一、最佳人选
问题描述
某特种部队采用了一套性格密码机制来筛选执行特定任务的最佳士兵,该机制的规则如下:
- 每个人的性格可以通过
M个维度来描述,每个维度分为A, B, C, D, E五种类型。 - 同一维度内,字母距离越近,性格类型差异越小,匹配程度越高。比如,A 和 B 的差异为
1,A 和 D 的差异为3。 - 其中
AE、BD、CE、BE为不相容性格类型,差异值设为无穷大(无法匹配)。 - 如果某一维度存在不相容性格类型,则表示两个士兵性格完全不匹配。
- 对于符合匹配条件的士兵,差异值总和越小表示匹配程度越高。
现在,有一个重要的机密任务,要求找到最匹配该任务所需性格密码的士兵。你需要编写一个算法,帮助部队找到符合条件的最佳人选。
m表示性格密码的维度。n表示备选特种兵的数量。target是代表任务的性格密码。array是一个包含n个元素的列表,每个元素为M位的性格密码。
测试样例
样例1:
输入:
m = 6, n = 3, target = "ABCDEA", array = ["AAAAAA", "BBBBBB", "ABDDEB"]
输出:'ABDDEB'
样例2:
输入:
m = 5, n = 4, target = "ABCED", array = ["ABCDE", "BCDEA", "ABDCE", "EDCBA"]
输出:'ABCDE'
样例3:
输入:
m = 4, n = 4, target = "AEBC", array = ["ACDC", "BBDC", "EBCB", "BBBB"]
输出:'None'
解题思路:
问题理解
- 性格密码维度:每个人的性格可以从
M个维度来描述,每个维度分为ABCDE5 种类型。 - 性格类型差异:同一维度内字母距离越近,表示该维度性格类型差异越小。例如,
A和B的差异为1,A和D的差异为3。 - 不相容性格类型:
AE、BD、CE、BE为不相容性格类型,可以认为他们的性格差异为正无穷大。 - 匹配度计算:如果两士兵性格密码在
M个维度下性格类型差异值总和越小,就代表这两人性格越匹配。但如果某一维度包含不相容性格类型,则表示两人性格密码完全不匹配。
数据结构选择
- 字符串:每个特种兵的性格密码可以用一个字符串表示。
- 向量:所有特种兵的性格密码可以用一个字符串向量表示。
算法步骤
-
输入处理:读取
M和N,以及目标性格密码和所有特种兵的性格密码。 -
差异计算:
- 对于每个特种兵的性格密码,逐个维度计算与目标性格密码的差异。
- 如果遇到不相容性格类型,直接标记为不匹配。
-
