专栏
LlamaFactory介绍
- LlamaFactory 是一个专注于高效、灵活的大规模语言模型(LLM)微调和训练的开源平台。它旨在为开发者和研究人员提供一套强大的工具,帮助他们快速定制和优化语言模型,以满足特定任务和业务需求。LlamaFactory 支持多种主流预训练模型(如 LLaMA、GPT 等),并提供直观的界面和丰富的 API,使用户能够轻松完成数据预处理、模型微调、性能评估和部署等全流程操作。
- LlamaFactory 的核心优势在于其模块化设计和高度可扩展性。用户可以根据需求选择不同的训练策略、优化器和硬件加速方案,同时支持分布式训练,显著提升模型训练效率。此外,LlamaFactory 还集成了多种评估工具,帮助用户实时监控模型性能并进行调优。
- 无论是学术研究还是工业应用,LlamaFactory 都能为用户提供高效、可靠的解决方案,助力语言模型在自然语言处理、对话系统、内容生成等领域的广泛应用。通过 LlamaFactory,用户可以更专注于创新,而无需为复杂的底层实现分心。
LlamaFactory安装
sudo mkdir -p /root/.pip
sudo touch /root/.pip/pip.conf
然后vim /root/.pip/pip.conf
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
[install]
trusted-host=mirrors.aliyun.com
- 我的是Ubuntu 22.04, 使用conda安装
conda create -n llamaFactory python=3.10 -y
conda activate llamaFactory
cd /usr/local
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]"
nohup env CUDA_VISIBLE_DEVICES=0 llamafactory-cli webui > output.log 2>&1 &
LlamaFactory实践
lora
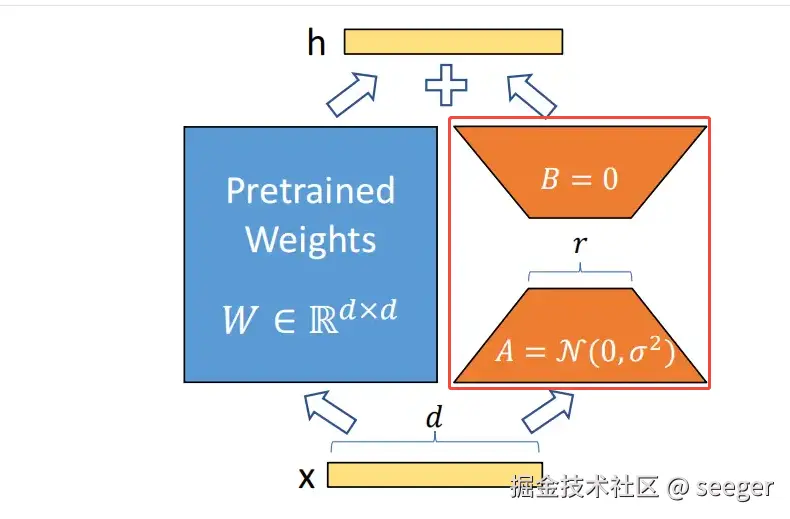
- 参数高效微调(Parameter-Efficient Fine-Tuning,简称PEFT)是一种针对大型预训练模型(如大语言模型)的微调技术,它旨在减少训练参数的数量,从而降低计算和存储成本,同时保持或提升模型性能。LoRA(Low-Rank Adaptation,低秩适应) 是 PEFT 的一种具体实现方法
- 本质上只是增加低秩矩阵
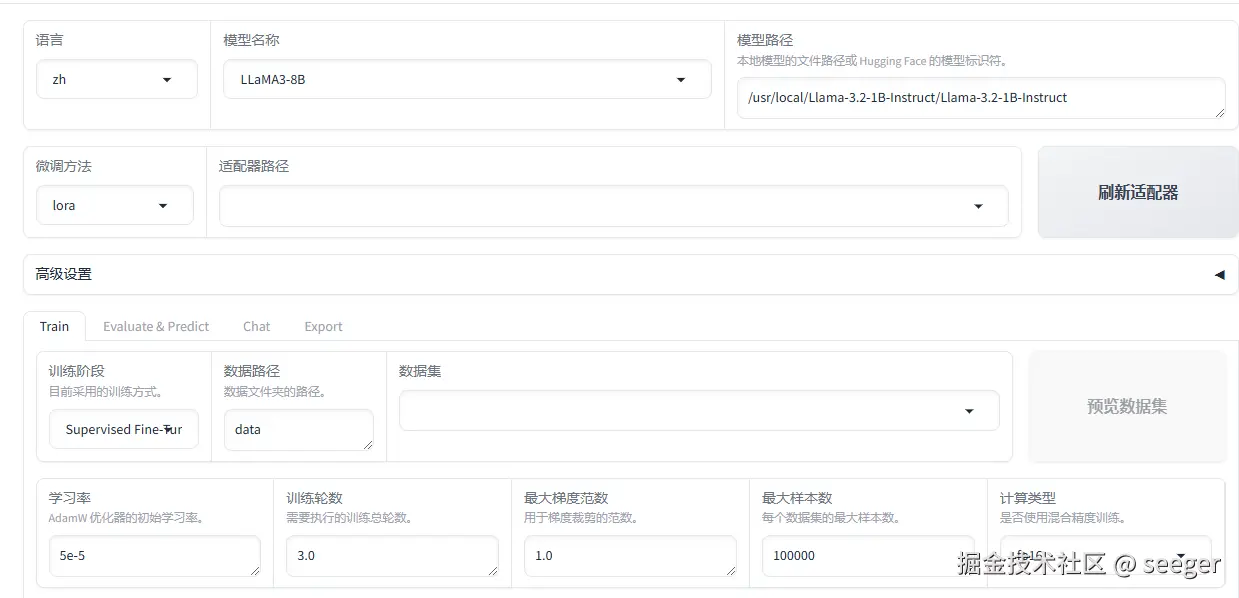
- 模型路径写自己下载的路劲,可以从魔塔社区下载,也可以执行下面命令
pip isntall modelscope
modelscope download --model LLM-Research/Llama-3.2-1B-Instruct --cache_dir /usr/local/Llama-3.2-1B-Instruct/
- 数据集,如果只是单个数据集快速验证,可以用偷懒的方式,打开你下载的LlamFactory目录执行下面命令,然后把alpaca_zh_demo.json替换成你自己的内容,这样界面上就能选择alpaca_zh_demo.json,展示的也是你自己的数据集合
cd /usr/local/src/LLaMA-Factory/data
cp alpaca_zh_demo.json alpaca_zh_demo.json.bak
