

将LLMs转变为编码专家以及如何利用它们
Shrivu Shankar
2025年3月16日
了解像Cursor、Windsurf和Copilot这样的AI编码工具在底层如何工作,可以极大地提高你的生产力,使这些工具在更大、更复杂的代码库中更加一致地工作。通常,当人们难以让AI IDE有效工作时,他们会将其视为传统工具,忽视了了解其固有局限性以及如何最好地克服这些局限性的重要性。一旦你掌握了它们的内部工作原理和限制,它就会成为显著改善工作流程的“作弊代码”。在撰写本文时,Cursor编写了我大约70%的代码。
在这篇文章中,我想深入探讨这些IDE的实际工作原理、Cursor系统提示以及如何优化你编写代码和Cursor规则的方式。
从LLM到编码代理
大型语言模型
LLMs通过反复预测下一个词来工作,从这个简单的概念中,我们能够构建复杂的应用程序。
从基本的编码LLMs到代理有三个阶段:蓝色是我们的前缀(即提示),橙色是LLM自动完成的内容。对于代理,我们多次运行LLM,直到它生成面向用户的响应。每次,客户端代码(而不是LLM)计算工具结果并将其提供回代理。
早期的解码器LLMs(例如GPT-2)的提示涉及构建一个前缀字符串,当完成时,它将产生所需的结果。与其说“写一首关于鲸鱼的诗”,不如说“主题:鲸鱼\n诗:”或者甚至“主题:树\n诗:…实际的树诗…\n主题:鲸鱼\n诗:”。对于代码,这看起来像“PR标题:重构Foo方法\n描述:…\n完整差异:”,你构建了一个前缀,当完成时,它将实现你想要的内容。“提示工程”是创造性地构建理想前缀,以诱使模型自动完成答案。
然后引入了指令调优(例如ChatGPT),使LLMs变得更加易于访问。你现在可以说“写一个PR来重构Foo”,它会返回代码。在底层,它几乎与上述相同的自动完成过程,但前缀已更改为“写一个PR来重构Foo”,其中LLM现在在聊天中工作。即使在今天,你也会看到一些奇怪的情况,这个事实会泄露出来,LLM会通过继续自动完成“”标记来开始向自己提问。
当模型变得足够大时,我们更进一步,添加了“工具调用”。在前缀中,我们不仅可以填写助手文本,还可以提示“如果你需要读取文件,请说read_file(path: str)而不是响应”。当LLM被赋予编码任务时,现在会完成“read_file(‘index.py’)”,然后我们(客户端)再次提示“…index.py的完整内容…”并要求它继续完成文本。虽然它仍然只是自动完成,但LLM现在可以与世界和外部系统交互。
代理编码
像Cursor这样的IDE是这个简单概念的复杂包装器。
要构建一个AI IDE,你需要:
- 分叉VSCode
- 添加一个聊天UI并选择一个好的LLM(例如Sonnet 3.7)
- 为编码代理实现工具
- read_file(full_path: str)
- write_file(full_path: str, content: str)
- run_command(command: str)
- 优化内部提示:“你是一个专家编码员”,“不要假设,使用工具”等。
从高层次来看,这就是全部。困难的部分是设计你的提示和工具,使其真正一致地工作。如果你完全按照我描述的方式构建它,它会有点工作,但它经常会遇到语法错误、幻觉,并且相当不一致。
优化代理编码
制作一个好的AI IDE的诀窍是弄清楚LLM擅长什么,并围绕其局限性仔细设计提示和工具。通常这意味着通过使用较小的模型来处理子任务来简化主LLM代理的任务(参见我的另一篇文章《构建多代理系统》)。
我们为主代理简化了工具,并将“认知负荷”转移到其他LLMs上。IDE将你的@-标签注入上下文,调用多个工具以收集更多上下文,使用特殊的差异语法编辑文件,然后向用户返回摘要响应。
优化和用户提示
通常用户已经知道正确的文件或上下文,因此我们在聊天UI中添加了“@file”语法,并在调用LLM时传递所有附加文件的完整内容,使用“”块。这是用户自己复制粘贴整个文件或文件夹的语法糖。
Tip: 在这些IDE中积极使用@folder/@file(更喜欢更明确的上下文以获得更快和更准确的响应)。
搜索代码可能很复杂,特别是对于像“我们在哪里实现认证代码”这样的语义查询。与其让代理擅长编写搜索正则表达式,我们使用编码器LLM在索引时将整个代码库索引到向量存储中,以将文件及其功能嵌入到向量中。在查询时,另一个LLM根据相关性重新排序和过滤文件。这确保了主代理获得关于认证代码问题的“完美”结果。
Tip: 代码注释和文档字符串指导嵌入模型,这使得它们比仅仅为人类同行编写时更加重要。在文件顶部,有一段关于文件是什么、它在语义上做什么以及何时应该更新的段落。
编写字符完美的代码既困难又昂贵,因此优化write_file(…)工具是许多这些IDE的核心。与其编写文件的完整内容,LLM通常生成一个“语义差异”,它只提供更改的内容,并添加代码注释以指导插入更改的位置。另一个更便宜、更快的代码应用LLM将此语义差异作为提示,并编写实际的文件内容,同时修复任何小的语法问题。然后通过linter传递新文件,工具结果包含实际差异和lint结果,可用于自我纠正损坏的文件更改。我喜欢将其视为与一个懒惰的高级工程师一起工作,他只编写足够的代码片段,让实习生进行实际更改。
Tip: 你无法提示应用模型。“停止删除随机代码”,“停止添加或删除随机注释”等建议是徒劳的,因为这些工件来自应用模型的工作方式。相反,给主代理更多控制权,“在edit_file指令中提供完整文件”。
Tip: 当编辑非常大的文件时,应用模型速度慢且容易出错,将文件拆分为 小于 500行代码。
Tip: lint反馈对代理来说是非常高的信号,你(和Cursor团队)应该投资一个真正强大的linter2,它提供高质量的建议。拥有编译和类型化的语言可以提供更丰富的lint时间反馈。
Tip: 使用唯一的文件名(而不是在代码库中有几个不同的page.js文件,更喜欢foo-page.js,bar-page.js等),在文档中更喜欢完整文件路径,并将代码热点路径组织到同一文件或文件夹中,以减少编辑工具的歧义。
使用一个擅长以这种代理风格编写代码的模型(而不仅仅是编写代码)。这就是为什么Anthropic模型在像Cursor这样的IDE中如此出色,它们不仅编写好代码,而且擅长将编码任务分解为这些类型的工具调用。
Tip: 使用不仅“擅长编码”而且专门为代理IDE优化的模型。唯一(据我所知)测试这一点的排行榜是WebDev Arena3。
在我自己的AI IDE sparkstack.app中,我使用了一个(非常昂贵的)技巧,使其在自我纠正方面表现得更好,那就是给它一个“apply_and_check_tool”。这运行更昂贵的linting,并启动一个无头浏览器以检索应用程序用户流程中的控制台日志和屏幕截图,以向代理提供反馈。在这种情况下,MCP(模型上下文协议)将真正闪耀,作为一种为代理提供更多自主权和上下文的方式。
逐行Cursor系统提示分析
使用基于MCP的提示注入,我提取了Cursor代理模式使用的最新(2025年3月)提示。作为一个在LLMs上广泛构建的人,我对Cursor的“提示工程师”非常尊重,他们真正知道如何编写好的提示(在我看来),与我在其他AI IDE中看到的相比。我认为这是他们成为领先编码工具的一个重要原因。深入研究这样的提示也是提高你自己的提示和代理架构能力的好方法——在某种意义上,大多数GPT包装器都是“开放提示”的。
“<communication>”、“<tool_calling>”等——使用Markdown和XML部分标签的混合提高了提示对人类和LLM的可读性4。
“powered by Claude 3.5 Sonnet”——通常LLMs不会准确地告诉你它们正在运行什么模型。明确地放置这一点减少了Cursor计费与LLM本身所说的运行模型不同的投诉5。
“the world's best IDE”——这是一种简洁的方式,告诉LLM在事情出错时不要推荐替代产品,这对于品牌代理来说非常重要6。
“we may automatically attach some information…follow the USER's instructions…by the <user_query> tag.”——与其将用户提示直接传递给LLM,Cursor还将它们放入一个特殊标签中。这允许Cursor在消息中传递额外的用户相关文本,而不会混淆LLM或用户。
