关系抽取
一、片段网络实现
论文:arxiv.org/pdf/1909.07…
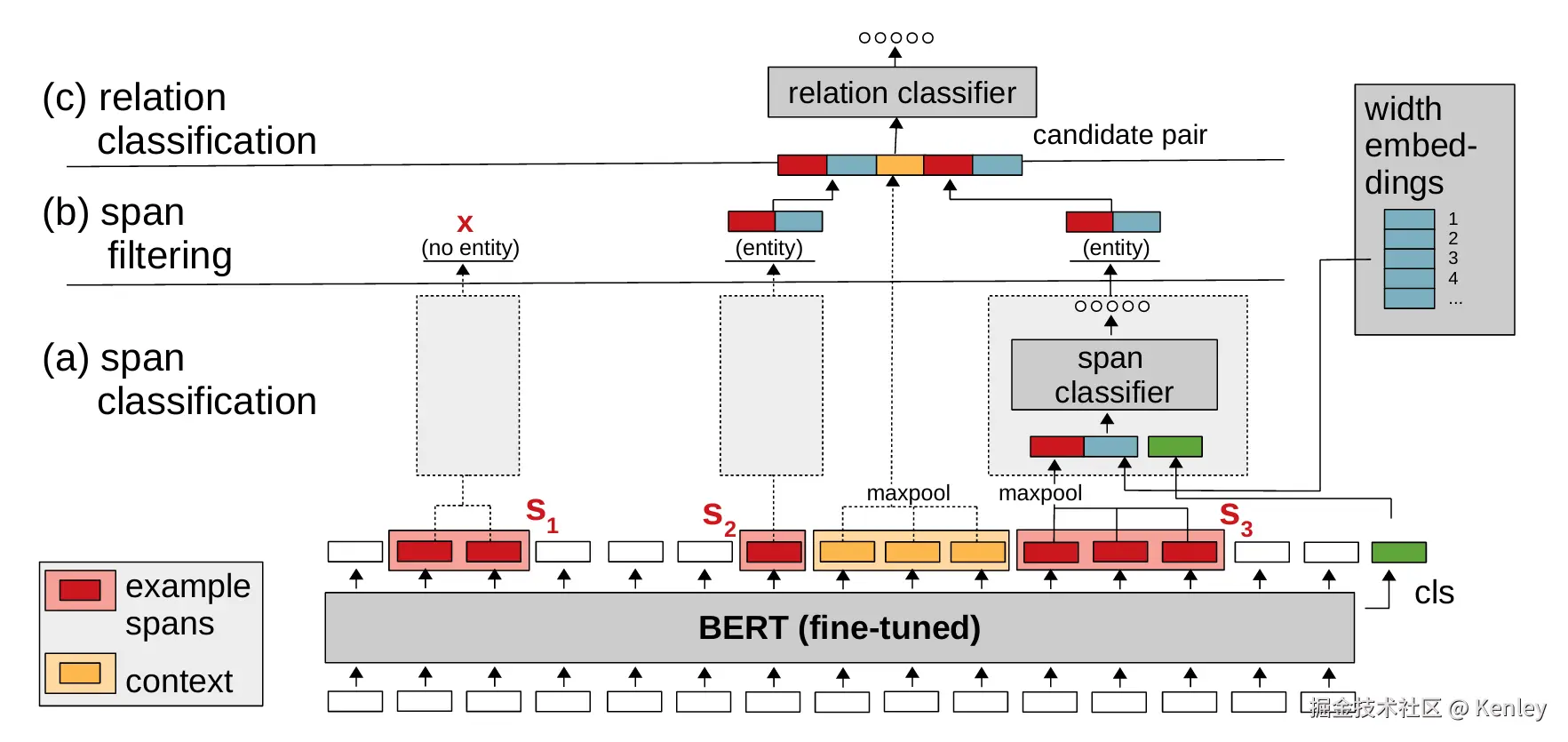
核心:(片段分类+片段组合进行关系分类)
1、对文本进行分词处理,每个词转成相应的token_id。
NOTE:文本中的一个词,可能会根据不同的分词规则,分成一个或者多个词。
2、对文本的token_id列表通过预训练的bert模型,提取每个token_id的特征向量。
NOTE:[N,T] ---> [N,T,E]
推理过程 :
3、根据片段的最大长度,从原始文本中穷举所有片段。通过对应关系,拿到每个片段的分词后的对应的每个词的特征向
量,然后求均值或者其他方式拿到每个片段的特征向量。[N,M,E]表示N个样本,每个样本M个片段,每个片段的特征向
量为E维度。
NOTE:M是有填充的,因为有的文本较短,所以片段较少。处理的时候需要一致,所以有填充。
4、对每个片段进行分类,类别数为片段/实体的类别数。然后通过argmax,获得每个片段的预测分类结果。
NOTE:[N,M,E] ---> [N,M,span_num_class] ---> [N,M]表示N个样本,每个样本M个分类结果。
每个分类结果的index,是会有个映射关系的,映射到token_ids中的从哪到哪,以及映射到原始
的从哪到哪。
5、对片段分类的结果进行过滤,拿到全部的实体片段,也就是值不为非实体的label以及不是填充值的值。
NOTE:[N,M] ---> [N,K]N个样本,每个样本K个预测的实体,有mask填充
6、对每个样本的实体片段进行两两组合,以及把对应实体的长度特征向量拿到和把他们之间的全部token的特征向量
拿到。
NOTE:具体是把实体片段的特征向量拿到,以及这个实体片段的长度特征向量拿到,拼接到一起得到2*E的特征。
然后把这两个实体之间的token的向量拿到求均值或者其他来表示token之间的特征得到E的特征。全部
和在一起就是2*E + E + 2*E,一共是5E维度的特征向量。
[N,K] ---> [N,R,5E]表示N个样本,R个实体组合,每个组合的特征向量文5E。
7、对每个实体组合进行分类,类别数为关系的数目。
