

选择此技术栈优先考虑以下几点:
- • 开发速度: 使用 Flask 和 Vue.js 可以实现快速原型设计和开发。
- • 性能: Python 配合 PyMuPDF 对于 PDF 处理任务是高效的。
- • 简单性: 所选工具对于此范围的项目相对易于学习和管理。
- • 生态系统: Python 和 JavaScript (用于 Vue.js) 都拥有庞大的生态系统和社区支持。
此推荐与 @memory-bank/game-design-document.md 中的"技术栈(建议)"部分保持一致,专注于为项目的核心需求提供一套实用且有效的工具。
### 生成实施计划
我这里是使用英文生成实施计划的,生成的效果还不错(推荐)
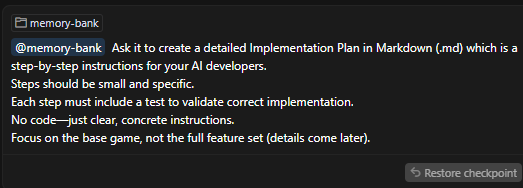
```markdown
@memory-bank Ask it to create a detailed Implementation Plan in Markdown (.md) which is a step-by-step instructions for your AI developers.
Steps should be small and specific.
Each step must include a test to validate correct implementation.
No code—just clear, concrete instructions.
Focus on the base game, not the full feature set (details come later).
如果生成的文档内容是英文的话,可以让他使用中文生成
生成后的实施计划如下:
# PDF 转 Markdown 转换器:实施计划 (MVP)
## 0. 引言
本文档概述了 PDF 转 Markdown 转换器基础功能(最小可行产品 - MVP)的逐步实施计划,主要面向 AI 开发人员。
**在开始任何开发之前,请确保您已透彻阅读并理解:**
1. **游戏设计文档 (GDD)**:`memory-bank/game-design-document.md`,了解项目需求和功能。
2. **架构文档** (可用后):`memory-bank/architecture.md`,了解系统设计和技术选型。
本计划首先专注于交付核心功能:PDF 上传、基本文本到 Markdown 的转换、结果显示以及 Markdown 文件下载。每个步骤都包含具体的指令和用于验证正确实施的测试。建议的技术(例如,后端 Python/Flask,前端 Vue.js,PDF 处理库 PyMuPDF)基于 GDD 对快速 MVP 开发的推荐;可以从 GDD 中选择等效的技术。
---
##阶段 1:用于 PDF 处理的后端 API
###步骤 1.1:后端项目设置
- **指令**:
1. 使用您选择的框架(例如,根据 GDD 的“技术栈(建议)”,Python 使用 Flask,Node.js 使用 Express)初始化一个新的后端项目。
2. 创建一个基本的健康检查端点(例如 `/health`),该端点返回 `200 OK` 状态和一个简单的 JSON 响应(例如 `{"status": "ok", "message": "后端正在运行"}`)。
- **测试**:
1. 启动后端服务器。
2. 使用 Web 浏览器或 `curl` 等工具访问 `/health` 端点。
3. 验证响应状态码为 `200 OK`。
4. 验证响应体为 `{"status": "ok", "message": "后端正在运行"}`。
###步骤 1.2:PDF 上传和验证端点
- **指令**:
1. 实现一个 API 端点(例如 `/api/upload_pdf`),通过 `POST` 请求(使用 `multipart/form-data`)接受 PDF 文件。
2. 该端点应将上传的文件临时保存到服务器上一个安全的指定位置。
3. 实现对上传文件的服务器端验证:
- **文件类型**:确保上传的文件是 PDF(检查 MIME 类型 `application/pdf` 和/或文件扩展名 `.pdf`)。拒绝非 PDF 文件。
- **文件大小**:确保文件大小在指定限制内(例如,根据 `game-design-document.md` 为 50MB)。拒绝超出限制的文件。
- **测试**:使用 `curl` 或 Postman 等工具:
1. **有效 PDF**:向 `/api/upload_pdf` 发送一个 `POST` 请求,附带一个有效的 PDF 文件(例如 `test.pdf`,<50MB)。
- 验证响应为 `200 OK`(或 `201 Created`),可能返回一个临时文件标识符。
- 在服务器上验证 `test.pdf` 文件已保存到指定的临时位置。
2. **无效文件类型**:发送一个带有非 PDF 文件(例如 `test.txt`)的 `POST` 请求。
