XLNet
论文链接
排列语言模型(Permutation Language Modeling)
- XLNET结合自回归语言模型和自编码语言模型的优点,提出了排列语言模型
- 我们对所有token进行排列组合。通过不同的排列,在预测某一个 token 的时候,总会有不同的排列能考虑到所有 token 的上下文信息。注意的是,实际在预训练时,并非真的重新排列,而是利用attention mask的思想来近似实现不同的排列。
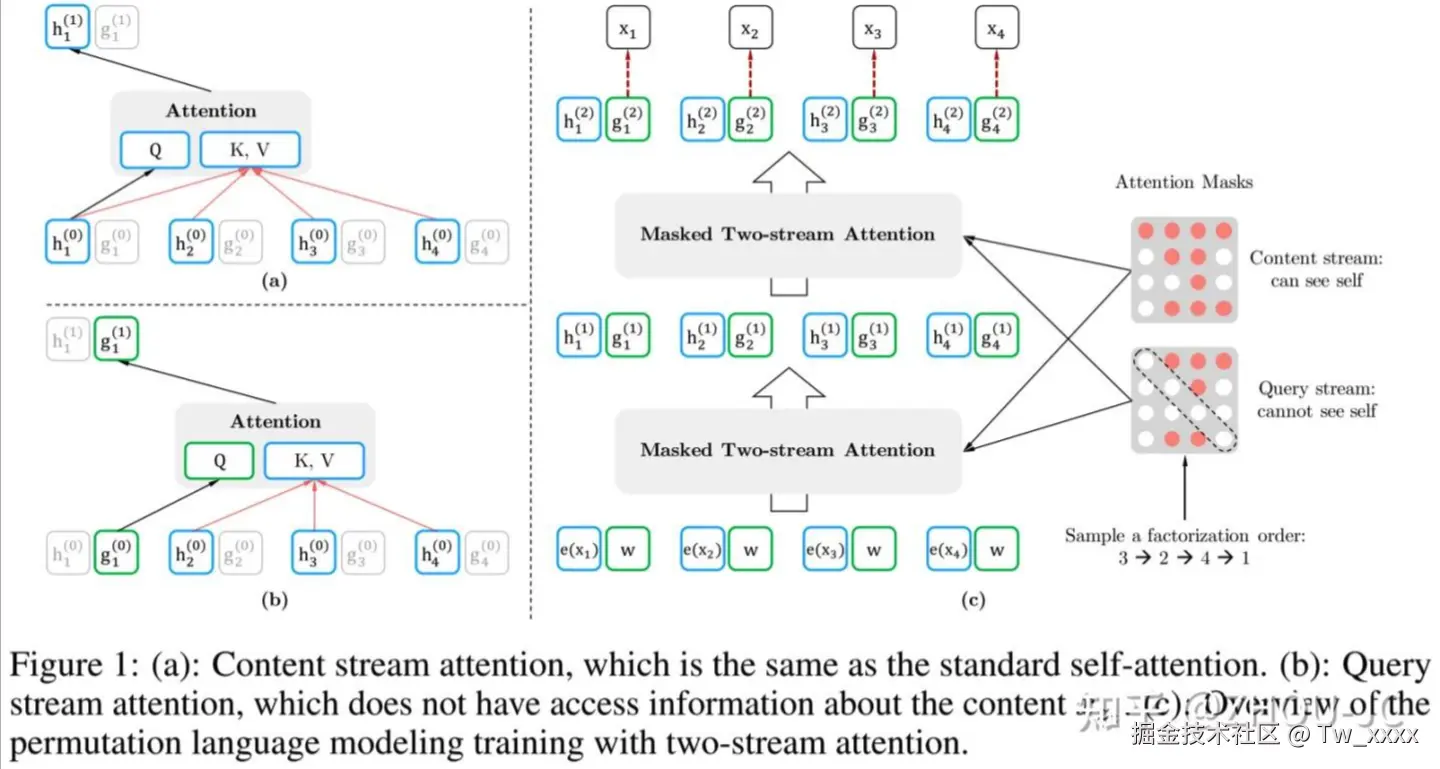
双流自注意力
- 根据上面的思想,又引出了一个问题,例如 I love New York 这四个token,现在有两个序列 1 -> 2 -> 3 -> 4 和 1 -> 2 -> 4 -> 3,假设已经知道前面两个 token 是 I love,要预测下一个token,很明显,在两个序列中,下一个token为New的概率都是一样的,这是非常不合理的,因为New作为位置3和位置4的概率应该是不一样的。因此,作者提出了一种双流自注意力。
- Query Stream:只能看到当前的位置信息,不能看到当前token的编码
- Content Stream:传统self-attention,像GPT一样对当前token进行编码
- 具体操作就是用两组隐状态(hidden states) g 和 h。其中 g 只有位置信息,作为 self-attention 里的Q,h包含内容信息,作为K和V。具体表示如下图所示: