

创作不易,方便的话点点关注,谢谢
文章结尾有最新热度的文章,感兴趣的可以去看看。
本文是经过严格查阅相关权威文献和资料,形成的专业的可靠的内容。全文数据都有据可依,可回溯。特别申明:数据和资料已获得授权。本文内容,不涉及任何偏颇观点,用中立态度客观事实描述事情本身
文章有点长(14000字阅读时长:25分),期望您能坚持看完,并有所收获。
编码自己的十亿参数 LLM
LLaMA 3 是继 Mistral 之后最有前途的开源模型之一,可以解决各种任务。下面介绍如何利用 LLaMA 架构从零开始创建一个拥有 230 多万个参数的 LLM。现在 LLaMA-3 发布了,我们将以更简单的方式重新创建它。
在本文章中,我们不会使用 GPU,但您需要至少 17 GB 的内存,因为我们将加载一些超过 15 GB 的文件。如果这对你来说是个问题,你可以使用 Kaggle 作为解决方案。由于我们不需要 GPU,Kaggle 可提供 30 GB 内存,同时只使用 CPU 内核作为加速器。
预备知识
我们不会使用面向对象编程(OOP)编码,只是普通的 Python 编程。不过,您应该对神经网络和 Transformer 架构有基本的了解。这是学习本文章仅需的两个先决条件。
LLaMA 2 与 LLaMA 3 的区别
在了解技术细节之前,您必须知道的第一件事是 LLaMA 3 的整个架构与 LLaMA 2 相同。因此,如果您还没有了解过 LLaMA 3 的技术细节。即使您不了解 LLaMA 2 的架构,也不用担心,我们也会对其技术细节进行高层次的概述。 下面是有关 LLaMA 2 和 LLaMA 3 的一些要点:
| FEATURE
|
Llama 3
|
Llama 2
| | --- | --- | --- | |
Tokenizer
|
Tiktoken (developed by OpenAI)
|
SentencePiece
| |
Number of Parameters
|
8B, 70B
|
70B, 13B, 7B
| |
Training Data
|
15T tokens
|
2.2T tokens
| |
Context Length
|
8192 tokens
|
4096 tokens
| |
Attention Mechanism
|
Grouped-query attention
|
Grouped-query attention
| |
Fine-Tuned Models
|
Yes
|
Yes
| |
Performance
|
Better than Llama 2 on all benchmarks
|
Better than Llama 1 on most benchmarks
| |
Computational Requirements
|
Very high (70B model)
|
Very high (70B model)
| |
Availability
|
Open source
|
Open source
| |
Reinforcement learning from human feedback
|
Yes
|
Yes
| |
Number of languages supported
|
30 languages
|
20 languages
| |
Suitable for
|
Best for more demanding tasks, such as reasoning, coding, and proficiency tests
|
Good for more demanding tasks, such as reasoning, coding, and proficiency tests
|
了解 LLaMA 3 的Transformer架构
在开始编码之前,了解 LLaMA 3 的架构非常重要。为了更直观地理解,下面是 Vanilla Transformer、LLaMA 2/3 和 Mistral 之间的对比图。
1.使用 RMSNorm 进行预归一化:
在与 LLaMA 2 相同的 LLaMA 3 方法中,一种名为 RMSNorm 的技术被用于对每个变压器子层的输入进行归一化处理。
想象一下,你正在为一场大型考试而复习,而你有一本篇幅很长的教科书,里面有很多章节。每一章都代表不同的主题,但有些章节对理解主题比其他章节更重要。
现在,在深入学习整本教科书之前,您决定评估每一章的重要性。你不想在每一章上都花同样多的时间;你想把更多的精力放在关键的章节上。
这就是使用 RMSNorm 对大型语言模型(LLM)(如 ChatGPT)进行预规范化的作用所在。这就好比根据每个章节的重要性为其分配权重。对主题至关重要的章节权重较高,而不太重要的章节权重较低。
因此,在深入学习之前,您要根据各章节的加权重要性调整学习计划。你要在权重较高的章节上分配更多的时间和精力,确保彻底掌握核心概念。
同样,使用 RMSNorm 进行预规范化可以帮助 LLM 优先考虑文本中哪些部分对于理解上下文和含义更为重要。它为重要的元素分配较高的权重,为不太重要的元素分配较低的权重,确保模型将注意力集中在准确理解最需要的地方。感兴趣的读者可以点击这里查看 RMSNorm 的详细实现过程。
2.SwiGLU 激活功能:
LLaMA 从 PaLM 中汲取灵感,引入了 SwiGLU 激活函数。
想象一下,你是一名教师,正试图向学生解释一个复杂的话题。你有一块大白板,你在上面写下要点并画出图表,让事情变得更清楚。但有时,你的字迹可能不太工整,或者你的图表可能画得不够完美。这会增加学生理解教材的难度。
现在,想象一下,如果你有一支神奇的笔,它能根据每个要点的重要性自动调整笔迹的大小和风格。如果某一点非常重要,这支笔就会把它写得更大更清晰,让它显得更加突出。如果不那么重要,这支笔就会把它写得小一些,但仍然清晰可辨。
SwiGLU 就像是 ChatGPT 等大型语言模型 (LLM) 的魔法笔。在生成文本之前,SwiGLU 会根据每个单词或短语与上下文的相关性来调整其重要性。就像魔术笔会调整书写的大小和风格一样,SwiGLU 也会调整每个单词或短语的重点。
这样,当法律硕士生成文本时,就可以更加突出重要部分,使其更加引人注目,并确保它们更有助于对文本的整体理解。这样,SwiGLU 就能帮助 LLM 生成更清晰、更易懂的文本,就像魔术笔能帮助你在白板上为学生创建更清晰的解释一样。有关 SwiGLU 的更多详情,请参阅相关论文。
3. Rotary Embeddings (RoPE):
旋转嵌入或绳索是LLaMA 3中使用的一种位置嵌入。
想象一下,你在一间教室里,想给学生分配座位进行小组讨论。通常情况下,你可能会按行和列来安排座位,每个学生都有一个固定的位置。但是,在某些情况下,你希望创建一个更动态的座位安排,让学生可以更自由地走动和互动。
ROPE 就像一种特殊的座位安排,允许学生旋转和变换位置,同时仍能保持彼此之间的相对位置。学生不再被固定在一个地方,而是可以做圆周运动,从而实现更流畅的互动。
在这种情况下,每个学生代表文本序列中的一个单词或标记,他们的位置与他们在序列中的位置相对应。正如 ROPE 允许学生旋转和改变位置一样,ROPE 允许文本序列中单词的位置嵌入根据它们之间的相对位置动态改变。
因此,在处理文本时,ROPE 不再将位置嵌入视为固定和静态的,而是引入了旋转方面,从而允许更灵活的表示,捕捉序列中单词之间的动态关系。这种灵活性有助于像 ChatGPT 这样的模型更好地理解和生成自然流畅并保持连贯性的文本,就像动态座位安排在课堂上促进互动讨论一样。对数学细节感兴趣的人可以参阅 RoPE 论文。
4.字节对编码(BPE)算法
LLaMA 3 使用 OpenAI 推出的 tiktoken 库中的字节对编码(BPE),而 LLaMA 2 标记符号生成器 BPE 则基于 sentencepiece 库。它们之间存在细微差别,但首先让我们了解一下 BPE 究竟是什么。
让我们从一个简单的例子开始。假设我们有一个包含单词的文本语料库:"ab"、"bc"、"bcd "和 "cde"。我们首先用文本语料库中的所有单个字符初始化我们的词汇表,因此我们的初始词汇表是 {"a"、"b"、"c"、"d"、"e"}。
接下来,我们计算每个字符在文本语料库中的出现频率。在我们的例子中,频率为{"a":1, "b":3, "c":3, "d":2, "e":1}.
