

引言:AI的“思维革命”
2017年,谷歌的一篇论文《Attention Is All You Need》提出了一种名为Transformer的模型,它像一颗种子,短短几年内长成了覆盖人工智能各个领域的参天大树。
今天,无论是ChatGPT的对话、MidJourney的绘画,还是手机里的实时翻译,背后都离不开Transformer的驱动。它不只是一个技术名词,更是一场关于“机器如何思考”的革命。
本文将用最易懂的方式,带你走进Transformer的世界——从基本定义到实际应用,从数学原理到生活场景,全面解析这个改变AI进程的“超级大脑”。
一、Transformer是什么?
1. 定义:AI的“全局思考者”
Transformer是一种基于注意力机制(Attention Mechanism)的深度学习模型,专门用于处理序列数据(如文字、语音、时间序列)。与传统模型不同,它能同时关注输入的所有部分,并动态分配注意力权重,从而捕捉长距离依赖关系。
类比理解: 想象你正在阅读一本侦探小说。传统AI像是一个只能逐页阅读的读者(如RNN),读到第100页时可能已经忘了第1页的线索;而Transformer则像一位能随时翻回任意页面的侦探,快速关联所有关键信息。
2. 发展历程
- 2014年:注意力机制首次应用于机器翻译(Bahdanau Attention)
- 2017年:谷歌提出Transformer架构,在机器翻译任务中超越所有传统模型
2017年,8位谷歌研究人员发表了Attention is All You Need。可以说,这篇论文是NLP领域的颠覆者。

主要Transformer贡献者:
Jakob Uszkoreit被公认是Transformer架构的主要贡献者。


Ashish Vaswani

在Transformers论文中,Niki Parmar是唯一的女性作者。
- 2018年:BERT(基于Transformer Encoder)刷新自然语言理解纪录
- 2020年:GPT-3(基于Transformer Decoder)展现惊人文本生成能力
- 2022年:Transformer扩展至图像(ViT)、音频(Whisper)、多模态(DALL·E 2)
国内基于Transformer的自然语言处理的中文大模型也在蓬勃发展。具有代表性的如:
- 2021年4月,阿里巴巴达摩院发布中文社区最大规模预训练语言模型PLUG,该模型参数规模达到270亿,集语言理解与生成能力与一身。
- 2021年4月,华为云发布千亿级生成与理解中文NLP大模型盘古,在中文语言理解评测基准 CLUE 榜单中,刷新三项榜单世界历史纪录;
- 2021年6月,由北京智源人工智能研究院发布了全球最大的超大规模智能模型“悟道2.0”,实现了“大而聪明”,具备大规模、高精度、高效率的特点。
- 2021年11月,阿里达摩院联合清华大学研发,中国首个万亿参数的超大规模多模态预训练Transformer模型M6。
- 2021年12月,百度推出拥有2600亿参数的百度文心大模型,使用编码器-解码器参数共享的Transformer作为自回归生成的主干网络。在国际权威的复杂语言理解任务评测SuperGLUE上超越谷歌的T5、OpenAI的GPT-3等大模型。
Transformer在CV领域的发展
目前,Transformer已经成功应用于计算机视觉任务当中,除三大视觉任务之外,在识别任务、图像增强、图像生成、视频处理等任务上,Transformer模型都表现优秀。
二、Transformer核心特点
1. 并行处理能力
- 传统模型困境:RNN必须按顺序处理数据(如逐词阅读),速度慢且难以利用GPU并行计算。
- Transformer突破:所有位置同时计算,训练速度提升5-10倍。
生活案例: 普通快递员(RNN)需要逐个派送包裹,而Transformer是一支快递车队,同时出发派送整个区域的包裹。
2. 全局信息感知
- 传统模型局限:CNN只能捕捉局部特征(如相邻词汇的关系)。
- Transformer优势:每个词可直接与任意位置的词建立联系,适合处理长文本、复杂逻辑。
案例对比: 分析法律合同时,传统AI可能漏掉跨页条款的关联,而Transformer能精准识别“第3页的甲方”与“第15页的违约责任”之间的关系。
3. 灵活的可扩展性
- 横向扩展:通过增加“注意力头”(Multi-Head),让模型学习多种关联模式(如语法、语义、指代)。
- 纵向扩展:堆叠更多层(如GPT-3有96层),逐层提取抽象特征。
4. 多任务通用性
同一套架构可处理翻译、摘要、图像生成等不同任务,只需调整输入输出方式。
5. 硬件友好性
密集的矩阵运算完美匹配GPU/TPU的计算特性,推动了大模型时代的算力革命。
三、Transformer的应用场景
1. 自然语言处理(NLP)
| 应用 | 典型案例 | 效果 |
|---|---|---|
| 机器翻译 | Google翻译、DeepL | 长句翻译准确率超90% |
| 文本生成 | ChatGPT、Jasper | 生成营销文案、小说续写 |
| 智能问答 | 客服机器人、医疗咨询助手 | 理解上下文,提供精准答案 |
2. 计算机视觉(CV)
- 图像分类:Vision Transformer(ViT)在ImageNet数据集上准确率超过CNN
- 图像生成:DALL·E 2根据“宇航员骑马的水彩画”生成高质量图像
- 视频理解:分析电影片段中的情感变化、人物关系
3. 语音与音频
- 语音识别:OpenAI的Whisper实现多语种高精度转录
- 语音合成:定制化声音克隆,还原特定人声
- 音乐生成:输入风格关键词,AI创作完整乐曲
4. 跨模态应用
- 图文互转:输入“夕阳下的海边小镇”,生成图片或诗歌
- 视频描述:为盲人用户实时解说视频内容
- 工业检测:结合传感器数据与图像分析设备故障
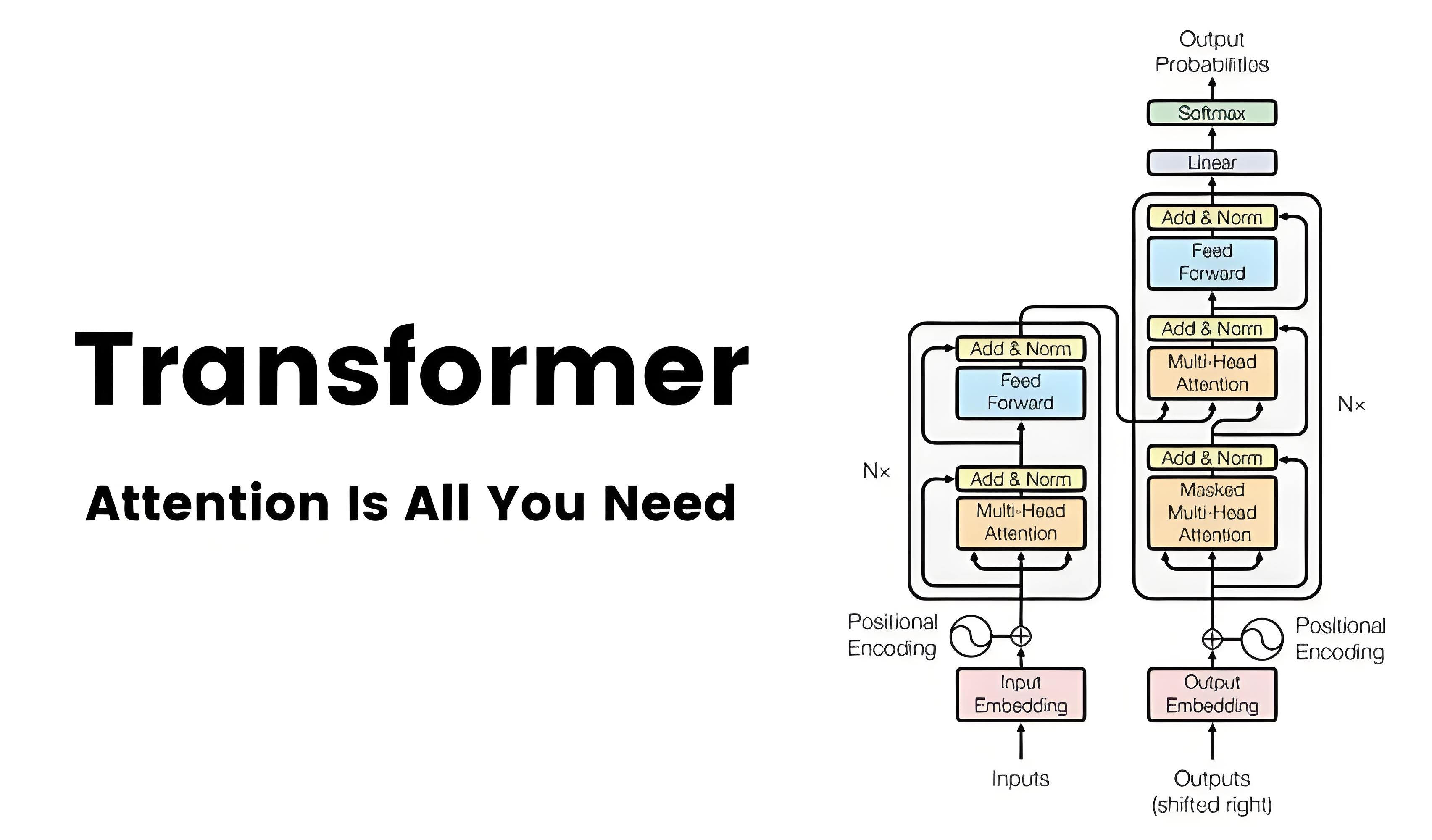
四、Transformer的架构与原理
1. 整体架构图
输入 → 词嵌入 + 位置编码 → 编码器(N层)→ 解码器(N层)→ 输出
│ │
├─ 自注意力机制 ├─ 掩码自注意力
└─ 前馈神经网络 └─ 交叉注意力
2. 核心组件详解
(1) 输入处理:给词语办“身份证”
- 词嵌入(Word Embedding) :将词语转换为数字向量(如“猫”→[0.2, -1.3, 0.8...])。
- 位置编码(Positional Encoding) :通过正弦波标记词语位置,解决“猫抓老鼠”与“老鼠抓猫”的语序问题。
通俗解释: 每个词获得两个身份标识:
- 语义ID:描述词的含义(类似姓名)
- 位置ID:标记词在句子中的座位号(如第一排3号)
(2) 自注意力机制(Self-Attention)
三步走流程:
- 提问与应答:每个词生成Query(问题)、Key(答案关键词)、Value(详细信息)
- 匹配度计算:Query与所有Key计算相似度(如“它”的Query与“猫”的Key匹配度高)
- 信息融合:按匹配度加权平均所有Value,生成新的词表示
举个栗子🌰 : 句子:“The cat didn't catch the mouse because it was too slow.”
-
“it”的注意力权重可能分配为:
- 猫(cat):70%
- 老鼠(mouse):30%
-
最终,“it”的新表示 = 0.7ד猫”的信息 + 0.3ד老鼠”的信息
(3) 多头注意力(Multi-Head Attention)
-
机制:并行运行多组自注意力(如8个“头”),分别关注不同层面的关系
-
优势:
- 头1:关注语法结构(主谓宾)
- 头2:捕捉语义关联(同义词、反义词)
- 头3:分析指代关系(代词指向)
类比理解: 就像让8个专家同时分析同一份文档,各自专注不同角度,最后综合所有人的意见。
(4) 前馈神经网络(FFN)
- 作用:对注意力结果进行非线性变换,增强模型表达能力
- 结构:两层全连接层 + ReLU激活函数
通俗解释: 注意力机制负责“收集信息”,FFN负责“消化吸收”,提炼出更高阶的特征。
(5) 残差连接与层归一化
- 残差连接:保留原始输入信息,防止深层网络的信息丢失
- 层归一化:稳定数据分布,加速训练收敛
类比: 写作时先保留初稿(残差连接),再润色修改(层归一化),避免改得面目全非。
五、Transformer的工作流程(以翻译任务为例)
步骤1:输入处理
- 源语言句子(如中文“今天天气很好”)
- 分词 → 词嵌入 + 位置编码 → 输入编码器
步骤2:编码器运作
- 经过N层编码器(每层包含自注意力 + FFN)
- 输出包含上下文信息的向量表示
步骤3:解码器生成
-
初始输入:起始符
<start> -
循环生成:
- 掩码自注意力:防止看到未来信息
- 交叉注意力:关注编码器输出的相关部分
- FFN处理 → 预测下一个词(如“The”)
- 将预测词加入输入,重复直至输出结束符
<end>
动态示例:
输入:“你好,最近怎么样?”
生成过程:
<start> → "Hello" → "Hello," → "Hello, how" → "Hello, how are" → "Hello, how are you?" → <end>
六、Transformer的局限与未来
现存挑战
- 计算成本高:训练GPT-3需耗费460万美元电费
- 长文本处理:自注意力的复杂度随文本长度平方增长
- 事实性错误:可能生成逻辑连贯但事实错误的内容
创新方向
-
高效注意力:
- 稀疏注意力(如Longformer的滑动窗口)
- 分块计算(如Reformer的局部敏感哈希)
-
知识增强:
- 结合知识图谱验证事实(如Google的LaMDA)
- 引入人类反馈强化学习(ChatGPT的RLHF技术)
-
多模态融合:
- 统一处理文本、图像、声音(如OpenAI的CLIP)
结语:当机器学会“专注”
Transformer的诞生,标志着AI从“机械记忆”迈向了“关联思考”。它不仅仅是一项技术突破,更是一种思维方式的革命——通过赋予机器“动态注意力”,我们让AI开始模仿人类最本质的认知能力:在复杂信息中抓住重点,在万千线索中建立联系。
正如Transformer之父Ashish Vaswani所说:“我们最初只是想改进翻译,但它展现的潜力远超想象。”或许在不远的未来,这场始于“注意力”的革命,将引领我们触摸真正智能的曙光。

本文由博客一文多发平台 OpenWrite 发布!
