

Index索引
Indexes是LangChang早期版本的一个组件,现在已经被整合到Retrieval(数据检索)这个单元中了。而Retrieval(包括Indexes),讲的其实就是如何把离散的文档及其他信息做嵌入,存储到向量数据库中,然后再提取的过程。
索引是一种高效地管理和定位文档信息的方法,确保每个文档具有唯一标识并便于检索。
具体来说,它的优势包括:
-
避免重复内容:确保你的向量存储中不会有冗余数据。
-
只更新更改的内容:能检测哪些内容已更新,避免不必要的重写。
-
省时省钱:不对未更改的内容重新计算嵌入,从而减少了计算资源的消耗。
-
优化搜索结果:减少重复和不相关的数据,从而提高搜索的准确性。
LangChain 利用了记录管理器(RecordManager)来跟踪哪些文档已经被写入向量存储。
在进行索引时,API 会对每个文档进行哈希处理,确保每个文档都有一个唯一的标识。这个哈希值不仅仅基于文档的内容,还考虑了文档的元数据。
一旦哈希完成,以下信息会被保存在记录管理器中:
-
文档哈希:基于文档内容和元数据计算出的唯一标识。
-
写入时间:记录文档何时被添加到向量存储中。
-
源 ID:这是一个元数据字段,表示文档的原始来源。
这种方法确保了即使文档经历了多次转换或处理,也能够精确地跟踪它的状态和来源,确保文档数据被正确管理和索引。
总结时刻
对LangChain各个组件的一个简明总结。
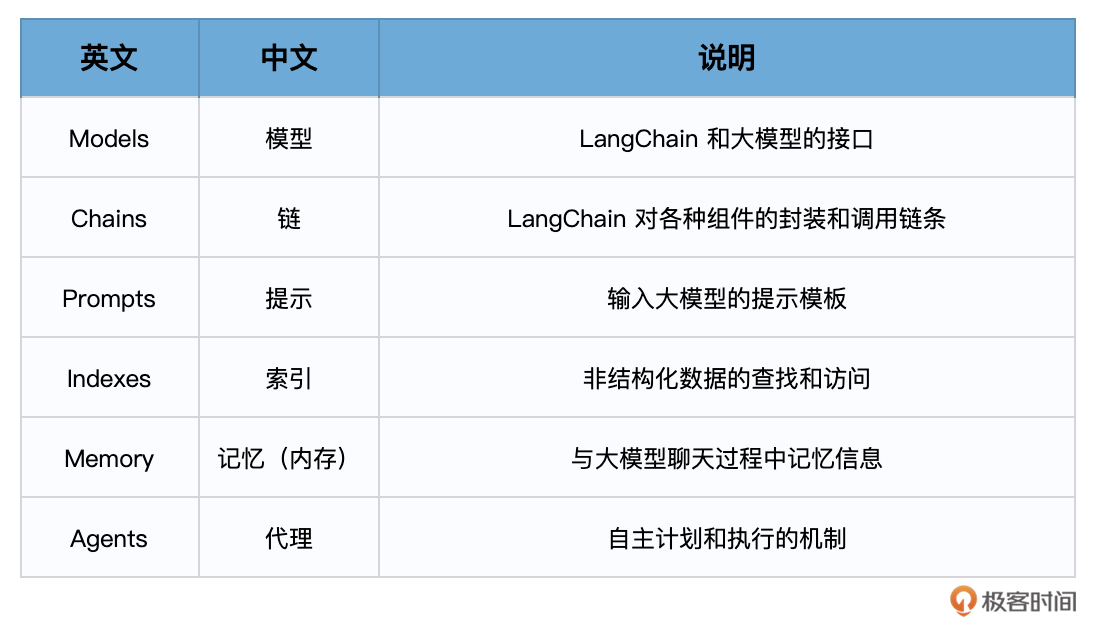
学习心得体会
在接触 LangChain 的学习过程中,我仿佛踏入了一片充满无限可能的新天地,它为我打开了通往智能应用开发的新大门,让我对人工智能与编程的结合有了全新的认知。
LangChain 以其独特的魅力简化了复杂的语言模型应用开发流程。它犹如一座桥梁,将各种语言模型与外部数据源、工具无缝连接,极大地拓展了语言模型的功能边界。通过它,我能轻松地为语言模型接入互联网搜索、数据库查询等功能,使其能够像人类一样整合多方信息,给出更全面且精准的回答。
学习 LangChain 的过程并非一帆风顺。其丰富的功能模块和多样的应用场景,在带来强大能力的同时,也伴随着一定的学习曲线。例如,在理解和配置不同的组件,以及处理各种数据流转和交互逻辑时,需要花费大量时间去钻研和实践。但每一次克服困难,成功实现一个功能,如构建一个基于 LangChain 的智能问答系统,都能让我感受到满满的成就感,也让我对其背后的设计理念和技术架构有了更深刻的理解。
总的来说,LangChain 是一款极具创新性和实用性的工具。它不仅提升了我在人工智能开发领域的技能水平,更激发了我探索更多智能应用可能性的热情。我相信,在未来的技术发展浪潮中,LangChain 将成为构建智能应用的关键利器,助力我们创造出更加智能、便捷、高效的软件系统,为人们的生活和工作带来前所未有的变革与提升。我也期待着能在更多实际项目中深入应用 LangChain,挖掘它的更多潜力。