匹配度比较:
- 计算每个特种兵与目标性格密码的总差异。
- 找到差异最小的特种兵。
-
输出结果:
- 如果有多个特种兵的差异相同且最小,输出所有这些特种兵的性格密码。
- 如果没有合适人选,输出
None。
最终代码:
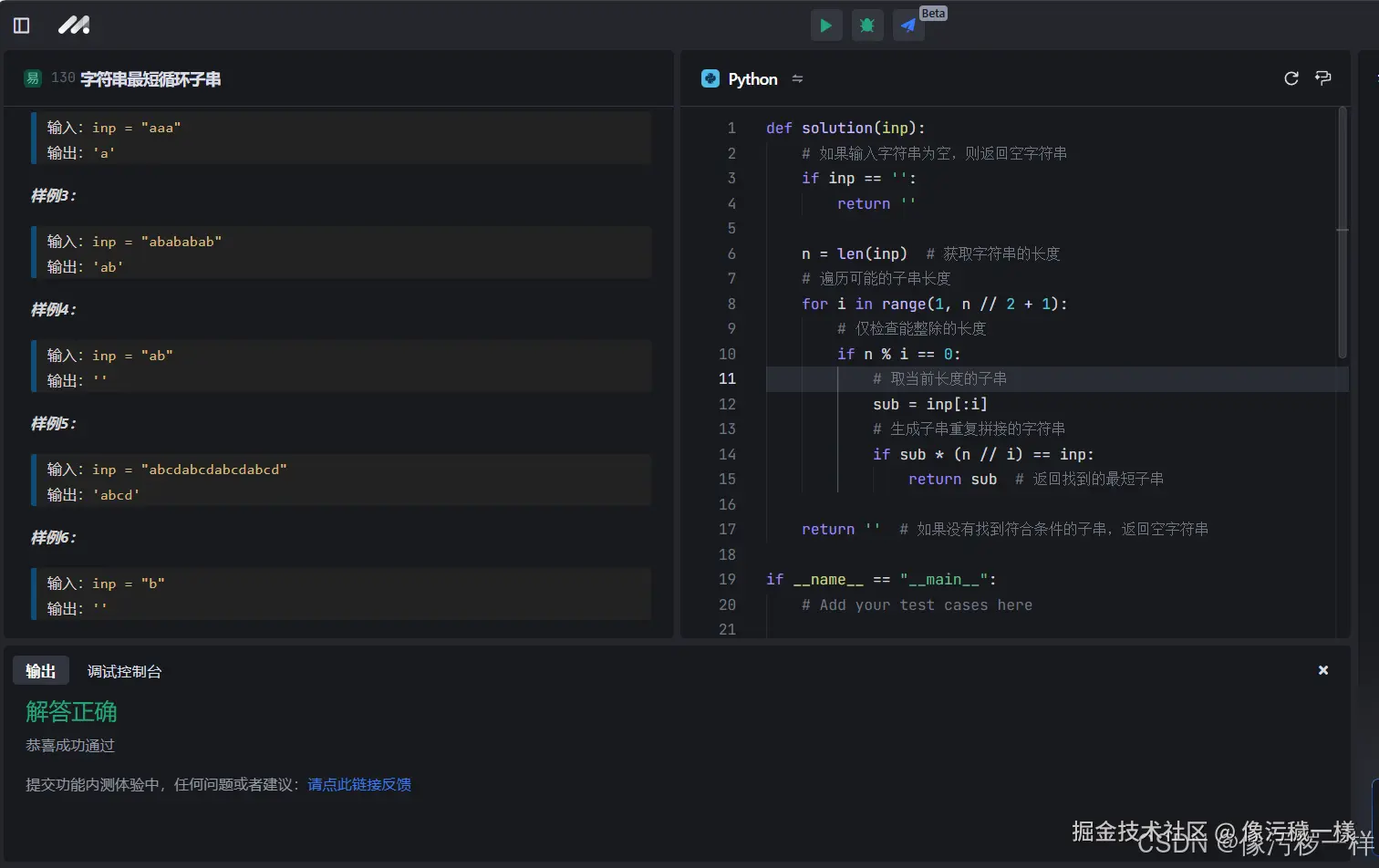
def solution(m, n, target, array):
scores = []
for i in range(n):
cand = array[i]
score = 0
for j in range(m):
if (cand[j] == 'A' and target[j] == 'E') or (cand[j] == 'E' and target[j] == 'A'):
score = 255
break
elif (cand[j] == 'B' and target[j] == 'D') or (cand[j] == 'D' and target[j] == 'B'):
score = 255
break
elif (cand[j] == 'C' and target[j] == 'E') or (cand[j] == 'E' and target[j] == 'C'):
score = 255
break
elif (cand[j] == 'B' and target[j] == 'E') or (cand[j] == 'E' and target[j] == 'B'):
score = 255
break
else:
score += abs(ord(cand[j])-ord(target[j]))
scores.append(255-score)
max_score = max(scores)
if max_score == 0:
return 'None'
people = []
for i in range(n):
if scores[i] == max_score:
people.append(array[i])
result = ' '.join(i for i in people)
return result
运行结果:

二、字符串最短循环子串
问题描述
小M在研究字符串时发现了一个有趣的现象:某些字符串是由一个较短的子串反复拼接而成的。如果能够找到这个最短的子串,便可以很好地还原字符串的结构。你的任务是给定一个字符串,判断它是否是由某个子串反复拼接而成的。如果是,输出该最短的子串;否则,输出空字符串""。
