Lecture 5 Policy Gradient I
1. Policy Optimization
Value-based RL 学习的是 near-deterministic policy,但是 Policy-based RL 可以学习 the optimal stochastic policy。
- 基于策略的强化学习是一个优化问题。
- 寻找能够最大化 V(s0,θ) 的策略参数 θ。
无梯度策略优化 Gradient Free Policy Optimization
- 举例 gradient free optimization
- Hill climbing
- Simplex / amoeba / Nelder Mead
- Genetic algorithms
- Cross-Entropy method (CEM)
- Covariance Matrix Adaptation (CMA)
- 通常是一个非常简单的基线方法,可以尝试使用
- 优势
- 可以用于任何策略参数化,包括不可微分的参数化。
- 通常非常容易并行化。
- 局限性
- 通常样本效率较低,因为它忽略了temporal structure
Policy Gradient
- Greater efficiency often possible using gradient
- Gradient descent
- Conjugate gradient
- Quasi-newton
- We focus on gradient descent, many extensions possible
- And on methods that exploit sequential structure
Policy Gradient定义
- Define Vπθ=V(s0,θ) to make explicit the dependence of the value on the policy parameters
- Assume episodic MDPs
- Policy gradient algorithms search for a local maximum in V(s0,θ) by ascending the gradient of the policy, w.r.t parameters θ
Δθ=α∇θV(s0,θ)
- Where ∇θV(s0,θ) is the policy gradient
∇θV(s0,θ)=∂θ1∂V(s0,θ)∂θ2∂V(s0,θ)⋮∂θn∂V(s0,θ)
这个公式表示的是策略梯度,它是一个向量,其中每个元素是价值函数 V(s0,θ) 关于参数 θi 的偏导数。
- α is a step-size parameter
Policy-Based RL优点和缺点
优点:
- 收敛性更好:基于策略的方法通常具有更好的收敛性质。
- 适用于高维或连续动作空间:在高维或连续动作空间中表现有效。
- 可以学习随机策略:能够学习随机策略,增加了策略的灵活性。
缺点:
- 容易陷入局部最优:通常会收敛到局部最优解而不是全局最优解。
- 策略评估(policy evaluation)效率低:评估一个策略通常是低效的,并且方差较高。
总结:
基于策略的强化学习方法在高维或连续动作空间中表现出色,并且能够学习随机策略。然而,它们容易陷入局部最优解,并且策略评估过程通常效率较低且方差较大。那么,接下来我们提出一些想法来解决这些局限性。
2. Differentiable Policy
Many choices of differentiable policy classes including:
- Softmax
- Gaussian
- Neural networks
Value of a Parameterized Policy
-
Assume policy πθ is differentiable whenever it is non-zero and we know the gradient ∇θπθ(s,a).
-
Recall policy value is
V(s0,θ)=Eπθ[∑t=0TR(st,at);πθ,s0]
where the expectation is taken over the states & actions visited by πθ.
-
We can re-express this in multiple ways:
- V(s0,θ)=∑aπθ(a∣s0)Q(s0,a,θ)
- V(s0,θ)=∑τP(τ;θ)R(τ)
-
Where:
- τ=(s0,a0,r0,…,sT−1,aT−1,rT−1,sT) is a state-action trajectory,
- P(τ;θ) is used to denote the probability over trajectories when executing policy π(θ) starting in state s0,
- R(τ)=∑t=0TR(st,at) is the sum of rewards for a trajectory τ.
-
To start will focus on this latter definition. See Chapter 13.1-13.3 of SB for a nice discussion starting with the other definition.
Likelihood Ratio Policies
-
Denote a state-action trajectory as
τ=(s0,a0,r0,…,sT−1,aT−1,rT−1,sT)
-
Use
R(τ)=∑t=0TR(st,at)
to be the sum of rewards for a trajectory τ
-
Policy value is
V(θ)=Eπθ[∑t=0TR(st,at);πθ]=∑τP(τ;θ)R(τ)
-
where P(τ;θ) is used to denote the probability over trajectories when executing policy π(θ)
-
In this new notation, our goal is to find the policy parameters θ:
argmaxθV(θ)=argmaxθ∑τP(τ;θ)R(τ)
Likelihood Ratio Policy Gradient
以下过程主要推导 score function 是怎么来的。
-
Goal is to find the policy parameters θ:
argθmaxV(θ)=argθmaxτ∑P(τ;θ)R(τ)
-
Take the gradient with respect to θ:
∇θV(θ)=∇θτ∑P(τ;θ)R(τ)
=τ∑∇θP(τ;θ)R(τ)
=τ∑P(τ;θ)P(τ;θ)∇θP(τ;θ)R(τ)
=τ∑P(τ;θ)R(τ)P(τ;θ)∇θP(τ;θ)
=τ∑P(τ;θ)R(τ)∇θlogP(τ;θ)
-
The term P(τ;θ)∇θP(τ;θ) represents the likelihood ratio.
Decomposing the Trajectories Into States and Actions:
- Approximate with empirical estimate for m sample paths under policy πθ:
∇θV(θ)≈g^=(1/m)i=1∑mR(τ(i))∇θlogP(τ(i))
∇θlogP(τ(i);θ)=∇θlog[μ(s0)t=0∏T−1πθ(at∣st)P(st+1∣st,at)]
where μ(s0) is the initial state distribution, πθ(at∣st) is the policy, P(st+1∣st,at) is the dynamics model.
=∇θ[logμ(s0)+t=0∑T−1logπθ(at∣st)+logP(st+1∣st,at)]
=t=0∑T−1∇θlogπθ(at∣st)
where the ∇θlogπθ(at∣st) represents the score function.
score function
在强化学习中,score function 是一个重要的概念,尤其是在策略梯度算法中。它用于帮助计算参数化策略的梯度,最终目的是最大化某种目标函数(例如累积奖励)。具体来说,score function 是关于模型参数 θ 的对数概率的梯度。
公式上,score function 通常表示为:
∇θlogπθ(a∣s)
其中:
- πθ(a∣s) 是在状态 s 下选择动作 a 的策略概率,通常由参数 θ 控制。
- ∇θ 表示对参数 θ 的梯度。
-
用途:在策略梯度方法中,通过计算策略的梯度来找到一组策略参数,以便最大化收益。通过对数概率的梯度,我们可以得到关于参数的更新方向。
-
对数简化:对数的导数转换了一些乘积规则为加法规则,计算上更为简便和稳定,特别是在处理小概率时。
-
无偏估计:score function 提供了一个无偏估计,用于评估策略改进的效果,通过结合样本轨迹的回报来进行参数更新。
在实际应用中,score function 是策略梯度定理的重要组成部分,是实现策略优化的重要工具。它允许我们利用采样的方法来估计策略参数的导数,从而进行策略改进。
Softmax Policy
核心思想是通过特征的线性组合对动作进行加权,并将动作的概率设置为该权重的指数化值的比例。这种策略特别适用于离散动作空间,以下是详细解释:
-
加权动作:动作是通过特征的线性组合来加权的,这里的特征表示为 ϕ(s,a)(代表状态 s 和动作 a 的特征),θ 是一组可学习的参数:
ϕ(s,a)Tθ
这种方式类似于线性分类器,通过参数 θ 对特征进行线性加权,计算每个动作的权重。
-
动作概率:给定状态 s 中选择动作 a 的概率与其加权指数值成比例:
πθ(s,a)=∑aeϕ(s,a)Tθeϕ(s,a)Tθ
这里,动作的选择概率是动作权重的 softmax 结果,将所有动作的指数化权重规范化。
-
评分函数(Score Function):针对该策略,评分函数描述了对数概率的梯度:
∇θlogπθ(s,a)=ϕ(s,a)−Eπθ[ϕ(s,⋅)]
- ϕ(s,a) 是特征向量。
- Eπθ[ϕ(s,⋅)] 是在给定状态 s 下根据策略 πθ 对所有动作的特征进行加权后的期望值。
这个评分函数的梯度用于更新策略参数,使得在每个状态下,被选择动作的特征相比于策略中其他潜在动作的特征得到更高的权重,从而改善动作选择的质量。利用这个梯度,策略可以被优化以最大化累积的未来期望奖励。
Gaussian Policy
一般在连续动作空间中使用高斯策略(Gaussian Policy):
-
高斯策略的使用场景:
- 在连续动作空间中,高斯策略是一种自然的选择。这是因为连续空间中动作的选择可以被建模为从一个高斯分布中采样。
-
平均值:
- 高斯策略的平均值 μ(s) 是状态特征 ϕ(s) 的线性组合,具体表示为:
μ(s)=ϕ(s)Tθ
- 这里,θ 是参数向量,ϕ(s) 是所选状态 s 的特征向量。
-
方差:
- 方差可能是固定的 σ2,也可以是参数化的,这意味着可以动态调整方差值来适应策略需要。
-
策略的形式:
- 动作 a 按高斯分布采样:
a∼N(μ(s),σ2)
- 这意味着在给定状态 s 下,动作 a 是从均值为 μ(s),方差为 σ2 的高斯分布中生成的。
-
评分函数(Score function):
- 高斯策略的评分函数用于优化策略参数,通过最大化某种目标(如期望回报),其表达式为:
∇θlogπθ(s,a)=σ2(a−μ(s))ϕ(s)
- 其中 (a−μ(s)) 表示当前动作与均值的偏差,ϕ(s) 是特征向量,方差 σ2 正常化梯度,这样可以指导参数 θ 的更新。
这个公式表示了在参数化策略中,如何根据偏差调整参数来优化策略,即在期望情况下,鼓励选择比当前均值有更高回报的动作,从而改善策略的整体表现。
Likelihood Ratio / Score Function Policy Gradient
似然比+评分函数来优化策略参数:
-
总体目标:
- 目标是找到策略参数 θ,这样可以最大化策略 πθ 的价值函数 V(θ)。这一目标用公式表示为:
argθmaxV(θ)=argθmaxτ∑P(τ;θ)R(τ)
- 这里,∑τP(τ;θ)R(τ) 表示所有可能轨迹的加权回报的综合。
-
经验估计+score function:
-
无需环境动态模型:
- 一个显著的优势是,这种方法不需要了解环境的动态模型。这意味着我们可以通过采样和经验轨迹来优化策略,而不需要明确建模环境的转移概率。
这种策略梯度方法通过对轨迹的回报进行加权平均,利用评分函数提供了对策略参数的无偏梯度估计,从而帮助优化策略以提升长期决策质量。它特别在高维或复杂环境下具有优势,因为不需要依赖对环境的明确建模。
策略梯度定理 Policy Gradient Theorem
-
策略梯度定理 Policy Gradient Theorem:
- 该定理是对似然比方法的广义化。它为从策略优化问题中求解策略梯度提供了一个正式框架,使得我们能够有效地更新策略以最大化累积奖励。
-
定理内容:
- 对于任何可微的策略 πθ(s,a),不论是针对episodic reward J1、每个时间步平均奖励 JavR、还是在折扣因子 γ 下的平均值 1−γ1JavV,策略梯度可以定义为:
∇θJ(θ)=Eπθ[∇θlogπθ(s,a)Qπθ(s,a)]
公式解析:
- ∇θJ(θ):表示目标函数 J(θ) 相对于策略参数 θ 的梯度。
- Eπθ:意味着在策略 πθ 下的期望值。
- ∇θlogπθ(s,a):这是评分函数,也叫对数概率的梯度,用于量化对动作选择的参数影响。
- Qπθ(s,a):代表特定状态-动作对的状态-动作价值函数(action-value function),即在给定策略下从状态 s 采取动作 a 开始所能获得的期望累积奖励。
应用意义:
- 策略优化:策略梯度定理提供了直接优化目标函数的方法,通过按比例更新参数,可以逐步提高策略性能。
- 灵活性:该定理适用于各种目标函数,无论是针对短期过程、平均奖励还是折扣累积值。
借助这一公式,策略迭代可以更加有效地进行,不仅利用样本路径的回报信息,而且通过价值函数的指导,形成更有导向性的优化。这在复杂环境或神经网络参数化策略中尤为关键,因为它允许通过估计与模拟来实现非线性决策策略的系统性优化。
3. Policy Gradient Algorithms and Reducing Variance
∇θV(θ)≈m1i=1∑mR(τ(i))t=0∑T−1∇θlogπθ(at(i)∣st(i))
-
公式:
- 公式表示了策略梯度的一个经验估计方法,其中通过 m1次采样路径 τ(i) 来近似 ∇θV(θ)。
- ∇θlogπθ(at∣st) 是策略对数的梯度,衡量采取某个动作 at 的偏导效果。
- R(τ(i)) 是第 i 个样本路径的总回报,作为每个路径在梯度更新中贡献的权重。
-
无偏但具有高噪声:
- 无偏性指的是这种估计方法在理论上可以准确反映阶梯度的期望值。然而,由于单路径回报和策略梯度计算的随机性,结果往往比较noisy。
-
实用改进方法:
- Temporal structure(时间结构):利用序列数据中的时间相关性可以减少噪声,比如通过平滑时间序列或者识别关键的时间依赖性。
- Baseline(基线):引入基线可以减少回报的方差,通常通过从回报上减去一个适当的基线来加强稳定性和减少噪声,最常见的基线是状态值函数的估计。
- Alternatives to MC Returns
通过这些改进,策略梯度的实际实现变得更为可操作和稳定,从而能够更有效地优化策略在复杂环境中的表现。
Temporal Structure
-
回顾之前:
- 初始的策略梯度估计针对的是整个回报的期望 ∇θEτ[R],可以通过以下公式来表示:
∇θEτ[R]=Eτ[(t=0∑T−1rt)(t=0∑T−1∇θlogπθ(at∣st))]
- 这表明我们在考虑整个轨迹的所有奖励和相应的策略对数梯度。
-
时间结构的使用:
- 可以将相同的方法应用于单个奖励项 rt′,以获得一个单独的奖励梯度估计:
∇θE[rt′]=Ert′t=0∑t′∇θlogπθ(at∣st)
- 通过这种方式,我们能够在计算中显式地表达时间结构。
-
累加以得到完整的策略价值梯度:
- 通过对上述公式在所有时间步 t 上进行累加,我们得到完整的策略梯度:
V(θ)=∇θE[R]=Et′=0∑T−1rt′t=0∑t′∇θlogπθ(at∣st)
- 进一步简化为:
=E[t=0∑T−1∇θlogπθ(at,st)t′=t∑T−1rt′]
- 这一形式表达了累积奖励作为未来时间步回报的和。
-
具体轨迹的回报:
- 对于特定轨迹 τ(i),其累积回报为 Gt(i):
∇θE[R]≈(1/m)i=1∑mt=0∑T−1∇θlogπθ(at,st)Gt(i)
- 这体现了通过蒙特卡罗模拟(MC)对期望回报的估计,把时间结构用于策略局部梯度计算以改进策略模型。
应用优势:
- 时间依赖结构:通过显式表达时间依赖结构,可以更直观地理解每个动作和状态对未来奖励的微影响,从而进行更细致的参数调整。
- 增量更新:利用这种方式,策略优化可以通过增量更新来实现,更好地捕捉时间相关性和动态变化因素,提升策略在复杂环境中的适应能力。
这种方法能够使策略的学习更为精细化,针对每一个时间步评估并运用其长期影响,更有效地优化策略,以实现更高效的任务执行。
Monte-Carlo Policy Gradient (REINFORCE)
利用似然比(likelihood ratio)/评分函数(score function)+ 时间结构(Temporal Structure)来更新策略参数:
-
似然比 / 评分函数:
- ∇θlogπθ(st,at) 被称为对数似然梯度或者评分函数,这部分是策略梯度方法的核心。
- 它衡量了策略参数 θ 如何影响在状态 st 下选择动作 at 的概率,提供了参数调整的方向。
-
时间结构:
- 算法利用了时间序列数据的结构,即每个动作在时间线上如何对后续回报产生影响。
- 这个结构在累积回报的设定中起关键作用。回报 Gt 表示从当前时间 t 到episode结束的总累积回报。
-
更新公式:
Δθt=α∇θlogπθ(st,at)Gt 是策略参数更新的公式。
- 其中,α 是学习率,控制参数更新的步长。
- 通过这个更新公式,算法以 Gt 为权重来调整 θ,选择时将更高的累计回报放在优先考虑的更新方向上。

实质:
- 该公式结合了从当前策略 πθ 生成的样本路径信息进行策略更新,其中每个动作的选择不仅考虑了即时影响,还内含了其对后续整个情节的影响。
- 通过使用似然比和时间结构,这种方法能够无偏地估计策略梯度,并通过样本生成的回报信息进行直接的、渐进的策略改进。
最终,这种方法提供了一种有效的路径优化机制,使策略参数在梯度方向上更快收敛,提升了策略在环境中的表现。
Baseline
引入基线的主要目的是减少梯度估计中的方差,同时保持无偏性。这为策略的更新提供了更稳定和高效的方式。
-
方差减少:
- 图中显示了使用基线 b(s) 以减少梯度估计的方差。基线函数仅依赖于状态 st,这可以是任意的,但常常选择为一个好的基线值以最小化方差。
-
无偏性:
- 对于任何基线选择,梯度估计保持无偏。这意味着引入基线不会改变梯度估计的期望值,仅仅是减少了结果的方差。
-
基线选择:
- 近最佳的基线选择是预期的后续回报:
b(st)≈E[rt+rt+1+…+rT−1]
- 将基线选为期望回报是因为它提供了实际回报和期望回报之间的对比,从而改善优化的稳定性。
-
阐释:
- 动作 at 的对数概率的增加与实际回报 ∑t′=tT−1rt′ 超出预期回报的程度成比例。即,当实际回报高于预期回报时,增加增加动作发生的概率。
不引入偏差的证明:
Eτ[∇θlogπθ(at∣st;θ)b(st)]
- 期望值 Eτ[∇θlogπθ(at∣st)b(st)] 在整个轨迹上的预期值为零,这证明了基线不引入偏差。
- 这是因为:任何关于状态的函数对更新方向并无影响,因为在梯度更新中,它被乘以一个与梯度无关的项。
计算流程:

状态值函数可作为基线:
-
Q 函数Qπ(s,a):
- 它表示在策略 π 下,从状态 s 开始并采取动作 a 后能期望获得的累积回报。
- 数学表达式为:
Qπ(s,a)=Eπ[r0+γr1+γ2r2+…∣s0=s,a0=a]
- 其中,γ 是折扣因子,用于衡量未来回报的重要性。
-
状态值函数 Vπ(s):
- 表示在状态 s 下,根据策略 π 继续采取行动时所期望的累积回报。
- 数学表达式为:
Vπ(s)=Eπ[r0+γr1+γ2r2+…∣s0=s]
- 也可以通过对所有可能动作的 Q 值求期望得到:
Vπ(s)=Ea∼π[Qπ(s,a)]
-
状态值函数作为基线:
- 在策略梯度方法中,状态值函数 Vπ(s) 可用作基线以减少方差,这样能够使策略更新更稳定。
- 使用 Vπ(s) 作为基线能够帮助分离普遍的奖励期望和特定动作的优越性。
总结:
- 引入基线可以显著减少策略梯度方法中的方差从而加速学习过程。
- 尽管基线的选择可以是任意的,选择一个合适的基线如状态价值的估计,可以更好地稳定学习过程。
- 在实际应用中,选取合适的基线是策略优化中一个重要且有效的技巧。
Alternatives to MC Returns (Actor-critic Methods)
根据上面Temporal Structure 和 Baseline,我们可以得到如下公式:
策略梯度公式
∇θE[R]≈m1i=1∑mt=0∑T−1∇θlogπθ(at,st)(Gt(i)−b(st))
Gt(i)无偏但是方差高。那么问题来了,能不能寻找一个替代,来替代 Monte Carlo 回报 Gt(i) 作为由 θ 参数化的策略的期望折现回报和的估计值?
