Rejection Sampling
拒绝采样 (Rejection Sampling, RS) 是一种流行且简单的方法,用于执行偏好微调。拒绝采样通过策划新的candidate instructions,并根据经过训练的奖励模型对其进行筛选,然后仅对top completions对原始模型进行微调。
这个名称来源于计算统计学,其中人们希望从一个复杂分布中采样,但没有直接的方法来做到这一点。为解决这个问题,可以从一个较容易建模的分布中采样,并使用启发式方法来检查样本是否可接受。对于语言模型,目标分布是对指令的高质量回答,筛选使用的是奖励模型,而采样分布则是当前的模型。
许多著名的基于人类反馈强化学习 (RLHF) 和偏好微调的论文将拒绝采样用作基线,但尚无标准的实现和文档。像 WebGPT、Anthropic 的有帮助且无害的代理、OpenAI 关于流程奖励模型的热门论文、Llama 2 聊天模型以及其他一些开创性的工作都采用了这一基线。
Training Process
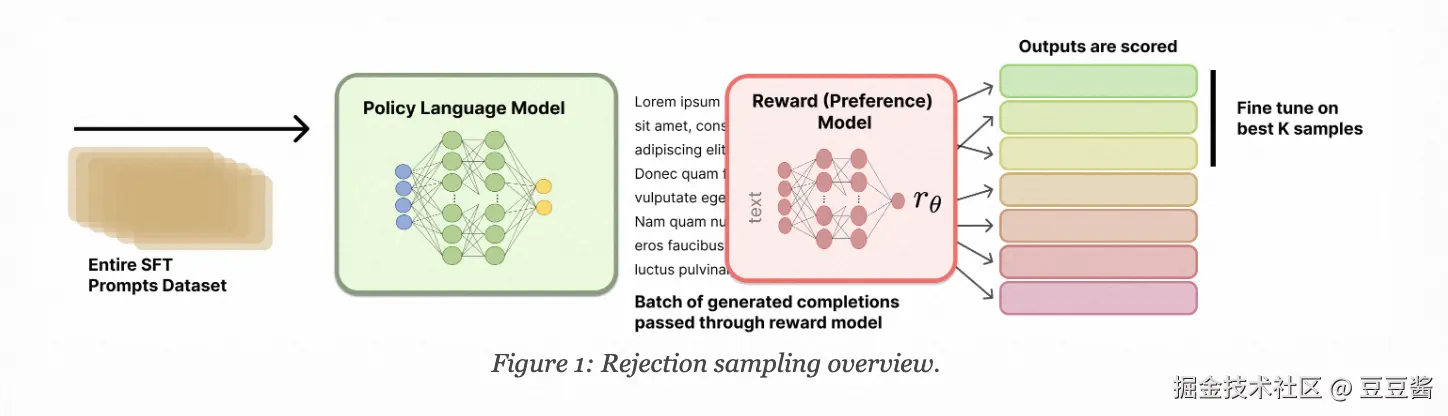
生成Completions
定义一组包含 M 个提示的向量:
X=[x1,x2,…,xM]
这些提示可以来源于许多渠道,但最常见的是来自指令训练集。对于每个提示 xi,我们生成 N 个补全。我们可以将这些补全表示为一个矩阵:
Y=y1,1y2,1⋮yM,1y1,2y2,2⋮yM,2⋯⋯⋱⋯y1,Ny2,N⋮yM,N
这个矩阵表示的是对于每个提示 xi 生成的 N 个补全,其中 yi,j 代表第 i 个提示的第 j 个补全。现在,我们将所有这些提示-补全对通过一个奖励模型,得到一个奖励矩阵。我们将奖励表示为矩阵 R:
R=r1,1r2,1⋮rM,1r1,2r2,2⋮rM,2⋯⋯⋱⋯r1,Nr2,N⋮rM,N
每个奖励 ri,j 是通过将补全 yi,j 及其对应的提示 xi 输入到奖励模型 R 中计算得到的:
ri,j=R(yi,j∣xi)
选择top-N Completions
有多种方法可以选择用于训练的top completions。
为了将选择最佳completion的过程形式化,我们可以基于我们的奖励矩阵定义一个选择函数 S,它作用于奖励矩阵 R。
Top Per Prompt
第一个潜在的选择函数是对每个提示取最大值。
S(R)=[argmaxjr1,j,argmaxjr2,j,…,argmaxjrM,j]
这个选择函数 S 返回一个索引的向量,其中每个索引对应于 R 的每一行中具有最高奖励的列。然后我们可以使用这些索引来选择我们最终的补全:
Ychosen=[y1,S(R)1,y2,S(R)2,…,yM,S(R)M]
Top Overall Prompts
除此之外,我们可以从整个集合中选择顶部K个提示-补全对。首先,我们将奖励矩阵R扁平化为一个向量:
Rflat=[r1,1,r1,2,…,r1,N,r2,1,r2,2,…,r2,N,…,rM,1,rM,2,…,rM,N]
这个向量 Rflat 的长度为 M×N,其中 M 是提示的数量,N 是每个提示的补全数量。
现在,我们可以定义一个选择函数 SK,它选择 Rflat 中最高的 K 个值的索引:
SK(Rflat)=argsort(Rflat)[−K:]
其中,argsort 返回对数组进行升序排序时的索引,我们取最后 K 个索引来得到最高的 K 个值。
为了得到我们选择的补全,我们需要将这些扁平化的索引映射回到我们原始的补全矩阵 Y 中。我们只需索引 Rflat 向量来得到我们的补全。
Selection Example

Per Prompt

Overall Prompt

Details
关于拒绝采样的实现细节相对较少。执行这种训练的核心超参数非常直观:
- 采样参数:拒绝采样直接依赖于从模型接收到的补全结果。RS 的常见设置包括大于零的温度,例如在 0.7 到 1.0 之间,以及其他参数的调整如 top-p 或 top-k 采样。
- 每个提示的补全数量:成功实现拒绝采样的实例包含每个提示 10 到 30 个或更多补全。使用太少的补全可能会导致训练偏向或噪声过大。
- 指令微调细节:目前尚未公布 RS 期间指令微调的具体训练细节。这些设置可能与模型最初指令微调阶段的设置略有不同。
- 异构模型生成:某些拒绝采样的实现包括来自多个模型的生成,而不仅仅是要训练的当前模型。关于如何实施的最佳实践尚未建立。
- 奖励模型训练:使用的奖励模型将严重影响最终结果。有关奖励模型训练的更多资源,请参阅相关章节。
Reference
rlhfbook.com/c/10-reject…


