token的生成过程
此处假设一个词就是一个token
#
LLM的回答如下:
RAG
RAG是
RAG是检
RAG是检索
RAG是检索增
RAG是检索增强
RAG是检索增强生
RAG是检索增强生成
在下一轮推理迭代过程中,本轮生成的token会拼加上之前生成的tokens,一起作为input输入到模型中生成下一个token,比如"RAG是检" + "索" -> "增"。
从token的生成流程我们可以看出,当前token的生存只依赖于以前的token,到这里可能会有疑惑token与以前的tokens有关也就是与之前的attention的QKV有关那么为什么只cache KV不cache Q呢?
下面我从attention计算角度进步分析KV可以被cache而Q不需要。
在自注意力机制中,查询(Q)、键(K)和值(V)之间的计算是非常关键的,特别是当模型在生成新的 token 时。每个新生成的 token 对应一个新的查询向量 qn,而这个查询向量需要与之前的所有键向量进行运算来计算注意力权重,好在我们只关注语句的上下文的上部分信息即只与前面生成的token有关,decoder中有一处Masked Multi-Head Attention,将矩阵右上三角设置为**-inf(负无穷大)** ,这样方便softmax的时候置为0,屏蔽未来数据的计算。
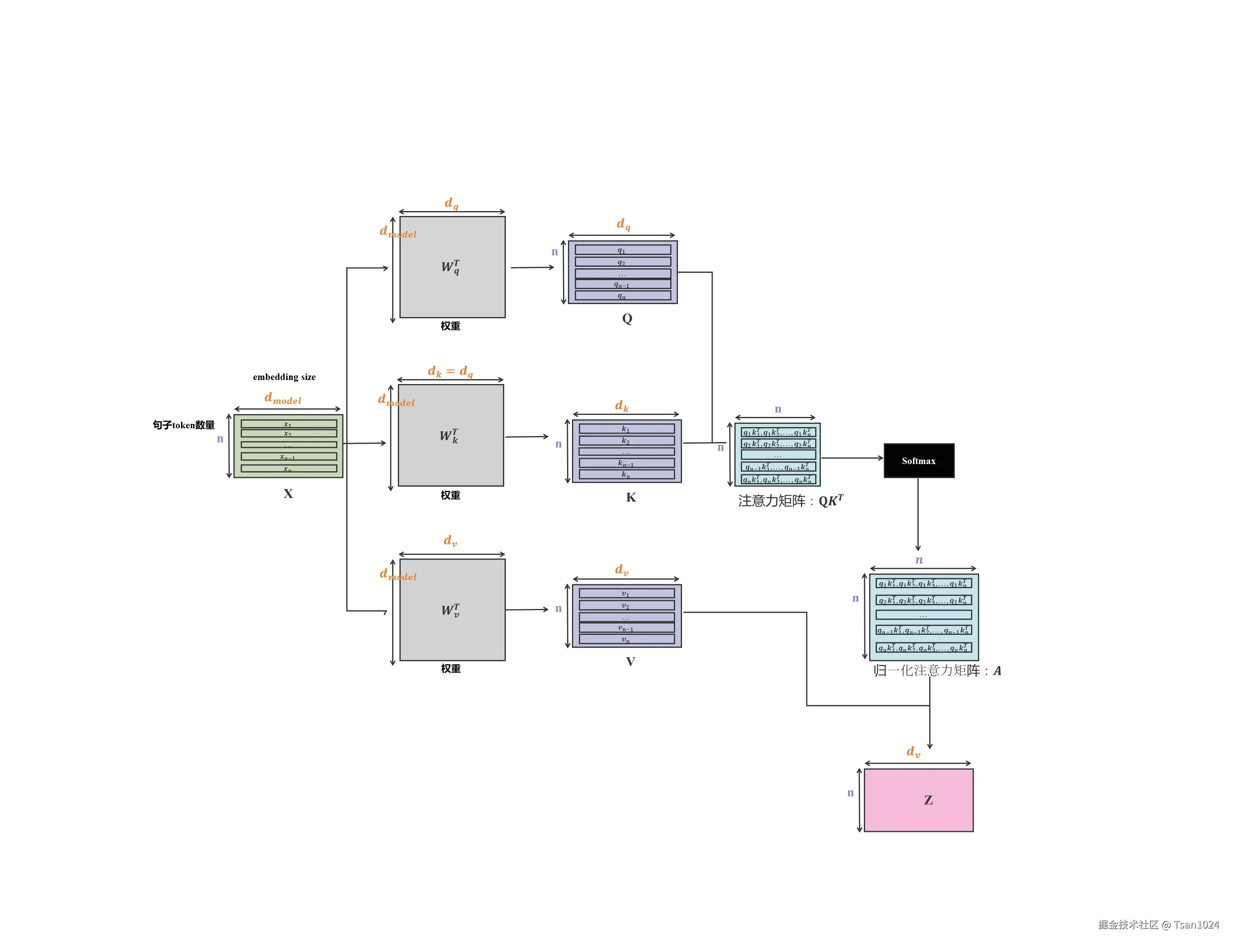
自注意力计算过程:
-
查询(Q)生成:每个新的输入 token xn 通过与权重矩阵 WQ 相乘生成查询向量 qn。
qn=xnWQ
-
计算与所有键 K 的注意力分数:然后新的查询 qn 会与所有之前生成的键 k1,k2,…,kn 进行运算(通常是计算点积)来得到注意力得分。
score(qn,ki)=qnKiT
其中 ki 是第 i 个键向量。
-
缓存键向量的必要性:对于每个新的查询向量 qn,我们不需要重新计算之前所有键的向量 k1,k2,…,kn−1 ,因为这些键的计算已经完成,并且它们会在生成过程中不断被使用。因此,**缓存这些键向量k1,k2,…,kn−1 ** 可以显著减少每次生成新 token 时的计算量。