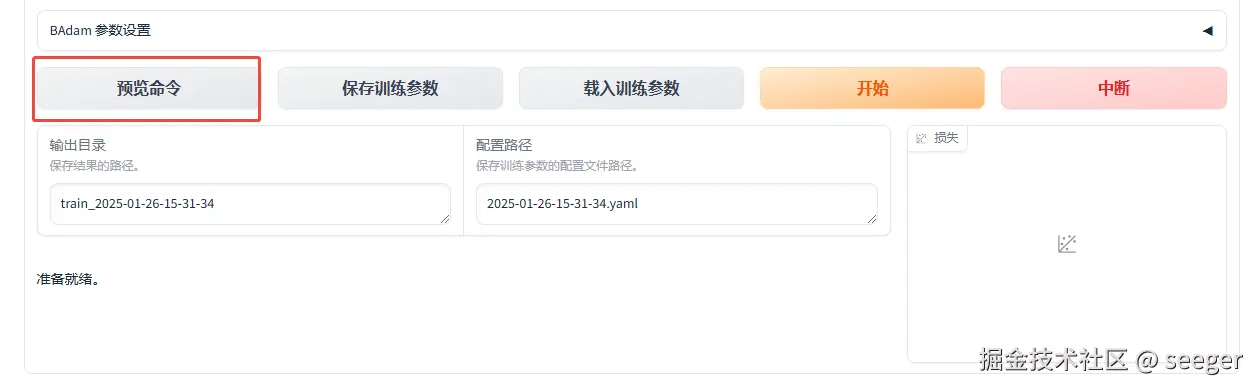
- 预览命令可以看实际lora微调执行的python命令,点击开始能看到每次迭代执行时loss
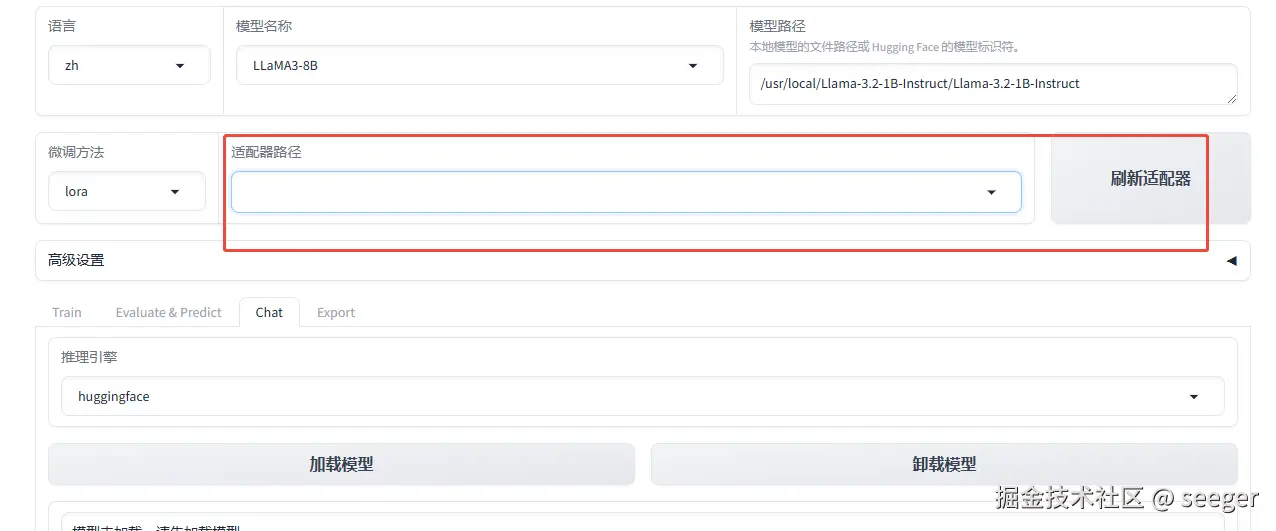
- 完成之后chat选择对应适配器之后可以试试微调后的效果
LlamaFactory集合DeepSpeed分布式多机多卡微调
真正执行train方法
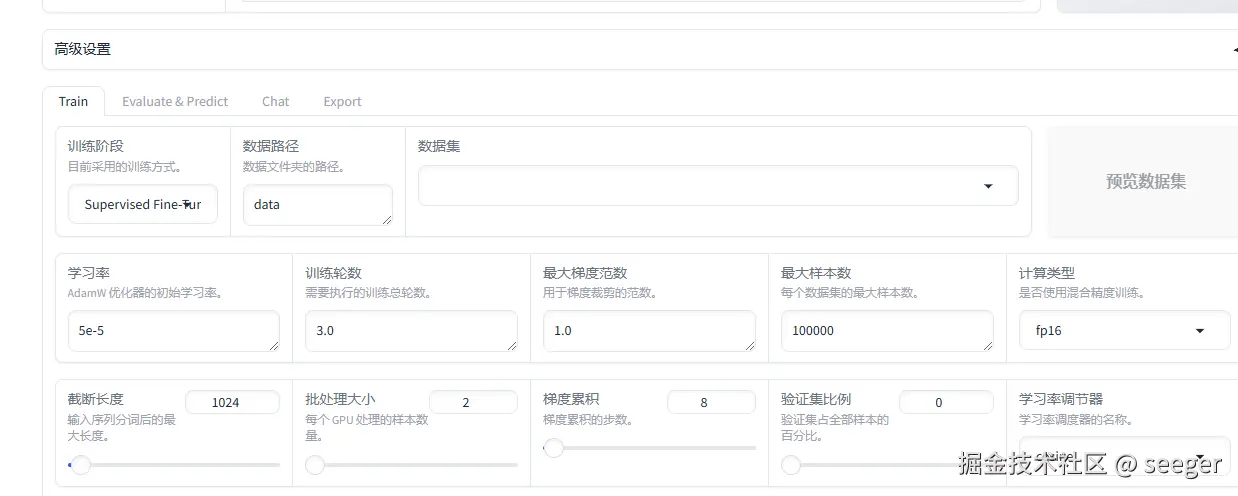
- LlamaFactory web界面配置好参数之后点击预览可以看到如下的train命令
llamafactory-cli train \
--stage sft \
--do_train True \
--model_name_or_path /usr/local/Llama-3.2-1B-Instruct \
--preprocessing_num_workers 16 \
--finetuning_type lora \
--template default \
--flash_attn auto \
--dataset_dir data \
--dataset mllm_demo \
--cutoff_len 1024 \
--learning_rate 5e-05 \
--num_train_epochs 3.0 \
--max_samples 100000 \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--optim adamw_torch \
--packing False \
--report_to none \
--output_dir saves/LLaMA3-8B/lora/train_2024-12-17-11-45-21 \
