化。例如,一种扩展的响应类型可以是y+的改写,一个回答另一个问题的不相关响应,或者只是与y+具有相同单词数量的随机生成的英语句子。我们在附录D.1中详细解释了为什么需要这些扩展响应以及它们是如何生成的。简而言之,Dprob有助于我们更细粒度地检查学习动态,这不仅可以支持我们上述的分析,还可以进一步揭示模型的预测如何在RV×L的整个空间中演变,这是一个非常稀疏和巨大的空间。
4.1 SFT的学习动态
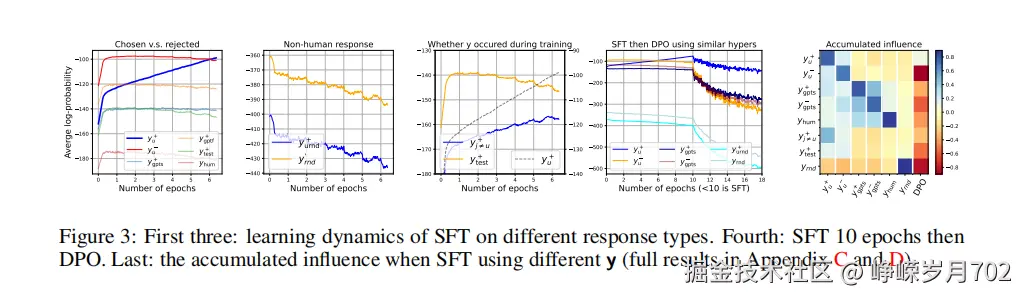
我们从第3.1节的分析中学到的主要教训是,从y+学习不仅增加了模型对y+的信心,而且还间接“拉动”了与y+相似的响应(强度较小,大致按∥Kt∥F2缩放),类似于学习“4”如何影响MNIST示例中“9”的预测。同时,πθ(y+∣xu)的增加自然“推下”所有y=y+,因为模型对Y空间中所有响应的预测概率之和为一。模型对不同y的行为主要是这些压力之间的权衡。为了验证这一点,我们对Dprob中的所有响应进行微调,并在几个时期内评估模型的预测,每25次更新评估一次(训练批次大小为100),并且每100个样本进行一次探测。对于每种类型的响应,我们平均模型在所有500个样本上的信心,并报告该对数似然的平均值。
如图3的第一面板所示,模型对yu的信心在整个学习过程中不断增加,这是直接的,因为主要的“拉动”压力直接施加在yu上。然而,一些与yu+相似的响应的行为并不平凡。例如,我们在同一面板中绘制了对相同问题(yu−)的不太首选响应,两种由ChatGPT生成的yu+的改写(ygpts+和ygptd+),另一种从测试集中随机选择的不太首选的响应(ytest−),甚至是一个随机生成的句子(ynum)。模型对这些响应的信心在训练开始时都略有增加,并随着训练的进行逐渐减少,即使模型在SFT期间从未看到过它们。这种反直觉的行为可以通过我们之前讨论的学习动态很好地解释。由于所有这些示例在某种程度上都“相似”于yu+(至少,它们都是常见的“标准英语”句子),它们∥Kt∥F合理地大。然后学习yu+将间接增加模型对这些相似y的信心,这就是为什么相应的πθ(y∣xu)在训练开始时略有增加的原因。然而,随着训练的进行,模型对yu+的信心不断增加,更新能量的范数∥GSFTt∥逐渐减少。这意味着间接的“拉起”压力也相应减少。然后,对所有y=yu+的“推下”压力变得占主导地位,所有相关曲线开始下降。
为了验证这种全局“推下”压力的存在,我们观察两种类型的响应;它们都与yu+有相同数量的单词。一种是完全随机的英语单词序列yrnd−。另一种是yu+中所有单词的随机排列,称为yperm−。由于两者都不是自然语言,我们预计它们与yu+之间的∥Kt∥F非常小,这意味着从yu+学习几乎不会对它们施加“拉起”压力;因此,“推下”压力将在整个训练过程中占主导地位。这些分析在图3的第二面板中得到了很好的支持,我们可以看到πθt(y∣xu)都从非常小的值开始,并在整个训练过程中持续下降。
另一种有趣的响应类型是yj=u+,即训练集中另一个问题xj=u的首选响应。对于这些响应,模型对πθt(yj=u+∣xu)的预测将受到两种“拉起”压力的影响:一种来自学习[xu;yu+],另一种来自学习[xj=u;yj=u+],后者可能更强,因为梯度是直接通过观察yj=u+计算的。这解释了为什么我们看到对yj=u+的信心以比yu+更小的速率持续增加。因为“拉起”压力总是足够强大以抵消“推下”压力。这些观察为我们提供了一个独特的解释,说明为什么在SFT之后特定类型的幻觉被放大。具体来说,πθt(yj=u+∣xu)的增加意味着如果我们要求模型回答一个问题xu,它可能会提供一个来自(或部分来自)训练集中另一个不相关的问题xj=u的响应。
最后,为了进一步从模型的角度探索不同响应之间的“相似性”,我们使用更多类型的响应对模型进行SFT,并观察πθ(y′∣xu)如何变化。结果在图3中展示,其中蓝色和橙色分别表示正向和负向影响。x轴是更新的响应,而y轴表示观察到的响应。因此,每一列类似于当我们使用[xu;y′]对模型进行SFT时[xu;y]的变化。一个有趣的发现是,ChatGPT生成的所有响应被认为是非常相似的,无论它们在语义上有多么不同。可能LLM有其偏好的习语或短语,这可以被认为是一种“指纹”。我们将这个有趣的问题留给未来的工作。
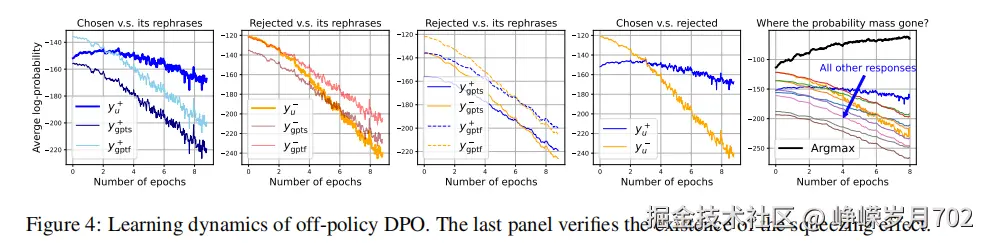
4.2 离策略DPO的学习动态
为了验证我们的框架也能解释模型在偏好微调中的行为,我们对DPO进行了类似的实验。回想一下,残差项GDPOt在yu+和yu−上引入了一对不同方向的箭头。为了展示这两种压力如何影响模型,我们检查了yu+或yu−(ygpts+,ygptd+,ygpts−, 和 ygptd−,用于之前的实验)的两种类型的改写。参见图4的第一面板,其中两个改写以相似的速度减少,比yu+的衰减速度更快。这是因为向上的压力直接施加在yu+上,而不是这些改写上。同样,在第二面板中,我们观察到yu−的衰减速度比其改写版本更快,因为GDPOt直接对yu−施加了负压力。然后在第三面板中,我们发现yu+的改写版本一致地比yu−的衰减速度慢,尽管在训练过程中它们从未出现过。这是因为这些响应与yu+或yu−非常接近,这意味着它们的∥Kt∥F相对较大。因此,施加在yu+和yu−上的压力也对它们产生了不可忽视的影响。最后,在第四面板中,πθ(yu+∣xu)−πθ(yu−∣xu)的差值持续增加,这意味着模型在训练过程中逐渐获得了区分yu+和yu−的能力。
尽管GDPOt直接对yu+施加了“拉起”压力,但πθ(yu+∣xu)的值并没有像在SFT中那样大幅增加。yu−上的向下箭头确实对与yu−相似的响应引入了“推下”压力,但这种影响不太可能那么强(它将被∥Kt∥F削弱),以使几乎每次观察到的响应的信心都像图3的最后一面板所示那样快速减少,其中我们对SFT和DPO使用了相似的η。那么,在DPO期间概率质量去哪里了?回答这个问题的关键是挤压效应,如第3.3节所讨论的:由于对yu−施加了大的负梯度,这可能是在πθ(y∣xu)的低区域,大多数y的信心将减少,而πθ(yu+∣xu)将非常快速地增加。
为了验证这一点,我们报告了通过贪婪解码选择的y的对数似然:每个标记都是通过最大化给定[xu;y<t]的条件概率实时选择的,其中y<t是yu+的一个子序列。正如图4的最后一面板所示,通过“教师强制”贪婪yu+的信心非常快地增加(从-113到-63),这甚至比SFT期间πθ(yu+∣xu)的增加(从-130到-90)还要快,8个周期内。然而,信心最高的标记并不一定形成首选响应:它将加强θ0中的先验偏差。这可能是对最近工作中报告的“退化”(例如,Holtzman等人,2020)的合理解释。当πθ在其最有信心的预测中变得更加尖锐时,它更容易采样重复短语的序列。请注意,这种行为也可以理解为一种特殊的自我偏差放大(Ren等人,2024),如果与多重生成自我改进算法(例如,自我奖励(Yuan等人,2024),迭代DPO(Xiong等人,2024)等)结合使用,将带来更严重的后果。