- 验证响应为 `400 Bad Request`(或 `415 Unsupported Media Type`)。
- 验证响应体包含清晰的错误消息(例如“无效的文件类型。只接受 PDF 文件。”)。
3. **文件过大**:发送一个带有超过 50MB 的 PDF 文件的 `POST` 请求。
- 验证响应为 `413 Payload Too Large`。
- 验证响应体包含清晰的错误消息(例如“文件大小超过 50MB 限制。”)。
###步骤 1.3:核心 PDF 到基本 Markdown 转换逻辑
- **指令**:
1. 创建一个专用的模块或函数(例如 `pdf_to_markdown_converter.py`)负责转换。
2. 此函数应接受临时保存的 PDF 的文件路径作为输入。
3. 使用选定的 PDF 处理库(例如,根据 GDD,Python 使用 PyMuPDF (`fitz`))。
4. 从 PDF 的所有页面中提取文本内容。
5. 实现基本的 Markdown 结构:
- **段落**:保留段落中断。PDF 中的连续文本行应在 Markdown 中视为单个段落。PDF 中文本块之间的空行或明显的垂直间距通常应在 Markdown 中产生双换行符以分隔段落。
- **MVP 阶段**:所有提取的文本将被视为纯段落。标题、列表、表格和图像等复杂元素不在此初始步骤的范围内。
- **测试**:
1. 准备测试 PDF 文件:
- `single_paragraph.pdf`:包含一个跨越多行的文本块。
- `multiple_paragraphs.pdf`:包含至少三个由明显垂直间距分隔的独立段落。
- `empty.pdf`:一个空的 PDF 或没有可提取文本的 PDF。
2. 直接使用 `single_paragraph.pdf` 调用转换函数。验证输出是一个单字符串,其中换行符在该段落内按原样保留(Markdown 将段落内的单个换行符视为空格,因此这意味着除非有意,否则没有双换行符)。
3. 使用 `multiple_paragraphs.pdf` 调用转换函数。验证输出字符串正确使用双换行符 (`\n\n`) 来分隔不同的段落。
4. 使用 `empty.pdf` 调用转换函数。验证输出为空字符串或合理的默认值(例如,消息“未找到文本内容”)。
###步骤 1.4:PDF 到 Markdown 转换的 API 端点
- **指令**:
1. 修改 `/api/upload_pdf` 端点(或创建一个新的,例如 `/api/convert_pdf_to_md`)以集成转换逻辑。
2. 在 PDF 成功上传和验证后(步骤 1.2),将保存的临时文件的路径传递给转换函数(步骤 1.3)。
3. API 端点应在其响应体中返回生成的 Markdown 文本。建议使用 JSON 响应(例如 `{"markdown_content": "...", "filename": "original_filename.pdf"}`)。
4. 至关重要的是,确保在转换过程完成后(无论成功与否)从服务器上安全删除临时 PDF 文件,以保护用户数据。
- **测试**:使用 `curl` 或 Postman 等工具:
1. **成功转换**:将 `multiple_paragraphs.pdf` 发送到转换端点。
- 验证响应为 `200 OK`。
- 验证 JSON 响应体包含一个 `markdown_content` 字段,其中包含正确格式化的 Markdown(段落中断)。
- 验证 JSON 响应体包含原始 PDF 的 `filename`。
- 在服务器上验证临时 PDF 文件已被删除。
2. **转换空 PDF**:将 `empty.pdf` 发送到端点。
- 验证响应为 `200 OK`。
- 验证 `markdown_content` 为空或指示未找到内容。
- 验证临时文件已被删除。
3. **错误处理(模拟)**:如果转换逻辑(步骤 1.3)对特定 PDF 抛出错误,请确保端点优雅地处理此问题(例如,返回 `500 Internal Server Error` 并附带通用错误消息),并且仍然删除临时文件。(这可能需要临时修改转换函数以模拟测试 PDF 的错误)。
---
##阶段 2:用于上传和显示的前端 UI
###步骤 2.1:前端项目设置
- **指令**:
1. 使用您选择的框架(例如,根据 GDD,Vue.js、React、Svelte)初始化一个新的前端项目。
2. 创建一个主应用程序组件(例如 `App.vue` 或 `App.js`),它将作为 PDF 转 Markdown 工具 UI 的容器。
3. 设置基本页面结构:工具的标题。
- **测试**:
1. 启动前端开发服务器。
2. 在 Web 浏览器中打开应用程序。
3. 验证基本应用程序页面加载时没有任何控制台错误。
4. 验证标题(例如“PDF 转 Markdown 转换器”)已显示。