现在,我们开始合并过程。我们重复以下步骤,直到我们的词汇量达到所需的大小: 首先,我们找出频率最高的一对连续字符。在本例中,频率最高的字符对是 "bc",频率为 2。然后,我们合并这对字符,创建一个新的子词单位 "bc"。合并后,我们更新频率计数,以反映新的子词单位。更新后的频率为{"a":1, "b":2, "c": 2, "d":2, "e":1, "bc": 2}。我们将新的子词单位 "bc "添加到我们的词汇表中,现在词汇表变为 {"a"、"b"、"c"、"d"、"e"、"bc"}。
我们重复这一过程。下一个出现频率最高的词对是 "cd"。我们将 "cd "合并成一个新的子词单元 "cd",并更新频率计数。更新后的频率为 {"a":1, "b":2, "c":1, "d":1, "e":1, "bc": 2, "cd":2}.我们将 "cd "添加到词汇表中,结果是{"a"、"b"、"c"、"d"、"e"、"bc"、"cd"}。
接着,下一个词频对是 "de"。我们将 "de "合并为子词单元 "de",并将频率计数更新为 {"a":1, "b":2, "c":1, "d":1, "e":0, "bc": 2, "cd":1, "de":1}.我们将 "de "添加到词汇表中,这样词汇表就变成了 {"a"、"b"、"c"、"d"、"e"、"bc"、"cd"、"de"}。
接下来,我们发现 "ab "是频率最高的词对。我们将 "ab "合并为子词单元 "ab",并将频率计数更新为{"a":0, "b":1, "c":1, "d":1, "e":0, "bc": 2, "cd":1、"de":1, "ab":1}.我们将 "ab "添加到词汇表中,词汇表就变成了{"a"、"b"、"c"、"d"、"e"、"bc"、"cd"、"de"、"ab"}。
然后,下一个频繁词对是 "bcd"。我们将 "bcd "合并为子词单元 "bcd",并将频率计数更新为 {"a":0, "b":0, "c":0, "d":0, "e":0, "bc":1, "cd":0、"de":1, "ab":1, "bcd":1}.我们将 "bcd "添加到词汇表中,结果是{"a"、"b"、"c"、"d"、"e"、"bc"、"cd"、"de"、"ab"、"bcd"}。
最后,出现频率最高的词对是 "cde"。我们将 "cde "合并为子词单元 "cde",并将频率计数更新为{"a":0, "b":0, "c":0, "d":0, "e":0, "bc":1, "cd":0、"de":0、"ab":1、"bcd":1, "cde":1}.我们将 "cde "添加到词汇表中,这样词汇表就变成了{"a"、"b"、"c"、"d"、"e"、"bc"、"cd"、"de"、"ab"、"bcd"、"cde"}。
这种技术可以提高 LLM 的性能,并处理罕见词和词汇量不足的词。TikToken BPE 与句子片段 BPE 的最大区别在于,如果整个单词已经为人所知,TikToken BPE 并不总是将单词分割成更小的部分。例如,如果词汇中有 "hugging"(拥抱),它就会保持为一个标记,而不会拆分成["hug", "ging"]。
做准备
我们将使用少量 Python 库,但最好还是先安装这些库,以免遇到 "找不到模块 "的错误。
pip install sentencepiece tiktoken torch blobfile matplotlib huggingface_hub
安装完所需库后,我们需要下载一些文件。由于我们要复制 llama-3-8B 的架构,因此您必须拥有 HuggingFace 的账户。此外,由于 llama-3 是一个封闭模型,您必须接受他们的条款和条件才能访问模型内容。 步骤如下:
通过此链接创建 HuggingFace 账户(https://huggingface.co/welcome)
从该链接接受 llama-3-8B 的条款和条件(https://huggingface.co/meta-llama/Meta-Llama-3-8B)
完成这两个步骤后,现在我们要下载一些文件。有两种方法可供选择: (选项 1:手动)从此链接进入 llama-3-8B HF 目录,手动下载这三个文件。
(选项 2:编码)我们可以使用之前安装的 hugging_face 库下载所有这些文件。不过,首先我们需要在工作笔记本中使用 HF 令牌登录 HuggingFace Hub。您可以创建一个新令牌,或通过此链接访问。
# Import the `notebook_login` function from the `huggingface_hub` module.
from huggingface_hub import notebook_login
# Execute the `notebook_login` function to log in to the Hugging Face Hub.
notebook_login()
运行该单元后,系统会要求您输入令牌。如果登录过程中出现错误,请重试,但一定要取消选中添加令牌作为 git 凭证。之后,我们只需运行一段简单的 Python 代码,下载 llama-3-8B 架构的三个主要文件。
# Import the necessary function from the huggingface_hub library
from huggingface_hub import hf_hub_download
# Define the repository information
repo_id ="meta-llama/Meta-Llama-3-8B"
subfolder ="original"# Specify the subfolder within the repository
# List of filenames to download
filenames =["params.json","tokenizer.model","consolidated.00.pth"]
# Specify the directory where you want to save the downloaded files
save_directory ="llama-3-8B/"# Replace with your desired path
# Download each file
for filename in filenames:
hf_hub_download(
repo_id=repo_id,# Repository ID
filename=filename,# Name of the file to download
subfolder=subfolder,# Subfolder within the repository
local_dir=save_directory # Directory to save the downloaded file
)
下载完所有文件后,我们需要导入本文章中将要使用的库。
# Tokenization library
import tiktoken
# BPE loading function
from tiktoken.load import load_tiktoken_bpe
# PyTorch library
import torch
# JSON handling
import json
接下来,我们需要了解每个文件的用途。
了解文件结构
由于我们的目标是精确复制 llama-3,这意味着我们的输入文本必须产生有意义的输出。例如,如果我们的输入是 "太阳的颜色是?",输出就必须是 "白色"。要做到这一点,需要在大型数据集上训练我们的 LLM,这对计算能力的要求很高,对我们来说是不可行的。
不过,Meta 已经公开发布了他们的 llama-3 架构文件,或者用更复杂的术语来说,他们的预训练权重,以供使用。我们刚刚下载了这些文件,这样我们就可以复制他们的架构,而不需要训练或大型数据集。一切都已准备就绪,我们只需在正确的地方使用正确的组件。
来看看这些文件及其重要性: tokenizer.model - 正如我们之前讨论过的,LLaMA-3 使用的是 tiktoken 的字节对编码(BPE)标记符,它是在一个包含 15 万亿个标记的数据集上训练出来的,比 LLaMA-2 使用的数据集大 7 倍。让我们加载这个文件,看看它有什么。
# Loading the tokenizer from llama-3-8B
tokenizer_model = load_tiktoken_bpe("tokenizer.model")
# Get the length of the tokenizer model
len(tokenizer_model)
# OUTPUT: 128000
# Get the type of the `tokenizer_model` object.
type(tokenizer_model)
# OUTPUT: dictionary
length 属性显示总词汇量,即训练数据中唯一的字符数。tokenizer_model 的类型是字典。
# Printing the first 10 items of tokenizer model
dict(list(tokenizer_model.items())[5600:5610])
#### OUTPUT ####
{
b'mitted':5600,
b" $('#":5601,
b' saw':5602,
b' approach':5603,
b'ICE':5604,
b' saying':5605,
b' anyone':5606,
b'meta':5607,
b'SD':5608,
b' song':5609
}
#### OUTPUT ####
当我们从中打印 10 个随机项时,你会看到使用 BPE 算法形成的字符串,与我们之前讨论的示例类似。键代表来自 BPE 训练的字节序列,而值则代表基于频率的合并等级。
consolidated.00.pth - 包含 Llama-3-8B 的学习参数(权重)。这些参数包括有关模型如何理解和处理语言的信息,例如如何表示词块、计算注意力、执行前馈转换以及对输出进行归一化。
# Loading a PyTorch model of LLaMA-3-8B
model = torch.load("consolidated.00.pth")
# printing first 11 layers of the architecture
list(model.keys())[:11]
#### OUTPUT ####
[
'tok_embeddings.weight',
'layers.0.attention.wq.weight',
'layers.0.attention.wk.weight',
'layers.0.attention.wv.weight',
'layers.0.attention.wo.weight',
'layers.0.feed_forward.w1.weight',
'layers.0.feed_forward.w3.weight',
'layers.0.feed_forward.w2.weight',
'layers.0.attention_norm.weight',
'layers.0.ffn_norm.weight',
'layers.1.attention.wq.weight',
]
#### OUTPUT ####
如果你熟悉变换器架构,就会知道查询、关键矩阵等。稍后,我们将在 Llama-3 的架构中使用这些层/权重来创建此类矩阵。 params.json- 包含各种参数值,例如
# Opening the parameters JSON file
withopen("params.json","r")as f:
config = json.load(f)
# Printing the content
print(config)
#### OUTPUT ####
{
'dim':4096,
'n_layers':32,
'n_heads':32,
'n_kv_heads':8,
'vocab_size':128256,
'multiple_of':1024,
'ffn_dim_multiplier':1.3,
'norm_eps':1e-05,
'rope_theta':500000.0
}
#### OUTPUT ####
这些值将帮助我们复制 Llama-3 架构,指定头的数量、嵌入向量的维度等细节。 让我们存储这些值,以便以后使用。
# Dimension
dim = config["dim"]
# Layers
n_layers = config["n_layers"]
# Heads
n_heads = config["n_heads"]
# KV_heads
n_kv_heads = config["n_kv_heads"]
# Vocabulary
vocab_size = config["vocab_size"]
# Multiple
multiple_of = config["multiple_of"]
# Multiplier
ffn_dim_multiplier = config["ffn_dim_multiplier"]
# Epsilon
norm_eps = config["norm_eps"]
# RoPE
rope_theta = torch.tensor(config["rope_theta"])
对输入数据进行标记 我们需要做的第一件事就是将输入文本转换为标记符,为此,我们首先需要创建一些特殊标记符,以便在标记化文本中提供结构化标记,使标记化器能够识别和处理特定条件或指令。
special_tokens = [
"<|begin_of_text|>",# Marks the beginning of a text sequence.
"<|end_of_text|>",# Marks the end of a text sequence.
"<|reserved_special_token_0|>",# Reserved for future use.
"<|reserved_special_token_1|>",# Reserved for future use.
"<|reserved_special_token_2|>",# Reserved for future use.
"<|reserved_special_token_3|>",# Reserved for future use.
"<|start_header_id|>",# Indicates the start of a header ID.
"<|end_header_id|>",# Indicates the end of a header ID.
"<|reserved_special_token_4|>",# Reserved for future use.
"<|eot_id|>",# Marks the end of a turn (in a conversational context).
]+[f"<|reserved_special_token_{i}|>"for i inrange(5,256-5)] # A large set of tokens reserved for future use.
接下来,我们通过指定不同的模式来匹配输入文本中的各类子串,从而定义将文本分割成标记的规则。我们可以这样做
# patterns based on which text will be break into tokens
tokenize_breaker = r"(?i:'s|'t|'re|'ve|'m|'ll|'d)|[^\r\n\p{L}\p{N}]?\p{L}+|\p{N}{1,3}| ?[^\s\p{L}\p{N}]+[\r\n]*|\s*[\r\n]+|\s+(?!\S)|\s+"
它可以从输入文本中提取单词、缩略语、数字(最多三位)和非空格字符序列,你还可以根据自己的要求进行定制。
我们需要使用 TikToken BPE 编写一个简单的标记化函数,它需要三个输入:tokenizer_model、tokenize_breaker 和 special_tokens。该函数将对输入文本进行相应的编码/解码。
# Initialize tokenizer with specified parameters
tokenizer = tiktoken.Encoding(
# make sure to set path to tokenizer.model file
name ="tokenizer.model",
# Define tokenization pattern string
pat_str = tokenize_breaker,
# Assign BPE mergeable ranks from tokenizer_model of LLaMA-3
mergeable_ranks = tokenizer_model,
# Set special tokens with indices
special_tokens={token:len(tokenizer_model)+ i for i, token inenumerate(special_tokens)},
)
# Encode "hello world!" and decode tokens to string
tokenizer.decode(tokenizer.encode("hello world!"))
#### OUTPUT ####
hello world!
#### OUTPUT ####
为了验证我们的编码器函数方法是否正常工作,我们将 "Hello World "传递给它。首先,它对文本进行编码,将其转换为数值。然后,解码回文本,得到 "hello world!"。这证明函数工作正常。让我们对输入进行标记化。
# input prompt
prompt ="the answer to the ultimate question of life, the universe, and everything is "
# Encode the prompt using the tokenizer and prepend a special token (128000)
tokens =[128000]+ tokenizer.encode(prompt)
print(tokens)# Print the encoded tokens
# Convert the list of tokens into a PyTorch tensor
tokens = torch.tensor(tokens)
# Decode each token back into its corresponding string
prompt_split_as_tokens =[tokenizer.decode([token.item()])for token in tokens]
print(prompt_split_as_tokens)# Print the decoded tokens
#### OUTPUT ####
[128000,1820,4320,311,...]
['<|begin_of_text|>','the',' answer',' to',...]
#### OUTPUT ####
我们对输入文本 "生命、宇宙和万物终极问题的答案是 "进行了编码,以一个特殊标记开始。
为每个令牌创建嵌入
如果我们检查输入矢量的长度,结果会是
# checking dimension of input vector
len(tokens)
#### OUTPUT ####
17
#### OUTPUT ####
checking dimension of embedding vector from llama-3 architecture
print(dim)
OUTPUT
4096
OUTPUT
我们的输入向量目前的维数为 (17x1),需要转换为每个标记词的嵌入。这意味着我们的 (17x1) 标记将变为 (17x4096),其中每个标记都有一个长度为 4096 的相应嵌入。
Define embedding layer with vocab size and embedding dimension
embedding_layer = torch.nn.Embedding(vocab_size, dim)
Copy pre-trained token embeddings to the embedding layer
embedding_layer.weight.data.copy_(model["tok_embeddings.weight"])
Get token embeddings for given tokens, converting to torch.bfloat16 format
token_embeddings_unnormalized = embedding_layer(tokens).to(torch.bfloat16)
Print shape of resulting token embeddings
token_embeddings_unnormalized.shape
OUTPUT
torch.Size([17,4096])
OUTPUT
这些嵌入没有进行归一化处理,如果我们不对其进行归一化处理,将会产生严重影响。下一节,我们将对输入向量进行归一化处理。
使用 RMSNorm 进行归一化
================
我们将使用前面提到的 RMSNorm 公式对输入向量进行归一化处理,以确保输入已归一化。
Calculating RMSNorm
defrms_norm(tensor, norm_weights):
Calculate the mean of the square of tensor values along the last dimension
squared_mean = tensor.pow(2).mean(-1, keepdim=True)
Add a small value to avoid division by zero
normalized = torch.rsqrt(squared_mean + norm_eps)
Multiply normalized tensor by the provided normalization weights
return(tensor * normalized)* norm_weights
我们将使用第 0 层的注意力权重对未归一化的嵌入进行归一化处理。使用第 0 层的原因是,我们正在创建 LLaMA-3 转换器架构的第一层。
using RMS normalization and provided normalization weights
token_embeddings = rms_norm(token_embeddings_unnormalized, model["layers.0.attention_norm.weight"])
Print the shape of the resulting token embeddings
token_embeddings.shape
OUTPUT
torch.Size([17, 4096])
OUTPUT
您可能已经知道,维数不会改变,因为我们只是对向量进行归一化处理,而不是其他。
注意头(查询、关键字、值)
=============
首先,让我们从模型中加载查询、键、值和输出向量。
Print the shapes of different weights
print(
Query weight shape
model["layers.0.attention.wq.weight"].shape,
Key weight shape
model["layers.0.attention.wk.weight"].shape,
Value weight shape
model["layers.0.attention.wv.weight"].shape,
Output weight shape
model["layers.0.attention.wo.weight"].shape )
OUTPUT
torch.Size([4096,4096])# Query weight dimension torch.Size([1024,4096])# Key weight dimension torch.Size([1024,4096])# Value weight dimension torch.Size([4096,4096])# Output weight dimension
OUTPUT
这些维度表明,我们下载的模型权重并不是针对每个头部的,而是针对多个注意力头部的,这是因为我们采用了并行方法/训练。不过,我们可以解开这些矩阵,使其仅适用于单个注意头。
Retrieve query weight for the first layer of attention
q_layer0 = model["layers.0.attention.wq.weight"]
Calculate dimension per head
head_dim = q_layer0.shape[0]// n_heads
Reshape query weight to separate heads
q_layer0 = q_layer0.view(n_heads, head_dim, dim)
Print the shape of the reshaped query weight tensor
q_layer0.shape
OUTPUT
torch.Size([32,128,4096])
OUTPUT
这里,32 是 Llama-3 中的注意力头数,128 是查询向量的大小,4096 是标记嵌入的大小。我们可以通过以下方法访问第一层第一个头部的查询权重矩阵:
Extract the query weight for the first head of the first layer of attention
q_layer0_head0 = q_layer0[0]
Print the shape of the extracted query weight tensor for the first head
q_layer0_head0.shape
OUTPUT
torch.Size([128, 4096])
OUTPUT
为了找到每个标记的查询向量,我们将查询权重与标记嵌入相乘。
Matrix multiplication: token embeddings with transpose of query weight for first head
q_per_token = torch.matmul(token_embeddings, q_layer0_head0.T)
Shape of resulting tensor: queries per token
q_per_token.shape
OUTPUT
torch.Size([17, 128])
OUTPUT
查询矢量本来就不知道自己在提示符中的位置,因此我们将使用 RoPE 让它们意识到这一点。
实施 RoPE
=======
我们将查询矢量分成两对,然后对每对矢量进行旋转角度移动。
Convert queries per token to float and split into pairs
q_per_token_split_into_pairs = q_per_token.float().view(q_per_token.shape[0], -1, 2)
Print the shape of the resulting tensor after splitting into pairs
q_per_token_split_into_pairs.shape
OUTPUT
torch.Size([17, 64, 2])
OUTPUT
我们有一个大小为 \[17x64x2\] 的向量,它表示 128 个长度的查询,每个提示符分成 64 对。每对查询将按 m\*theta 旋转,其中 m 是我们要旋转查询的标记的位置。 我们将使用复数的点积来旋转矢量。
Generate values from 0 to 1 split into 64 parts
zero_to_one_split_into_64_parts = torch.tensor(range(64))/64
Print the resulting tensor
zero_to_one_split_into_64_parts
OUTPUT
tensor([0.0000,0.0156,0.0312,0.0469,0.0625,0.0781,0.0938,0.1094,0.1250, 0.1406,0.1562,0.1719,0.1875,0.2031,0.2188,0.2344,0.2500,0.2656, 0.2812,0.2969,0.3125,0.3281,0.3438,0.3594,0.3750,0.3906,0.4062, 0.4219,0.4375,0.4531,0.4688,0.4844,0.5000,0.5156,0.5312,0.5469, 0.5625,0.5781,0.5938,0.6094,0.6250,0.6406,0.6562,0.6719,0.6875, 0.7031,0.7188,0.7344,0.7500,0.7656,0.7812,0.7969,0.8125,0.8281, 0.8438,0.8594,0.8750,0.8906,0.9062,0.9219,0.9375,0.9531,0.9688, 0.9844])
OUTPUT
分割步骤完成后,我们将计算其频率。
Calculate frequencies using a power operation
freqs =1.0/(rope_theta ** zero_to_one_split_into_64_parts)
Display the resulting frequencies
freqs
OUTPUT
tensor([1.0000e+00,8.1462e-01,6.6360e-01,5.4058e-01,4.4037e-01,3.5873e-01, 2.9223e-01,2.3805e-01,1.9392e-01,1.5797e-01,1.2869e-01,1.0483e-01, 8.5397e-02,6.9566e-02,5.6670e-02,4.6164e-02,3.7606e-02,3.0635e-02, 2.4955e-02,2.0329e-02,1.6560e-02,1.3490e-02,1.0990e-02,8.9523e-03, 7.2927e-03,5.9407e-03,4.8394e-03,3.9423e-03,3.2114e-03,2.6161e-03, 2.1311e-03,1.7360e-03,1.4142e-03,1.1520e-03,9.3847e-04,7.6450e-04, 6.2277e-04,5.0732e-04,4.1327e-04,3.3666e-04,2.7425e-04,2.2341e-04, 1.8199e-04,1.4825e-04,1.2077e-04,9.8381e-05,8.0143e-05,6.5286e-05, 5.3183e-05,4.3324e-05,3.5292e-05,2.8750e-05,2.3420e-05,1.9078e-05, 1.5542e-05,1.2660e-05,1.0313e-05,8.4015e-06,6.8440e-06,5.5752e-06, 4.5417e-06,3.6997e-06,3.0139e-06,2.4551e-06])
OUTPUT
现在,每个标记的查询元素都有一个复数,我们可以将查询转换成复数,然后使用点乘法根据它们的位置进行旋转。
Convert queries per token to complex numbers
q_per_token_as_complex_numbers = torch.view_as_complex(q_per_token_split_into_pairs)
q_per_token_as_complex_numbers.shape
Output: torch.Size([17, 64])
Calculate frequencies for each token using outer product of arange(17) and freqs
freqs_for_each_token = torch.outer(torch.arange(17), freqs)
Calculate complex numbers from frequencies_for_each_token using polar coordinates
freqs_cis = torch.polar(torch.ones_like(freqs_for_each_token), freqs_for_each_token)
Rotate complex numbers by frequencies
q_per_token_as_complex_numbers_rotated = q_per_token_as_complex_numbers * freqs_cis
q_per_token_as_complex_numbers_rotated.shape
Output: torch.Size([17, 64])
在得到旋转向量后,我们可以将复数再次视为实数,从而回到原来的成对查询。
Convert rotated complex numbers back to real numbers
q_per_token_split_into_pairs_rotated = torch.view_as_real(q_per_token_as_complex_numbers_rotated)
Print the shape of the resulting tensor
q_per_token_split_into_pairs_rotated.shape
OUTPUT
torch.Size([17, 64, 2])
OUTPUT
现在,旋转后的数据对将被合并,从而产生一个新的查询向量(旋转查询向量),其形状为 \[17x128\],其中 17 是标记数,128 是查询向量的维度。
Reshape rotated token queries to match the original shape
q_per_token_rotated = q_per_token_split_into_pairs_rotated.view(q_per_token.shape)
Print the shape of the resulting tensor
q_per_token_rotated.shape
OUTPUT
torch.Size([17, 128])
OUTPUT
对于密钥,过程与此类似,但要记住密钥向量也是 128 维的。密钥的权重只有查询的 1/4,因为它们一次由 4 个磁头共享,以尽量减少计算量。密钥也会旋转,以包含位置信息,这与查询类似。
Extract the weight tensor for the attention mechanism's key in the first layer of the model
k_layer0 = model["layers.0.attention.wk.weight"]
Reshape key weight for the first layer of attention to separate heads
k_layer0 = k_layer0.view(n_kv_heads, k_layer0.shape[0]// n_kv_heads, dim)
Print the shape of the reshaped key weight tensor
k_layer0.shape # Output: torch.Size([8, 128, 4096])
Extract the key weight for the first head of the first layer of attention
k_layer0_head0 = k_layer0[0]
Print the shape of the extracted key weight tensor for the first head
k_layer0_head0.shape # Output: torch.Size([128, 4096])
Calculate key per token by matrix multiplication
k_per_token = torch.matmul(token_embeddings, k_layer0_head0.T)
Print the shape of the resulting tensor representing keys per token
k_per_token.shape # Output: torch.Size([17, 128])
Split key per token into pairs and convert to float
k_per_token_split_into_pairs = k_per_token.float().view(k_per_token.shape[0],-1,2)
Print the shape of the resulting tensor after splitting into pairs
k_per_token_split_into_pairs.shape # Output: torch.Size([17, 64, 2])
Convert key per token to complex numbers
k_per_token_as_complex_numbers = torch.view_as_complex(k_per_token_split_into_pairs)
Print the shape of the resulting tensor representing key per token as complex numbers
k_per_token_as_complex_numbers.shape # Output: torch.Size([17, 64])
Rotate complex key per token by frequencies
k_per_token_split_into_pairs_rotated = torch.view_as_real(k_per_token_as_complex_numbers * freqs_cis)
Print the shape of the rotated complex key per token
k_per_token_split_into_pairs_rotated.shape # Output: torch.Size([17, 64, 2])
Reshape rotated key per token to match the original shape
k_per_token_rotated = k_per_token_split_into_pairs_rotated.view(k_per_token.shape)
Print the shape of the rotated key per token
k_per_token_rotated.shape # Output: torch.Size([17, 128])
现在我们有了每个令牌的旋转查询和密钥,每个令牌的大小为 \[17x128\]。
实施自我关注
======
将查询矩阵和密钥矩阵相乘,就能得到将每个标记映射到另一个标记的得分。这个分数表示每个标记的查询和关键字之间的关系。
Calculate query-key dot products per token
qk_per_token = torch.matmul(q_per_token_rotated, k_per_token_rotated.T) / (head_dim) ** 0.5
Print the shape of the resulting tensor representing query-key dot products per token
qk_per_token.shape
OUTPUT
torch.Size([17, 17])
OUTPUT
\[17x17\]形状代表注意力分数(qk\_per\_token),其中 17 是提示符的数量。我们需要屏蔽查询键得分。在训练过程中,未来标记的查询密钥得分是被屏蔽的,因为我们只学会使用过去的标记来预测标记。因此,在推理过程中,我们会将未来标记设置为零。
Create a mask tensor filled with negative infinity values
mask = torch.full((len(tokens),len(tokens)),float("-inf"), device=tokens.device)
Set upper triangular part of the mask tensor to negative infinity
mask = torch.triu(mask, diagonal=1)
Print the resulting mask tensor
mask
OUTPUT
tensor([[0.,-inf,-inf,-inf,-inf,-inf,-inf,-inf,-inf,-inf,-inf,-inf,-inf,-inf,-inf,-inf,-inf], [0.,0.,-inf,-inf,-inf,-inf,-inf,-inf,-inf,-inf,-inf,-inf,-inf,-inf,-inf,-inf,-inf], [0.,0.,0.,-inf,-inf,-inf,-inf,-inf,-inf,-inf,-inf,-inf,-inf,-inf,-inf,-inf,-inf], [0.,0.,0.,0.,-inf,-inf,-inf,-inf,-inf,-inf,-inf,-inf,-inf,-inf,-inf,-inf,-inf], [0.,0.,0.,0.,0.,-inf,-inf,-inf,-inf,-inf,-inf,-inf,-inf,-inf,-inf,-inf,-inf], [0.,0.,0.,0.,0.,0.,-inf,-inf,-inf,-inf,-inf,-inf,-inf,-inf,-inf,-inf,-inf], [0.,0.,0.,0.,0.,0.,0.,-inf,-inf,-inf,-inf,-inf,-inf,-inf,-inf,-inf,-inf], [0.,0.,0.,0.,0.,0.,0.,0.,-inf,-inf,-inf,-inf,-inf,-inf,-inf,-inf,-inf], [0.,0.,0.,0.,0.,0.,0.,0.,0.,-inf,-inf,-inf,-inf,-inf,-inf,-inf,-inf], [0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,-inf,-inf,-inf,-inf,-inf,-inf,-inf], [0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,-inf,-inf,-inf,-inf,-inf,-inf], [0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,-inf,-inf,-inf,-inf,-inf], [0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,-inf,-inf,-inf,-inf], [0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,-inf,-inf,-inf], [0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,-inf,-inf], [0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,-inf], [0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,0.]])
