

残差网络 ResNet
今天学习了李沐深度学习pytorch版的残差网络相关的视频,重点内容总结如下:
ResNet简单理解
resnet的思想非常重要,简单来说呢就是有一个加法的计算在里面,如下图所示,输入x可以按照传统的串联的设计思路一步一步走下去,先经过卷积、BN层和ReLU激活函数等虚线框中的层,得到一个结果,该结果可以直接和跳转过来的输入x,进行相加操作,即思想类似于:
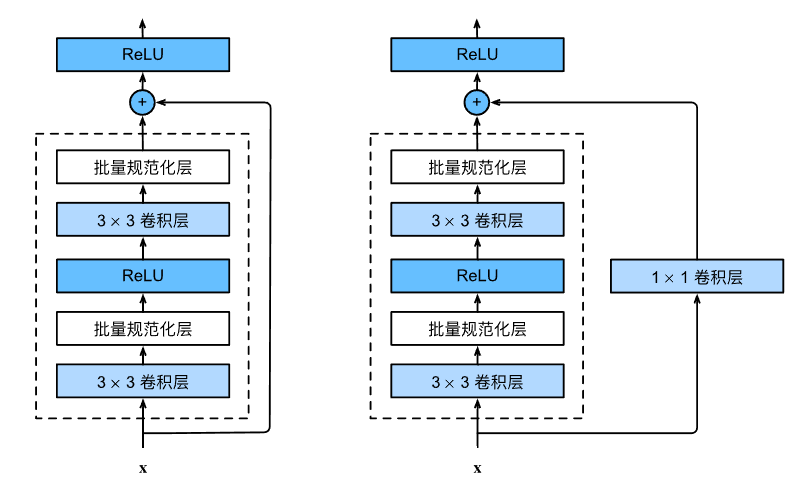
也就是图中“短路”那一条线,好似一条快捷通道一样。在该条通道上有的需要经过1x1卷积层,有的不需要,判断标准是虚线框内卷积层的参数设置,如果需要更改输入的通道数及宽高(一般是高宽减半,通道数加倍),那么就需要加上1x1的卷积层来对输入同样进行高宽和通道数的增减处理,这样到后面才能进行相加操作。
Resnet的核心代码及相关注释如下所示:
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
class Residual(nn.Module):
def __init__(self, input_channels, num_channels, use_1X1conv=False, strides=1):
super().__init__()
# 也就是说这里这个第一个卷积层的步幅stride可以设置 由传入参数设置 如果把他设置为2,那么高宽就会减半,同时可以设置成通道数加倍
self.conv1 = nn.Conv2d(input_channels, num_channels,
kernel_size=3, padding=1, stride=strides)
# 这里这个第二个卷积层就不设置步幅了 就采用默认值为1, 这个卷积层通道数不变 高宽也不变
self.conv2 = nn.Conv2d(num_channels, num_channels, kernel_size=3, padding=1)
if use_1X1conv:
# 对于1x1卷积而言 默认情况步幅为1padding为0时输出高宽与输入高宽相同
# 但padding=0, stride=2时,输出高宽会减半
# 如果输出的高宽比输入小,则是下采样 ;如果输出的高宽比输入大,则是上采样。
self.conv3 = nn.Conv2d(input_channels, num_channels, kernel_size=1, stride=strides)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
def forward(self, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X
return F.relu(Y)
blk3 = Residual(3, 3)
# 批量大小 通道数 高度 宽度
X = torch.rand(4, 3, 6, 6)
Y = blk3(X)
print(Y.shape)
blk2 = Residual(3, 6, use_1X1conv=True, strides=2)
print(blk2(X).shape)
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
def resnet_block(input_channels, num_channels, num_residuals,
first_block=False):
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(Residual(input_channels, num_channels,
use_1X1conv=True, strides=2))
else:
blk.append(Residual(num_channels, num_channels))
return blk
b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True))
b3 = nn.Sequential(*resnet_block(64, 128, 2))
b4 = nn.Sequential(*resnet_block(128, 256, 2))
b5 = nn.Sequential(*resnet_block(256, 512, 2))
net = nn.Sequential(b1, b2, b3, b4, b5,
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(),
nn.Linear(512, 10))
# print(net)
X = torch.rand(size=(1, 1, 224, 224))
for layer in net:
X = layer(X)
print(layer.__class__.__name__, "output shape:\t", X.shape)
lr, num_epochs, batch_size = 0.05, 10, 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
其中,网络结构如下:(print(net)即可)
Sequential(
(0): Sequential(
(0): Conv2d(1, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
)
(1): Sequential(
(0): Residual(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): Residual(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(2): Sequential(
(0): Residual(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv3): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): Residual(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(3): Sequential(
(0): Residual(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv3): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): Residual(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(4): Sequential(
(0): Residual(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv3): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2))
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): Residual(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(5): AdaptiveAvgPool2d(output_size=(1, 1))
(6): Flatten(start_dim=1, end_dim=-1)
(7): Linear(in_features=512, out_features=10, bias=True)
)
代码示例中的各层shape为:
Sequential output shape: torch.Size([1, 64, 56, 56])
Sequential output shape: torch.Size([1, 64, 56, 56])
Sequential output shape: torch.Size([1, 128, 28, 28])
Sequential output shape: torch.Size([1, 256, 14, 14])
Sequential output shape: torch.Size([1, 512, 7, 7])
AdaptiveAvgPool2d output shape: torch.Size([1, 512, 1, 1])
Flatten output shape: torch.Size([1, 512])
Linear output shape: torch.Size([1, 10])
ResNet如何处理梯度消散
核心在于用了加法,计算底层(靠近数据层)的权重参数的梯度的时候,由于梯度计算的链式法则,从顶至底一步一步计算而来的梯度需要相乘计算,如果有一个很小的数来相乘,就会导致整个计算结果变得非常小,导致梯度消散,而ResNet的加法思想缓解了这一问题,虽然从顶至底一步一步计算而来的梯度还是有可能很小,但是没关系,这只是加法中的一方,而另外一方是由顶部可以沿着“短路”线直接跳转计算到底部,这部分的梯度是相对来说比较大的,因此底层的参数也比较好的更新,缓解了梯度消散的问题,这也是为什么ResNet可以训练出1000层模型的原因。
