1 - 神经网络的反向传播
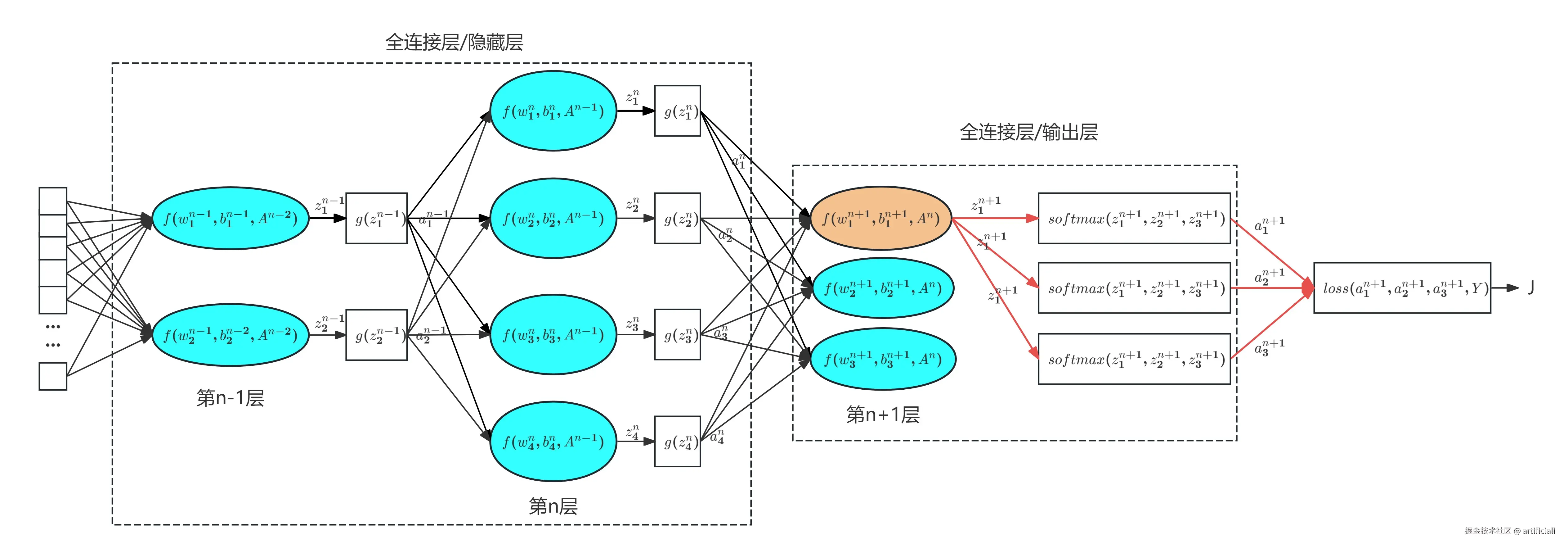 由于图片可知这个网络输出层维度为3
由于图片可知这个网络输出层维度为3
第n+1层为例第1个神经元参数w1n+1,b1n+1通过如下连锁变化影响损失函数J:
w1n+1−−>z1n+1−−>(a1n+1,a2n+1,a3n+1)−−>J
b1n+1−−>z1n+1−−>(a1n+1,a2n+1,a3n+1)−−>J
根据复合函数求导的链式法则:
dw1n+1=∂w1n+1∂J=∂a1n+1∂J∂z1n+1∂a1n+1∂w1n+1∂z1n+1+∂a2n+1∂J∂z1n+1∂a2n+1∂w1n+1∂z1n+1+∂a3n+1∂J∂z1n+1∂a1n+3∂w1n+1∂z1n+1=(∂a1n+1∂J∂z1n+1∂a1n+1+∂a2n+1∂J∂z1n+1∂a2n+1+∂a3n+1∂J∂z1n+1∂a3n+1)∂w1n+1∂z1n+1
db1n+1=∂b1n+1∂J=∂a1n+1∂J∂z1n+1∂a1n+1∂b1n+1∂z1n+1+∂a2n+1∂J∂z1n+1∂a2n+1∂b1n+1∂z1n+1+∂a3n+1∂J∂z1n+1∂a1n+3∂b1n+1∂z1n+1=(∂a1n+1∂J∂z1n+1∂a1n+1+∂a2n+1∂J∂z1n+1∂a2n+1+∂a3n+1∂J∂z1n+1∂a3n+1)∂b1n+1∂z1n+1
关键观察:
- 最后一项 ∂w1n+1∂z1n+1 是相同的:
-
因为 z1n+1=w1n+1⋅an+b1n+1,所以:
∂w1n+1∂z1n+1=an(对所有k都相同)
-
这一项与求和索引 k 无关,可以提到求和符号外面。
- 前两项 ∂akn+1∂J⋅∂z1n+1∂akn+1 是Softmax的耦合效应:
-
Softmax的每个输出 akn+1 受所有 zjn+1 影响,因此:
-
当 k=1:∂z1n+1∂a1n+1=a1n+1(1−a1n+1)
-
当 k=1:∂z1n+1∂akn+1=−akn+1a1n+1
-
这意味着 w1n+1 的梯度需要汇总所有输出神经元 a1n+1,a2n+1,a3n+1 的贡献。
结合网络结构分析上式,最后一项相等,将公共项 ∂w1n+1∂z1n+1=an 提出:前两项可以合并,得到
dw1n+1=dz1n+1∂w1n+1∂z1n+1
db1n+1=dz1n+1∂b1n+1∂z1n+1
同理可得:
dw2n+1=dz2n+1∂w2n+1∂z2n+1,db2n+1=dz2n+1∂b2n+1∂z2n+1
dw3n+1=dz3n+1∂w3n+1∂z3n+1,db3n+1=dz3n+1∂b3n+1∂z3n+1
给定数据计算:
权重矩阵 Wn+1:3个神经元,每个神经元有4个输入权重(对应前一层4个神经元)。
Wn+1=w1n+1w2n+1w3n+1=w1w5w9w2w6w10w3w7w11w4w8w12Bn+1=b1n+1b2n+1b3n+1=b1b2b3An=a1na2na3na4n=a11a12a13a14a21a22a23a24
对应前一层输入数据 An:4个神经元,2个样本(矩阵形式)。
根据前向传播原理,可以得到:
Zn+1=Wn+1An+Bn+1=z1n+1z2n+1z3n+1=z11z12z13z21z22z23=w1a11+w2a12+w3a13+w4a14+b1w5a11+w6a12+w7a13+w8a14+b2w9a11+w10a12+w11a13+w12a14+b3w1a21+w2a22+w3a23+w4a24+b1w5a21+w6a22+w7a23+w8a24+b2w9a21+w10a22+w11a23+w12a24+b3
向量的求导法则,可以推出:
由公式只看括号内就是dz1n+1=∂Z1n+1∂J
∂w1n+1∂J=(∂a1n+1∂J⋅∂z1n+1∂a1n+1+∂a2n+1∂J⋅∂z1n+1∂a2n+1+∂a3n+1∂J⋅∂z1n+1∂a3n+1)⋅∂w1n+1∂z1n+1
可得这一层的dZn+1=∂Zn+1∂J,由所有神经元拼接起来。
dZn+1=∂Zn+1∂J=∂z1n+1∂J∂z2n+1∂J∂z3n+1∂J=dz1n+1dz2n+1dz3n+1=∂z11∂J∂z12∂J∂z13∂J∂z21∂J∂z22∂J∂z23∂J=dz11dz12dz13dz21dz22dz23
∂w1n+1∂z1n+1=[∂w1∂z11∂w1∂z21∂w2∂z11∂w2∂z21∂w3∂z11∂w3∂z21∂w4∂z11∂w4∂z21]=(An)T,∂b1n+1∂z1n+1=[∂b1∂z11∂b1∂z21]=[11]
同理可得第2、3个神经元:
∂w2n+1∂z2n+1=(An)T,∂b2n+1∂z2n+1=[11]
∂w3n+1∂z3n+1=(An)T,∂b3n+1∂z3n+1=[11]
综上,根据dw1n+1,dw2n+1,dw3n+1,db1n+1,db2n+1,db3n+1的计算结果,得到损失函数J对Wn+1,Bn+1的梯度:
由于公式dw1n+1=dz1n+1∂w1n+1∂z1n+1可得这一层的dWn+1,由所有神经元拼接起来。
dWn+1=dw1n+1dw2n+1dw3n+1=dz1n+1(An)Tdz2n+1(An)Tdz3n+1(An)T=dz1n+1dz2n+1dz3n+1(An)T=dz11dz12dz13dz21dz22dz23(An)T=dZn+1(An)T
