

该项目用来做什么的
这个项目是一个综合性的点评系统,涵盖了优惠卷管理,订单管理,消息队列等功能。是为用户提供店铺点评和优惠券购买服务的,同时为商家提供优惠卷发布和订单管理服务。
Redis项目中遇到的技术难点
使用悲观锁解决超卖问题时,我一上来使用synchronized锁住了整个方法,这显然是有问题的,如果不同线程访问当前方法难道会进行锁的竞争吗,肯定不会,所以不应该锁住整个方法,我们需要锁住相同用户id的createVoucherOrder方法防止一人买多个优惠卷。既然我们要锁userid,需要先把userid变成String,userid.toString但是toString的底层是创建个新的String也就是对象地址改变了,而synchronized锁的是内存地址,所以我们使用了intern方法从常量池中寻找与userid相同的字符串的地址,这个是不变的。在抢购秒杀卷这个方法中调用了创建订单的方法,而在同一个类的内部一个方法调用另一个事务方法这时就需要使用动态代理来进行调用了,而不能使用this直接调用。
JWT
createJWT里用了jwts.builders,而parseJWT用了jwts.parse
用Hash存储能比用String存储少用点内存,因为Hash的value只存储数据本身而不用把数据变为Json存储。
threadlocal中存储的不是token而是用户每次请求携带的token解析出来的用户信息
验证手机号:正则表达式
拦截器:Spring MVC框架,HTTP请求处理过程中会自动触发preHandle
刷新token:StringRedisTemplate.expire(key, val, val的单位)
怎么进行调优的
使用Redis缓存代替数据库,使用本地缓存缓存部分热点数据,使用消息队列RabbitMQ进行异步接收消息。
分布式ID
时间戳(往前移动一定的位数) + 序列号(固定的字符串+传入的字符串+时间字符串(进行自增)) 全局唯一ID:时间戳+序列号+数据库自增
分布式锁
满足集群下的多线程可见并且互斥的锁 Redis实现分布式锁:SETNX
- 获取锁:
- 互斥:确保只能有一个线程获取锁
- 非阻塞:尝试一次,成功返回true,失败返回false
- 释放锁的方式:
- 手动释放
- 超时释放:获取锁时添加一个超时时间
缓存击穿:
互斥锁:tryLock + double check
首先check是否获取到锁没获取到进行重试,再check从数据库获取的是否是空的。更加容易实现,但是容易产生死锁。
逻辑过期:先进性缓存预热(查询数据库的数据,重新更新到缓存中)
到缓存中查看是否过期,如果过期那就获取锁,异步开启线程进行重置逻辑过期时间,异步线程进行的同时原先的线程会返回脏读数据。
超卖问题:
单机下的一人一单:限制每个用户一人一单(抢优惠券的场景)
解决方式悲观锁(适合新增数据):适合写入操作多,冲突频繁的场景
该场景下也可以用乐观锁的版本号法来进行上锁, CAS是用某个字段作为标准来判断前后数据是否变化了,那订单号下订单后又不会改变,而版本号法可以新增个用于存在性判断的字段,正好当前一人一单的逻辑也是判断是否有响应的订单存在。只不过比较麻烦要新增字段,所以不用了
- 注意事项:
- synchronized尽量锁代码块而不是锁整个方法,锁的粒度越大,性能越低
- 锁的对象一定要是一个不变的值 userId.toString().intern()
- 我们要锁住整个事务,而不是锁住事务内部的代码。如果我们锁住事务内部的代码会导致其它线程能够进入事务,当我们事务还未提交,其他线程读取了未提交的数据的中间态那么锁一旦释放,仍然会存在超卖问题
- service中一个方法调用另一个事务方法,此时会失效,应当使用动态代理来调用
单机下的一人多单:防止卖出数量大于库存的数量
乐观锁(适合更新数据):适合读取操作多,冲突少的场景
-
版本号:新增个version字段
-
CAS(当前项目使用):在进行修改操作时把stock作为version进行查询
- 看stock与查询时的数量是否相等,这种方式有弊端:在使用乐观锁过程中假设100个线程同时都拿到了100的库存,然后大家一起去进行扣减,但是100个人中只有1个人能扣减成功,其他的人在处理时,他们在扣减时,库存已经被修改过了,所以此时其他线程都会失败
- 只要stock > 0就进行更新
集群下的一人一单:
1. 分布式锁
a. Redis的setnx
//设置锁
set [key] [value] ex [time] nx
//释放锁 (除了手动释放还可以超时释放)
del [key]
ⅰ. 使用try-finally
ⅱ. A事务方法内部调用B事务的方法,那么A事务方法不能直接catch,否则事务会失效
2. 分布式锁的优化
a. 为了解决误删除别的线程的锁的问题
ⅰ. 