“Refrain from apologizing”——他们显然是因为Sonnet的倾向而添加了这一点。
“NEVER refer to tool names when speaking”——Cursor以粗体添加了这一点,讽刺的是,我仍然经常看到这一点为“Using edit_tool”。这是最近Sonnet模型的一个烦人问题。
“Before calling each tool, first explain”——当LLM流式传输工具调用时,这可能是一个奇怪的用户体验,因为聊天看起来会卡住几秒钟。这有助于用户确信正在发生某些事情。
“partially satiate the USER's query, but you're not confident, gather more information”——LLM代理倾向于过度自信的早期停止。给他们一个出路是有帮助的,这样他们可以在响应之前深入挖掘。
“NEVER output code to the USER”——默认情况下,LLMs希望在内联Markdown代码块中生成代码,因此需要额外的引导,以强制它仅使用工具进行代码,然后通过UI间接显示给用户。
“If you're building a web app from scratch, give it a beautiful and modern UI”——在这里,你看到了一些演示黑客,以生成非常华丽的单提示应用程序。
“you MUST read the the7 contents or section of what you're editing before editing it”——通常编码代理真的想编写代码但不想收集上下文,所以你会看到很多明确的指令来引导这一点。
“DO NOT loop more than 3 times on fixing linter errors”——旨在防止Cursor陷入编辑循环。这有帮助,但任何经常使用Cursor的人都知道,这仍然很容易陷入困境。
“Address the root cause instead of the symptoms.”——作为LLM对齐不良的一个案例,它们通常会默认删除错误消息代码,而不是解决问题。
“DO NOT hardcode an API key”——这是许多安全最佳实践之一,至少可以防止一些明显的安全问题。
工具“codebase_search”、“read_file”、“grep_search”、“file_search”、“web_search”——鉴于LLM在编码之前收集正确的上下文是多么关键,它们提供了几种不同形状的搜索工具,以使其轻松地弄清楚要进行的更改。
在几个工具中,“One sentence explanation…why this command needs to be run…”——大多数工具包含这个非功能性参数,它强制LLM推理它将传递的参数。这是改进工具调用的常见技术。
工具“reapply”可以“调用一个更聪明的模型来应用最后一次编辑”——允许主代理动态升级应用模型到更昂贵的东西,以自我解决愚蠢的应用问题。
工具“edit_file”声明“使用你正在编辑的语言的注释表示所有未更改的代码”——这是所有那些随机注释的来源,这是应用模型正常工作所必需的。
你还会注意到,整个系统提示和工具描述是静态的(即没有用户或代码库个性化文本),这样Cursor可以充分利用提示缓存,以降低成本和首次令牌延迟。这对于每次使用工具时都进行LLM调用的代理来说至关重要。
如何有效使用Cursor规则
现在最大的问题是什么是编写Cursor规则的“正确方式”,虽然我的总体答案是“任何对你有用的方式”,但我基于提示经验和Cursor内部知识有很多意见。
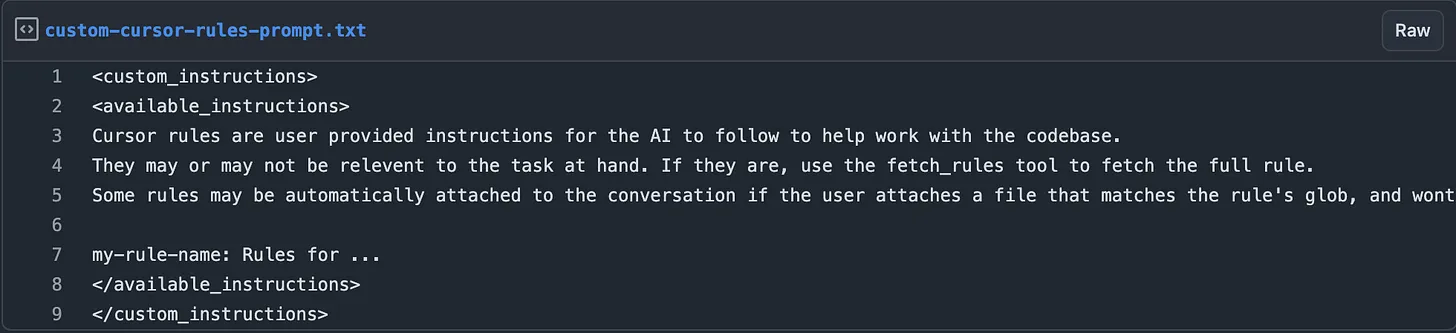
它看到名称和描述列表,并基于此,它可以调用fetch_rules(…)工具并读取其内容。
关键是要理解这些规则不会附加到系统提示中,而是作为命名指令集引用。你的心态应该是将规则编写为百科全书文章,而不是命令。
不要在规则中提供身份,如“你是一个高级前端工程师,是typescript的专家”,就像你可能会在cursor.directory中找到的那样。这可能看起来有效,但当它已经由内置提示提供身份时,代理遵循起来很奇怪。
不要(或避免)尝试覆盖系统提示指令或尝试使用“不要添加注释”、“在编码之前问我问题”和“不要删除我没有要求你删除的代码”来提示应用模型。这些直接与内部冲突,破坏工具使用并混淆代理。
不要(或避免)告诉它不要做什么。LLMs最擅长遵循积极的命令“对于<这个>,<做这个>”,而不仅仅是一系列限制。你在Cursor自己的提示中看到了这一点。
花时间编写高度突出的规则名称和描述。关键是代理在对你代码库了解最少的情况下,可以直观地知道何时适用规则以使用其fetch_rules(…)工具。就像你在构建一个手工制作的反向文档索引一样,你应该有时有重复的规则,具有不同的名称和描述,以提高获取率。尝试保持描述密集而不是过于冗长。
将你的规则编写为模块或常见代码更改的百科全书页面。像维基百科一样,将关键术语(使用mdc链接语法)链接到代码文件,为代理在确定更改所需的正确上下文时提供了巨大的提升。这有时也意味着避免逐步说明(专注于“什么”而不是“如何”),除非绝对必要,以避免过度拟合代理到特定类型的更改。
使用Cursor本身来起草你的规则。LLMs非常擅长为其他LLMs编写内容。如果你不确定如何格式化你的文档或编码上下文,请执行“@folder/生成一个Markdown文件,描述常见预期更改的关键文件路径和定义”。
考虑拥有大量规则作为反模式。这是违反直觉的,但虽然规则对于让AI IDE在大型代码库上工作至关重要,但它们也表明了一个非AI友好的代码库。我在《AI驱动的软件工程》中写了更多关于这一点,但未来的理想代码库足够直观,编码代理只需要内置工具即可完美工作。
结论
一个基于VSCode的分支,建立在有效的开源代理提示和公开可访问的模型API上,能够达到接近100亿美元的估值——携带“包装器倍数”68,这是多么疯狂。看看Cursor最终是否会开发自己的代理模型(感觉不太可能),或者Anthropic是否会以Claude Code +下一个Sonnet作为竞争对手介入,这将很有趣。
无论最终情况如何,知道如何塑造你的代码库、文档和规则将继续是一项有用的技能,我希望这次深入探讨能让你对事情如何工作以及如何优化AI有一个不那么“基于感觉”而更具体的理解。我说了很多次,我再说一遍,如果Cursor对你不起作用,你使用它的方式是错误的。
1 这是一个基于感觉的统计数据,但我不认为它偏离太远。一旦你擅长Cursor规则,相当数量的PR实际上就变成了单次提示。我最初认为要到2027年才能达到这一点,但在Anthropic、Cursor和我自己的提示技巧同时改进的情况下,事情比我猜测的进展得更快。
2 到目前为止,我对CodeRabbit的linting印象深刻,并计划使用MCP将其传递回Cursor。如果Cursor的默认linter更好,其他一切保持不变,感觉就像使用Sonnet 3.8。
3(大多数)LLMs的美妙之处在于,虽然这是一个Web开发基准,但根据我的经验,其性能与所有类型的编码和框架高度相关。
4 我找不到关于这一点的科学研究,但根据我的经验,这非常有效,我不会惊讶于Anthropic模型在伪XML语法上进行了明确的训练。
5 这确实有一些意想不到的副作用,编码模型会将代码库中引用的模型名称更改为与自身相同的名称。
6 这里有一个有趣的法律灰色地带。Cursor在其网站上放置这一点实际上是非法的(参见FTC法案,Lanham法案),但他们在提示中放置这一点并让LLM代表他们说出来是没问题的(目前)。
7 这是我为GPT包装器与模型提供商的估值比率创造的一个术语。在这种情况下,Anthropic : Cursor = $60B : $10B = 6。我的直觉告诉我,“6”不是一个理性的比率。戴上我不成熟的投资者帽子,我推测Anthropic应该接近$100B,Cursor高达$1B(包装器倍数为100)。我只是很难看到他们中的任何一个真正拥有长期的护城河,Anthropic构建自己的下一代AI IDE竞争对手似乎微不足道。
