

目录
- 简介
- 模型架构
- 数据构建与训练
- 基础设施创新
- 性能与评估
- 专业能力
- 缩放分析
- 局限性与未来方向
- 结论
简介
视觉语言模型 (VLMs) 已迅速发展成为多模态推理、图像编辑、GUI 代理、自动驾驶和机器人等各种应用中的重要组成部分。 然而,当前的 VLM 在 3D 空间理解、对象计数、视觉推理和交互式游戏功能方面仍然面临重大限制。 字跳动公司的 Seed1.5-VL 代表了该领域的重大进步,它解决了这些挑战,同时突破了 VLM 可以完成的任务的界限。
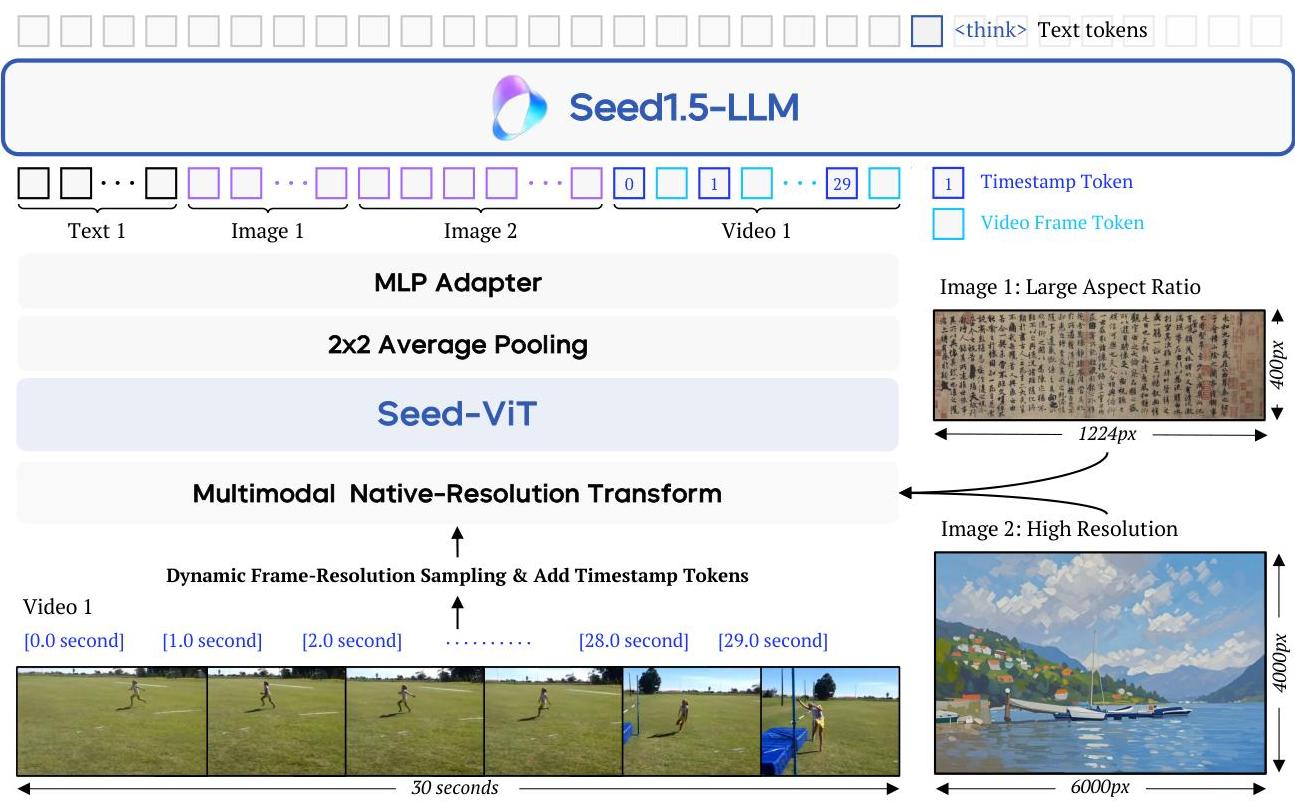 图 1:Seed1.5-VL 架构,展示了 Seed-ViT 与 Seed1.5-LLM 的集成,支持包括文本、图像和视频的多模态输入,并具有动态分辨率处理能力。
图 1:Seed1.5-VL 架构,展示了 Seed-ViT 与 Seed1.5-LLM 的集成,支持包括文本、图像和视频的多模态输入,并具有动态分辨率处理能力。
Seed1.5-VL 旨在克服阻碍 VLM 发展的两个关键挑战:与大型语言模型 (LLM) 可用的文本语料库相比,高质量、多样化的视觉语言注释的稀缺性,以及处理具有不对称架构的多模态数据的固有复杂性。 该模型通过其全面的训练方法、创新的架构设计以及对各种任务的严格评估,使其与现有方法区分开来。
模型架构
Seed1.5-VL 采用由三个主要组件组成的复杂架构:
-
视觉编码器 (Seed-ViT):一个拥有 5.32 亿个参数的视觉转换器,专为原生分辨率特征提取而设计。 该编码器可以适应动态图像分辨率,采用 2D 旋转位置编码 (RoPE) 来保持空间感知能力。
-
专家混合 (MoE) LLM:一个拥有 200 亿个激活参数的语言模型,可以处理文本信息并处理对视觉输入的推理。
-
MLP 适配器:将视觉特征投影到 LLM 可以处理的多模态令牌中,从而在视觉和语言组件之间创建无缝接口。
对于视频处理,Seed1.5-VL 实施了一种动态帧分辨率采样策略,该策略根据内容智能地调整帧速率和分辨率。 这样可以对具有不同时间动态和视觉复杂性的视频进行最佳处理。