总之,不同类型的响应的行为都很好地符合我们的分析。更多微妙的趋势支持我们对SFT和DPO的解释。由于空间限制,我们在附录D中解释了其他模型和数据集的完整结果。
4.3 通过增强SFT训练集来缓解挤压效应
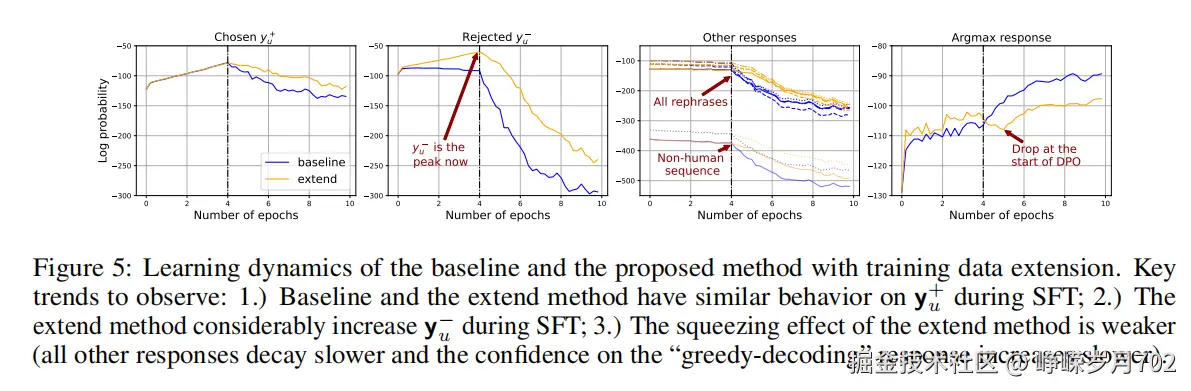
由于在不太可能的预测上施加大的负梯度所引起的“挤压效应”可能会损害模型在DPO期间的性能,我们可以在SFT阶段首先在[xu;yu+]和[xu;yu−]上训练模型(使负响应更有可能),然后运行常规的DPO。根据上述分析,我们可以预期在新的SFT阶段,那些与yu+或yu−相似的响应区域将同时被“拉起”。这正是我们想要的,因为在许多情况下,yu+和yu−对于问题xu都是相当好的响应;新的SFT设计因此有助于拉起一个更大的区域,该区域包含比基线SFT更多的合适响应。之后,DPO期间施加的“推下”压力可以.有效地减少模型对yu−及其相似响应的信心。由于在DPO之前yu−不再那么不可能,挤压效应不应像基线程序中那样强烈。
我们将我们的训练流程称为“扩展”,并将其学习动态与图5中的基线设置进行比较。很明显,挤压效应得到了缓解,因为在DPO期间其他响应的信心下降得更慢,并且在DPO开始时我们也观察到了贪婪解码响应的显著下降。为了进一步证明缓解挤压效应确实带来了好处,我们通过将它们输入到ChatGPT和Claude 3中,比较使用不同方法训练的模型生成的响应。具体来说,我们首先使用上述两种方法对模型进行两个周期的SFT,并称生成的策略网络为πbase和πextend。然后,我们在πbase和πextend上进行几个周期的相同DPO训练。所提出方法与基线方法的胜率在表1中提供。显然,在DPO之前,πbase更好,因为πextend明确地在这些y−上进行了训练。然而,在DPO几个周期后,πextend表现更好,因为挤压效应得到了有效缓解。请参阅附录F以获取更多详细信息。在未来,这种受我们分析启发的简单方法可以通过在两个阶段引入更多响应(例如,yu+的改写等)进行进一步改进,也可以与我们之前提到的许多现有的无RL方法结合使用。
5.结论
学习动态描述了模型在学习新样本时预测如何变化,为分析使用梯度下降训练的模型行为提供了一个强大的工具。为了更好地利用这一工具在大型语言模型(LLM)微调的背景下,我们首先推导出各种常见算法的LLM微调的逐步分解。然后,我们提出了一个统一的框架,用于理解不同微调方法下LLM预测行为。所提出的分析成功解释了LLM在指令微调和偏好微调期间的各种现象,其中一些现象相当反直觉。我们还将阐明在SFT阶段如何引入特定的幻觉,如之前观察到的(Gekhman等人,2024年),以及与原始非策略DPO相比,一些新的无RL算法的改进来自哪里。对挤压效应的分析也有可能应用于其他应用大负梯度于已经不太可能的结果的深度学习系统。最后,受此分析的启发,我们提出了一种简单(但反直觉的)方法,有效提高了模型的一致性。
附录
A.