NOTE:[N,R,5E] ---> [N,R,rel_num_class]表示N个样本,R个实体组合,每个组合的对应的类别置信度。
8、最后进行argmax和其他等等的映射关系,得到每个实体组合的关系是什么。
训练过程:
3、此时不需要根据片段的最大长度来穷举所有片段了,因为训练的时候直到实体和对应的关系。直接可以计算出每个实
体的特征向量。但是此时需要选一定个数的负样本,也就是非实体的片段出来。此时需要根据片段的最大长度来进行穷
举了,穷举的时候排除实体片段即可。最后得出来[N,M,E],表示N个样本,每个样本M个片段,每个片段的特征向量为
E维度。
NOTE:非实体的个数是固定的,不够则填充,而实体的个数也是固定的,不够则填充。最后都在M上进行表示,进行
填充处理。
4、对每个片段进行分类,类别数为片段/实体的类别数,得到实体的置信度。
NOTE:计算损失用,交叉熵损失,实体和非实体的损失
5、和推理部分不一样,训练的时候直接可以拿到每个实体,不需要通过计算拿了
6、同推理,实体两两组合,拿到特征向量5E
7、同推理,进行关系的分类,得到关系的置信度。
NOTE:计算损失用,交叉熵损失
二、指针网络实现
论文:arxiv.org/pdf/1909.03…
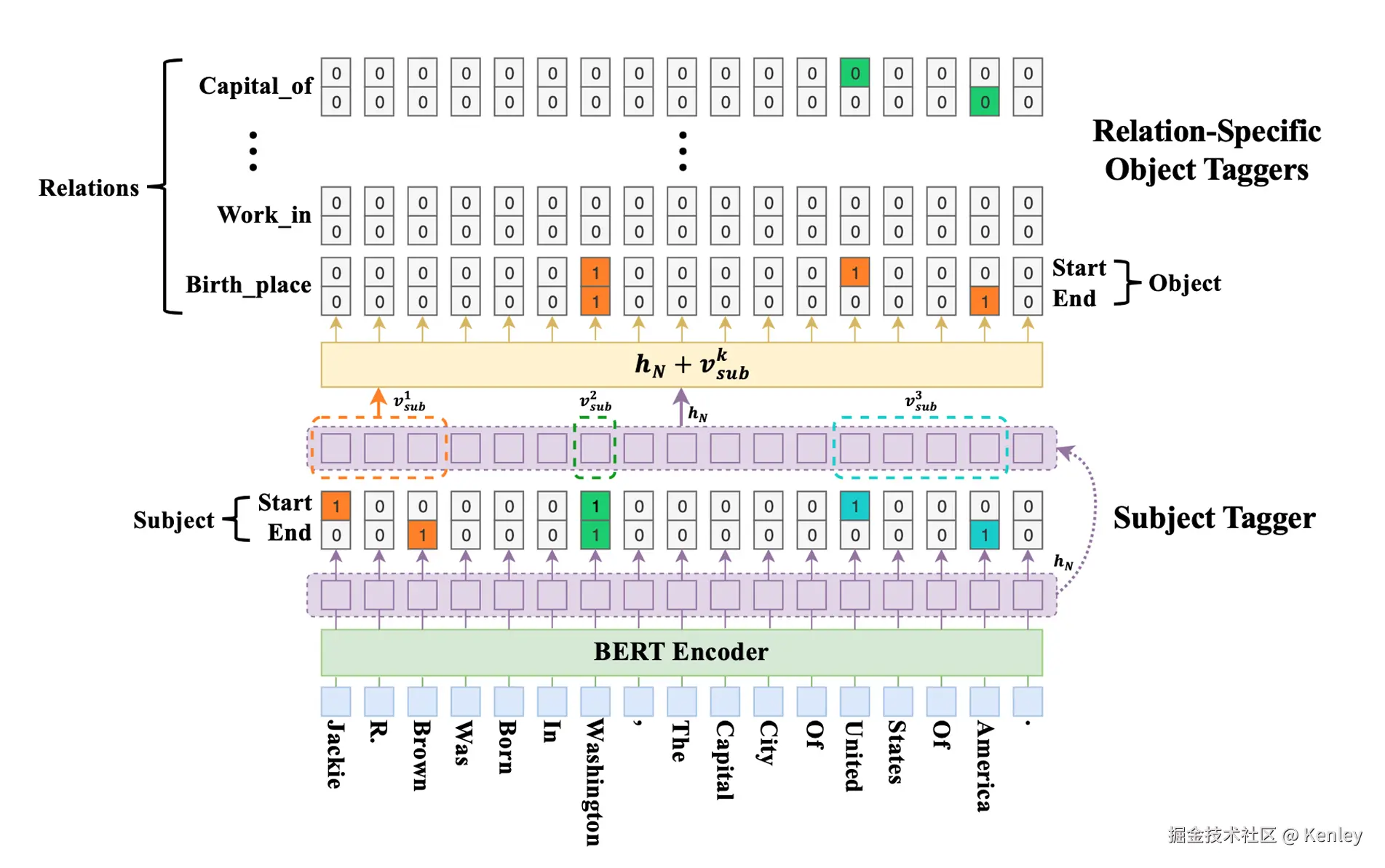
核心:(主客体+关系可以推出来主客体的类别)
1、对文本进行分词处理,每个词转成相应的token_id。
NOTE:文本中的一个词,可能会根据不同的分词规则,分成一个或者多个词。
2、对文本的token_id列表通过预训练的bert模型,提取每个token_id的特征向量。
NOTE:[N,T] ---> [N,T,E]
推理过程:
3、拿到每个词的特征向量,对这个词进行二分类,判断他是不是实体的开始或者结尾,得到对应的置信度。
NOTE:一个词可能是会分成了多个token_id,所以这里需要求均值或者其他,得到E维度的向量代表这个词。
[N,t,E]--->[N,t,2]t表示每个样本多少个词,T才是多少个token_id
4、对置信度进行sigmoid求概率,得到是开始还是结尾的概率值。