###步骤 2.2:PDF 文件上传 UI
- **指令**:
1. 在主应用程序组件中,实现一个用于文件上传的 UI 部分:
- 包含一个 HTML 文件输入元素 (`<input type="file" id="pdfUpload" accept=".pdf">`)。
- 为文件输入添加清晰的标签(例如“选择一个 PDF 文件”)。
- 一旦选择了文件,就在输入旁边或指定区域显示所选文件的名称。
- 添加一个“转换为 Markdown”按钮。此按钮最初应处于禁用状态。只有当用户选择了有效的 PDF 文件后,它才应变为启用状态。
- (MVP 阶段可选,但 GDD 推荐:实现 PDF 上传的拖放功能。)
- **测试**:
1. **初始状态**:验证文件输入及其标签可见。验证“转换为 Markdown”按钮存在且已禁用。
2. **文件选择**:单击文件输入。应打开浏览器的文件选择对话框。
3. 选择一个 PDF 文件(例如 `my_document.pdf`)。验证“my_document.pdf”(或所选文件的名称)显示在 UI 上。验证“转换为 Markdown”按钮变为启用状态。
4. **文件更改**:选择一个不同的 PDF 文件。验证显示的文件名已更新,并且按钮保持启用状态。
5. **清除选择(如果浏览器允许轻松操作)**:如果可能,清除文件选择。验证显示的文件名已清除,并且“转换为 Markdown”按钮再次变为禁用状态。
6. **(如果已实现拖放功能)**:
- 将 PDF 文件拖到指定的放置区域。验证文件名已显示并且按钮已启用。
- 将非 PDF 文件(例如 `.txt`、`.jpg`)拖到放置区域。验证文件被拒绝(无文件名显示,按钮保持禁用,可能带有拒绝的视觉提示)。
###步骤 2.3:Markdown 输出的显示区域
- **指令**:
1. 添加一个 UI 部分(例如,一个只读的 `<textarea>` 或一个带有 `<pre>` 和 `<code>` 标签用于预格式化文本的 `<div>`)以显示将从后端接收的 Markdown 内容。
2. 此区域最初应为空或显示占位符消息(例如“您转换的 Markdown 将在此处显示...”)。
3. 在此显示区域旁边或下方包含一个“复制 Markdown”按钮。此按钮最初应处于禁用状态。
- **测试**:
1. 验证 Markdown 显示区域在页面上存在。
2. 验证它按设计显示占位符消息或为空。
3. 验证“复制 Markdown”按钮存在且已禁用。
---
##阶段 3:连接前端和后端以及下载功能
###步骤 3.1:用于转换的前端到后端通信
- **指令**:
1. 当单击“转换为 Markdown”按钮(来自步骤 2.2)并且已选择文件时:
- 前端应构造一个包含所选 PDF 文件的 `FormData` 对象。
- 向后端的转换 API 端点(例如,来自步骤 1.4 的 `/api/convert_pdf_to_md`)发送异步 HTTP `POST` 请求。
2. 实现对 API 响应的处理:
- **成功时(例如 200 OK)**:
- 解析 JSON 响应以获取 `markdown_content`。
- 在指定的 UI 区域(来自步骤 2.3)中显示此 Markdown 内容。
- 启用“复制 Markdown”按钮(来自步骤 2.3)。
- 启用“下载 .md 文件”按钮(将在步骤 3.2 中创建)。
- **出错时(例如 4xx 或 5xx 状态码)**:
- 向用户显示用户友好的错误消息(例如“转换失败。请重试。”或后端提供的更具体的消息(如果可用))。
- 确保 Markdown 显示区域已清除或重置。
3. 在此过程中实现视觉反馈:
- 在文件上传和后端处理期间显示加载指示器(例如,旋转器或“正在转换...”消息)。
- 在此加载状态期间禁用“转换为 Markdown”按钮以防止多次提交。
- **测试**:
1. **成功转换**:
- 在 UI 中选择 `multiple_paragraphs.pdf`。单击“转换为 Markdown”。
- 验证加载指示器出现,并且“转换”按钮暂时禁用。
- 一旦后端响应,验证加载指示器消失。
- 验证来自 `multiple_paragraphs.pdf` 的 Markdown(具有正确的段落中断)显示在输出区域中。
- 验证“复制 Markdown”按钮变为启用状态。
2. **后端验证错误**:使用后端将拒绝的测试 PDF(例如,如果绕过了前端验证,则将 `.txt` 文件重命名为 `.pdf`,或者已知会导致特定后端验证失败的文件)。
- 尝试转换。验证加载指示器出现并消失。
- 验证前端显示了用户友好的错误消息。
- 验证 Markdown 显示区域保持为空或显示占位符。
3. **后端服务器错误(模拟)**:临时修改后端端点以返回 `500 Internal Server Error`。
- 尝试转换。验证显示了有关服务器问题的用户友好错误消息。
###步骤 3.2:Markdown“复制到剪贴板”和下载 UI
- **指令**:
1. **复制 Markdown**:
- 实现“复制 Markdown”按钮(来自步骤 2.3)的功能。
- 单击时,它应将 Markdown 显示区域的全部内容复制到用户的剪贴板。
- 提供视觉反馈(例如,短暂地将按钮文本更改为“已复制!”,显示一个提示通知)。
2. **下载 .md 文件**:
- 向 UI 添加一个“下载 .md 文件”按钮。此按钮最初应处于禁用状态,并且只有在成功转换并且 Markdown 内容可用后才启用。
- 单击时,前端应:
- 从显示区域获取 Markdown 文本。
- 创建一个文本 Blob。
- 使用一种技术(例如,创建一个带有 `download` 属性且 `href` 设置为该 Blob 的对象 URL 的 `<a>` 元素)来触浏览器下载。
- 建议的文件名应基于原始 PDF 的名称(如果可从后端响应中获得),否则使用通用名称,如 `converted.md`。例如,如果转换了 `original_filename.pdf`,则建议使用 `original_filename.md`。
- **Test**:
1. **初始状态**:验证“下载 .md 文件”按钮存在且已禁用。“复制 Markdown”按钮也已禁用。
2. **成功转换后**:
- 成功转换 PDF。验证“复制 Markdown”和“下载 .md 文件”按钮均变为启用状态。
3. **复制功能**:
- 单击“复制 Markdown”按钮。
- 验证视觉反馈(例如,“已复制!”)。
- 将内容粘贴到文本编辑器中。验证其与 UI 中显示的 Markdown 匹配。
4. **下载功能**:
- 单击“下载 .md 文件”按钮。
- 验证浏览器中已启动文件下载。
- 建议的文件名应适当(例如,如果上传了 `example.pdf`,则应建议 `example.md`)。
- 打开下载的 `.md` 文件。验证其内容与 UI 中显示的 Markdown 相同。
---
此 MVP 计划为进一步开发奠定了坚实的基础。可以根据 `game-design-document.md` 在此基础上构建更多增强功能(例如更复杂的 Markdown 解析、OCR、UI 改进等)。
可以看到步骤,以及测试方式。
这一步十分重要,可以让我们清楚的知道AI做了什么,以及我们要如何验证。
下面是中文的提示语,大家也可以试一下看看如何
@memory-bank 要求它用 Markdown创建详细的实施计划(implementation-plan.md),这是针对您的 AI 开发人员的分步说明。
步骤应该小而具体。
每个步骤都必须包括测试以验证正确实施。
没有代码——只有清晰、具体的指令。
专注于需求,而不是完整的功能集(详细信息稍后公布)。
创建两个空文件和基础规则
在memory-bank文件夹下,生成两个空文件
- • progress.md
- • architecture.md
用来记录开发进程和基础内容
以及生成一个基础规则,让ai能够每次都去阅读基础设施文件和需求文档,并且做修改
#重要:
#在编写任何代码之前,请务必阅读memory-bank/@architecture.md。
#在编写任何代码之前,请务必阅读memory-bank/@game-design-document.md。
#添加主要功能或完成里程碑后,更新memory-bank/@architecture.md。
英文版本:
# IMPORTANT:
# Always read memory-bank/@architecture.md before writing any code. Include entire database schema.
# Always read memory-bank/@game-design-document.md before writing any code.
# After adding a major feature or completing a milestone, update memory-bank/@architecture.md.
执行计划
输入内容
Read all the documents in /memory-bank, and proceed with Step 1 of the implementation plan. I will run the tests. Do not start Step 2 until I validate the tests. Once I validate them, open memory-bank/progress.md and document what you did for future developers. Then add any architectural insights to architecture.md to explain what each file does.