dBn+1=db1n+1db2n+1db3n+1=dz1n+1dz2n+1dz3n+1[11]=dz11dz12dz13dz21dz22dz23[11]=sum(dZn+1,axis=1)
维度验证
- 这一层:dWn+1=dZn+1⋅(An)T=[3,2][2,4]=[3,4]
- dZn+1 形状:3×2(3个神经元,2个样本)
- An 形状:4×2(4个输入神经元,2个样本)
- (An)T 形状:2×4
- 结果 dWn+1 形状:3×4(与 Wn+1 一致)
- 单个神经元: dw1n+1=dz1n+1∂w1n+1∂z1n+1=dz1n+1(An)T=[1,2][2,4]=[1,4]
- 这个dz1n+1是[1,2],当激活函数g=softmax、损失函数J为交叉熵时的维度验证有详细介绍,[1,4]表示:是第1个神经元的权重梯度
按照同样的方法计算损失函数J对任意全连接层参数Wn,Bn的梯度,比较其结果,可以得到如下结论:
结论一:误差J对任意全连接层参数Wn,Bn的梯度由以下公式计算:
- dWn=dZn(An−1)T
- dBn=sum(dZn,axis=1)
sum(dZn,axis=1)表示在dZn的水平方向累加,得到一个n*1的向量,n表示层号。
2 - 误差对全连接层线性输出的梯度
由结论一可知,计算梯度dWn,dBn需要首先计算损失函数J对线性输出Zn的梯度dZn,而计算dZn会根据激活函数来确定。由于softmax激活函数不同于一般的激活函数,根据作用于Zn的激活函数g是否为softmax函数把计算dZn分成两种情况。
当激活函数g=softmax、损失函数J为交叉熵时
softmax激活函数应用于网络的最后一层(输出层),其作用是输出样本的预测概率分布。以上图为例,神经网络第n+1层(输出层)的激活函数g为softmax,根据网络结构以及向量的求导法则,可以推出:
dZn+1=dz1n+1dz2n+1dz3n+1=∂a1n+1∂J∂z1n+1∂a1n+1+∂a2n+1∂J∂z1n+1∂a2n+1+∂a3n+1∂J∂z1n+1∂a3n+1∂a1n+1∂J∂z2n+1∂a1n+1+∂a2n+1∂J∂z2n+1∂a2n+1+∂a3n+1∂J∂z2n+1∂a3n+1∂a1n+1∂J∂z3n+1∂a1n+1+∂a2n+1∂J∂z3n+1∂a2n+1+∂a3n+1∂J∂z3n+1∂a3n+1=da1n+1∂z1n+1∂a1n+1+da2n+1∂z1n+1∂a2n+1+da3n+1∂z1n+1∂a3n+1da1n+1∂z2n+1∂a1n+1+da2n+1∂z2n+1∂a2n+1+da3n+1∂z2n+1∂a3n+1da1n+1∂z3n+1∂a1n+1+da2n+1∂z3n+1∂a2n+1+da3n+1∂z3n+1∂a3n+1(1)