--fp16 True \
--plot_loss True \
--ddp_timeout 180000000 \
--include_num_input_tokens_seen True \
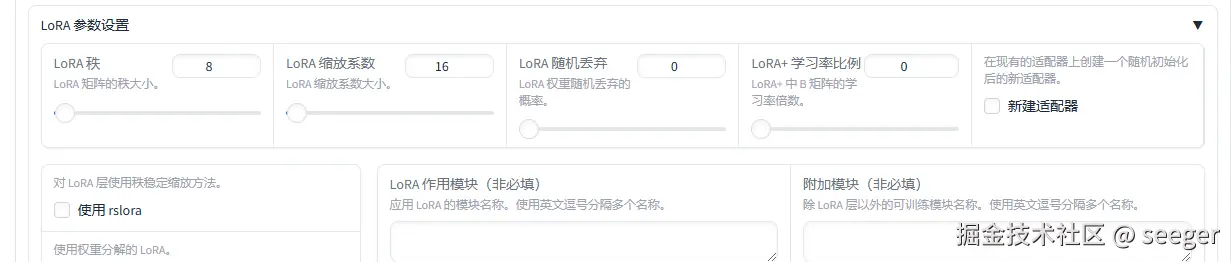
--lora_rank 8 \
--lora_alpha 16 \
--lora_dropout 0 \
--lora_target all
- 实际的批量大小 = batch_size * gradient_accumulation_steps
- 允许在多个小批次(mini-batches)上累积梯度,然后一次性更新模型参数,然增加了总体计算时间,但可以更有效地利用 GPU,特别是在处理大型模型时,如果显存有限,可以考虑调小这几个参数,当然微调的时间也要变更长
- max_grad_norm 限制梯度的最大范数(norm),确保梯度不会超过指定的阈值
- cosine 学习率调度器基于余弦函数来逐渐降低学习率,从初始学习率平滑地降低到非常小的值。
lr(t) = lr_min + 0.5 * (lr_max - lr_min) * (1 + cos(t * π / T))
- warmup_steps 在训练初期,学习率从一个很小的值开始,逐步增加到设定的最大值。 这个过程称为 "warmup"(预热)阶段
- self.dropout(x):首先对输入 x 应用 dropout。Dropout是一种正则化技术,随机"丢弃"一部分神经元,防止过拟合。在训练时随机置零一些元素,在推理时通常不应用。
多机多卡训练
- 可参考之前文章大模型私有化部署实践(三):使用DeepSpeed多机多卡训练
参考文章


