

Prometheus 是一种强大的开源监控工具,适合用于微服务架构的性能监控和指标收集。结合 Prometheus 和 Gin,我们可以实现对 HTTP 请求的实时监控,分析流量、性能瓶颈以及错误分布。本文将详细介绍如何通过 Prometheus 监控 Gin 服务,包括环境配置、集成代码、指标采集和可视化的全过程。
1. 为什么需要监控 Gin 服务?
Gin 是一个高性能的 Web 框架,广泛用于构建 API 服务。在高并发场景下,服务的实时状态对于定位问题和优化性能至关重要。通过监控,我们可以:
- 实时掌握请求流量和响应时间。
- 分析服务的错误比例和状态码分布。
- 提前发现潜在的性能瓶颈。
2. 核心监控指标定义
通过 Prometheus,我们可以采集以下 Gin 服务的核心指标:
- 请求总数:按路径和状态码分组。
- 响应时间:按耗时范围分布。
- 错误请求分布:如 4xx 和 5xx 错误比例。
- 请求并发数:当前正在处理的请求数量。
这些指标通过 Prometheus 的 /metrics 接口暴露并定期采集,最终可在 Grafana 中实时展示。
3. 环境准备
3.1 安装 Prometheus
从 Prometheus 官网 下载并安装 Prometheus。
3.2 安装 Grafana
Grafana 是 Prometheus 的可视化工具,可通过仪表盘展示监控数据。
3.3 项目依赖
通过以下命令安装 Gin 和 Prometheus 相关库:
go get github.com/gin-gonic/gin
go get github.com/prometheus/client_golang/prometheus
4. 集成 Prometheus 到 Gin
4.1 注册监控指标
下面是所有的 HTTP 请求总数,和请求持续时间的 Prometheus 监控指标定义:
var (
httpRequestsTotal = promauto.NewCounterVec(prometheus.CounterOpts{
Name: "http_requests_total",
Help: "Count of all HTTP requests",
}, []string{"method", "path", "status"})
httpRequestDuration = promauto.NewHistogramVec(prometheus.HistogramOpts{
Name: "http_request_duration_seconds",
Help: "Duration of HTTP requests",
Buckets: []float64{0.1, 0.3, 0.5, 0.7, 1, 1.5, 2, 3},
}, []string{"method", "path"})
)
4.2 监控中间件
func prometheusMiddleware() gin.HandlerFunc {
return func(c *gin.Context) {
start := time.Now()
path := c.FullPath()
c.Next()
duration := time.Since(start).Seconds()
status := c.Writer.Status()
httpRequestsTotal.WithLabelValues(c.Request.Method, path, http.StatusText(status)).Inc()
httpRequestDuration.WithLabelValues(c.Request.Method, path).Observe(duration)
}
}
4.3 暴露指标路由
func main() {
r := gin.Default()
// 使用 Prometheus 中间件
r.Use(prometheusMiddleware())