又因为:
An+1=softmax(Zn+1)=a1n+1a2n+1a3n+1)=a11a12a13a21a22a23=ez11+ez12+ez13ez11ez11+ez12+ez13ez12ez11+ez12+ez13ez13ez21+ez22+ez23ez21ez21+ez22+ez23ez22ez21+ez22+ez23ez23
解释:这里的分母是一个样本,竖着看的求和。
Y=y11y12y13y21y22y23
根据交叉熵损失函数的定义可知:
J=E(Y,A)=−n1j=1∑ni=1∑myjilog(aji)=−21(y11log(a11)+y12log(a12)+y13log(a13)+y21log(a21)+y22log(a22)+y23log(a23))
n表示样本的数量,yji表示第j个样本是第i个类别的真实概率,aji表示第j个样本是第i个类别的预测概率。为保证结果书写简洁,后续求导过程中暂不考虑常数项-1/2
按照向量的求导法则,可以得到以下结果:
da1n+1=∂a1n+1∂J=[∂a11∂J∂a21∂J]=[a11y11a21y21]
补充:维度[1,2],对 J=yloge(a) 求导y是真实标签,对a求导∂a∂J=ay,同理
da2n+1=∂a2n+1∂J=[∂a12∂J∂a22∂J]=[a12y12a22y22]
da3n+1=∂a3n+1∂J=[∂a13∂J∂a23∂J]=[a13y13a23y23]
下面是softmax 函数偏导数,维度[2,2]
∂z1n+1∂a1n+1=[∂z11∂a11∂z11∂a21∂z21∂a11∂z21∂a21]=[(ez11+ez12+ez13)2ez11(ez12+ez13)00(ez21+ez22+ez23)2ez21(ez22+ez23)]=[a11(1−a11)00a21(1−a21)]
同理可得到:
∂z2n+1∂a1n+1=[−a11a1200−a21a22],∂z3n+1∂a1n+1=[−a11a1300−a21a23]
∂z1n+1∂a2n+1=[−a11a1200−a21a22]∂z2n+1∂a2n+1=[a12(1−a12)00a22(1−a22)]∂z3n+1∂a2n+1=[−a12a1300−a22a23]
∂z1n+1∂a3n+1=[−a11a1300−a21a23]∂z2n+1∂a3n+1=[−a13a1200−a23a22]∂z3n+1∂a3n+1=[a13(1−a13)00a23(1−a23)]
把上述求导结果带入式(1),并乘以−21,得到:
dZn+1=21(A−Y)
维度验证
- 单个神经元:
dz1n+1=da1n+1∂z1n+1∂a1n+1=[1,2][2,2]=[1,2]
- 这一层:
dZn+1就是[3,2],有三个类别(神经元),两个样本。
综上,可以得到如下结论:
结论二:如果输出层激活函数为softmax,损失函数为交叉熵损失,则误差对输出层线性组合Z的梯度:
dZ=m1(A−Y)
m表示样本的个数,A是softmax层的激活输出,Y是基于one-hot编码的样本真实概率分布。
当激活函数g!=softmax,损失函数J为交叉熵时
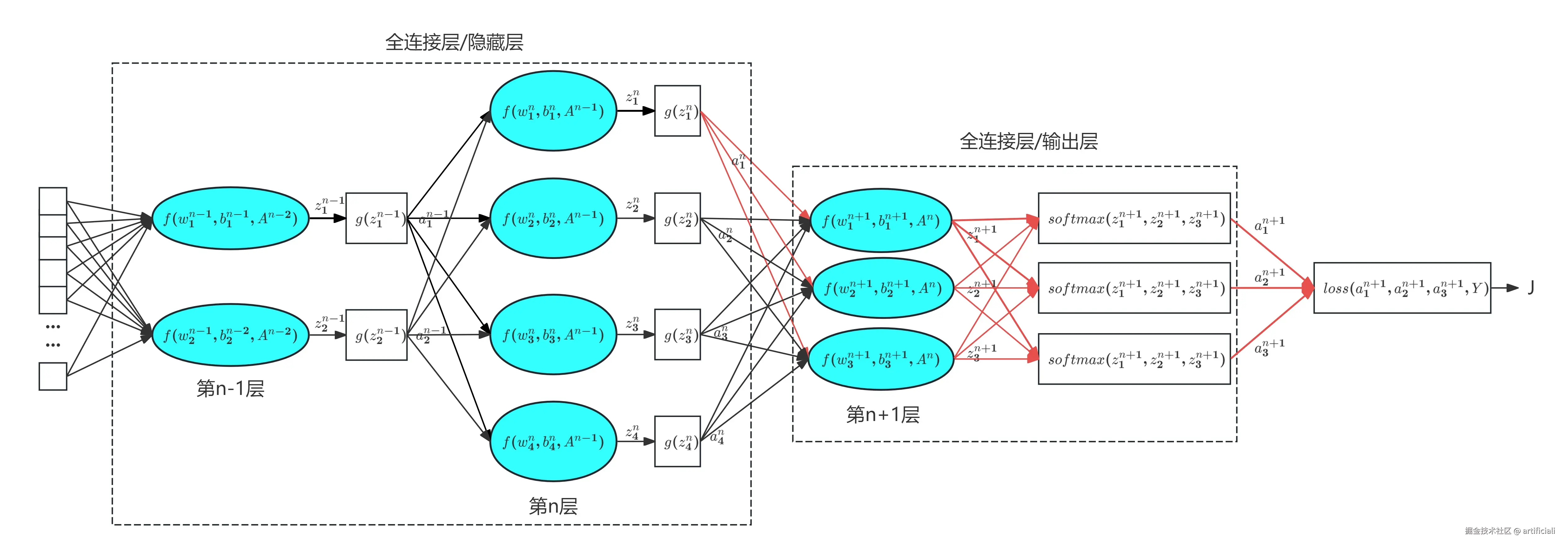
由上图可知,第n层的激活函数g!=softmax,第1个神经元线性输出z1n会通过以下连锁变化改变损失函数的值。
z1n−−>a1n−−>(z1n+1,z2n+1,z3n+1)−−>(a1n+1,a2n+1,a3n+1)−−>J
dz1n=∂a3n+1∂J∂z1n+1∂a3n+1∂a1n∂z1n+1∂z1n∂a1n+∂a3n+1∂J∂z2n+1∂a3n+1∂a1n∂z2n+1∂z1n∂a1n+∂a3n+1∂J∂z3n+1∂a3n+1∂a1n∂z3n+1∂z1n∂a1n+∂a2n+1∂J∂z1n+1∂a2n+1∂a1n∂z1n+1∂z1n∂a1n+∂a2n+1∂J∂z2n+1∂a2n+1∂a1n∂z2n+1∂z1n∂a1n+∂a2n+1∂J∂z3n+1∂a2n+1∂a1n∂z3n+1∂z1n∂a1n+∂a1n+1∂J∂z1n+1∂a1n+1∂a1n∂z1n+1∂z1n∂a1n+∂a1n+1∂J∂z2n+1∂a1n+1∂a1n∂z2n+1∂z1n∂a1n+∂a1n+1∂J∂z3n+1∂a1n+1∂a1n∂z3n+1∂z1n∂a1n
分析上式,可以发现:
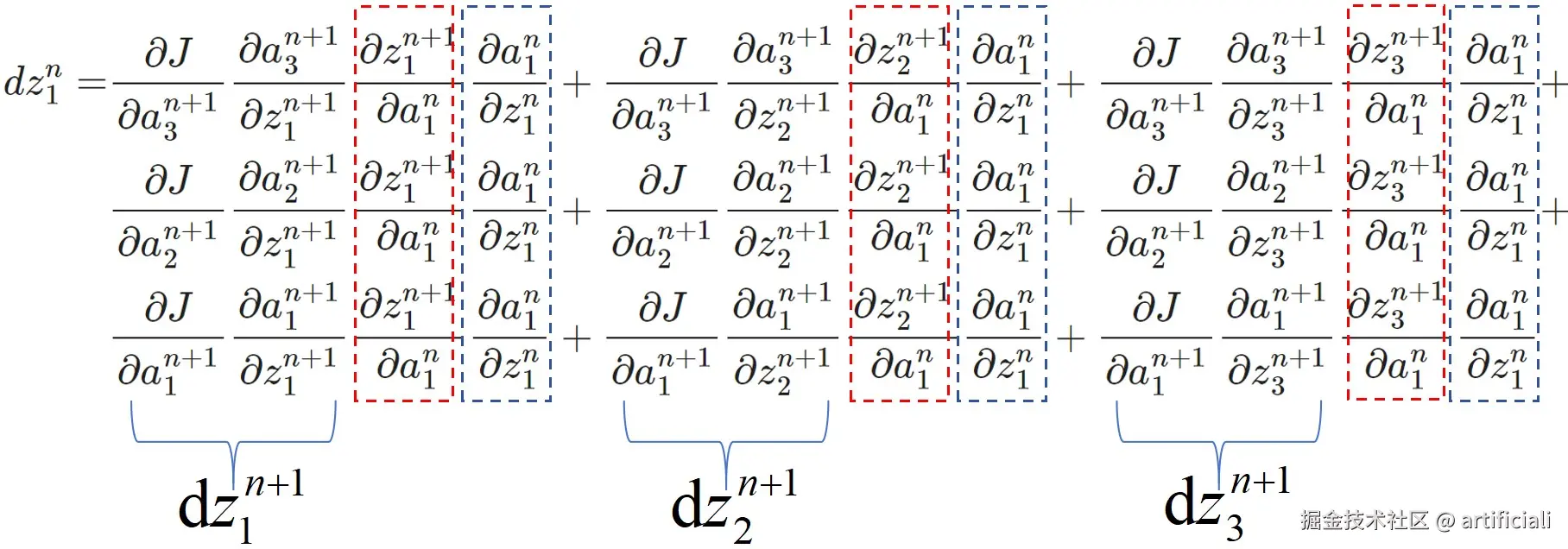

这个式子水平三个式子代表红色的线,竖直代表蓝色的线,也就是蓝色括号,可以按照最上面的公式化简,如下图

定义第 n+1 层的局部梯度:dzkn+1=∂zkn+1∂J=∂akn+1∂J⋅∂zkn+1∂akn+1
得到:
dz1n=(dz1n+1∂a1n∂z1n+1+dz2n+1∂a1n∂z2n+1+dz3n+1∂a1n∂z3n+1)∂z1n∂a1n
同理,可以推出:
dz2n=(dz1n+1∂a2n∂z1n+1+dz2n+1∂a2n∂z2n+1+dz3n+1∂a2n∂z3n+1)∂z2n∂a2n
dz3n=(dz1n+1∂a3n∂z1n+1+dz2n+1∂a3n∂z2n+1+dz3n+1∂a3n∂z3n+1)∂z3n∂a3n