OUTPUT
现在,我们必须对每个标记向量的查询密钥应用掩码。此外,我们还要在其上应用 softmax,将输出分数转换为概率。这有助于从模型的词汇表中选择最有可能的标记或标记序列,使模型的预测结果更具可解释性,更适合语言生成和分类等任务。
Add the mask to the query-key dot products per token
qk_per_token_after_masking = qk_per_token + mask
Apply softmax along the second dimension after masking
qk_per_token_after_masking_after_softmax = torch.nn.functional.softmax(qk_per_token_after_masking, dim=1).to(torch.bfloat16)
值矩阵标志着自我注意力部分的结束,与键类似,值权重也是每 4 个注意力头共享的,以节省计算量。因此,值权重矩阵的形状为 \[8x128x4096\]。
Retrieve the value weight for the first layer of attention
v_layer0 = model["layers.0.attention.wv.weight"]
Reshape value weight for the first layer of attention to separate heads
v_layer0 = v_layer0.view(n_kv_heads, v_layer0.shape[0] // n_kv_heads, dim)
Print the shape of the reshaped value weight tensor
v_layer0.shape
OUTPUT
torch.Size([8, 128, 4096])
OUTPUT
与查询矩阵和关键矩阵类似,第一层和首部的值矩阵也可以通过以下方法获得:
Extract the value weight for the first head of the first layer of attention
v_layer0_head0 = v_layer0[0]
Print the shape of the extracted value weight tensor for the first head
v_layer0_head0.shape
OUTPUT
torch.Size([128, 4096])
OUTPUT
通过值权重,我们计算出每个标记的注意力值,从而得到一个大小为 \[17x128\] 的矩阵。其中,17 表示提示符的数量,128 表示每个提示符的值向量的维度。
Calculate value per token by matrix multiplication
v_per_token = torch.matmul(token_embeddings, v_layer0_head0.T)
Print the shape of the resulting tensor representing values per token
v_per_token.shape
OUTPUT
torch.Size([17, 128])
OUTPUT
为了得到注意力矩阵,我们可以进行以下乘法运算:
Calculate QKV attention by matrix multiplication
qkv_attention = torch.matmul(qk_per_token_after_masking_after_softmax, v_per_token)
Print the shape of the resulting tensor
qkv_attention.shape
OUTPUT
torch.Size([17, 128])
OUTPUT
现在,我们得到了第一层和第一头的注意力值,换句话说,就是自我注意力值。
实施多头关注
======
将执行一个循环,进行与上述相同的计算,但针对的是第一层中的每个头部。
Store QKV attention for each head in a list
qkv_attention_store =[]
Iterate through each head
for head inrange(n_heads):
Extract query, key, and value weights for the current head
q_layer0_head = q_layer0[head] k_layer0_head = k_layer0[head//4]# Key weights are shared across 4 heads v_layer0_head = v_layer0[head//4]# Value weights are shared across 4 heads
Calculate query per token by matrix multiplication
q_per_token = torch.matmul(token_embeddings, q_layer0_head.T)
Calculate key per token by matrix multiplication
k_per_token = torch.matmul(token_embeddings, k_layer0_head.T)
Calculate value per token by matrix multiplication
v_per_token = torch.matmul(token_embeddings, v_layer0_head.T)
Split query per token into pairs and rotate them
q_per_token_split_into_pairs = q_per_token.float().view(q_per_token.shape[0],-1,2) q_per_token_as_complex_numbers = torch.view_as_complex(q_per_token_split_into_pairs) q_per_token_split_into_pairs_rotated = torch.view_as_real(q_per_token_as_complex_numbers * freqs_cis[:len(tokens)]) q_per_token_rotated = q_per_token_split_into_pairs_rotated.view(q_per_token.shape)
Split key per token into pairs and rotate them
k_per_token_split_into_pairs = k_per_token.float().view(k_per_token.shape[0],-1,2) k_per_token_as_complex_numbers = torch.view_as_complex(k_per_token_split_into_pairs) k_per_token_split_into_pairs_rotated = torch.view_as_real(k_per_token_as_complex_numbers * freqs_cis[:len(tokens)]) k_per_token_rotated = k_per_token_split_into_pairs_rotated.view(k_per_token.shape)
Calculate query-key dot products per token
qk_per_token = torch.matmul(q_per_token_rotated, k_per_token_rotated.T)/(128)**0.5
Create a mask tensor filled with negative infinity values
mask = torch.full((len(tokens),len(tokens)),float("-inf"), device=tokens.device)
Set upper triangular part of the mask tensor to negative infinity
mask = torch.triu(mask, diagonal=1)
Add the mask to the query-key dot products per token
qk_per_token_after_masking = qk_per_token + mask
Apply softmax along the second dimension after masking
qk_per_token_after_masking_after_softmax = torch.nn.functional.softmax(qk_per_token_after_masking, dim=1).to(torch.bfloat16)
Calculate QKV attention by matrix multiplication
qkv_attention = torch.matmul(qk_per_token_after_masking_after_softmax, v_per_token)
Store QKV attention for the current head
qkv_attention_store.append(qkv_attention)
Print the number of QKV attentions stored
len(qkv_attention_store)
OUTPUT
32
OUTPUT
现在,第一层所有 32 个头的 QKV 注意力矩阵都已得到,所有的注意力分数将合并成一个大小为 \[17x4096\] 的大矩阵。
Concatenate QKV attentions from all heads along the last dimension
stacked_qkv_attention = torch.cat(qkv_attention_store, dim=-1)
Print the shape of the resulting tensor
stacked_qkv_attention.shape
OUTPUT
torch.Size([17, 4096])
OUTPUT
关注第 0 层的最后一个步骤是将权重矩阵与堆叠 QKV 矩阵相乘。
Calculate the embedding delta by matrix multiplication with the output weight
embedding_delta = torch.matmul(stacked_qkv_attention, model["layers.0.attention.wo.weight"].T)
Print the shape of the resulting tensor
embedding_delta.shape
OUTPUT
torch.Size([17, 4096])
OUTPUT
现在,我们有了关注后嵌入值的变化,这些变化应添加到原始标记嵌入值中。
Add the embedding delta to the unnormalized token embeddings to get the final embeddings
embedding_after_edit = token_embeddings_unnormalized + embedding_delta
Print the shape of the resulting tensor
embedding_after_edit.shape
OUTPUT
torch.Size([17, 4096])
OUTPUT
对嵌入变化进行归一化处理,然后通过前馈神经网络运行。
Normalize edited embeddings using root mean square normalization and provided weights
embedding_after_edit_normalized = rms_norm(embedding_after_edit, model["layers.0.ffn_norm.weight"])
Print the shape of resulting normalized embeddings
embedding_after_edit_normalized.shape
OUTPUT
torch.Size([17, 4096])
OUTPUT
执行 SwiGLU 激活功能
==============
鉴于我们已经熟悉了前一节中的 SwiGLU 激活函数,我们将在这里应用我们之前研究过的方程。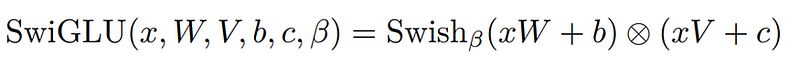
Retrieve weights for feedforward layer
w1 = model["layers.0.feed_forward.w1.weight"] w2 = model["layers.0.feed_forward.w2.weight"] w3 = model["layers.0.feed_forward.w3.weight"]
Perform operations for feedforward layer
output_after_feedforward = torch.matmul(torch.functional.F.silu(torch.matmul(embedding_after_edit_normalized, w1.T))* torch.matmul(embedding_after_edit_normalized, w3.T), w2.T)
Print the shape of the resulting tensor after feedforward
output_after_feedforward.shape
OUTPUT
torch.Size([17,4096])
OUTPUT
合并一切
====
现在一切准备就绪,我们需要合并代码,生成另外 31 个图层。
Initialize final embedding with unnormalized token embeddings
final_embedding = token_embeddings_unnormalized
Iterate through each layer
for layer inrange(n_layers):
Initialize list to store QKV attentions for each head
qkv_attention_store =[]
Normalize the final embedding using root mean square normalization and weights from the current layer
layer_embedding_norm = rms_norm(final_embedding, model[f"layers.{layer}.attention_norm.weight"])
Retrieve query, key, value, and output weights for the attention mechanism of the current layer
q_layer = model[f"layers.{layer}.attention.wq.weight"] q_layer = q_layer.view(n_heads, q_layer.shape[0]// n_heads, dim) k_layer = model[f"layers.{layer}.attention.wk.weight"] k_layer = k_layer.view(n_kv_heads, k_layer.shape[0]// n_kv_heads, dim) v_layer = model[f"layers.{layer}.attention.wv.weight"] v_layer = v_layer.view(n_kv_heads, v_layer.shape[0]// n_kv_heads, dim) w_layer = model[f"layers.{layer}.attention.wo.weight"]
Iterate through each head
for head inrange(n_heads):
Extract query, key, and value weights for the current head
q_layer_head = q_layer[head] k_layer_head = k_layer[head//4]# Key weights are shared across 4 heads v_layer_head = v_layer[head//4]# Value weights are shared across 4 heads
Calculate query per token by matrix multiplication
q_per_token = torch.matmul(layer_embedding_norm, q_layer_head.T)
Calculate key per token by matrix multiplication
k_per_token = torch.matmul(layer_embedding_norm, k_layer_head.T)
Calculate value per token by matrix multiplication
v_per_token = torch.matmul(layer_embedding_norm, v_layer_head.T)
Split query per token into pairs and rotate them
q_per_token_split_into_pairs = q_per_token.float().view(q_per_token.shape[0],-1,2) q_per_token_as_complex_numbers = torch.view_as_complex(q_per_token_split_into_pairs) q_per_token_split_into_pairs_rotated = torch.view_as_real(q_per_token_as_complex_numbers * freqs_cis) q_per_token_rotated = q_per_token_split_into_pairs_rotated.view(q_per_token.shape)
Split key per token into pairs and rotate them
k_per_token_split_into_pairs = k_per_token.float().view(k_per_token.shape[0],-1,2) k_per_token_as_complex_numbers = torch.view_as_complex(k_per_token_split_into_pairs) k_per_token_split_into_pairs_rotated = torch.view_as_real(k_per_token_as_complex_numbers * freqs_cis) k_per_token_rotated = k_per_token_split_into_pairs_rotated.view(k_per_token.shape)
Calculate query-key dot products per token
qk_per_token = torch.matmul(q_per_token_rotated, k_per_token_rotated.T)/(128)**0.5
Create a mask tensor filled with negative infinity values
mask = torch.full((len(token_embeddings_unnormalized),len(token_embeddings_unnormalized)),float("-inf"))
Set upper triangular part of the mask tensor to negative infinity
mask = torch.triu(mask, diagonal=1)
Add the mask to the query-key dot products per token
qk_per_token_after_masking = qk_per_token + mask
Apply softmax along the second dimension after masking
qk_per_token_after_masking_after_softmax = torch.nn.functional.softmax(qk_per_token_after_masking, dim=1).to(torch.bfloat16)
Calculate QKV attention by matrix multiplication
qkv_attention = torch.matmul(qk_per_token_after_masking_after_softmax, v_per_token)
Store QKV attention for the current head
qkv_attention_store.append(qkv_attention)
Concatenate QKV attentions from all heads along the last dimension
stacked_qkv_attention = torch.cat(qkv_attention_store, dim=-1)
Calculate embedding delta by matrix multiplication with the output weight
embedding_delta = torch.matmul(stacked_qkv_attention, w_layer.T)
Add the embedding delta to the current embedding to get the edited embedding