-
当然上述只是可以缓存的一部分原因,此处只是减少了Ki的重复计算也就是xiWK计算,同理Value也是一样,这还远远不够,下文直接引用一位博主的分享。
QKT = [q1,q2,...,qn]∗KT
-
矩阵乘法的每个元素是行向量与列向量的点积:
具体来说,矩阵 ( QK^T ) 的第 ( (i, j) ) 个元素是查询向量 ( q_i ) 和键向量 ( k_j ) 的点积:
(QKT)ij=qi⋅kj=t=1∑dkqit⋅kjt
- 展开矩阵乘法:
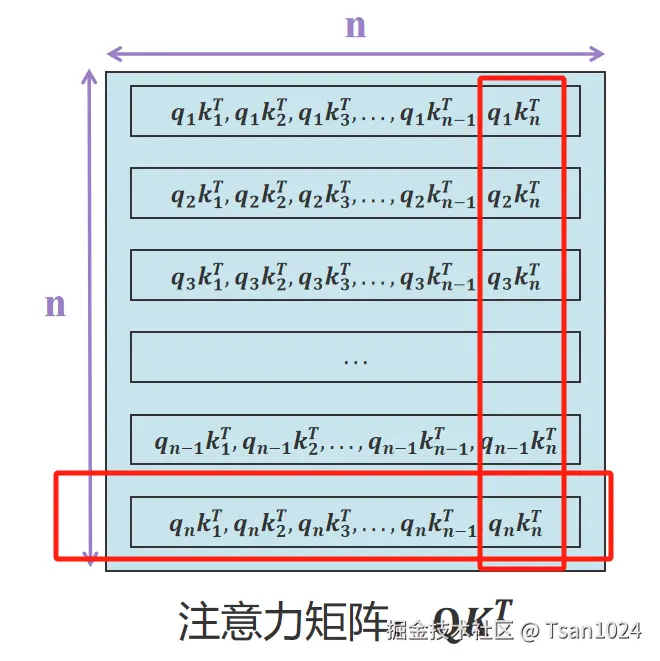
QKT=q1⋅k1Tq2⋅k1Tq3⋅k1T⋮qn⋅k1Tq1⋅k2Tq2⋅k2Tq3⋅k2T⋮qn⋅k2T……q3⋅k3T⋮qn⋅k3Tq1⋅kn−1Tq2⋅kn−1T…qn−1⋅kn−1T…q1⋅knTq2⋅knTq3⋅knTqn−1⋅knTqn⋅knT
注意:此处的矩阵的最后一行输入的xn通过WQ计算得到qn,qn分别与k1T、 k22 ... knT计算,其中1到n-1的kiT在上面几轮都出现过,因此可以缓存下来加速推理,避免重复计算ki,但矩阵的最后一列中的knT 与q1,q2 ... ,qn−1都有计算关系,那么q是不是也需要缓存呢?而且从矩阵计算看后续的xn对以前的xi注意力分数产生了影响,但在真实的推理中我们并不知道未来的token可能是什么,未来的token xn也不应该影响过去的注意力计算。在每一轮计算中有右上三角红色部分对我们并没有什么好处反而有影响,为了屏蔽这部分影响我们将矩阵右上三角设置为**-inf(负无穷大)** ,这样方便softmax的时候置为0。这就是为什么K需要缓存而Q不需要缓存的原因,同理V需要缓存也是一样的原因。
- 查询矩阵 Q 和 键矩阵 K 的点积:
QKT=q1q2⋮qn[k1Tk2T…knT]
- 缩放操作:
dkQKT
- Softmax 操作:
Attention Weights=Softmax(dkQKT)
- 下面是引用几位博主的图解attention计算图解
引用自:"为什么KV Cache只需缓存K矩阵和V矩阵,无需缓存Q矩阵?",博主讲解的更易懂,安利!!
