

前言
目前语音交互主要的实现大体有两种:
- 级联方案,指的是,大规模语言模型 (LLM)、文本转语音 (TTS) 和语音转文本 (STT),客户的话通过vad断句到STT的语音转文本,经过大模型进行生成文本,生成文本后通过TTS进行回复给用户。(主流方案)
- 端到端的方案,开发者无需再组合多个模型来实现语音助手功能,而是可以通过单一 API 调用来处理整个过程,从语音识别到文本推理,再到语音合成。这种集成方法不仅提高了效率,还保留了情感、重音和口音等细节,大大增强了用户体验。(openai realtime)
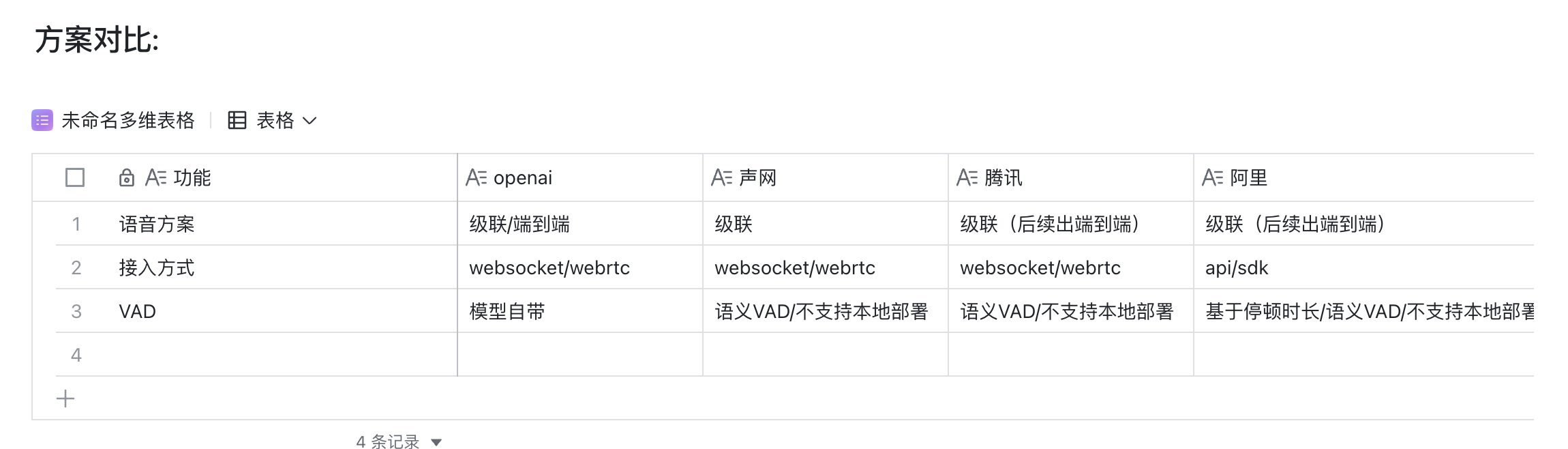
方案对比:
暂时无法在飞书文档外展示此内容
国内目前:没有realtime端到端的方案,据了解都在25年的时候会进行发布
openai:
Realtime API with WebRTC(适用于客户端应用程序)
Realtime API with WebSockets (适用于服务端到服务端应用程序)
声网RTC:
声网本身不做大模型,但是为了使大模型在语音领域的使用,采用级联方案,这样普通大模型也能够应用到语音领域
声网认为延迟很重要,所以在延迟上下了很多功夫,这种考虑是C端的用户,用户的语音输入可能使用5g和wifl进行传输,所以延迟不稳定。
但是对于呼叫中心的场景,客户一般使用pstn,依赖手机运营商信号,比网络稳定,我们不需要考虑网络稳定这一因素
声网的指标:
一般来说,延迟在 1.7 秒内会让人感觉自然,2 秒多、 3 秒则会让人觉得卡顿、反应慢。
大模型这里的耗时是流式的
声网demo
convoai-preview.shengwang.cn/

腾讯TRTC
腾讯的实现大体都和声网一样
体验demo:rtcube.cloud.tencent.com/component/e…
思考:为什么大厂的选择背道而驰
为什么国内这些大厂在知道有端到端的方案的时候,还要在级联方案呢?
