

文章摘要
本文主要介绍 在LevelDB中的核心机制 compaction, 主要用来对数据进行分级存储,并且能够根据需要动态对数据进行上推或者下移,从而在保证数据尽可能高效的读取的情况下降低存储的开销
适用人群:
- 数据库开发的专业人士
- 使用常见数据库如MySQL,Redis等,但是对数据库细节有更高理解需求的使用方
- 线上服务的构建者,希望能找到一种方式在磁盘上以尽可能的低的方式降低存储开销
- 没有技术背景的小型企业主,目前已经有技术团队或正在搭建技术团队,可以用本文内容来检测后端程序员的技术功底
阅读建议:
- 作者本人功底有限不太可能考虑到所有读者的阅读细节,建议读者先通盘阅读下本文,先熟悉本文中会出现哪些关键概念和关键流程,并配合上AI工具对文章中个别流程进行细致理解。
- 如果有关于LSM相关读写流程的卡点,可以参考
- 如果有LevelDB Version版本相关概念的卡点,请参考 -[LevelDB]LevelDB版本管理的黑魔法-为什么能在不锁表的情况下管理数据? ](blog.csdn.net/luog_aiyu/a…)
- 本文面向的受众,默认是对计算机的内存&磁盘等概念有简单了解的同志,如果存在部分术语存在理解gap,请自行百度解决,这边不做基础扫盲工作,节约大家的时间,感谢理解。
为什么需要Compaction
场景复现
任何技术都是有要解决的问题,都是为了满足某种特定的需求而存在的,接下来让我们来设想以下的场景。
- 假设我们调用LevelDB的接口对如下的数据进行写入操作,先写入 memtable 然后写入 sstable。
Put("a", "v1")
Put("b", "v1")
Put("c", "v1")
- 再次调用接口,对原有的数据进行更新和删除操作,并且再次刷写为 sstable。
Put("b", "v2")
Delete("c")
- 当前我们得到了2个刷写到磁盘上的文件即上图中绿色的文件。
等待解决的问题
ps:首先我们需要明确存储器的本质是在计算机系统提前存储我们需要的数据,其他的数据都可以不需要,因此如果能够将我们需要的数据缩减的足够小,系统的运转效率就会越高
那上图中的文件有哪些问题是可以被解决的呢?或者可以怎么操作能够让系统存储更少的数据?
- 空间浪费
对于上述的文件中, 其实等价于 下面的文件,其他的数据都可以被删除
Put("a", "v1")
Put("b", "v2")
多余的数据主要来源于两个方面
更新操作: 如果一个key被多次更新,本质上只需要保留最后一个kv即可,除非实现MVCC 删除操作: 在LSM架构中,如果想要删除一条记录,默认是通过添加一条删除记录来实现,因此这条数据会永远存在,并且需要一直存在
- 读放大严重(需要检索所有的文件才能获得想要的值) 如果想要读取 b键的值,那么需要读取 文件1和文件2 两个文件才能最终确认b的文件为v2