该模型架构提供了几个优点:
- 能够处理具有不同宽高比和分辨率的图像而不会失真
- 通过智能采样高效处理视频内容
- 在同一框架内统一处理文本、图像和视频
- 平衡计算效率和模型性能的可扩展设计
数据构建与训练
Seed1.5-VL 的训练涉及针对特定能力的全面的数据构建策略:
-
预训练数据:该模型在包含 3 万亿个令牌的大规模语料库上进行训练,其中包括:
- 通用图像-文本对
- 具有文本识别功能的 OCR 数据
- 视觉基础和计数注释
- 3D 空间理解数据
- 具有时间推理的视频序列
- 用于技术理解的 STEM 数据
- GUI 交互数据
-
数据合成:为了解决专业领域中数据稀缺的问题,该团队开发了多样化的合成管道,用于:
- OCR 和文档理解
- 对象定位和计数
- 视频理解
- 需要空间推理的视觉谜题
-
数据平衡:一个复杂的框架重新平衡了常见和稀有视觉知识的分布,确保模型不会过度拟合频繁出现的模式。
训练过程遵循多阶段方法:
1. 预训练:
- 阶段 1:掩码图像建模
- 阶段 2:对比学习
- 阶段 3:全模态预训练
2. 后训练:
- 监督微调 (SFT)
- 具有混合方法的强化学习 (RL)
- RLHF(来自人类反馈的 RL)
- RLVR(具有可验证奖励的 RL)
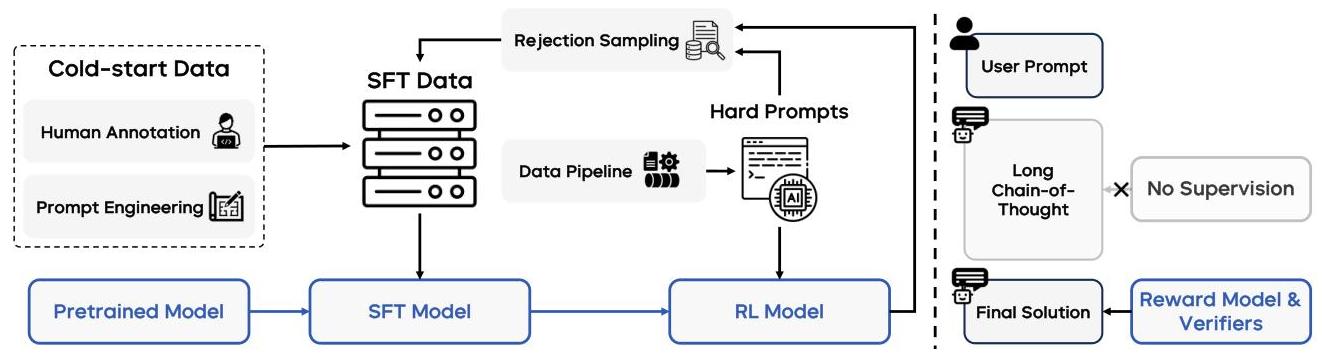 图 2:Seed1.5-VL 的训练流程,展示了从冷启动数据到 SFT 和 RL 阶段的进展,其中融合了人工标注、提示工程和奖励建模。
图 2:Seed1.5-VL 的训练流程,展示了从冷启动数据到 SFT 和 RL 阶段的进展,其中融合了人工标注、提示工程和奖励建模。
一个值得注意的创新是在 SFT 期间使用的长链思维 (LongCoT) 方法,该方法引导模型通过逐步推理来完成复杂的视觉任务。 这种方法显著提高了模型在需要多步骤推理的任务上的性能。
基础设施创新
大规模训练 VLM 因视觉和语言组件的非对称性而带来独特的挑战。 Seed1.5-VL 引入了几项基础设施创新来应对这些挑战:
-
混合并行:该团队开发了一种定制的并行策略,将用于视觉编码器的 ZeRO 数据并行与用于 LLM 的 4-D 并行相结合,从而优化了非对称工作负载。
-
工作负载平衡:一种视觉token重新分配策略平衡了 GPU 工作负载,解决了处理具有不同分辨率的图像的可变计算需求。
-
并行感知数据加载:该系统最大限度地减少了 3D 并行下的 I/O 瓶颈,这对于处理训练所需的大型数据集至关重要。
-
容错:一个强大的训练框架可确保在长时间的训练过程中能够抵御硬件故障。
这些创新使得 Seed1.5-VL 能够以空前的规模进行高效训练,从而使模型能够充分利用大量训练数据,而不会受到计算限制。
性能和评估
Seed1.5-VL 经过多个维度的全面评估:
-
公共基准:该模型在涵盖视觉推理、定位、计数、文档理解和视频解释的 60 个公共基准中的 38 个上实现了最先进的性能。
-
内部基准:一个内部基准测试套件侧重于核心能力,同时降低了基准过度拟合的风险,从而提供了对模型真实能力的更可靠的评估。
-
真实世界测试:该模型已部署在内部聊天机器人系统中,以监控真实世界和分布外 (OOD) 查询的性能。
-
专业任务:性能在 GUI 交互、游戏和具有复杂文档的多语言 OCR 解析方面进行评估。
 图 3:Seed1.5-VL 的对象检测能力在一个具有多种食物的复杂图像上得到证明。 右图显示了准确标记了边界圆的检测到的对象。
图 3:Seed1.5-VL 的对象检测能力在一个具有多种食物的复杂图像上得到证明。 右图显示了准确标记了边界圆的检测到的对象。
在与其他领先的 VLM 的性能比较中,Seed1.5-VL 在以下方面表现出卓越的能力:
- 需要整合多个图像区域信息的视觉推理任务
- 复杂场景中的精确对象定位和计数
- 具有混合语言和格式的文档理解
- 具有时间推理的视频解释
- 视觉拼图和空间推理挑战中的问题解决
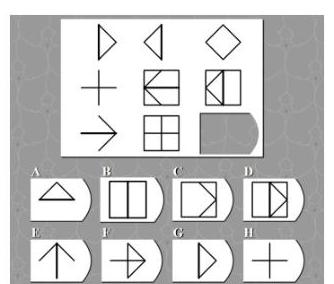 图 4:需要空间推理能力的视觉谜题示例。Seed1.5-VL 可以分析模式和关系以确定正确答案。
图 4:需要空间推理能力的视觉谜题示例。Seed1.5-VL 可以分析模式和关系以确定正确答案。
专门能力
Seed1.5-VL 在以下几个专业领域表现出卓越的性能:
对象计数和定位
该模型可以准确地识别和计数复杂场景中的对象,即使在处理部分遮挡或不寻常的方位时也是如此。其定位能力允许对文本查询中提到的对象进行精确定位。
多语言 OCR 和文档理解
Seed1.5-VL 擅长处理包含多种语言的文档,其解析多语言收据并从中提取结构化信息的能力就证明了这一点。
 图 5:包含多语言内容的收据,Seed1.5-VL 可以准确解析,提取不同语言的项目、价格和总额。
图 5:包含多语言内容的收据,Seed1.5-VL 可以准确解析,提取不同语言的项目、价格和总额。
GUI 代理能力
该模型在基于 GUI 的任务中表现出强大的性能,有效地解释界面元素并确定适当的操作。这使得它特别适合于自动化需要与图形用户界面交互的任务。
游戏玩法和互动推理
Seed1.5-VL 在游戏场景中表现出令人印象深刻的能力,它必须理解规则、跟踪状态变化并做出战略决策。在这些以代理为中心的任务中,该模型优于领先的多模态系统。
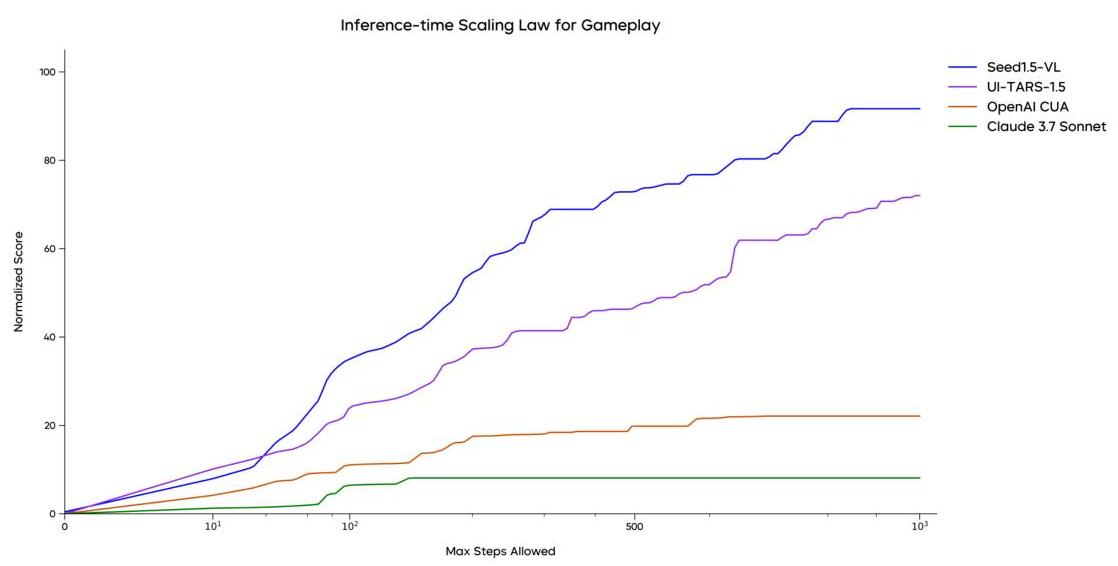 图 6:图表显示,随着允许的最大步数增加,Seed1.5-VL 在游戏场景中的性能优于其他领先模型。
图 6:图表显示,随着允许的最大步数增加,Seed1.5-VL 在游戏场景中的性能优于其他领先模型。
视觉谜题和空间推理
该模型擅长解决需要空间推理、模式识别和抽象思维的视觉谜题。示例包括完成视觉序列、识别模式和解决几何问题。
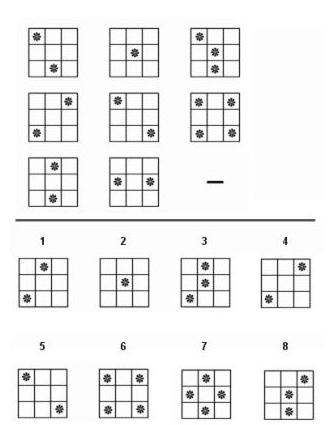 图 7:一个矩阵推理谜题,测试 Seed1.5-VL 识别模式并将其应用于确定缺失元素的能力。
图 7:一个矩阵推理谜题,测试 Seed1.5-VL 识别模式并将其应用于确定缺失元素的能力。
缩放分析