ⅱ. 我们要进行判断,判断当前线程的线程ID + ID_PREFIX是否与Redis中获取的值是一样的
b. 为了解决释放锁时的原子性问题
ⅰ. 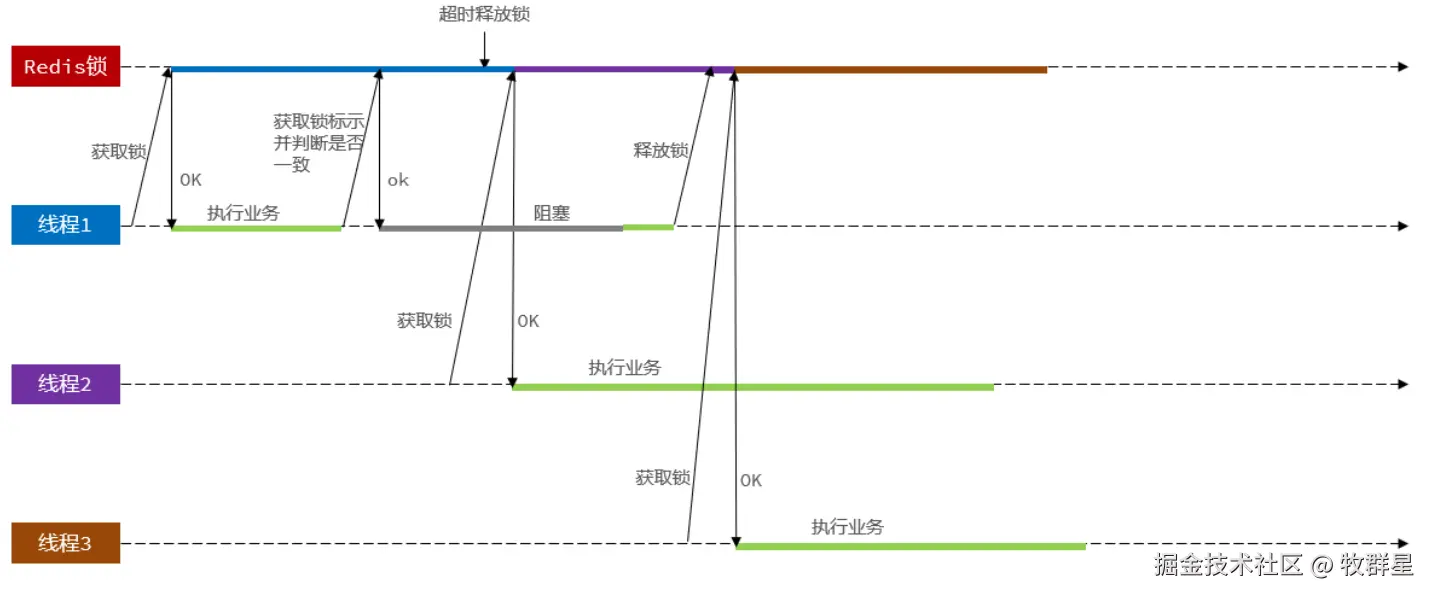
ⅱ. 引出了Lua脚本解决多条命令的原子性
ⅲ. 注意Lua脚本中Redis指令出错是会进行回滚操作的,而Lua出现逻辑错误无法进行回滚
3. 经过上面的分布式锁优化分布式锁达到了生产可用级别解下来要解决以下问题
a. 分布式锁不可重入, 分布式锁不可重试, 分布式锁超时释放, 主从一致性问题
为了解决以上问题我们可以对Redis分布式锁进行改进,或者直接使用Redission
为了解决ID自增问题,引出分布式ID,为了解决单体下的一人多单超卖问题,使用乐观锁CAS,业务变更--》抢秒杀卷,要求一人一单但是在并发情况下出现超卖问题,我们使用悲观锁锁住用户线程。由于用户量激增,单体项目变成集群,那集群模式下又产生了一人一单超卖问题,引出了分布式锁,一开始实现的分布式锁比较简单,会出现误删别的线程的锁导致出现超卖问题,给锁加标识解决,当释放锁时,又出现判断是否是当前线程的锁和删除锁两个操作不是原子性的就会导致超卖(A线程判断完是自己的锁以后 线程阻塞了过一段时间锁超时释放了,B线程在A线程释放锁后获取了锁,这时A线程醒了A线程进行删除锁的操作将B线程的锁给删除了,那C线程又获取到锁与B线程并行,导致超卖。)为了解决原子性的问题,我们使用Lua脚本。而我们上面的操作是在对Redis锁进行优化,还存在一些问题比如 锁不可重入,不可重试,超时释放而不能续期等等,但事实上有成熟的方案替换掉它,那就是Redisson,最终我们引入Redisson依赖并使用它的锁。现在锁的优化到了极致。我们接下来对性能和稳定性进行优化。
我们在进行秒杀下单流程的时候可以进行优化
我们将耗时较长的逻辑判断操作放入Redis中,那么只要这些逻辑都行得通就说明这一单一定能成。
使用java自带的阻塞队列BlockingQueue实现消息队列异步实现秒杀订单
- 异步情况下出现的问题无法从ThreadLocal中获取原线程的一些属性
- AOPContext.currentProxy()底层也是用ThreadLocal获取的,所以在异步线程中无法使用,有两种解决方案
- 将代理对象和订单一起放入阻塞队列中
- 代理对象的作用域提升,从类方法的方法变量,变成类的成员变量
由于BlockingQueue有诸多限制例如
- BlockingQueue中的消息是存储在内存中,无法做到持久化,一旦服务发生宕机或异常,消息会丢失
- BlockingQueue的容量有限制,无法进行扩容一旦达到最大容量,会报OOM错误
于是我们使用Redis中的消息队列
- List:支持持久化,但是无法避免数据的丢失,只支持单消费者
- PubSub(Redis2.0引入):支持单生产,单消费,但是不支持数据的持久化,无法避免数据丢失
- Stream(Redis5.0引入):有消息确认机制,并且能进行消息回溯,但是有消息漏读的风险
-
- 开启一个线程一直监听消息队列中的订单消息
接下来我们实现店铺内容的新增,查询,点赞,查看点赞排行榜等功能
而新增和查询都是非重点功能,没用到Redis
而接下来的点赞和查看点赞排行榜等功能都是重点,先来看点赞功能