翻译后:
请阅读 中的所有文档/memory-bank,然后继续执行实施计划的第一步。我会运行测试。在我验证测试结果之前,请勿开始第二步。在我验证测试结果后,请打开memory-bank/progress.md并记录您所做的工作,以供未来的开发人员参考。然后,添加任何架构见解,以memory-bank/architecture.md解释每个文件的功能。
运行效果:
AI就会按步骤进行执行,然然后并且让你进行验证
当你验证没问题后,输入
它就会将完成的步骤 记录到process.md和architecture.md中
遇到问题
遇到问题后,则将问题复制给它。让它进行处理即可
如:
-
- 未生成markdown的格式
-
- 图片没有生成
验证
最后生成了前端和后端代码
然后后端使用的是python,则需要安装python,并且下载依赖,基本上按照步骤执行即可。
注意:如果在cursor中无法执行命令的话,则使用命令行工具进行执行
cd backend
pip install -r requirements.txt
python run.py
前端启动:
双击打开即可
页面效果如下:
传入一份pdf,点击转换markdown,然后点击下载完整包
生成md文件如下:
总结
这个方式是在网上研究多了多种AI生成方式之后,得出的一个比较可靠的AI生成方式,不然AI生成编程一个黑盒子,而是能够知道AI做了什么,让AI不会容易脱离我们的掌控,生成的质量也会高很多。
今天,突然有个需求,就是想要将从网上下载的pdf转成markdown格式,放在自己的文件中,自己进行编辑等。
但是网上支持的方式很少,效果比较好的,又都是收费的。
所以想着要不使用AI开发一个吧,然后就有了结果了。
加上现在Claude4,0出来了,正好试试效果~
看看效果
我们先看看生成的效果,这个是网站页面
生成效果的markdown
-
- 支持Markdown格式
-
- 支持将图片下载到本地,不使用上传到图床上去的方式,这样子不安全
然后我们首先先介绍一下,编码的方式。
不是直接将需求直接输入给Cursor然后进行生成,而是按能够让AI自己拆解任务、执行任务、记录执行步骤。
下面便使用github start1.1K 的一篇文章,来进行介绍如何更好去使用cursor生成代码~
vibe coding文件解析
首先是构建一个memory-bank(记忆银行),用于存放生成项目需要的东西。
然后该文件夹下的作用分别如下:
-
- game-design-document:需求文档
-
- tech-stack.md:根据需求文档生成技术栈
-
- implementation-plan.md:实施计划 AI根据需求文档罗列需要实现的步骤
-
- progress.md:实施进程 在验证没问题后,AI会记录实现到哪一步
-
- architecture.md: 直译过来是“基础设施”的意思,主要用来存储项目的基础信息,便于提供上下文给AI进行参考
OK,下面便进行直接实现的步骤了,目的是为了生成一个网站:PDF转md格式
实现步骤
配置基础规则
AI使用中文进行回答
我的电脑系统是Windows
Cursor中创建一个文件夹
之后点击右侧、然后选择Agent模式+sonnet4.0
本文都采用Agent+Claude4.0+sonnet的方式进行生成。
生成需求文档
输入下面的文字:
生成需求文档到memory-bank/game-design-document.md中
需求如下:生成一个网站,将pdf转为markdown格式
生成效果:
# 需求文档:PDF 转 Markdown 网站
## 1. 项目概述
本项目旨在创建一个在线工具,允许用户上传 PDF 文件并将其转换为 Markdown 格式。该工具应易于使用、高效,并能准确地保留原始 PDF 的内容结构。
## 2. 功能需求
### 2.1 核心功能
- **PDF 文件上传**:
- 用户应能够通过拖放或文件选择器上传 PDF 文件。
- 支持单个文件上传。
- 应有文件大小限制(例如,最大 50MB)。
- 应有文件类型验证,确保上传的是 PDF 文件。
- **PDF 到 Markdown 转换**:
- 系统应能准确解析 PDF 内容,包括文本、标题、列表、表格、图片(可选,可考虑转换为 Markdown 图片链接或 Base64 嵌入)、代码块等。
- 尽可能保留原始文档的格式和结构。
- 对于无法直接转换的复杂元素,应提供合理的降级处理。
- **Markdown 内容展示**:
- 转换完成后,用户应能在网页上直接预览生成的 Markdown 内容。
- 提供 Markdown 文本的复制功能。
- **Markdown 文件下载**:
- 用户应能够将转换后的 Markdown 内容下载为 `.md` 文件。
### 2.2 用户界面 (UI) 和用户体验 (UX)
- **简洁直观的界面**:界面设计应简洁明了,易于用户理解和操作。