dz4n=(dz1n+1∂a4n∂z1n+1+dz2n+1∂a4n∂z2n+1+dz3n+1∂a4n∂z3n+1)∂z4n∂a4n
列出前面(给定数据计算)给定的数据:
Wn+1=w1w5w9w2w6w10w3w7w11w4w8w12,Bn+1=b1b2b3,An=a1na2na3na4n=a11a12a13a14a21a22a23a24
向量的求导法则,可以推出:
Zn+1=Wn+1An+Bn+1=z1n+1z2n+1z3n+1=z11z12z13z21z22z23=w1a11+w2a12+w3a13+w4a14+b1w5a11+w6a12+w7a13+w8a14+b2w9a11+w10a12+w11a13+w12a14+b3w1a21+w2a22+w3a23+w4a24+b1w5a21+w6a22+w7a23+w8a24+b2w9a21+w10a22+w11a23+w12a24+b3
应用向量的求导法则,可以推出:
第 n+1 层神经元线性输出 zkn+1 对第 n 层激活值 a1n 的偏导数
∂a1n∂z1n+1=[∂a11∂z11∂a11∂z21∂a21∂z11∂a21∂z21]=[w100w1],∂a1n∂z2n+1=[∂a11∂z12∂a11∂z22∂a21∂z12∂a21∂z22]=[w500w5],∂a1n∂z3n+1=[∂a11∂z13∂a11∂z23∂a21∂z13∂a21∂z23]=[w900w9]
第 n 层第2、3、4个神经元的梯度(类似推导)
∂a2n∂z1n+1=[∂a12∂z11∂a12∂z21∂a22∂z11∂a22∂z21]=[w200w2],∂a2n∂z2n+1=[∂a12∂z12∂a12∂z22∂a22∂z12∂a22∂z22]=[w600w6],∂a2n∂z3n+1=[∂a12∂z13∂a12∂z23∂a22∂z13∂a22∂z23]=[w1000w10]
∂a3n∂z1n+1=[∂a13∂z11∂a13∂z21∂a23∂z11∂a23∂z21]=[w300w3],∂a3n∂z2n+1=[∂a13∂z12∂a13∂z22∂a23∂z12∂a23∂z22]=[w700w7],∂a3n∂z3n+1=[∂a13∂z13∂a13∂z23∂a23∂z13∂a23∂z23]=[w1100w11]
∂a4n∂z1n+1=[∂a14∂z11∂a14∂z21∂a24∂z11∂a24∂z21]=[w400w4],∂a3n∂z2n+1=[∂a14∂z12∂a14∂z22∂a24∂z12∂a24∂z22]=[w800w8],∂a3n∂z3n+1=[∂a14∂z13∂a14∂z23∂a24∂z13∂a24∂z23]=[w1200w12]
结合dz1n,dz2n,dz3n,dz4n的计算公式:
第 n 层第1个神经元的梯度
dz1n=(dz1n+1∂a1n∂z1n+1+dz2n+1∂a1n∂z2n+1+dz3n+1∂a1n∂z3n+1)∂z1n∂a1n=(dz1n+1[w100w1]+dz2n+1[w500w5]+dz3n+1[w900w9])∂z1n∂a1n
维度计算:([1,2][2,2])∗[2,2]=[1,2],注意∂a1n/∂z1n(2x2 的对角矩阵)
第 n 层第2、3、4个神经元的梯度(类似推导)
dz2n=(dz1n+1[w200w2]+dz2n+1[w600w6]+dz3n+1[w1000w10])∂z2n∂a2n
dz3n=(dz1n+1[w300w3]+dz2n+1[w700w7]+dz3n+1[w1100w11])∂z3n∂a3n
dz4n=(dz1n+1[w400w4]+dz2n+1[w800w8]+dz3n+1[w1200w12])∂z4n∂a4n
又因为损失函数J对Zn+1的梯度:
dZn+1=dz1n+1dz2n+1dz3n+1=dz11dz12dz13dz21dz22dz23
带入dz1n,dz2n,dz3n,dz4n可得:
dz1n=[w1dz11+w5dz12+w9dz13w1dz21+w5dz22+w9dz23]∂z1n∂a1n
dz2n=[w2dz11+w6dz12+w10dz13w2dz21+w6dz22+w10dz23]∂z2n∂a2n
dz3n=[w3dz11+w7dz12+w11dz13w3dz21+w7dz22+w11dz23]∂z3n∂a3n
dz4n=[w4dz11+w8dz12+w12dz13w4dz21+w8dz22+w12dz23]∂z4n∂a4n
又因为:An 是第 n 层的激活值矩阵,由该层的线性输出 Zn 经过逐元素(element-wise)激活函数 g(⋅) 计算得到。具体来说:
An=g(Zn)=g(z1nz2nz3nz4n)=g(z1n)g(z2n)g(z3n)g(z4n)=a1na2na3na4n
其中ain=g(zin) 是第 i 个神经元的激活值(仍为 1×2 向量,对应 2 个样本),这一层输出维度依然是[4.2],一个神经元是输出是[1,2],但是他的反向求导是[2,2]的对称矩阵。
所以:
∂Zng(Zn)=∂z1n∂a1n∂z2n∂a2n∂z3n∂a3n∂z4n∂a4n在反向传播中,∂Zn∂An 是一个对角矩阵(因为 g 是逐元素的)
示例(ReLU 激活函数)
假设 g(z)=ReLU(z)=max(0,z),且:
Zn=1.0−2.00.00.5−0.53.00.5−1.0
则:
An=ReLU(Zn)=max(0,1.0)max(0,−2.0)max(0,0.0)max(0,0.5)max(0,−0.5)max(0,3.0)max(0,0.5)max(0,−1.0)=1.00.00.00.50.03.00.50.0
- 每一行 对应一个神经元的输出(如 z1n=[z11,z12] 是第 1 个神经元对 2 个样本的线性输出)。
- 每一列 对应一个样本(如第 1 列 [z11,z21,z31,z41]T 是第一个样本在 4 个神经元上的输出)。
维度验证:
含义:第n层的输出
- 这一层:dZn=dz1ndz2ndz3ndz4n=((Wn+1)T⋅dZn+1)⊙∂Zn∂g(Zn)=[4,3][3,2]=[4,2]
- (Wn+1)T.shape=[4,3]
- dZn+1.shape=[3,2]
- ∂Zng(Zn).shape=[4,2]
单个神经元梯度验证:
梯度计算:每个神经元 dzin 的梯度由权重与上层梯度的线性组合构成,
- 例如第一个神经元:dz1n=(w1⋅dz1n+1+w5⋅dz2n+1+w9⋅dz3n+1)⊙∂z1n∂a1n=[1,2][2,2]∗[2,2]=[1,2]
- 逐元素乘法:∂z1n∂a1n 维度为 [1×2]。
- 输出维度:dz1n 维度为 [1×2],符合逐样本梯度计算,就是一个神经元输出两个样本。
前向传播维度验证:
- 输入:第 n 层激活值 An 维度为 [4×2](4 个神经元,2 个样本)。
- 权重矩阵:Wn+1 维度为 [3×4],偏置 Bn+1 维度为 [3×1]。
- 线性输出:Zn+1=Wn+1An+Bn+1=[4×2][3×4]=[3×2],维度为 [3×2](3 个神经元,2 个样本)。
所以得到一下结论:
- 前向传播:Zn+1=Wn+1An+Bn+1,维度从 [4×2] 转换为 [3×2]。
- 反向传播:dZn=((Wn+1)T⋅dZn+1)⊙∂Zn∂g(Zn),维度从 [3×2] 恢复为 [4×2],确保梯度逐层回传。
- 维度验证总结:单个神经元梯度:dzin 的维度为 [1×2],符合逐样本梯度计算。
整体梯度矩阵:dZn 维度为 [4×2],与 Zn 一致,验证了反向传播公式的维度正确性。
分析dz1n,dz2n,dz3n,dz3n,∂Zng(Zn)的最终形式,利用矩阵的乘法规则,可以得到如下结论:
结论三:如果全连接层的激活函数g不是softmax,损失函数为交叉熵损失,则误差对线性组合Z的梯度:
dZn=dz1ndz2ndz3ndz4n=((Wn+1)T⋅dZn+1)⊙∂Zn∂g(Zn)
- 其中g表示激活函数,可以是relu或者tan。符号*表示左右2个矩阵的对应元素相乘,结果是同样大小的矩阵。