例如:当输入字符串为 abababab 时,它可以由子串 ab 反复拼接而成,因此输出 ab;而如果输入 ab,则该字符串不能通过子串的重复拼接得到,因此输出空字符串。
测试样例
样例1:
输入:
inp = "abcabcabcabc"
输出:'abc'
样例2:
输入:
inp = "aaa"
输出:'a'
样例3:
输入:
inp = "abababab"
输出:'ab'
样例4:
输入:
inp = "ab"
输出:''
样例5:
输入:
inp = "abcdabcdabcdabcd"
输出:'abcd'
样例6:
输入:
inp = "b"
输出:''
解题思路:
问题理解
我们需要判断一个字符串是否可以由某个子串重复拼接而成,并且找到这个最短的子串。如果可以找到这样的子串,就返回它;否则,返回空字符串。
数据结构选择
由于我们只需要处理字符串,不需要额外的数据结构。
算法步骤
- 边界条件处理:如果输入字符串为空,直接返回空字符串。
- 遍历可能的子串长度:从1到字符串长度的一半(因为子串长度至少要是1,且不能超过字符串长度的一半)。
- 检查子串长度是否能整除字符串长度:只有能整除的情况下,才有可能由该子串重复拼接而成。
- 生成重复拼接的字符串并比较:取当前长度的子串,重复拼接成与原字符串长度相同的字符串,然后与原字符串比较。
- 返回结果:如果找到符合条件的子串,返回该子串;否则,返回空字符串。
关键点
- 整除性检查:只有能整除的情况下,才有可能由该子串重复拼接而成。
- 重复拼接:通过重复拼接子串并与原字符串比较,判断是否符合条件。
最终代码:
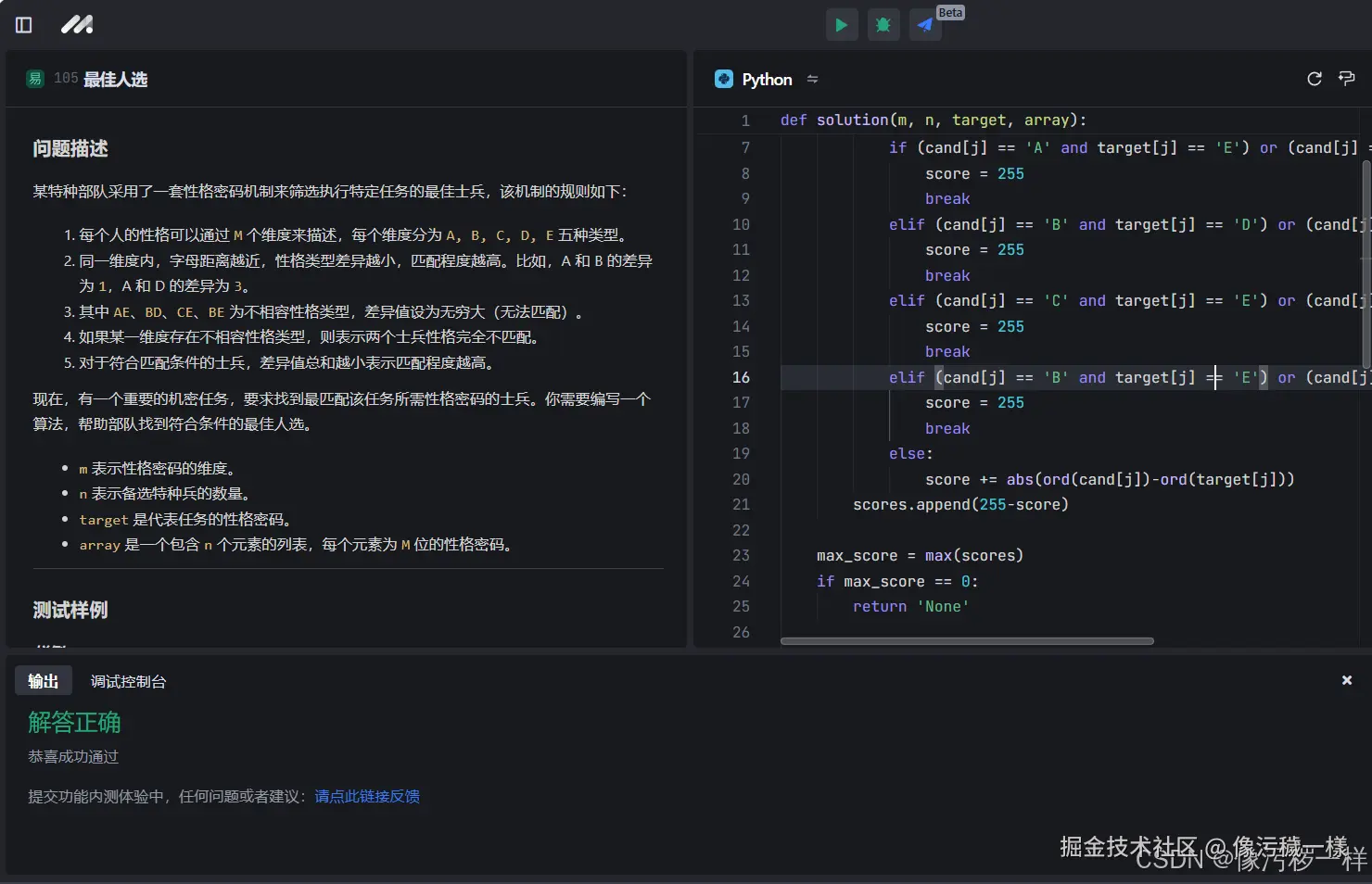
def solution(inp):
# 如果输入字符串为空,则返回空字符串
if inp == '':
return ''
n = len(inp) # 获取字符串的长度
# 遍历可能的子串长度
for i in range(1, n // 2 + 1):
# 仅检查能整除的长度
if n % i == 0:
# 取当前长度的子串
sub = inp[:i]
# 生成子串重复拼接的字符串
if sub * (n // i) == inp:
return sub # 返回找到的最短子串
return '' # 如果没有找到符合条件的子串,返回空字符串
if __name__ == "__main__":
# Add your test cases here
print(solution("abcabcabcabc") == "abc")
运行结果: