

LLM是啥
LLM的本质是人工神经网络,而神经网络只能接受数字作为输入,并只能输出数字,其中用小学数学描述就是加法和乘法的运算。
Understanding LLMs from Scratch Using Middle School Math | Towards Data Science
看完文章大概理解,LLM从输入预测下一个token,然后把上一个输出+token重新作为输入,然后再预测下一个token的迭代过程。
如果把AI的基准设置成一个人,那么LLM就只剩下一个脑子、一只耳朵、一张嘴,没了,硬要说的话,把它当成一个嘴强王者就行了。
LLM如何调用外部工具
大家都知道,语言生成模型就知道“胡说八道”,比如你让deepseek简单滴查询一下天气
> 广州天气
# Deepseek V3
> 您可以通过以下方式获取广州的最新天气情况:
天气预报网站或应用:访问中国气象局官网(www.cma.gov.cn)或使用第三方天气应用(如墨迹天气、彩云天气等)。
搜索引擎:直接在百度、Google等搜索引擎输入“广州天气”即可获取实时天气信息。
本地新闻报道:广州本地的新闻媒体或电视台通常会播报最新的天气动态。
短信或微信订阅:部分城市提供天气预报短信服务,也可以通过微信小程序查询。
以下是广州天气的一般特点:
气候类型:亚热带季风气候。
夏季:炎热潮湿,常有降雨或台风。
冬季:温和干燥,偶尔有寒潮。
春秋季:温暖舒适,降雨较少。
如果需要实时数据,请查询最新的天气预报以获得准确信息!
它可以告诉你去别的地方去查,本身不会告诉你结果,又或者
> 广州天气
# DeepSeek V3 0324
> 广州目前的天气情况如下(2023年10月数据,仅供参考,建议查看实时天气):
气温:25~32℃左右,日间较热,早晚稍凉。
天气状况:以多云或晴天为主,偶有短时阵雨,湿度较高。
建议穿着:短袖+薄外套(应对室内外温差),出门可带折叠伞。
空气质量:轻度到中度污染(PM2.5可能偏高)。
实时更新建议:
可通过“中国天气网”或“广东气象台”官网获取最新预报,或使用“墨迹天气”“彩云天气”等APP查看分钟级降水预测。
如需更详细的信息(如未来一周预报或台风动态),可告知具体需求哦!
它会告诉你一些符合输出的“假”数据,产生“幻觉”,让你产生疑惑,这TiMi到底行不行。
外部工具
假如,我说假如,如果当输入查询某地天气的时候,LLM给我返回一个特定的格式而不是胡说八道会怎样
> 广州天气
# any LLM
>
<tool_call>
{"name": "getWeather", "arguments": {"city": "广州"}}
</tool_call>
那接下来是不是可以把内容转换一下
-
name值:getWeather当成API函数签名
-
arguments值:当成API函数实参
那再然后有了API签名和实参,把文本转成具体函数是不是就可以调用,那调用算不算使用了外部工具?
func callExternal() (resp interface{}) {
......
// 1. chat with LLM
resp, err := api.chatToLLM()
// 2. extract specified format
fn := response["tool_call"]["name"]
args := make(map[string]interface{})
args["city"] = response["tool_call"]["city"]
// 3. exec external tool
switch fn {
case "getWeather":
......