// 添加 Prometheus 指标路由
r.GET("/metrics", gin.WrapH(promhttp.Handler()))
// 业务路由
r.GET("/", func(c *gin.Context) {
c.JSON(200, gin.H{"message": "Hello, Prometheus!"})
})
r.GET("/api", func(c *gin.Context) {
time.Sleep(100 * time.Millisecond) // 模拟处理时间
c.JSON(200, gin.H{"message": "API response"})
})
r.Run(":8080")
}
以上代码会自动将服务的监控指标暴露到 /metrics 路由。这些指标会随着服务运行动态更新。
5. 配置 Prometheus 抓取指标
在 Prometheus 配置文件(prometheus.yml)中添加 Gin 服务的抓取规则:
job_name定义和你的服务相关的名称即可,主要是靠targets中的地址抓取指标
scrape_configs:
- job_name: "gin_service"
static_configs:
- targets: ["localhost:8080"]
完成后启动 Prometheus,服务的指标会定期抓取并存储。
下图就是上面配置的http请求总数示例:
6. 可视化监控数据
虽然 Prometheus 也提供了图表的展示,但是通常大家还是使用 Grafana 做图形化展示。
6.1 安装 Grafana
- 访问官方安装地址
- 选择 Windows 版本(.zip 或 .msi 安装包),推荐.msi
6.2 创建监控仪表盘
连接 Prometheus 数据源
- 在 Grafana 左侧菜单点击 ⚙ Configuration → Data sources
- 点击 Add data source,选择 Prometheus
- 配置参数:
- URL:
http://localhost:9090(Prometheus 的默认地址) - 其他保持默认
- URL:
- 点击 Save & Test,确认显示绿色的成功提示。
导入或创建仪表板
方案A:快速导入现成仪表板(推荐新手)
- 在 Grafana 左侧菜单点击 Create (➕) → Import
- 输入以下任意一个仪表板 ID:
- Go 应用监控:
6671(官方基础仪表板) - HTTP 请求监控:
7589
- Go 应用监控:
- 选择刚添加的 Prometheus 数据源
- 点击 Import 完成导入
方案B:手动创建自定义仪表板
- 点击 Create → Dashboard
- 添加面板(Panel),编写 PromQL 查询:
- 示例1(请求总数):
http_requests_total{handler="/ping"}- 示例2(错误请求比例):
rate(http_requests_total{code="500"}[5m]) - 设置可视化类型(如 Time series、Stat 等)
下图是请求总数的grafana示例
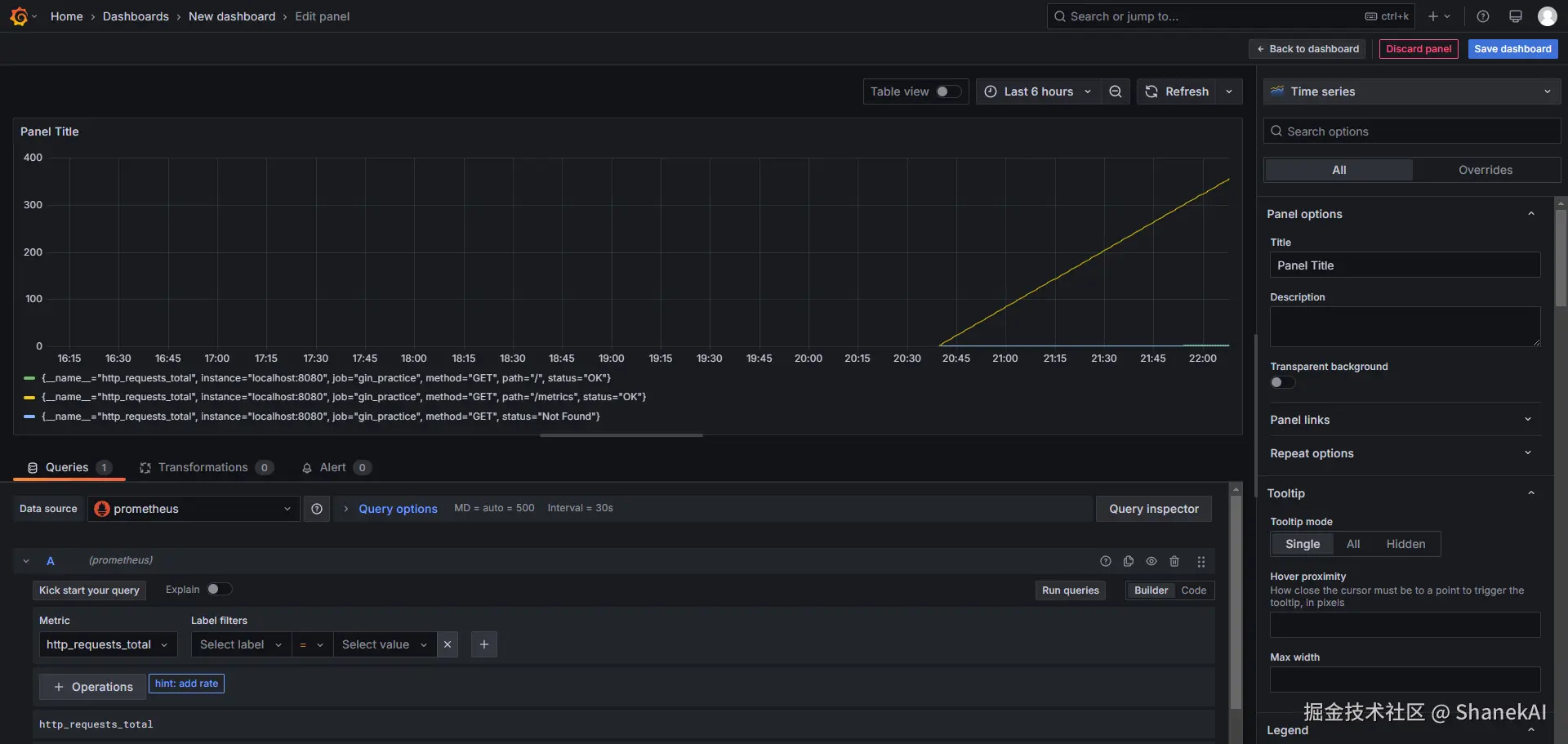
7. 最佳实践
- 分阶段监控:
- 初期监控基本指标(如请求数和响应时间)。
- 随着业务发展,逐步加入自定义指标。
- 报警规则:
- 在 Prometheus 配置报警规则,例如:
- 响应时间超过阈值。
- 错误请求比例过高。
- 在 Prometheus 配置报警规则,例如:
- 结合日志分析:
- 通过日志记录补充监控数据,定位指标异常原因。
总结
通过 Prometheus,我们可以轻松实现对 Gin 服务的高效监控。结合 Grafana 的实时可视化和报警规则,开发者能够快速发现性能瓶颈和错误请求,显著提高服务的可靠性和用户体验。如果你对某个监控场景或指标的实现有更多疑问,欢迎进一步探讨!