研究团队进行了全面的缩放分析,以了解模型性能如何与增加模型参数和训练计算相关联。结果显示了几个重要的趋势:
-
损失缩放:OCR 损失和定位损失都随着训练计算量的增加呈对数递减,遵循与更大的语言模型一致的幂律。
-
评估指标缩放:评估指标的性能随着训练损失的减少而可预测地提高,这表明持续的缩放将产生进一步的改进。
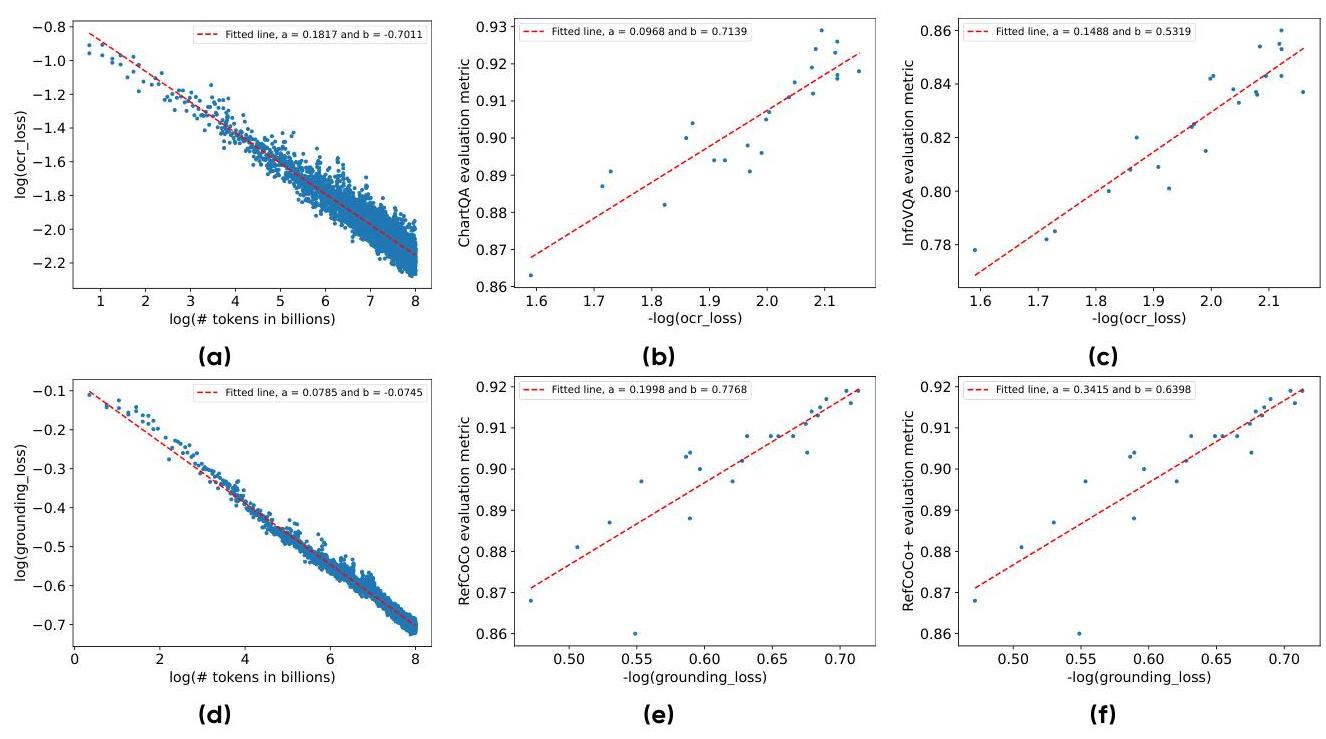 图 8:缩放分析显示了 Seed1.5-VL 的训练 token、损失值和评估指标之间的关系。
图 8:缩放分析显示了 Seed1.5-VL 的训练 token、损失值和评估指标之间的关系。
分析表明,模型性能随着规模的增加而不断提高,没有出现收益递减的迹象,这表明可以使用额外的计算资源开发出更强大的模型。
局限性和未来方向
尽管 Seed1.5-VL 具有令人印象深刻的能力,但它也有一些局限性,这些局限性指出了未来研究的方向:
-
3D 空间推理:虽然比以前的模型有所改进,但 Seed1.5-VL 仍然难以处理复杂的 3D 空间推理任务,这些任务需要从多个视点理解对象关系。
-
幻觉缓解:与其他 VLM 一样,该模型有时会产生输入图像中不存在的细节幻觉,尤其是在提示关于模糊区域或提出高度具体的问题时。
-
组合搜索:该模型在需要系统地评估许多可能性的问题中执行详尽搜索的能力有限。
未来的研究方向包括:
- 与图像生成能力集成
- 增强工具在复杂问题解决中的使用
- 通过专门的训练来提高 3D 理解能力
- 通过验证机制减少幻觉
- 将游戏能力扩展到更复杂的场景
结论
Seed1.5-VL 代表了视觉语言建模方面的重大进步,解决了先前方法的关键局限性,同时在各种任务中建立了新的最先进的性能。该模型在 GUI 交互、游戏和视觉解谜等专业领域的优势展示了其在各种实际应用中的潜力。
全面的训练方法、创新的架构和基础设施优化为该领域提供了有价值的见解,而缩放分析为未来的模型开发提供了指导。随着 VLM 的不断发展,Seed1.5-VL 中率先采用的方法可能会影响下一代多模态人工智能系统。