- 因为点赞这种功能是高频使用的,如果使用Mysql实现是会影响整个系统的性能的,那么我们选择使用Redis
- 那我们这里选择Set数据结构(也可以使用Hash,SortedSet),有以下三点原因
- 不重复 符合业务的特点,一个用户只能点赞一次
- 高性能 set内部使用的是Hash表实现的
- 灵活性 set集合可以实现一对多,一个用户可以对多个博客点赞
再来看实现点赞排行榜的功能
- 我们有三种数据结构可以选择
- List 不满足唯一性
- set 不满足有序性
- SortedSet 都满足,所以我们使用SortedSet来进行
- zscore key value 相当于 sismember语句
- zadd key value score 添加缓存
- opsforZset().add(key, score, value);
- opsforZset().range(key, value1, value2) 查询set里按顺序排第value1到value2之间的值,
- last("order by field (id," + idStr + ")")) 这条语句很关键,是用来维持原来固定id顺序的,保证了是按照查询出来的排序规则展示点赞而不会变成按照id自增的顺序,last-->允许自定义sql语句
完成好友关注的功能
关注与取关
- 使用简单的逻辑判断和数据库更新即可
共同关注
- 使用opsForSet().intersect(key1, key2);即可得出缓存中key1集合和key2集合中的公共值 ---> 共同关注
推流模式
Feed流关注推送
时间排序(Timeline):不做内容筛选,简单的按照内容发布时间排序,常用于好友或关注。例如朋友圈(本项目中采用)
- 优点:信息全面,不会有缺失。并且实现也相对简单
- 缺点:信息噪音较多,用户不一定感兴趣,内容获取效率低
- 拉模式:该模式的核心含义就是:当张三和李四和王五发了消息后,都会保存在自己的邮箱中,假设赵六要读取信息,那么他会从读取他自己的收件箱,此时系统会从他关注的人群中,把他关注人的信息全部都进行拉取,然后在进行排序
- 优点:比较节约空间,因为赵六在读信息时,并没有重复读取,而且读取完之后-可以把他的收件箱进行清楚。
- 缺点:比较延迟,当用户读取数据时才去关注的人里边去读取数据,假设用户关注了大量的用户,那么此时就会拉取海量的内容,对服务器压力巨大。
- 推模式:推模式是没有写邮箱的,当张三写了一个内容,此时会主动的把张三写的内容发送到他的粉丝收件箱中去,假设此时李四再来读取,就不用再去临时拉取了
- 优点:时效快,不用临时拉取
- 缺点:内存压力大,假设一个大V写信息,很多人关注他, 就会写很多分数据到粉丝那边去
- 推拉模式:推拉模式是一个折中的方案,站在发件人这一段,如果是个普通的人,那么我们采用写扩散的方式,直接把数据写入到他的粉丝中去,因为普通的人他的粉丝关注量比较小,所以这样做没有压力,如果是大V,那么他是直接将数据先写入到一份到发件箱里边去,然后再直接写一份到活跃粉丝收件箱里边去,现在站在收件人这端来看,如果是活跃粉丝,那么大V和普通的人发的都会直接写入到自己收件箱里边来,而如果是普通的粉丝,由于他们上线不是很频繁,所以等他们上线时,再从发件箱里边去拉信息。
智能排序:利用智能算法屏蔽掉违规的、用户不感兴趣的内容。推送用户感兴趣信息来吸引用户
- 优点:投喂用户感兴趣信息,用户粘度很高,容易沉迷