}
}
这不就找到了一种LLM调用外部工具的思路咯?那关键的只剩一个点,LLM如何产生特定格式。
如何输出特定格式
-
LLM直接生成特定格式,Function Call
-
设定提示词,然后由LLM根据提示词生成
Function Call
OpenAI当初宣布支持Function Call的时候,并没有公布训练思路,也不知道训练的对话数据集,但是可以确定的是,Function Call是由基底模型通过后训练微调得到的,所以只能通过OpenAI的API使用FC特性,对的,你只能通过SDK使用。
from openai import OpenAI
def send_messages(messages):
response = client.chat.completions.create(
model="deepseek-chat",
messages=messages,
tools=tools
)
return response.choices[0].message
client = OpenAI(
api_key="<your api key>",
base_url="https://api.deepseek.com",
)
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get weather of city, the user shoud supply a location first",
"parameters": {
"type": "object",
"properties": {
"city": {
"type": "string",
"description": "The city and state, e.g. Guangzhou",
}
},
"required": ["city"]
},
}
},
]
这就是使用步骤,把你要定义的API签名在tools字段告诉LLM,当你实际对话的时候,模型自己去预测要不要调用tools,如果有调用,就会返回上面所说的特定的格式。
当然也有 ToolenGPT:NeurIPS-2023-toolkengpt-augmenting-frozen-language-models-with-massive-tools-via-tool-embeddings-Paper-Conference,这篇论文给出一种如何使得LLM输出这种特定格式的思路
通过预设提示词产生特定格式
通过后训练微调LLM支持FC不是一般人玩得起的呀,数据集怎么设计,微调也得有硬件支持,你以为不要钱的啊?所以,提示词才是平民玩家的选择。
<|im_start|>system
You may call one or more functions to assist with the user query