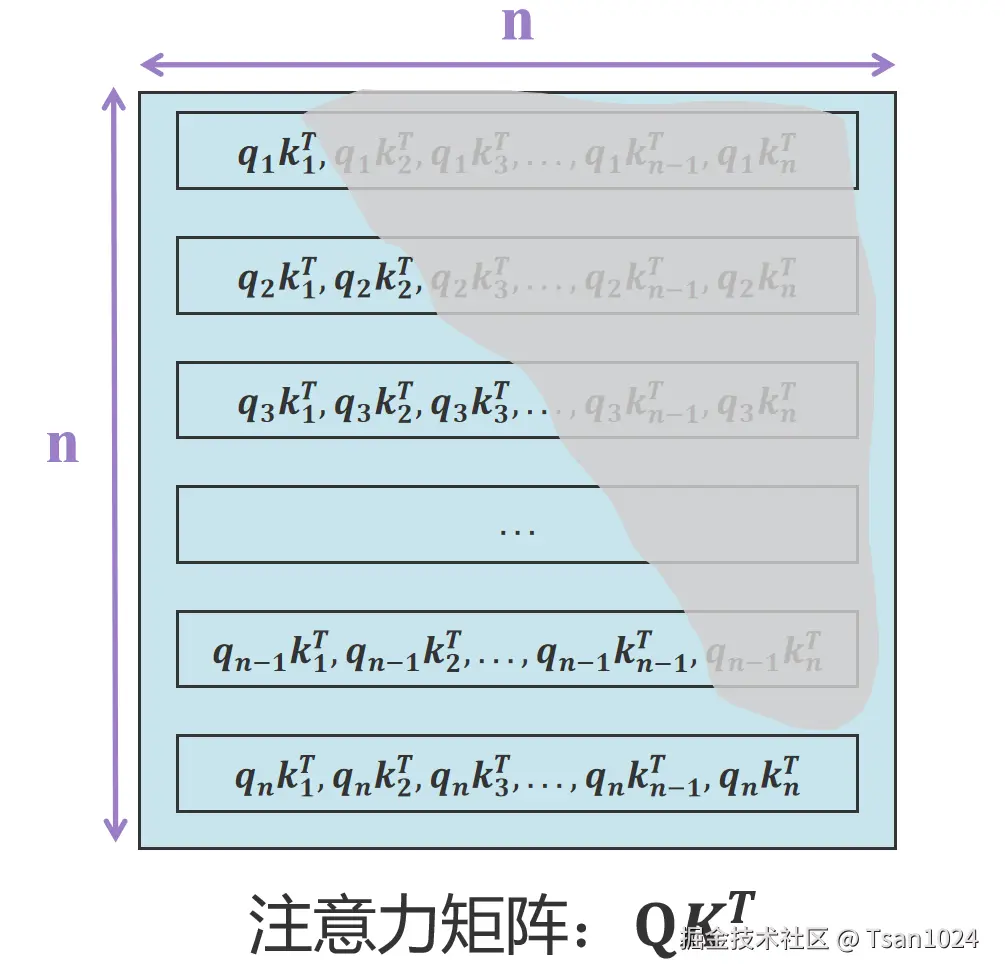
图解
KV 可以被cache源于token的attention仅依赖于以前的token KV计算, masked屏蔽了未来tokens对注意力计算的影响。
tokens计算的过程
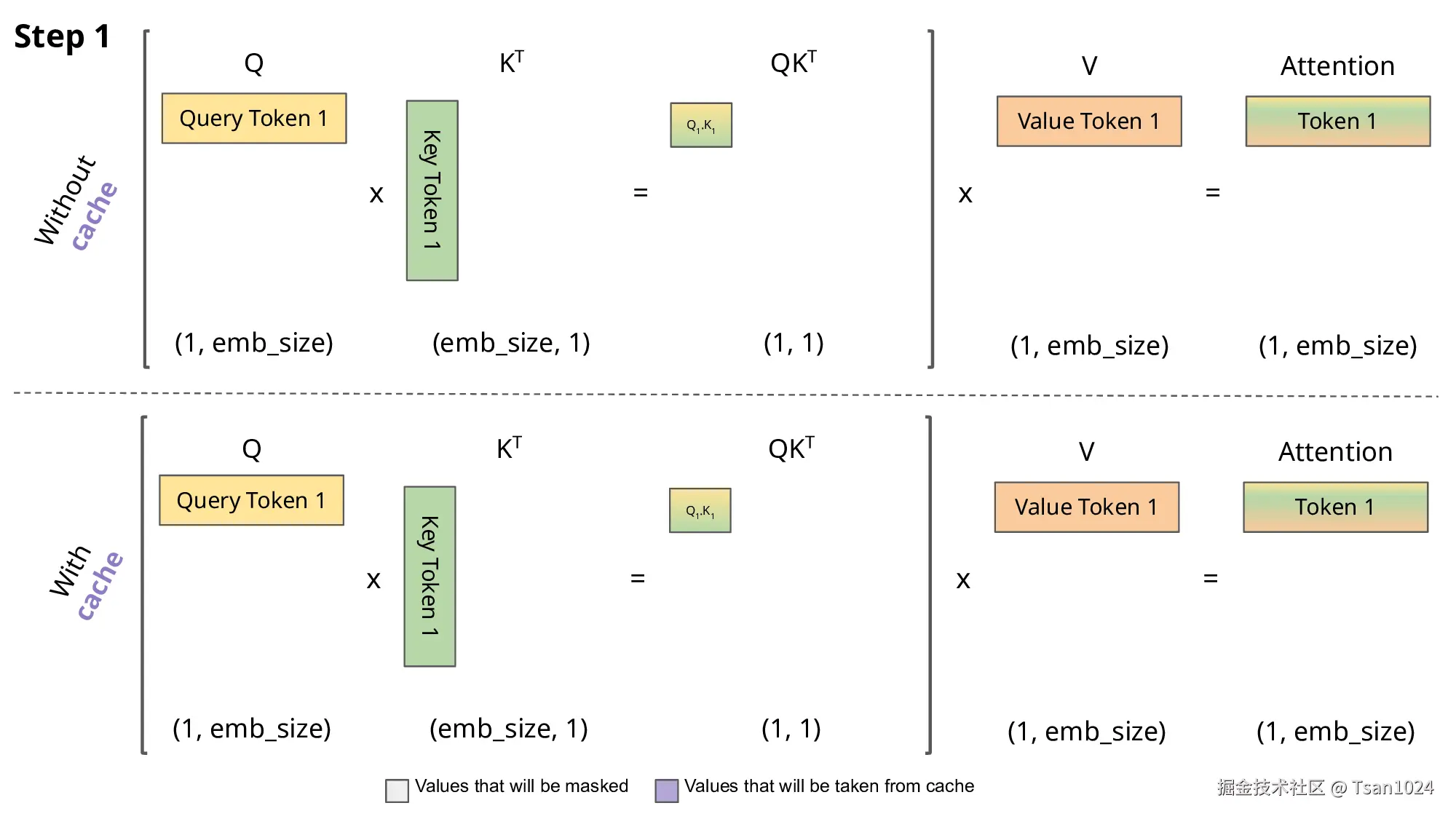 引用自: Transformers KV Caching Explained
引用自: Transformers KV Caching Explained
参考
- medium.com/@joaolages/…
- blog.csdn.net/wlxsp/artic…
- blog.csdn.net/qq_35054222…