- **清晰的指引**:提供清晰的操作指引,引导用户完成上传、转换和下载过程。
- **进度提示**:在文件上传和转换过程中,应有明确的进度提示。
- **错误处理**:对于上传失败、转换错误等情况,应向用户显示友好的错误提示和可能的解决方案。
- **响应式设计**:网站应能在不同设备(桌面、平板、手机)上良好显示和操作。
### 2.3 可选/高级功能
- **批量上传与转换**:支持一次上传和转换多个 PDF 文件。
- **OCR 功能集成**:对于扫描版或图片型 PDF,集成 OCR 功能以提取文本。
- **自定义转换选项**:允许用户选择是否转换图片、如何处理表格等。
- **API 接口**:为开发者提供 API 接口,以便将此功能集成到其他应用中。
- **用户账户系统**:允许用户注册登录,保存转换历史等。
## 3. 非功能性需求
- **性能**:
- 文件上传和转换过程应尽可能快。
- 网站响应速度快。
- **准确性**:Markdown 转换结果应高度忠实于原始 PDF 内容。
- **安全性**:
- 用户上传的文件在处理后应及时删除,确保用户数据隐私。
- 防止常见的 Web 攻击(如 XSS, CSRF)。
- **可扩展性**:系统架构应易于扩展,以支持未来可能增加的新功能或更高的并发量。
- **兼容性**:
- 支持主流的现代浏览器(Chrome, Firefox, Safari, Edge)。
- 能处理各种常见版本的 PDF 文件。
## 4. 技术栈(建议)
- **前端**:React / Vue.js / Angular / Svelte (任选其一或使用原生 HTML, CSS, JavaScript)
- **后端**:Python (Flask/Django) / Node.js (Express) / Java (Spring Boot) (任选其一)
- **PDF 处理库**:
- Python: `PyMuPDF (fitz)`, `pdfminer.six`, `pdf2image`
- JavaScript (Node.js): `pdf-parse`, `pdfjs-dist`
- **数据库** (如果需要用户账户系统): PostgreSQL / MySQL / MongoDB
## 5. 部署
- 考虑使用 Docker 进行容器化部署。
- 可部署在云平台如 AWS, Google Cloud, Azure 或 Vercel/Netlify (针对纯前端或 Jamstack 架构)。
## 6. 维护与迭代
- 定期更新依赖库,修复安全漏洞。
- 根据用户反馈和需求变化进行功能迭代和优化。
生成技术栈文档
生成结果:
# 项目技术栈推荐
本文档概述了 PDF 转 Markdown 转换器项目的推荐技术栈,详情请参阅 @memory-bank/game-design-document.md。
##核心技术栈组件:
1. **前端**: Vue.js
- **理由**: Vue.js 提供了一个渐进式框架,易于上手且能高效构建用户界面。对于此规模的项目,它在简单性(相较于 Angular/React)和强大功能(用于响应式和交互式体验)之间取得了良好平衡。原生 HTML/CSS/JS 是追求极致简单的替代方案,但即使对于略微复杂的 UI,Vue.js 也能提供更好的结构。
2. **后端**: Python 与 Flask
- **理由**: Python 因其成熟的库而非常适合 PDF 处理。Flask 是一个轻量级的微框架,可以快速搭建用于转换逻辑的 API 端点,而没有不必要的开销。
3. **PDF 处理库**: PyMuPDF (`fitz`)
- **理由**: PyMuPDF 以其从 PDF 文件中提取文本、图像和元数据的速度和全面功能而闻名。它是核心转换任务的稳健选择。
4. **数据库**: (初期 MVP 无需)
- **理由**: PDF 到 Markdown 转换的核心功能本身不需要数据库。如 GDD 中提到的用户账户或转换历史等可选功能,可以在后续迭代中引入数据库(例如,追求简单的 SQLite,或追求可伸缩性的 PostgreSQL)。
##选择理由:
如果需要源码的话,可以关注一下公众号**I am Walker**,回复**<font style="color:rgb(26, 27, 28);">pdf2md</font>**
## 往期回顾
[超详细Cursor生成需求文档+UI设计图(附详细操作)](https://mp.weixin.qq.com/s/hQaGP-9hAHBKKxQGY23WHg)
[保姆级教学!Cursor+Figma实现可编辑产品原型图(附使用案例)](https://mp.weixin.qq.com/s/IXI07sSlN_XjJ69VKT3gMA)