You are provided with function signatures within <tools></tools> XML tags:
<tools>
{"name": "getWeather", "description": "获取指定城市的天气", "parameters": {"type": "object", "properties": {"city": {"type": "string", "description": "城市名称"}, "date": {"type": "string", "description": "请求天气的日期"}}, "required": ["city"]}}
</tools>
For each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:
<tool_call>
{"name": "<function-name>", "arguments": <args-json-object>}
</tool_call>
<|im_end|>
<|im_start|>user
请查询广州的天气
<|im_end|>
比如你在使用SDK的时候把这份提示词append到最开始的上下文,又或者用AI客户端工具把提示提设定好。
测试一下
比如我在CherryStudio中设定好提示词
MCP又是个啥?
看流程,Call Format是LLM给出的调用外部工具的特定格式,MCP描述的就是从这里开始如何规范使用外部工具的协议。
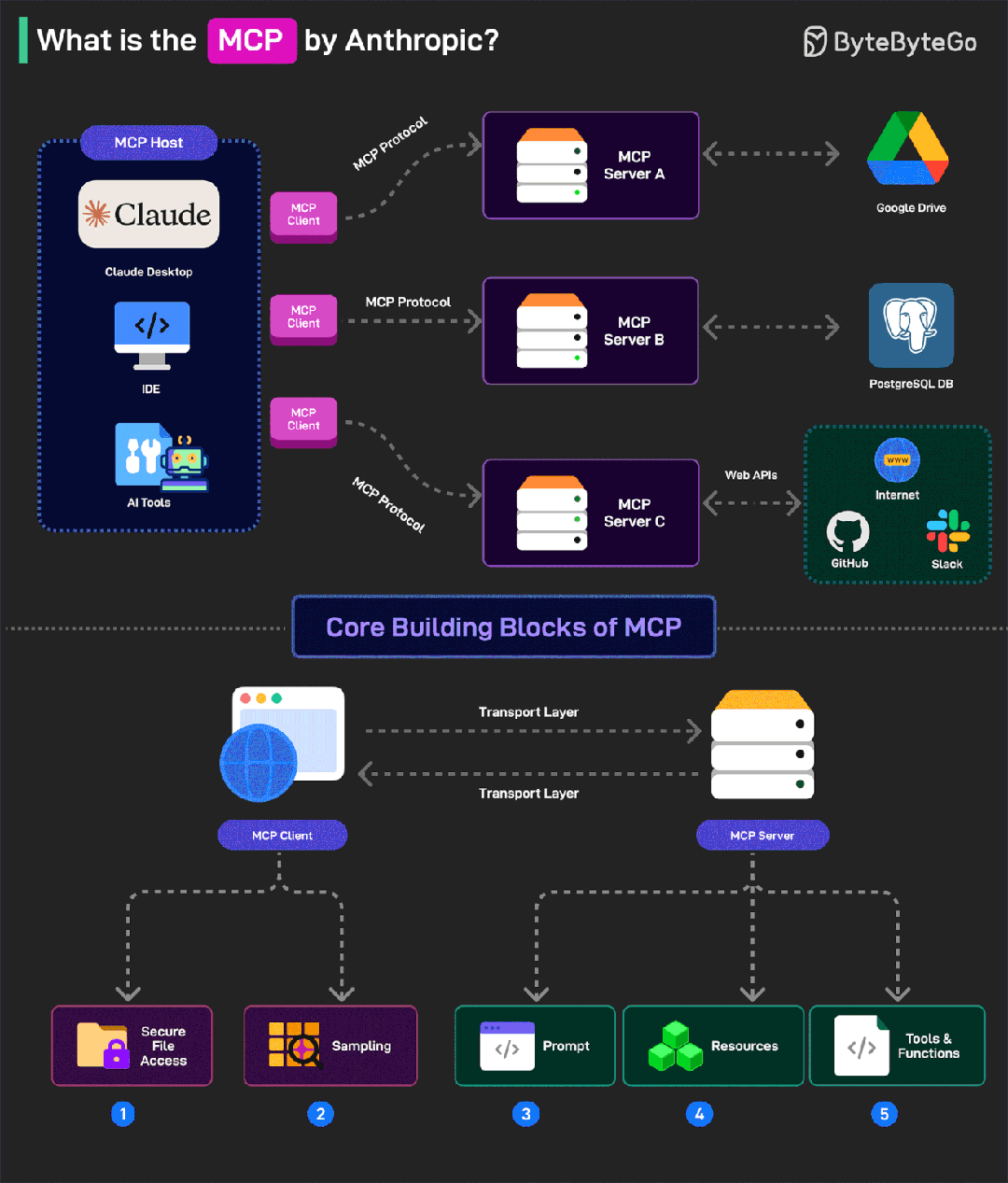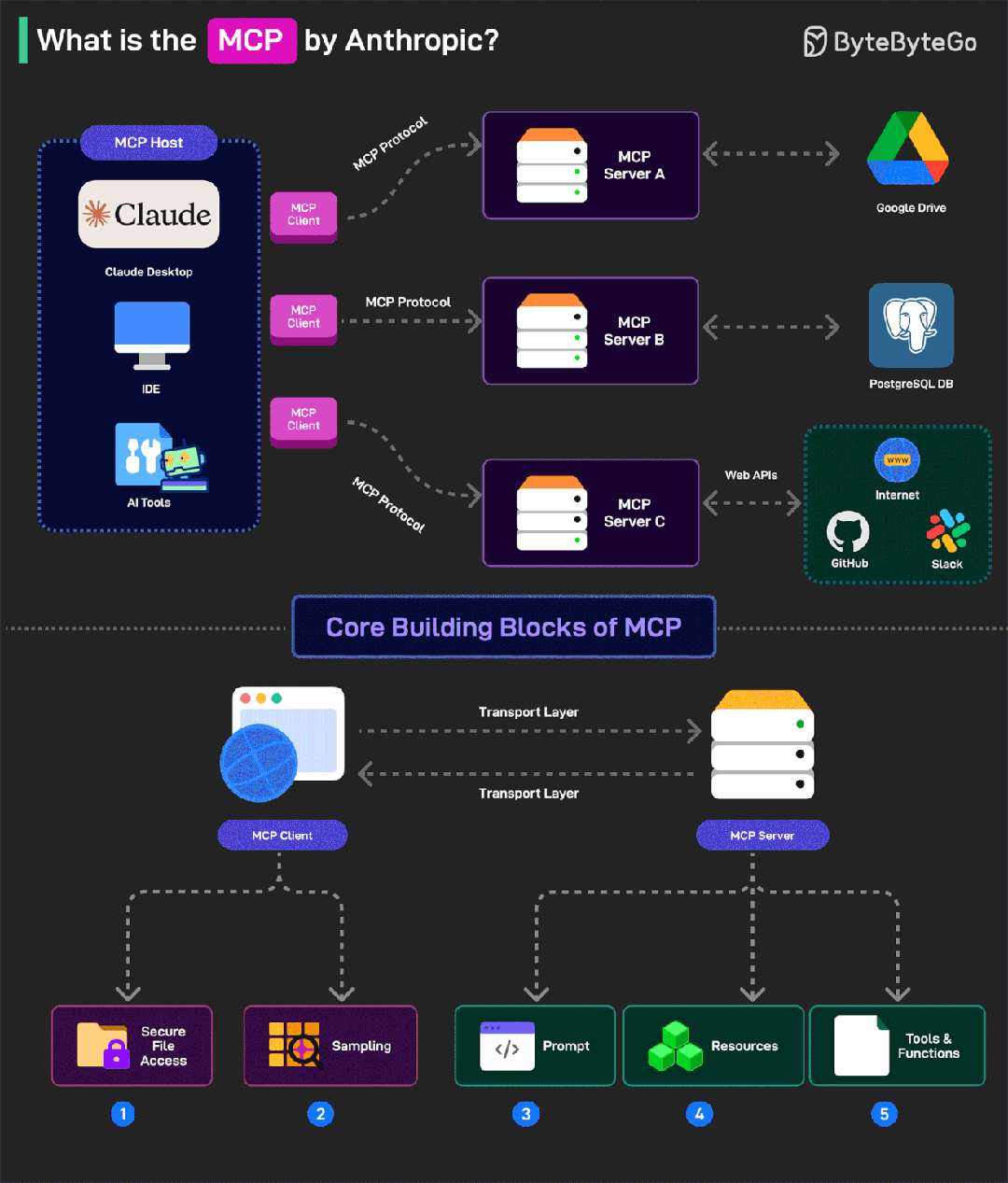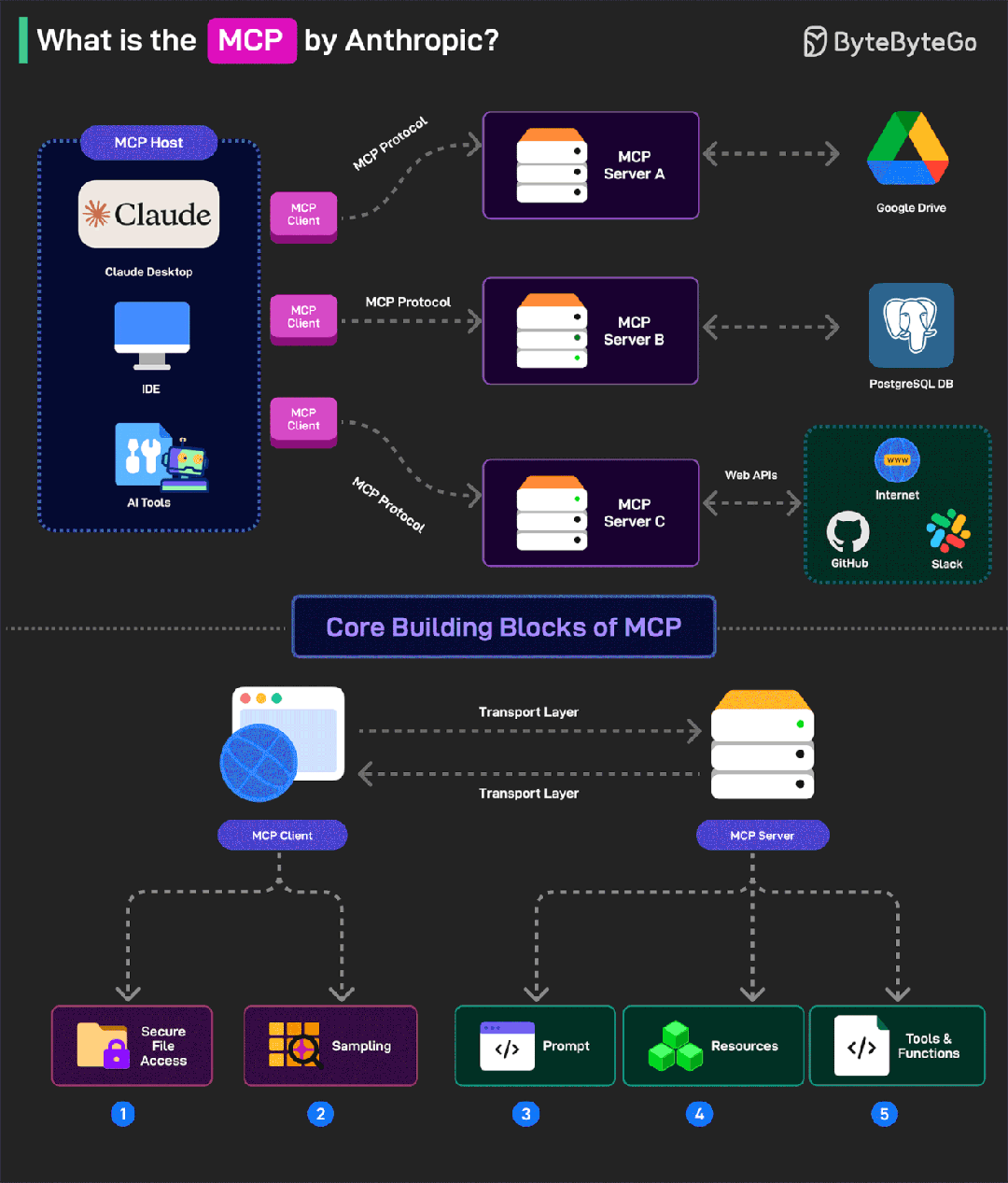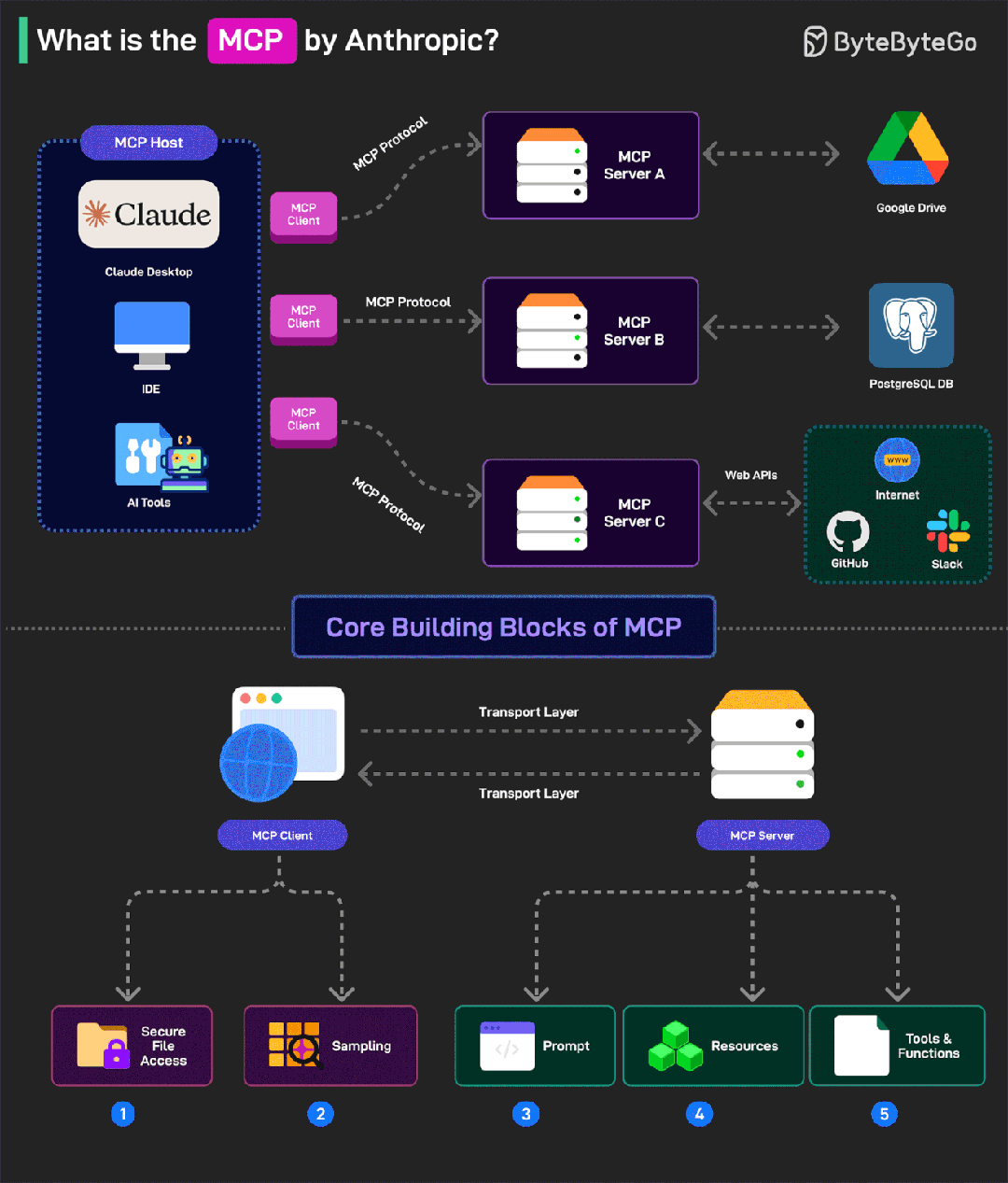
这下看懂了吧,你可以说MCP扩充了FC,也可以说MCP和FC一点屌关系都没有,MCP没有关注LLM是如何产生特定格式的,你是Function Call也好,提示词模板也好,只要特定格式给到MCP的Client,就可以通过Client根据格式调用外部的工具。
Specification - Model Context Protocol
Agent才是终极形态
假设你提问:B站Top10播放量视频,以网页输出
通过LLM一轮又一轮的的推理对话,拆解出可实现的步骤逻辑:
-
B站的网址是什么?需要爬虫工具抓取信息
-
排序播放量最高的视频
-
下载视频文件并存入数据库
-
markdown格式写入数据,保存文件
-
输出HTML/CSS构建的文件
-
......
这玩意就是策划给Agent提了个需求,然后Agent自主思考(推理型LLM),任务规划(LLM预测可执行步骤),并调用外部工具(FC/MCP),完成目标。这才是偷懒的终极目标。
