

GaussDB-案例:选择合适的分布列
现象描述
表定义如下:
| ``` CREATE TABLE t1 (a int, b int); CREATE TABLE t2 (a int, b int);
| ------------------------------------------------------------------------ |
执行如下查询:
| ```
SELECT * FROM t1, t2 WHERE t1.a = t2.b;
``` |
| ------------------------------------------------ |
#### 优化分析
如果将a作为t1和t2的分布列:
| ```
CREATE TABLE t1 (a int, b int) DISTRIBUTE BY HASH (a); CREATE TABLE t2 (a int, b int) DISTRIBUTE BY HASH (a);
``` |
| ---------------------------------------------------------------------------------------------------------------------- |
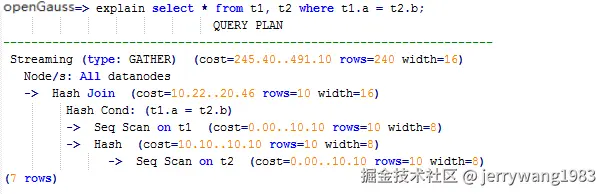
则执行计划将存在“Streaming”,导致DN之间存在较大通信数据量,如[图1](https://doc.hcs.huawei.com/db/zh-cn/gaussdbqlh/24.1.30/devg-dist/gaussdb-12-0302.html#ZH-CN_TOPIC_0000001911586325__zh-cn_topic_0000001704458425_zh-cn_topic_0073253824_zh-cn_topic_0040046521_fig21969731)所示。
[]()[]()**图1** 选择合适的分布列案例(一)

如果将a作为t1的分布列,将b作为t2的分布列:
| ```
CREATE TABLE t1 (a int, b int) DISTRIBUTE BY HASH (a); CREATE TABLE t2 (a int, b int) DISTRIBUTE BY HASH (b);
``` |
| ---------------------------------------------------------------------------------------------------------------------- |
则执行计划将不包含“Streaming”,减少DN之间存在的通信数据量,从而提升查询性能,如[图2](https://doc.hcs.huawei.com/db/zh-cn/gaussdbqlh/24.1.30/devg-dist/gaussdb-12-0302.html#ZH-CN_TOPIC_0000001911586325__zh-cn_topic_0000001704458425_zh-cn_topic_0073253824_zh-cn_topic_0040046521_fig63509856)所示。
[]()[]()**图2** 选择合适的分布列案例(二)
更多详情请参考GaussDB 文档中心:<https://doc.hcs.huawei.com/db/zh-cn/gaussdbqlh/24.1.30/productdesc/qlh_03_0001.html>