embedding_after_edit = final_embedding + embedding_delta
Normalize the edited embedding using root mean square normalization and weights from the current layer
embedding_after_edit_normalized = rms_norm(embedding_after_edit, model[f"layers.{layer}.ffn_norm.weight"])
Retrieve weights for the feedforward layer
w1 = model[f"layers.{layer}.feed_forward.w1.weight"] w2 = model[f"layers.{layer}.feed_forward.w2.weight"] w3 = model[f"layers.{layer}.feed_forward.w3.weight"]
Perform operations for the feedforward layer
output_after_feedforward = torch.matmul(torch.functional.F.silu(torch.matmul(embedding_after_edit_normalized, w1.T))* torch.matmul(embedding_after_edit_normalized, w3.T), w2.T)
Update the final embedding with the edited embedding plus the output from the feedforward layer
final_embedding = embedding_after_edit + output_after_feedforward
生成输出
====
现在我们有了最终的嵌入,它代表了模型对下一个标记的猜测。它的形状与普通的标记嵌入相同,即 \[17x4096\],有 17 个标记,嵌入维度为 4096。
Normalize the final embedding using root mean square normalization and provided weights
final_embedding = rms_norm(final_embedding, model["norm.weight"])
Print the shape of the resulting normalized final embedding
final_embedding.shape
OUTPUT
torch.Size([17, 4096])
OUTPUT
现在,我们可以将嵌入解码为令牌值。
Print the shape of the output weight tensor
model["output.weight"].shape
OUTPUT
torch.Size([128256, 4096])
OUTPUT
为了预测下一个值,我们利用了上一个标记的嵌入。
Calculate logits by matrix multiplication between the final embedding and the transpose of the output weight tensor
logits = torch.matmul(final_embedding[-1], model["output.weight"].T)
Print the shape of the resulting logits tensor
logits.shape
OUTPUT
torch.Size([128256])
OUTPUT
# Find the index of the maximum value along the last dimension to determine the next token
next_token = torch.argmax(logits, dim=-1)
# Output the index of the next token
next_token
#### OUTPUT ####
tensor(2983)
#### OUTPUT ####
```
从令牌 ID 获取生成的文本
```
# Decode the index of the next token using the tokenizer
tokenizer.decode([next_token.item()])
#### OUTPUT ####
42
#### OUTPUT ####
```
因此,我们的输入是 "生命、宇宙和万物的终极问题的答案是",输出是 "42",这是正确答案。 您只需在整个代码中修改这两行,就可以尝试使用不同的输入文本,其他代码保持不变!
```
# input prompt
prompt = "Your Input"
# Replacing 17 number with total number of tokens in your input
# You can check total number of tokens using len(tokens)
freqs_for_each_token = torch.outer(torch.arange(17), freqs)
```
**希望你们喜欢这篇文章,并能从中学到新东西!**

**点个“在看”不失联**
最新热门文章推荐:
[国外Rust程序员分享:Rust与C++的完美结合](https://mp.weixin.qq.com/s?__biz=MzkzNjI3ODkyNQ==&mid=2247486074&idx=1&sn=2770aefeb2110c3353590daa43184bf6&scene=21#wechat_redirect)
[国外C++程序员分享:2024/2025年C++是否还值得学习?](https://mp.weixin.qq.com/s?__biz=MzkzNjI3ODkyNQ==&mid=2247486076&idx=1&sn=d646c8a6c06a3a95a2ced4094c021aa2&scene=21#wechat_redirect)
[外国人眼中的贾扬清:从清华到阿里,再创业LeptonAI](https://mp.weixin.qq.com/s?__biz=MzkzNjI3ODkyNQ==&mid=2247486075&idx=1&sn=9f8ce330fcc87e908b523df3afaa104e&scene=21#wechat_redirect)
[白宫关注下,C++的内存安全未来走向何方?](https://mp.weixin.qq.com/s?__biz=MzkzNjI3ODkyNQ==&mid=2247486035&idx=1&sn=f6ce5327b66d91a36cd4fa1d9b8a9f80&scene=21#wechat_redirect)
[国外Python程序员分享:如何用Python构建一个多代理AI应用](https://mp.weixin.qq.com/s?__biz=MzkzNjI3ODkyNQ==&mid=2247485989&idx=1&sn=439789fd8492ee8bda40fef51d3e6145&scene=21#wechat_redirect)
[本地部署六款大模型:保护隐私、节省成本,特定环境首选](https://mp.weixin.qq.com/s?__biz=MzkzNjI3ODkyNQ==&mid=2247485969&idx=1&sn=54c20e46c70172307c72026abbf2755b&scene=21#wechat_redirect)
[国外CUDA程序员分享:2024年GPU编程CUDA C++(从环境安装到进阶技巧)](https://mp.weixin.qq.com/s?__biz=MzkzNjI3ODkyNQ==&mid=2247485788&idx=1&sn=77e8feae61345b275e8e5a8ee400b2bb&scene=21#wechat_redirect)
[我卸载了VSCode,我的生产力大幅提升](https://mp.weixin.qq.com/s?__biz=MzkzNjI3ODkyNQ==&mid=2247485827&idx=1&sn=5e9f02fdd3959cb427f15c70d9203122&scene=21#wechat_redirect)
[国外Python程序员分享:2024年NumPy高性能计算库(高级技巧)](https://mp.weixin.qq.com/s?__biz=MzkzNjI3ODkyNQ==&mid=2247485735&idx=1&sn=99586afdf165f53caeb4cf7a9062cfde&scene=21#wechat_redirect)
[外国人眼中的程明明:从“电脑小白”到CV领域领军者](https://mp.weixin.qq.com/s?__biz=MzkzNjI3ODkyNQ==&mid=2247485725&idx=1&sn=1a74cb4c9ea6f868ff5a88d91338718d&scene=21#wechat_redirect)
[外国人眼中的周志华:人工智能奖获得者、人工智能学院院长](https://mp.weixin.qq.com/s?__biz=MzkzNjI3ODkyNQ==&mid=2247485669&idx=1&sn=85842c2b4802ecc9dc988bab8394772f&scene=21#wechat_redirect)
[国外C++程序员分享:C++多线程实战掌握图像处理高级技巧](https://mp.weixin.qq.com/s?__biz=MzkzNjI3ODkyNQ==&mid=2247485687&idx=1&sn=6e1634cea46c7aacf3759d77a2d64338&scene=21#wechat_redirect)
[外国人眼中的卢湖川:从大连理工到全球舞台,他的科研成果震撼世界!](https://mp.weixin.qq.com/s?__biz=MzkzNjI3ODkyNQ==&mid=2247485650&idx=1&sn=396801f5408a194aee956a3acd30129b&scene=21#wechat_redirect)
[外国人眼中的张祥雨:交大90后男神博士,3年看1800篇论文,还入选福布斯精英榜](https://mp.weixin.qq.com/s?__biz=MzkzNjI3ODkyNQ==&mid=2247485593&idx=1&sn=cba8bf9d52b4a63321cd07afd88efa43&scene=21#wechat_redirect)
参考文献: 《图片来源网络》 《Building LLaMA 3 From Scratch with Python》
> 本文使用 [文章同步助手](https://juejin.cn/post/6940875049587097631) 同步