Compaction如何解决这些问题
简单来说,compaction会通过后台调度进程,读取这两个已经写入磁盘中的数据再进行一次合并。最后我们能得到如下的sstable。 todo:
PS: 不过当前考虑的是最简单的情况,真实情况下,并不会只有两个文件,也并不会只有一层的原始层级, 下面会跟各位读者详细介绍,在LevelDB中是如何一步步设计compaction,从而达到既能存储和访问的trade-off(取舍)。
Compaction前置信息补充
在介绍Compaction操作之前,需要先介绍操作基于的一些基本概念
- VersionSet: 用于管理当前LevelDB存储的所有历史版本Version。
- Version: Version 相当于在 sstable中用一个版本字段来进行版本控制。
- sstable: 在磁盘上存储levelDB数据的基本单元,具体细节可参考。
简单来说,Compaction 操作就是基于当前 Version 的文件分布,选择一组 sstable 文件进行合并、清理和上推,生成新的 sstable 文件和新的 Version,从而优化存储结构和查询效率。
Compaction 源码级解析-待更新todo
本部分仅适合对技术或者源码有了解诉求的同志,否则跳过即可,接下来是硬核内容。 PS: 这部分涉及概念很多,并且足够底层和细节,作者功底有限,很难保证100%讲清楚,敬请谅解
本次涉及代码范围
| 文件名 | 主要内容/作用 | 类型 |
|---|---|---|
| version_set.h/.cc | Version、VersionSet、Compaction 的定义与实现 | 核心逻辑 |
| version_edit.h/.cc | VersionEdit 的定义与实现,描述版本变更 | 核心逻辑 |
| version_set_test.cc | 版本管理相关的单元测试 | 测试代码 |
| version_edit_test.cc | 版本变更相关的单元测试 | 测试代码 |
| db_impl.cc/.h | 数据库主流程,内部用到版本管理 | 相关代码 |
| snapshot.h | 快照机制,依赖多版本能力 | 相关代码 |
Compaction-触发时机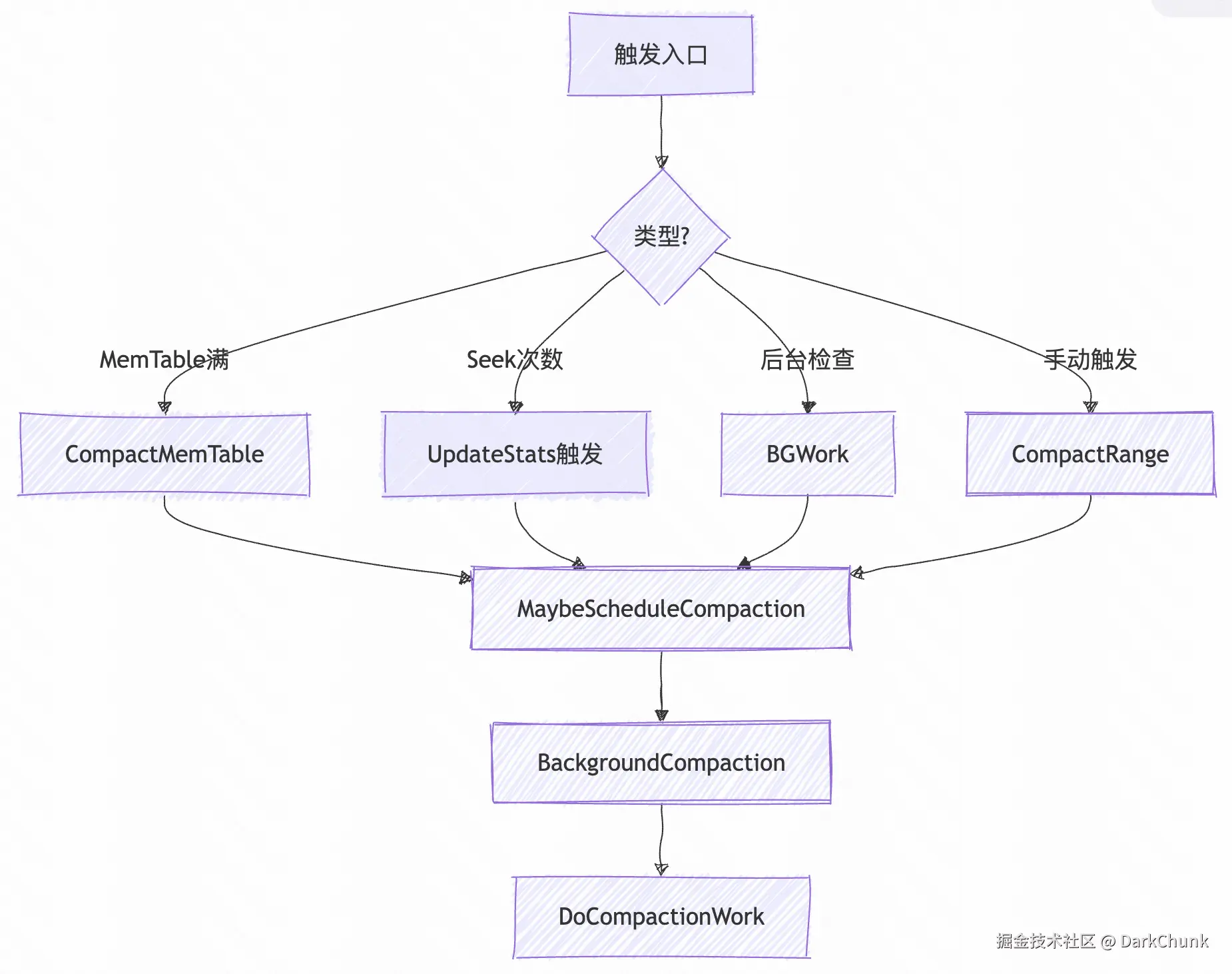
compaction主要有4种情况会被触发
- compactMemTable:当前内存过大就会触发
- 基于seek次数的compaction: 如果查询的次数变多,就会触发压缩。
- 后台检查:后台检查,如果当前level的块超过限度就会后台进行触发
- 手动触发: 调用 CompactRange 方法进行手动触发.
Compaction-具体执行细节-基于源代码详解
Compaction的具体执行主要分为下述的三个阶段
- 前置动作-内存压缩-磁盘压缩
前置动作
源代码详情
/ 记录开始时间
const uint64_t start_micros = env_->NowMicros();
int64_t imm_micros = 0; // 用于记录内存压缩表所需要消耗的时间
// 日志格式 输入数据数量,当前层级索引,输出数据数量,输出层级索引
Log(options_.info_log, "Compacting %d@%d + %d@%d files",
compact->compaction->num_input_files(0), compact->compaction->level(),
compact->compaction->num_input_files(1),
compact->compaction->level() + 1);
// 断言检查-压缩操作前提条件:
// 1. 当前层级至少有一个文件
// 2. 当前层级没有正在构建的输出文件
assert(versions_->NumLevelFiles(compact->compaction->level()) > 0);
assert(compact->builder == nullptr);
assert(compact->outfile == nullptr);
// 确定最小快照
// 如果不存在快照 就设置 最小快照为 当前版本中的最后一个序列号
if (snapshots_.empty()) {
compact->smallest_snapshot = versions_->LastSequence();
} else {
compact->smallest_snapshot = snapshots_.oldest()->sequence_number();
}
// 创建输入迭代器
Iterator* input = versions_->MakeInputIterator(compact->compaction);// 合并多个SSTable的数据
// 释放互斥锁
mutex_.Unlock(); // 释放持有的互斥锁, 因为压缩操作需要读取多个文件, 需要释放锁, 减少锁竞争
//初始化 输入迭代器
//
input->SeekToFirst();
Status status;
// 存储从输入迭代器中解析出的内部键,包含用户键,以及相关序列号和类型
ParsedInternalKey ikey;
std::string current_user_key;
bool has_current_user_key = false;
SequenceNumber last_sequence_for_key = kMaxSequenceNumber;
内存压缩
核心方法是compactMemory
源代码详情
/**
* 压缩内存表,将不可变内存表压缩为新的表文件,并更新版本集。
*/
void DBImpl::CompactMemTable() {
mutex_.AssertHeld();
assert(imm_ != nullptr);
VersionEdit edit;
Version* base = versions_->current();
base->Ref();
Status s = WriteLevel0Table(imm_, &edit, base);// 写入一个新的 Level0表文件, 更新edit 将内存表转换成SSTable
base->Unref();
if (s.ok() && shutting_down_.load(std::memory_order_acquire)) {
s = Status::IOError("Deleting DB during memtable compaction");
}
// 更新新的版本
if (s.ok()) {
edit.SetPrevLogNumber(0);
edit.SetLogNumber(logfile_number_); // Earlier logs no longer needed
s = versions_->LogAndApply(&edit, &mutex_);
}
if (s.ok()) {
// Commit to the new state
imm_->Unref();
imm_ = nullptr;
has_imm_.store(false, std::memory_order_release);
RemoveObsoleteFiles();// 删除过期的方法 逻辑等待解释
} else {
RecordBackgroundError(s);// 记录后台报错的方法
}
}
磁盘压缩
源代码详情:
if (!drop) {
// Open output file if necessary
if (compact->builder == nullptr) {
status = OpenCompactionOutputFile(compact);
if (!status.ok()) {
break;
}
}
if (compact->builder->NumEntries() == 0) {
compact->current_output()->smallest.DecodeFrom(key);
}
compact->current_output()->largest.DecodeFrom(key);
compact->builder->Add(key, input->value());
// Close output file if it is big enough
if (compact->builder->FileSize() >=
compact->compaction->MaxOutputFileSize()) {
status = FinishCompactionOutputFile(compact, input);
if (!status.ok()) {
break;
}
}
}
猜你喜欢
C++多线程: blog.csdn.net/luog_aiyu/a… 一文了解LevelDB数据库读取流程:blog.csdn.net/luog_aiyu/a… 一文了解LevelDB数据库写入流程:blog.csdn.net/luog_aiyu/a… 关于LevelDB存储架构到底怎么设计的:blog.csdn.net/luog_aiyu/a…
PS
你的赞是我很大的鼓励 我是darkchink,一个计算机相关从业者&一个摩托佬&AI狂热爱好者 本职工作是某互联网公司数据相关工作,欢迎来聊,内推或者交换信息 vx 二维码见: www.cnblogs.com/DarkChink/p…