增强的空间推理、改进的细粒度视觉理解和复杂的问题解决能力的集成使 Seed1.5-VL 成为从教育工具到自主系统的各种应用的通用基础,标志着朝着更通用和更有能力的人工智能迈出了重要一步。
相关引用
Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, 和 Furu Wei。Kosmos-2:将多模态大型语言模型与世界对齐。arXivpreprintarXiv:2306.14824, 2023.
- 此引用之所以相关,是因为该论文提到了“在统一模型中对齐视觉和文本模态”,而对齐是这种对齐的关键方面。 Kosmos-2 被引用为 VLM 的一个突出例子。
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, 等。Gpt-4o 系统卡。arXivpreprintarXiv:2410.21276, 2024.
- GPT-4o 被引用为 VLM 的一个例子,用于评估部分进行比较。 由于 Seed-1.5 与之进行了比较,因此这是支持新模型定位的重要引用。
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, 等. Qwen2. 5-vl 技术报告。arXivpreprintarXiv:2502.13923, 2025.
- Qwen 2.5-VL 用作评估中的比较基线,显示了 Seed-1.5 的相对性能。 因此,它对于论文中提出的评估至关重要。
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, 等. Mmmu:一个大规模多学科多模态理解和推理基准,用于专家通用人工智能。 在IEEE/CVF计算机视觉和模式识别会议论文集中,第 9556–9567 页,2024 年。
- MMMU 是用于评估 Seed-1.5 的核心基准,因此该引用与理解如何以标准化方式衡量模型的性能有关。 它被用作多模态推理能力的主要指标。
本文使用 文章同步助手 同步