NOTE:因为一个词可以既是开始也是结束,表示这个单个词为一个实体,或者这个词属于两个不同的实体,只不过是这
个词是这两个不同的实体的开始和结尾。
5、根据自定义的规则,拿到每个实体,因为实体长度不一样,所以需要求一下均值或者其他来用E维度向量表示实体
NOTE:因为有嵌套关系,不同的规则,拿出来的实体可能不一样
eg: ( ( ) ) 用a b c d 表示,可能有一下组合。
1、ac和bd
2、ac和ad
3、ad和bc
6、此时可以拿到[N,M,E],表示N个样本,每个样本M个实体,每个实体的特征向量是E维度。
7、每个实体的向量[1,E]和它对应的文本的向量[t,E]加起来(广播),对这个向量[t,E]的每个时刻进行分类,类别是
rel_num*2,表示这个时刻是否是这个实体对应的每个关系的客体的开始还是结尾。
NOTE:[N,M,t,E] ---> [N,M,t,rel_num*2]
8、对上一步的结果进行reshape,由[N,M,t,rel_num*2] 变为[N,M,t,rel_num,2],相当于关系的二分类了
然后进行一次sigmoid,得到关系的客体的开始和结尾的概率,然后根据规则进行组合,得到每个实体作为主体后的关系
以及关系的客体是什么。
NOTE:关系确定了,主客体也确定了,则主客体的类型其实也就知道了。
训练过程:
3、同推理过程,得到[N,t,2]
4、同推理过程,进行sigmoid
NOTE:求损失,用BCE损失函数,如果不求sigmoid的话,用BCEWithLogitsLoss也可以
5、此时不需要根据规则拿到对应的实体了,因为现在实体是确定的。
6、同推理过程
7、同推理过程
8、同推理过程,此时由推理值和真实值,可以求损失
三、指针+片段网络实现
问题:
指针网络:嵌套关系不好解决
片段网络:片段过多不好解决,片段多了计算量大,片段少了准确率低
解决:
通过指针+片段结合进行实现
1、延用指针网络的思路,训练不变,推理进行更改。
2、在指针网络得到主体的二分类后,拿到每个开始和每个结尾。让开始和结尾进行两两组合,从而得到实体的片段。
3、之后进行关系的二分类后,也是一样,关系的开始和结尾进行两两组合,从而得到关系的片段。