- 缺点:如果算法不精准,可能起到反作用
本项目由于用户数量少,我们选择推模式,延迟低、内存占比少
我们要实现分页查询功能
- 我们可以选择List和SortedSet,Set是无序的所以不选
- 而List存在索引飘移,所以我们不适用它
- 经过分析我们使用滚动分页,选择SortedSet,我们可以按照score(按照时间戳生成)排序读取
- 上次查询的最小时间戳作为这次查询的最大时间戳,如果有相同时间戳的那offset(偏移量) ++;否则os = 1;
完成附近商铺搜索功能
我们使用GEO数据结构实现
opsForGeo()
.search(
key,
GeoReference.fromCoordinate(x, y),//给出当前使用app时所处的位置
new Distance(5000),//给定半径
RedisGeoCommands.GeoSearchCommandArgs.newGeoSearchArgs().includeDistance().limit(end)//查出半径在给定半径以内的商家,并规定查出end条数据
);
完成用户签到和连续签到统计
SETBIT key offset value
# 读取所有的bit位
BITFIELD key
# 查找第一个数出现的位置
BITPOS key value
BITPOS bm1 1 # 返回的就是0,11100111 offset位0的位置就是1
BITPOS bm1 0 # 返回的就是0,11100111 offset位0的位置就是1
# 读取指定位数的bit位
BITFIELD key GET type offset
# 获取的数据是3
BITFIELD bm1 get u2 0
u表示无符号,i表示有符号,这里读取到3,是因为u2表示获取两个bit位,0表示从0开始计数,前面我们存入的数据是11100111,从0开始计数,往后数两个bit位 就是 11 ,11代表的数字就是3,如果是 BITFIELD bm1 get u3 0 对应的就是111,代表的数据就是7,BITFIELD bm1 get u5 0对应的数字也是7(11100)
签到统计
- 问题1:什么叫做连续签到天数?
从最后一次签到开始向前统计,直到遇到第一次未签到为止,计算总的签到次数,就是连续签到天数。
- 问题2:如何得到本月到今天为止的所有签到数据?
BITFIELD key GET u[dayOfMonth] 0
- 问题3:如何从后向前遍历每个bit位?
与 1 做与运算,就能得到最后一个bit位。随后右移1位,下一个bit位就成为了最后一个bit位。
UV统计
首先我们搞懂两个概念:
- UV:全称Unique Visitor,也叫独立访客量,是指通过互联网访问、浏览这个网页的自然人。1天内同一个用户多次访问该网站,只记录1次。
- PV:全称Page View,也叫页面访问量或点击量,用户每访问网站的一个页面,记录1次PV,用户多次打开页面,则记录多次PV。往往用来衡量网站的流量。
UV统计在服务端做会比较麻烦,因为要判断该用户是否已经统计过了,需要将统计过的用户信息保存。但是如果每个访问的用户都保存到Redis中,数据量会非常恐怖。
我们用HyperLogLog来做海量数据的统计工作
- 优点:内存占用低、性能好
- 缺点:有一定误差
实验得出100w条用户数据,至多占用0.02MB的内存