主要有以下几个原因
- 端到端的方案影响了大模型的推理能力
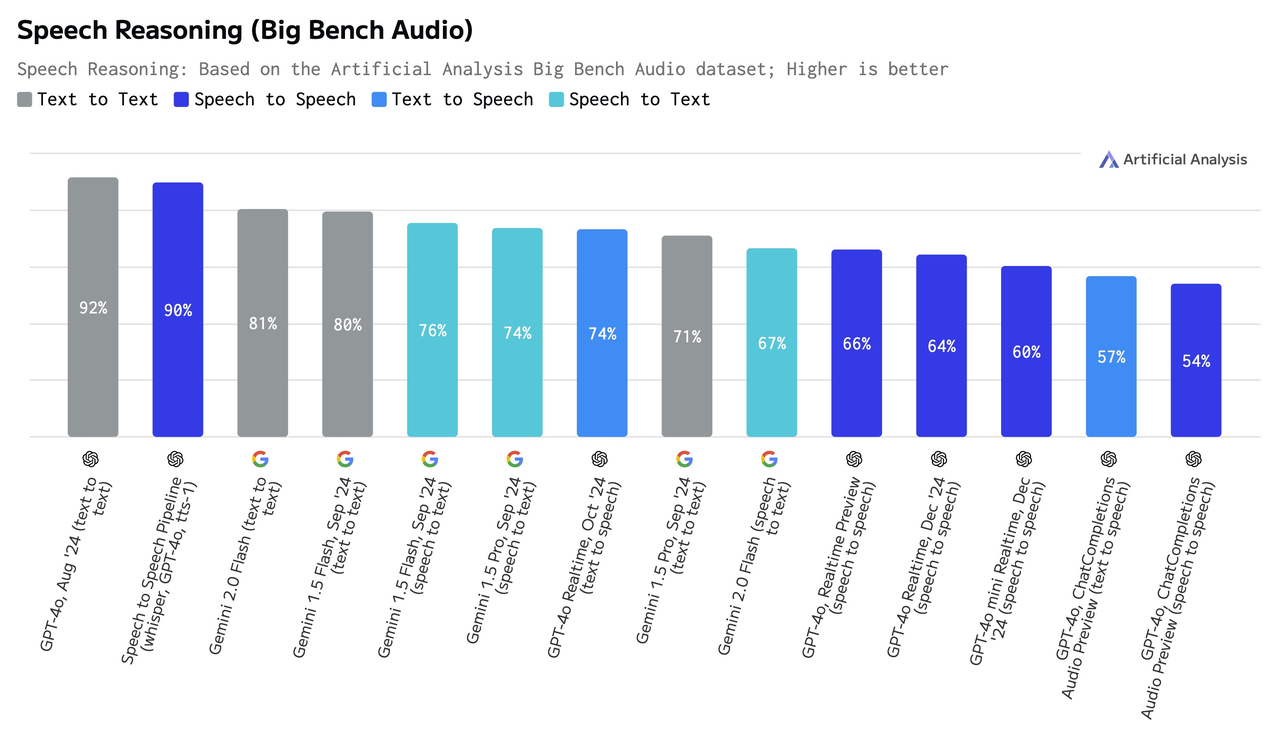
GPT-4o 在数据集的纯文本版本上实现了 92% 的准确率,但其语音到语音的性能下降至 66%。
2.语音转文本需要人工标注,耗时且昂贵,而文本数据相对容易获取和标注。
3.模型训练复杂 语音训练要求更大的模型和更多的计算资源。
综上所述:
端到端的方案的技术应用普及,仍需要一段时间,目前级联就是最好的选择
语音打断
- VAD技术:根据说话的停顿时间进行打断,对环境要求比较苛刻,单多人或者嘈杂环境体验极差
- 指令词打断,说特点的打断话术,在进行打断,不自然,不优雅
- 基于语义进行打断
- 开源方案:x.com/livekit/sta…
本文使用 文章同步助手 同步