答案:Actor-critic Methods
Lecture 6 Policy Gradient II
1. Actor-critic Methods
- 对 V/Q 的估计是由评论家(critic)完成的。
- 演员-评论家(actor-critic)方法保持策略 policy 和价值函数 value function 的明确表示,并同时更新这两者。
- A3C(Mnih 等在 ICML 2016年提出)是一个非常流行的演员-评论家方法。
使用价值函数的策略梯度公式
∇θEτ[R]≈Eτ[t=0∑T−1∇θlogπ(at∣st;θ)A^π(st,at)]
- 其中,state-action advantage function Aπ(s,a)=Qπ(s,a)−Vπ(s)
Choosing the Target: N-step estimators
∇θV(θ)≈m1i=1∑mt=0∑T−1R^t(i)∇θlogπθ(at(i)∣st(i))
- 请注意,评论家可以选择任何时间差分(TD)和蒙特卡罗(MC)估计器的混合,以替代真实的状态-动作值函数。
R^t(1)=rt+γV(st+1)
R^t(2)=rt+γrt+1+γ2V(st+2)…
R^t(inf)=rt+γrt+1+γ2rt+2+⋯
A^t(1)=rt+γV(st+1)−V(st)
A^t(inf)=rt+γrt+1+γ2rt+2+⋯−V(st)
解决方案:A^t(1) 具有低方差和高偏差,A^t(∞) 具有高方差但低偏差。
2. Policy Gradients 的问题
策略梯度回顾
策略梯度算法尝试通过对策略参数 θ 进行随机梯度上升来解决优化问题:
θmaxJ(πθ)=˙Eτ∼πθ[t=0∑∞γtrt]
使用策略梯度:
g=∇θJ(πθ)=Eτ∼πθ[t=0∑∞γt∇θlogπθ(at∣st)Aπθ(st,at)].
策略梯度的局限性:
- 样本效率低:策略梯度方法往往需要大量样本才能取得有效的学习。
- 参数空间的距离 ≠ 策略空间的距离:
- 什么是策略空间?对于表格情况,策略空间是矩阵的集合:
Π={π:π∈R∣S∣×∣A∣,a∑πsa=1,πsa≥0}
- 策略梯度在参数空间内采取步进。
- 因此,步长的设置很难准确把握。
策略梯度的样本效率
- 对于原始策略梯度方法来说,样本效率很低。
- 在进行一步梯度更新后立即丢弃每一批次的数据。
- 为什么?因为策略梯度是一种依赖当前策略的期望值。
- 获取无偏策略梯度估计的两种主要方法:
- 从当前策略采集样本轨迹,然后形成样本估计。(更稳定)
- 使用其他策略的轨迹。(较不稳定)
- 机会:在使用新策略收集更多数据之前,利用旧数据进行多次梯度更新。
- 挑战:即便可以使用旧数据来估计多个梯度,应该进行多少步更新?
策略梯度选择步长
策略梯度算法是随机梯度上升:
θk+1=θk+αkg^k
其中步长 Δk=αkg^k。
- 如果步长太大,可能会导致性能崩溃。
- 如果步长太小,进展会变得不可接受的慢。
- “合适的”步长大小是基于 θ 变化的。
像advantage normalization 或 Adam 风格的优化器这样的自动学习率调整可以有所帮助。但这是否解决了问题?
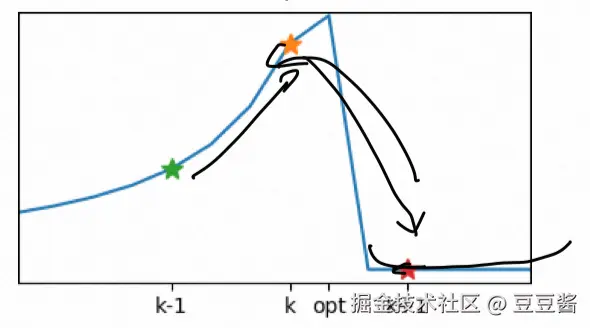 图中展示了 x 轴上的策略参数和 y 轴上的性能。一个错误的步进可能导致性能崩溃,而这可能很难恢复。
图中展示了 x 轴上的策略参数和 y 轴上的性能。一个错误的步进可能导致性能崩溃,而这可能很难恢复。
这张图的内容翻译如下:
问题不仅仅是步长
考虑一个具有以下参数化形式的策略族:
πθ(a)={σ(θ)1−σ(θ)a=1a=2
其中 σ(θ) 是逻辑函数,即 1+e−θ1。
图中展示了不同 θ 值时 π(a∣θ) 的效果:
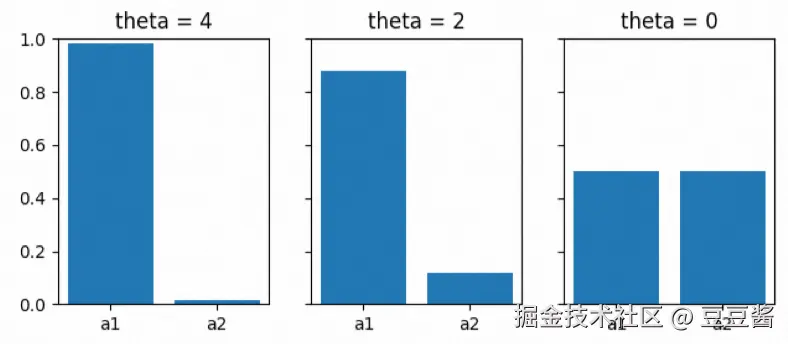
图中描述了在策略参数发生小变化时,策略可能会意外地发生巨大变化。
重要问题:
如何制定一个更新规则,以确保策略的变化不会超过预期?
3. Policy Performance Bounds
两个策略的相对性能
在策略优化算法中,我们希望更新步长:
- 尽可能高效地使用从最近的策略收集的 rollout 数据。
- 在策略空间中采取尊重策略空间距离的步长,而不是参数空间的距离。
为了找出正确的更新规则,我们需要利用两个策略之间性能的关系。
Performance difference lemma 性能差异引理:
我们要求你证明,对于任何策略 π 和 π′:
J(π′)−J(π)=Eτ∼π′[t=0∑∞γtAπ(st,at)]=1−γ1Es∼dπ′,a∼π′[Aπ(s,a)]
其中,
dπ(s)=(1−γ)t=0∑∞γtP(st=s∣π)
这有什么用?
我们能否将其用于策略改进,其中 π′ 表示新策略,而 π 表示旧策略?
π′maxJ(π′)=π′max(J(π′)−J(π))
=π′maxEτ∼π′[t=0∑∞γtAπ(st,at)]
这具有启发性,但目前还不够实用。
这个优化问题的一个优点是:它定义了 π′ 的性能,以 π 的 advantage 为依据!
但也存在问题:依然需要从 π′ 中采样轨迹……
我们的目标:仅从 π 的数据中估计 J(π′)。
重要性采样
根据 discounted future state distribution , dπ 定义为:
dπ(s)=(1−γ)t=0∑∞γtP(st=s∣π),
我们可以重新表述相对策略性能等式:
J(π′)−J(π)=Eτ∼π′[t=0∑∞γtAπ(st,at)]
=1−γ1Es∼dπ′,a∼π′[Aπ(s,a)]
=1−γ1Es∼dπ′,a∼π[π(a∣s)π′(a∣s)Aπ(s,a)]
最后一步是重要性采样 (importance sampling) 的一个实例(下次将详细讨论这个)。
那么!现在我们唯一的问题是 s∼dπ′。
一个有用的近似
如果我们直接假设 dπ′≈dπ 并不对此进行担心,会是什么结果呢?
J(π′)−J(π)≈1−γ1Es∼dπ,a∼π[π(a∣s)π′(a∣s)Aπ(s,a)]
=˙Lπ(π′)
事实证明,当 π′ 和 π 非常接近时,这个近似效果非常好。但为什么呢?他们需要多接近?
相对策略性能界 Relative policy performance bounds:
∣J(π′)−(J(π)+Lπ(π′))∣≤CEs∼dπ[DKL(π′∥π)[s]]
如果策略在 KL 散度上很接近,那么这个近似就很好!
什么是 KL 散度?
对于离散随机变量上的概率分布 P 和 Q:
DKL(P∥Q)=x∑P(x)logQ(x)P(x)
性质:
- DKL(P∥P)=0
- DKL(P∥Q)≥0
- DKL(P∥Q)=DKL(Q∥P) —— 非对称!
策略之间的 KL 散度是什么?
DKL(π′∥π)[s]=a∈A∑π′(a∣s)logπ(a∣s)π′(a∣s)
通过进行这种近似,我们获得了什么?
J(π′)−J(π)≈Lπ(π′)
Lπ(π′) 定义为:
Lπ(π′)=1−γ1Es∼dπ,a∼π[π(a∣s)π′(a∣s)Aπ(s,a)]
=Eτ∼π[t=0∑∞γtπ(at∣st)π′(at∣st)Aπ(st,at)]
- 这是一种可以通过旧策略 π 采样的轨迹进行优化的方法!
- 类似于使用重要性采样,但由于权重仅依赖于当前时间步(而不是先前的历史),因此不会消失或爆炸。
PPO
Proximal Policy Optimization (PPO) 是一种流行的强化学习算法,它以简单而有效著称。PPO 使用了一种新的策略梯度更新方法来稳定训练过程,同时减少了复杂度和超参数的调整。PPO 运用的核心是其特殊的损失函数,这个损失函数能够限制策略更新的变化幅度,因此称为"近端"(Proximal)策略优化。
PPO 的总损失函数
梯度上升
L(θ)=Et[LCLIP(θ)−cvLVF(θ)+ceLENTROPY(θ)]
其中:
- LVF(θ) 是值函数损失,用于估计状态值,通常是均方误差(MSE)。
- cv 和 ce 是常数,控制每个损失项的相对权重。
这种设计使得 PPO 能够在短步长(small steps)内更新策略,而不会偏离太远,从而增强了策略调整过程的稳定性和可靠性。这种稳定的政策搜索方法可以在解决连续控制任务和离散动作空间任务时取得良好的效果。
1. 克利普损失函数(Clipped Surrogate Objective)
克利普损失函数是 PPO 的核心,它通过限制策略之间的变动幅度来稳定策略更新。其基本思想是通过折减(clipping)比率 (ratio) ,有条件地限制新策略与旧策略的变化。具体公式如下:
LCLIP(θ)=Et[min(rt(θ)A^t,clip(rt(θ),1−ϵ,1+ϵ)A^t)]
其中:
- rt(θ)=πθold(at∣st)πθ(at∣st):表示新旧策略概率比。
- A^t:是优势函数(advantage function)的估计值,它衡量动作 at 的有益程度。
- ϵ:是一个很小的参数,用于限制策略变化的范围(通常在0.1到0.2之间)。
- clip(⋅):函数将比率限制在 [1−ϵ,1+ϵ] 的范围内。
2.值函数损失
LVF(θ)=Et[(Vθ(st)−V^t)2]
即
=21Vθ(s)−(t=0∑Tγtrt∣s0=s)22
3. 熵奖励(Entropy Bonus)
PPO 通常包括一个熵项来鼓励策略的探索。这是通过增加损失函数的熵来实现的,即:
LENTROPY(θ)=Et[β⋅H(πθ(⋅∣st))]
其中:
- H(πθ(⋅∣st)):表示策略在状态 st 下的熵。
- β:是熵奖励系数,控制熵项在总损失中的权重。
详解
近端策略优化(PPO)是一类方法,它通过对策略变化过大的步长施加惩罚来优化策略,通过不计算自然梯度来近似强制执行 KL 约束。它有两种变体:
1. Adaptive KL Penalty 自适应 KL 惩罚
- 策略更新解决无约束的优化问题:
θk+1=argθmaxLθk(θ)−βkDˉKL(θ∥θk)
DˉKL(θ∥θk)被定义为:
DˉKL(θ∥θk)=Es∼dπk[DKL(θk(⋅∣s),πθ(⋅∣s))]
- 惩罚系数 βk 在迭代之间变化,以近似强制 KL 散度约束。

2. 截断目标 Clipped Objective
-
新的目标函数:令 rt(θ)=πθ(at∣st)/πθk(at∣st)。那么
LθkCLIP(θ)=Eτ∼πk[t=0∑Tmin(rt(θ)A^tπk,clip(rt(θ),1−ϵ,1+ϵ)A^tπk)]
其中,ϵ 是一个超参数(可能取值是 0.2)。
-
策略更新为 θk+1=argmaxθLθkCLIP(θ)。

这张图解释了在PPO算法中,截断(clipping)如何通过让目标函数在远离θk的位置上保持"悲观"态度,以确保策略的稳定性和连续性。
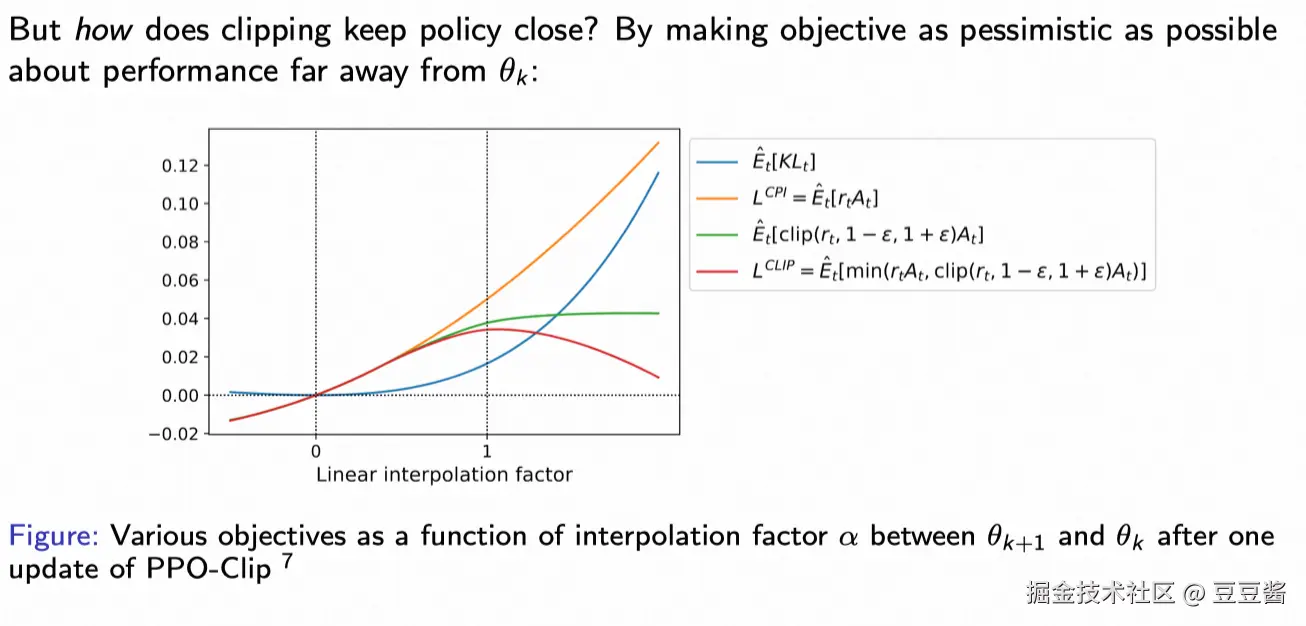 图表解释:
图表解释:
-
X轴:线性插值因子α,它表示当前策略参数θ在θk和θk+1之间的插值位置。
-
Y轴:不同目标函数的值,这反映了目标函数随α变化时的表现。
-
线条表示:
- 蓝色线:E^t[KLt],表示KL散度的期望值,随着α增大,KL散度也增大,反映策略的变化。
- 橙色线:LCPI,即经典的策略梯度目标函数E^t[rtAt],它的值随着α增加单调上升(CPI:Conservative Policy Iteration)。
- 绿色线:E^t[clip(rt,1−ϵ,1+ϵ)At],它对α的响应被截断,以限制策略更新的步幅。
- 红色线:LCLIP,即PPO的截断目标函数E^t[min(rtAt,clip(rt,1−ϵ,1+ϵ)At)],这条线演示了PPO通过取较小值来避免策略参数过大变化的作用,它在α过大时趋于水平,表示对过大变化的抑制。
-
Pessimistically Optimistic:截断目标通过限制更新幅度使得其在远离当前策略θk时表现为"悲观",即不会鼓励策略在每一步更新中过多改变,以避免由于更新过大导致的不稳定性。
-
稳定性与效率:通过限制策略更新步幅,PPO保持策略逐步改进,使其能在复杂策略空间中稳定收敛。
Generalized Advantage Estimator ( GAE )
我们得到PPO的截断目标是
LθkCLIP(θ)=Eτ∼πk[∑t=0Tmin(rt(θ)A^tπk,clip(rt(θ),1−ϵ,1+ϵ)A^tπk)]
那么问题来了,我们如何在策略更新中估计优势函数A^tπk?
∇_θV(θ)≈m1∑_i=1m∑_t=0T−1A_ti∇_θlogπ_θ(a_ti∣s_ti)
- 回顾N-step advantage estimators
A^(1)∗t=r_t+γV(s∗t+1)−V(s_t)
A^(2)∗t=r_t+γr∗t+1+γV(s_t+2)−V(s_t)
A^(inf)∗t=r_t+γr∗t+1+γ2r_t+2+⋯−V(s_t)
δV_t=r_t+γV(s_t+1)−V(s_t)
然后:
A^(1)∗t=δV_t=r_t+γV(s∗t+1)−V(s_t)
A^(2)∗t=δV_t+γδV∗t+1=r_t+γr_t+1+γ2V(s_t+2)−V(s_t)
A^(k)∗t=∑∗l=0k−1γlδV_t+l=∑_l=0k−1γlr_t+l+γkV(s_t+k)−V(s_t)
以上是一个 telescoping sum 例子。
Generalized Advantage Estimator ( GAE ) Balance
A^(k)∗t=∑∗l=0k−1γlr_t+l+γkV(s_t+k)−V(s_t)
- GAE 是一种对 k-step estimators 进行指数加权平均的方式:
A^tGAE(γ,λ)=(1−λ)(A^t(1)+λA^t(2)+λ2A^t(3)+⋯)
=(1−λ)(δV_t+λ(δV_t+γδV_t+1)+λ2(δV_t+γδV_t+1+γ2δV_t+2)+⋯)
=(1−λ)(δV_t(1+λ+λ2+⋯)+γδV_t+1(λ+λ2+⋯)+γ2δV_t+2(λ2+λ3+⋯)+...)
=(1−γ)(δV_t1−λ1+γλδV_t+11−λ1+γ2λ2δV_t+21−λ1+⋯)
=∑_l=0∞(γλ)lδV_t+l
-
GAE 方法首次在 Schulman 等人的“High-Dimensional Continuous Control Using Generalized Advantage Estimation”论文中引入(发表于ICLR 2016年)。
-
通常,我们会选择 λ∈(0,1) 来平衡偏差和方差。
PPO 使用了 GAE 的截断版本:
A^∗t=∑∗l=0T−t−1(γλ)lδV_t+l
- 优势:只需在环境中运行策略 T 个时间步长后即可进行更新,从而改进梯度估计。
Monotonic Improvement Theory
回到两个策略之间差异的近似界限
- 在上次中,我们使用 dπ′ 作为 dπ 的近似
J(π′)−J(π)≈1−γ1Es∼dπ,a∼π′[π(a∣s)π′(a∣s)Aπ(s,a)]
这个近似结果被标注为 Lπ(π′)
∣J(π′)−(J(π)+Lπ(π′))∣≤CEs∼dπ[DKL(π′∥π)[s]]
Monotonic Improvement Theory定义
根据上面的公式,我们得到:
J(π′)−J(π)≥Lπ(π′)−CEs∼dπ[DKL(π′∥π)[s]]
- 如果我们最大化右侧(right hand side RHS)关于 π′(新策略) 的值,我们可以保证相对于 π (旧策略)取得改进。
- 这是一种关于真实目标(即左侧 LHS)的majorize-maximize算法。
- Lπ(π′) 和 KL 散度项都可以使用来自 π 的样本进行估计!
证明:
假设 πk+1 和 πk 通过以下关系关联:
πk+1=argπ′maxLπk(π′)−CEs∼dπk[DKL(π′∥πk)[s]]
-
πk 是一个可行点,并且在 πk 的目标值等于0。
- Lπk(πk)∝Es,a∼dπk,πk[Aπk(s,a)]=0
- DKL(πk∥πk)[s]=0
-
⟹ optimal value ≥0
-
⟹ 根据性能界限,J(πk+1)−J(πk)≥0
以上证明在我们将优化域限制于任意参数化策略类 Πθ 时依然成立,只要 πk∈Πθ。
Approximate Monotonic Improvement
公式:
πk+1=argπ′maxLπk(π′)−CEs∼dπk[DKL(π′∥πk)[s]]
问题:
- 当折扣因子 γ 接近1时,理论提供的 C 值相当高 => 公式中的步长太小。
解决方案:
- 调整 KL penalty(=> PPO)。
- 使用 KL constraint(called trust region)。
PPO 总结
- 提高数据效率:在从新策略收集更多数据之前,可以进行多个梯度步骤
- 使用 clipping (或者 KL constraint) 来帮助增加单调改进的可能性
- 保守的策略更新在强化学习中是一个具有影响力的理念,至少可以追溯到2000年代初
- 收敛到局部最优
- 非常流行的方法,易于实现,用于ChatGPT的调优
Policy Gradient 总结
- 极其流行且有用的算法
- 可用于奖励函数不可微的情况
- 经常与无模型的价值方法结合使用:actor-critic methods
Lecture 7 Imitation Learning
模仿学习(Imitation Learning)是一种机器学习方法,它通过模仿专家演示的行为来学习任务。模仿学习在任务中不明确或很难定义奖励函数时,特别有用,常见于机器人控制、自动驾驶和游戏等领域。
-
专家演示:
- 模仿学习的基础在于专家提供的行为轨迹,这些轨迹包含状态和相应的动作序列。例如,一个人类驾驶员在驾驶过程中做的决策可以作为演示数据。
-
学习策略:
- 目标是从这些演示中学习一个策略,使得学习到的代理能在相似情境下采取与专家相似的动作。
-
不依赖显式奖励信号:
- 与常规强化学习不同,模仿学习主要依赖于演示数据,而不是环境提供的奖励信号。它通过模仿专家成功的动作偏好来指导学习。
模仿学习的常见方法
-
行为克隆(Behavioral Cloning):
- 是模仿学习最简单的形式,把模仿问题转换为监督学习问题。直接从状态-动作对中学习映射,类似于分类或预测任务。
- 依赖于大量的高质量演示数据,并可能对未见过的状态表现不佳(即分布外的泛化问题)。
-
逆向强化学习(Inverse Reinforcement Learning, IRL):
- 通过演示推断出隐含的奖励函数,然后使用这个奖励函数来引导策略学习。
- 能够泛化到新的环境,并不需要显式的奖励定义。
应用场景
- 自动驾驶:通过模仿人类驾驶数据,形成自动驾驶系统的控制策略。
- 游戏AI:模仿高水平玩家,在视频游戏环境中执行复杂的策略。
- 机器人手臂控制:通过模仿专家操作机器人手臂,完成复杂任务。
挑战
- 数据质量:模仿学习对演示数据的质量和多样性要求很高,坏数据会显著影响性能。
- 分布偏移:当状态分布与训练时的分布不同时,模型性能可能下降。
- 鲁棒性和泛化:在未见过的状态下,应保证策略依然有效。
通过有效地利用演示数据,模仿学习能够在一定程度上减少任务的手动定义复杂性,尤其是在奖励函数难以确定或不易捕捉任务本质的情况下。
问题设置
1. Behavioral Cloning
行为克隆(Behavioral Cloning, BC)是一种模仿学习技术,通过将专家的行为演示转化为监督学习问题,直接从状态-动作对中进行学习。这种方法的目标是学习一个策略,使得人工智能代理可以在类似情况下采取与专家相同的动作。
- 数据收集:
- 从专家操作的系统或者环境中获取大量的演示数据。这些数据构成了一系列的状态和对应的动作对 ((s, a)),用于训练模型。
- 监督学习问题:
- 行为克隆将模仿问题框化为一个经典的监督学习问题,其中状态 (s) 作为输入,动作 (a) 作为目标输出。
- 可以使用标准的机器学习算法(如线性回归、决策树、神经网络)训练这个输入到输出的映射。
- 训练策略:
- 使用收集到的数据集训练策略模型,使其能够在给定状态下预测适当的动作。
优势
- 直接性和简单性:
- 将模仿任务转化为一个标准的监督学习任务,易于理解和实施。
- 快速学习:
- 不需要明确的奖励函数设计,直接利用专家行为数据,可以迅速部署和测试。
局限性
- 数据依赖:
- 需要大量高质量和多样化的演示数据覆盖大部分可能的状态空间。
- 没有足够的演示数据可能导致策略在新场景中的表现不佳。
- 分布偏移(Covariate Shift):
- 由于代理的行为不同于专家,运行时的状态分布可能与训练分布不同,从而影响策略的有效性。
- 如果模型偏离了专家的演示路径,可能无法有效恢复,尤其在没有看到过的状态。
- 泛化能力:
- 通常在训练数据之外的状态具有较差的泛化性能,容易出现错误决策。
DAGGER
DAGGER(Dataset Aggregation)是一种改进的行为克隆方法,旨在克服行为克隆中常见的分布偏移问题。行为克隆在遇到代理的状态分布与训练时的分布不同(通常由于早期决策错误导致系统偏离正常轨迹)时,性能可能受到显著影响。DAGGER通过交互式数据收集和逐步更新来解决这一问题。
-
初始训练:
- 从专家的演示中初始化模型,与经典的行为克隆方法类似。
-
在线交互与收集:
- 模型用来运行一段时间或若干步骤,收集由此产生的状态和动作对。
- 与此同时,专家在这些新出现的状态下也给出对应的动作,生成一个专家标注的“正确”动作。
-
数据集聚合:
- 将新收集的状态和相应的专家动作标注加入到训练数据集中,以扩展和多样化数据样本。
-
重新训练模型:
- 使用更新后的数据集再次训练模型,以不断提高策略的鲁棒性和准确性。
-
迭代更新:
- 重复以上过程,直到模型在多样化的状态空间上达到满意的性能表现。

优势
- 有效缓解分布偏移:
- 通过逐渐扩展数据集,使模型能在各种状态下做出更准确的决策,从而抵御由分布偏移引起的性能下降。
- 增强泛化能力:
- 引入多样化的状态和相应的专家动作,使模型能处理未见过的状态,提升泛化能力。
- 实用性:
- DAGGER在需要相对较少的专家交互的情况下显著提高模型的鲁棒性,是多种机器人和自动驾驶应用中实现稳定策略的重要方法。
局限性
- 专家干预要求:
- 需要从专家处收集新的动作标注,可能对现实系统的原型设计和部署造成一些复杂性。
- 计算和时间成本:
- 由于模型需要多个迭代进程来训练和更新,多次训练的成本可能很高。
2. Reward Learning
- 给定状态空间、动作空间、转移模型 P(s′∣s,a)
- 没有奖励函数 R
- 一组或多组教师的演示 (s0,a0,s1,s0,…)(动作从 teacher policy π∗ 中抽取)
- 目标:推断奖励函数 R
假设教师的策略是最优的,存在许多可能的 R 使得教师的策略最优。
Linear Feature Reward Inverse RL
- 回忆 linear value function approximation
- 类似地,这里考虑 reward 在特征上是线性的情况:
- R(s)=wTx(s),其中 w∈Rn,x:S→Rn
- 目标:给定一组demonstrations,计算出来权重向量 w
- 对于一个策略 π,其相应的值函数可以表示为:
Vπ(s0)=Es∼π[t=0∑∞γtR(st)∣s0]=Es∼π[t=0∑∞γtwTx(st)∣s0]=wTEs∼π[t=0∑∞γtx(st)∣s0]=wTμ(π)
- 其中,μ(π)(s) 被定义为在状态 s0 下,策略 π 下 state features 的折扣加权频率。
Relating Frequencies to Optimality
Vπ=wTμ(π)
- 其中 μ(π)(s) = discounted weighted frequency of state s under policy π
Es∼π∗[t=0∑∞γtR∗(st)∣π∗]=V∗≥Vπ=Es∼π[t=0∑∞γtR∗(st)∣π]∀π
- 因此,如果专家的演示来自最优策略,要识别 w 就需找到满足以下条件的 w∗:
w∗Tμ(π∗)≥w∗Tμ(π),∀π=π∗
Feature Matching
- 希望找到一个奖励函数,使得专家策略相较于其他策略具有更好的表现。
- 对于策略 π ,为了确保其表现与专家策略 π∗ 一样好,只需要保证其折扣求和值的特征期望与专家的策略相匹配 [Abbeel & Ng, 2004]。
- 更准确地说,如果
∣μ(π)−μ(π∗)∣_1≤ϵ
那么对于所有满足 ∥w∥∞≤1 的 w (使用Holder不等式):
∣wTμ(π)−wTμ(π∗)∣≤ϵ
Ambiguity
-
奖励函数的无限多样性:
- 存在无穷多个奖励函数可以对应同一个最优策略。这意味着,从相同的最优行为中推断奖励机制时,无法唯一确定可能的奖励函数。
-
随机策略的无限多样性:
- 存在无穷多个随机策略可以匹配相同的feature counts,即μ(π) 。这意味着即使feature counts匹配,仍然可能有许多策略组合能够实现这些匹配。
那么选择哪个?:由于有众多符合条件的奖励函数和策略,需要决定选择哪个作为基础进行学习。这通常涉及到添加某种偏好、约束或额外的信息来解决这种歧义性。
Maximum Entropy Inverse RL
最大熵原理在逆向强化学习中的应用
- 回顾一个分布 p(s) 的熵,其计算公式是:−∑s′p(s=s′)logp(s=s′)
- 最大熵原理:在给定特定先验数据约束的情况下,最好地表示当前知识状态的概率分布是拥有最大熵的那个分布。
- 直观上:考虑所有与观察数据一致的概率分布,并选择具有最大熵的概率分布。
- 在线性奖励情况下,这等价于指定权重 w,以产生具有最大熵的策略,同时满足特征期望的约束:
max_P−∑_τP(τ)logP(τ)s.t.∑_τP(τ)μ(τ)=∣D∣1∑_i∈Dμ(τ_i)∑_τP(τ)=1
- 其中,μ(τ) 是轨迹 τ 的特征,D 是观察到的专家数据。
Matching Rewards to Learning Policies
- 通常情况下,希望找到一个策略 π,其引发的轨迹分布 p(τ) 在给定奖励函数 rϕ 下,具有与专家演示P^(τ) 相同的期望奖励。
- 具体地,要解决以下优化问题:
- 为此,将在计算奖励函数、利用该奖励函数学习最优策略,以及更新轨迹/状态频率以更新奖励函数之间交替进行。
- 注意:在最初的最大熵逆向强化学习论文中,假设dynamics / reward model是已知的。
计算流程
注意:假设已知的 dynamics model 和 linear rewards
- 输入:专家演示 D
- 初始化 rϕ
- 计算在给定 rϕ 下的最优策略 π(a∣s),例如使用价值迭代方法 value iteration
- 计算 state visitation frequencies状态访问频率 p(s∣ϕ,T)
- 计算奖励模型的梯度
∇J(ϕ)=M1∑_τ_d∈Df_s−∑_sp(s∣ϕ,T)f_s
- 使用一个梯度步骤更新 ϕ
- 返回步骤3
- 以下算法的哪些步骤依赖于已知的动态模型?
- (1) 计算最优策略 T
- (2) 计算状态访问频率 T
- (3) 计算梯度 No
总结
- 最大熵方法具有巨大的影响力。
- 最初的公式化(Ziebart等人)使用线性奖励并假设动态模型是已知的。
- Finn等人于2016年(引导成本学习:通过策略优化进行深度逆向最优控制)展示了如何使用通用的奖励/成本函数并消除了对已知动态模型的需要。
模仿学习总结
- 模仿学习可以大大减少学习一个良好策略所需的数据量。
- 挑战依然存在,一个令人兴奋的领域是将逆向强化学习/从示例中学习与在线强化学习相结合。
- 若要了解模仿学习与强化学习之间的一些理论,请参考Sun, Venkatraman, Gordon, Boots, Bagnell在ICML 2017年的论文。
应该了解的内容:
- 定义行为克隆以及它与强化学习的区别。
- 理解最大熵原理、由此产生的轨迹分布,以及如何利用这些来学习奖励函数并拟合策略。


