专栏
简介
- YOLO物体检测实际上已经不太算是大模型的范畴,但因为是深度学习的领域,就放到一起说
- YOLO是一种流行的实时物体检测算法,由Joseph Redmon等人在2016年提出。它将物体检测视为回归问题,通过卷积神经网络直接从图像中预测物体的边界框和类别。YOLO将输入图像划分为多个网格,每个网格负责预测中心点落在该网格内的物体。其优点在于速度快,可实时检测,且能捕捉到图像的全局信息,减少假阳性检测。YOLO系列算法经过多个版本的改进,如YOLOv2引入的anchor boxes、YOLOv3的多尺度预测等,检测精度和效率不断提升。YOLO广泛应用于视频监控、自动驾驶、工业自动化等领域,展现出强大的泛化能力和实用性。
安装
conda create --name yolo python=3.10
conda activate yolo
- 下载yolo相关模型的时候网速比较慢这边使用多线程下载, x m l模型区别x最大l次之,m比较综合
aria2c -x 16 -s 16 https://github.com/ultralytics/assets/releases/download/v8.3.0/yolo11x.pt
可视化YOLO标注数据
pip install label-studio
label-studio start
- 记得注册,我比较习惯选下面标签去处理打标签
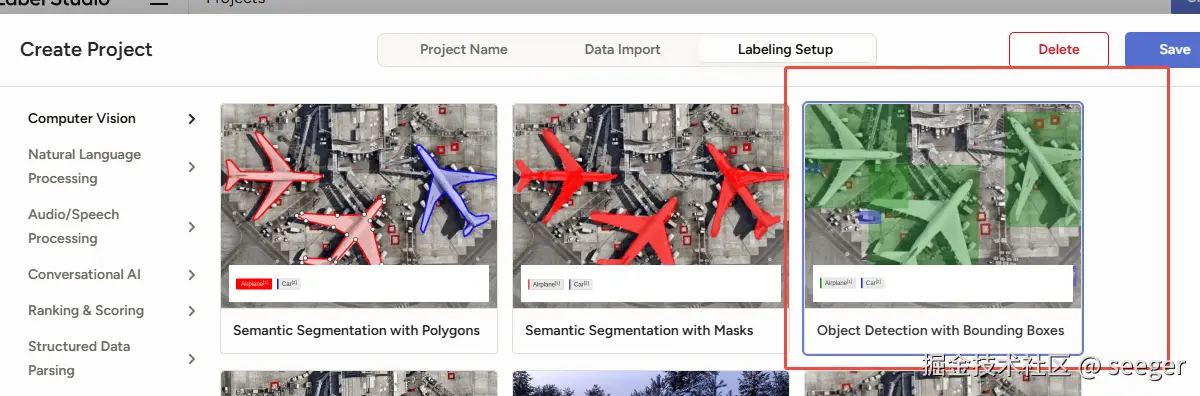
微调YOLO
- 使用label-studio标注需要微调的物体,然后导出
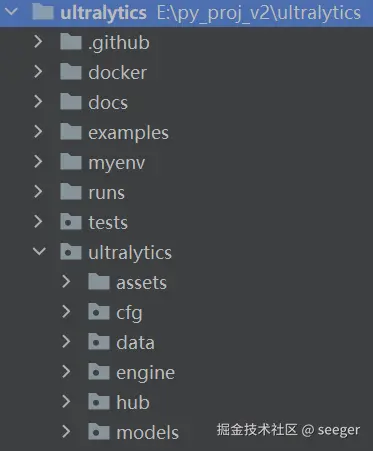
- 项目结构
- 先新增一个配置文件, classes里面的内容填你想要打标图像的类型
E:\py_proj_v2\ultralytics\ultralytics\cfg\models\11\auto-parts-det.yaml
train: E:/py_proj_v2/ultralytics/ultralytics/cfg/datasets/det_auto_parts_20250114/images/res
val: E:/py_proj_v2/ultralytics/ultralytics/cfg/datasets/det_auto_parts_20250114/images/res
names:
0: mailBox
1: repo
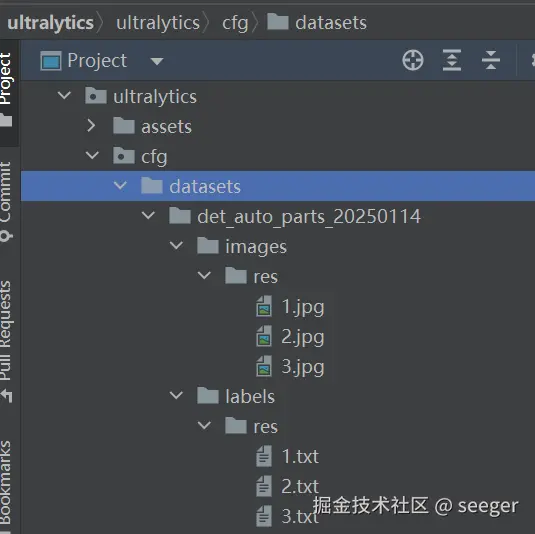
- 导出的数据合集放到下面目录,按照导出的格式,下面代码也可以改从中断位置训练,记得改模型地址
训练
from ultralytics import YOLO
model = YOLO("E:\py_proj_v2\ultralytics\runs\yolo11m.pt")
train_params = {
'data': "E:\py_proj_v2\ultralytics\ultralytics\cfg\models\11\auto-parts-det.yaml",
'epochs': 100,
'imgsz': 600,
'batch': 8,
'save': True,
'save_period': -1,
'cache': False,
'device': None,
'workers': 8,
'name': None,
'exist_ok': False,
'optimizer': 'auto',
'verbose': True,
'seed': 0,
'deterministic': True,
'single_cls': False,
'rect': False,
'cos_lr': False,
'close_mosaic': 10,
'resume': False,
'amp': True,
'fraction': 1.0,
'profile': False,
'freeze': None,
'lr0': 0.01,
'lrf': 0.01,
'momentum': 0.937,
'weight_decay': 0.0005,
'warmup_epochs': 3.0,
'warmup_momentum': 0.8,
'warmup_bias_lr': 0.1,
'box': 7.5,
'cls': 0.5,
'dfl': 1.5,
'pose': 12.0,
'kobj': 1.0,
'label_smoothing': 0.0,
'nbs': 64,
'overlap_mask': True,
'mask_ratio': 4,
'dropout': 0.0,
'val': True,
'plots': True,
'project': "runs/train",
'hsv_h': 0.2,
'hsv_s': 0.7,
'hsv_v': 0.4,
'degrees': 30.0,
'translate': 0.1,
'scale': 0.5,
'shear': 0.0,
'perspective': 0.0,
'flipud': 0.0,
'fliplr': 0.5,
'bgr': 0.0,
'mosaic': 0.5,
'mixup': 0.0,
'copy_paste': 0.0,
'copy_paste_mode': 'flip',
'auto_augment': 'randaugment',
'erasing': 0.4,
'crop_fraction': 1.0,
}
if __name__ == '__main__':
results = model.train(**train_params)
推理
- 是否有GPU速度差距非常大,best.pt是训练好的模型
from ultralytics import YOLO
import time
model = YOLO("E:\py_proj_v2\ultralytics\runs\best.pt")
if __name__ == '__main__':
start_time = time.time()
results = model.predict(
source=["E:\\predict\130.jpg", "E:\\predict\131.jpg"],
conf=0.45,
iou=0.6,
imgsz=640,
half=False,
device=None,
max_det=300,
vid_stride=1,
stream_buffer=False,
visualize=False,
augment=False,
agnostic_nms=False,
classes=None,
retina_masks=False,
embed=None,
show=False,
save=True,
save_frames=False,
save_txt=True,
save_conf=False,
save_crop=False,
show_labels=True,
show_conf=True,
show_boxes=True,
line_width=None
)
execution_time = time.time() - start_time
print(f"程序执行时间:{execution_time:.4f} 秒")
参考文章


